") NSDI '23熱點(diǎn)論文:可編程、RDMA、數(shù)據(jù)中心、GPU有哪些新動(dòng)態(tài)?
NSDI '23熱點(diǎn)論文:可編程、RDMA、數(shù)據(jù)中心、GPU有哪些新動(dòng)態(tài)?
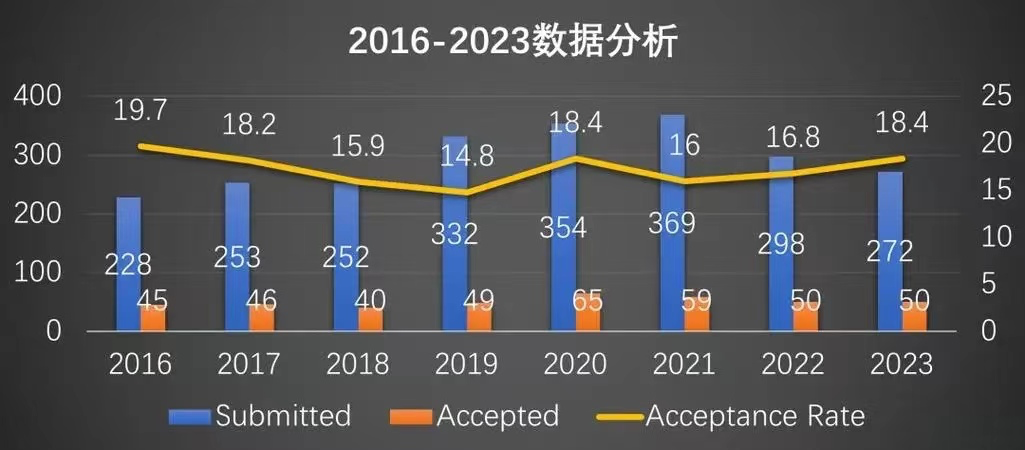 | NSDI 2016-2023論文數(shù)據(jù)分析,來源:網(wǎng)絡(luò)NSDI常年錄取率非常低,穩(wěn)定在20%以下,有的年份甚至低于15%。投稿量來看,在早幾年中呈現(xiàn)出緩慢上升的趨勢(shì),從16年的228到2021年的369篇,一路上升,然后有所下降,2022年和2023年分別為298和272篇。錄取量也呈現(xiàn)出緩慢上升的趨勢(shì),到2020年的65篇,之后開始下降,至2022的50篇。錄取率整體呈現(xiàn)浮動(dòng)的趨勢(shì),但是相對(duì)穩(wěn)定,2023年錄取率為18.4%。NSDI重點(diǎn)關(guān)注計(jì)算機(jī)網(wǎng)絡(luò),但也覆蓋了人工智能、機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺、無線和分布式計(jì)算等內(nèi)容,是一個(gè)非常全面的會(huì)議。本文介紹了NSDI 2023中可編程、RDMA、數(shù)據(jù)中心、GPU方向的相關(guān)論文,文末附NSDI 2023全部論文下載鏈接。
可編程
標(biāo)題:A High-Speed Stateful Packet Processing Approach for Tbps Programmable Switches
| NSDI 2016-2023論文數(shù)據(jù)分析,來源:網(wǎng)絡(luò)NSDI常年錄取率非常低,穩(wěn)定在20%以下,有的年份甚至低于15%。投稿量來看,在早幾年中呈現(xiàn)出緩慢上升的趨勢(shì),從16年的228到2021年的369篇,一路上升,然后有所下降,2022年和2023年分別為298和272篇。錄取量也呈現(xiàn)出緩慢上升的趨勢(shì),到2020年的65篇,之后開始下降,至2022的50篇。錄取率整體呈現(xiàn)浮動(dòng)的趨勢(shì),但是相對(duì)穩(wěn)定,2023年錄取率為18.4%。NSDI重點(diǎn)關(guān)注計(jì)算機(jī)網(wǎng)絡(luò),但也覆蓋了人工智能、機(jī)器學(xué)習(xí)、計(jì)算機(jī)視覺、無線和分布式計(jì)算等內(nèi)容,是一個(gè)非常全面的會(huì)議。本文介紹了NSDI 2023中可編程、RDMA、數(shù)據(jù)中心、GPU方向的相關(guān)論文,文末附NSDI 2023全部論文下載鏈接。
可編程
標(biāo)題:A High-Speed Stateful Packet Processing Approach for Tbps Programmable Switches作者:Mariano Scazzariello and Tommaso Caiazzi, KTH Royal Institute of Technology and Roma Tre University; Hamid Ghasemirahni, KTH Royal Institute of Technology; Tom Barbette, UCLouvain; Dejan Kosti? and Marco Chiesa, KTH Royal Institute of Technology
>摘要高速 ASIC 交換機(jī)有望在高速數(shù)據(jù)平面中直接卸載復(fù)雜的數(shù)據(jù)包處理管道。然而,當(dāng)今各種各樣的數(shù)據(jù)包處理管道,包括有狀態(tài)網(wǎng)絡(luò)功能和數(shù)據(jù)包調(diào)度程序,都需要以編程的方式在短時(shí)間內(nèi)存儲(chǔ)一些(或所有)數(shù)據(jù)包。而如今的高速 ASIC 交換機(jī)缺少這種可編程緩沖功能。在這項(xiàng)工作中,我們提出了一種擴(kuò)展可編程交換機(jī)系統(tǒng)——RIBOSOME。它具有外部存儲(chǔ)器(用于存儲(chǔ)數(shù)據(jù)包)和外部通用數(shù)據(jù)包處理設(shè)備(用于執(zhí)行有狀態(tài)操作),如 CPU 或 FPGA。由于當(dāng)今的數(shù)據(jù)包處理設(shè)備受到網(wǎng)絡(luò)接口速度的限制,RIBOSOME 只將相關(guān)數(shù)據(jù)比特傳輸?shù)竭@些設(shè)備。RIBOSOME 利用直接連接的服務(wù)器的空閑帶寬,通過RDMA存儲(chǔ)傳入的有效負(fù)載。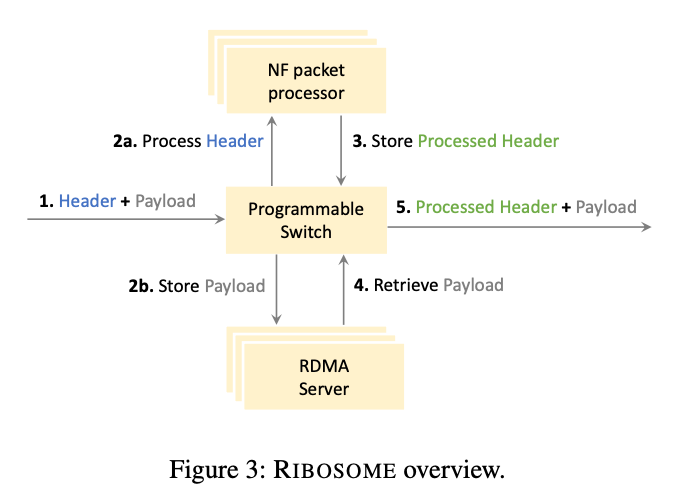 標(biāo)題:ExoPlane: An Operating System for On-Rack Switch Resource Augmentation
標(biāo)題:ExoPlane: An Operating System for On-Rack Switch Resource Augmentation作者:Daehyeok Kim, Microsoft and University of Texas at Austin; Vyas Sekar and Srinivasan Seshan, Carnegie Mellon University
>摘要在實(shí)際的部署中(例如云和 ISP),在網(wǎng)計(jì)算的承諾仍然沒有實(shí)現(xiàn),因?yàn)榻粨Q機(jī)的片上資源有限,在可編程交換機(jī)上服務(wù)并發(fā)有狀態(tài)應(yīng)用程序仍然具有挑戰(zhàn)性。在這項(xiàng)工作中,我們?cè)O(shè)計(jì)并實(shí)施了 ExoPlane,這是一種用于機(jī)架交換機(jī)資源擴(kuò)充的操作系統(tǒng),可以支持多個(gè)并發(fā)應(yīng)用程序。在設(shè)計(jì) ExoPlane 時(shí),我們提出了一個(gè)實(shí)用的運(yùn)行時(shí)操作模型和狀態(tài)抽象,以最小的性能和資源開銷解決跨多個(gè)設(shè)備正確管理應(yīng)用程序狀態(tài)的挑戰(zhàn)。我們對(duì)各種 P4 應(yīng)用程序的評(píng)估表明,ExoPlane 可以為應(yīng)用程序提供低延遲、可擴(kuò)展吞吐量和快速故障轉(zhuǎn)移,同時(shí)以較小的資源開銷實(shí)現(xiàn)這些,并且無需或只需對(duì)應(yīng)用程序進(jìn)行少量修改。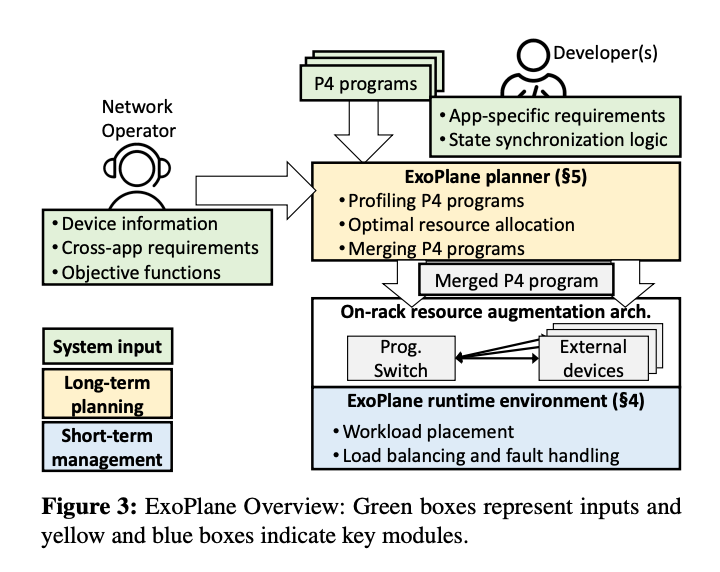 標(biāo)題:Sketchovsky: Enabling Ensembles of Sketches on Programmable Switches
標(biāo)題:Sketchovsky: Enabling Ensembles of Sketches on Programmable Switches作者:Hun Namkung, Carnegie Mellon University; Zaoxing Liu, Boston University; Daehyeok Kim, Microsoft Research; Vyas Sekar and Peter Steenkiste, Carnegie Mellon University
>摘要網(wǎng)絡(luò)運(yùn)營(yíng)商需要在可編程交換機(jī)上運(yùn)行各種測(cè)量任務(wù),以支持管理決策(例如流量工程或異常檢測(cè))。雖然之前的工作已經(jīng)表明運(yùn)行單個(gè)sketch實(shí)例的可行性,但它們?cè)诤艽蟪潭壬虾雎粤藶橐唤M測(cè)量任務(wù)運(yùn)行多個(gè)sketch實(shí)例的問題。因此,現(xiàn)有的工作不足以有效地支持sketch實(shí)例的一般集合。在這項(xiàng)工作中,我們介紹了 Sketchovsky 的設(shè)計(jì)和實(shí)現(xiàn),這是一種新穎的cross-sketch優(yōu)化和構(gòu)圖框架。我們確定了五個(gè)新的cross-sketch優(yōu)化構(gòu)建塊,以減少關(guān)鍵的交換機(jī)硬件資源。我們?cè)O(shè)計(jì)了有效的啟發(fā)式方法來為任意集合選擇和應(yīng)用這些構(gòu)建塊。為了簡(jiǎn)化開發(fā)人員的工作,Sketchovsky 自動(dòng)生成要輸入到硬件編譯器的組合代碼。我們的評(píng)估表明,Sketchovsky 使多達(dá) 18 個(gè)sketch實(shí)例的集成變得可行,并且可以減少多達(dá) 45% 的關(guān)鍵硬件資源。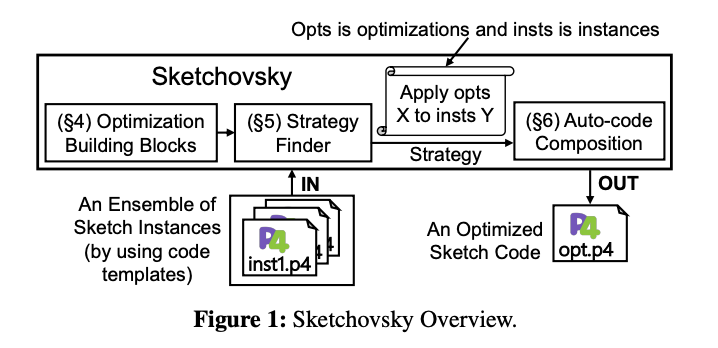 標(biāo)題:RingLeader: Efficiently Offloading Intra-Server Orchestration to NICs
標(biāo)題:RingLeader: Efficiently Offloading Intra-Server Orchestration to NICs作者:Jiaxin Lin, Adney Cardoza, Tarannum Khan, and Yeonju Ro, UT Austin; Brent E. Stephens, University of Utah; Hassan Wassel, Google; Aditya Akella, UT Austin
>摘要在數(shù)據(jù)中心服務(wù)器上周密的編排請(qǐng)求,對(duì)于滿足嚴(yán)格的尾部延遲要求并確保高吞吐量和最佳 CPU 利用率至關(guān)重要。編排是多管齊下的,涉及到負(fù)載平衡和調(diào)度跨CPU資源屬于不同服務(wù)的請(qǐng)求,以及調(diào)整 CPU 分配以適應(yīng)突發(fā)請(qǐng)求。集中式服務(wù)器內(nèi)編排提供了理想的負(fù)載平衡性能、調(diào)度精度和突發(fā)容錯(cuò) CPU 重新分配。然而,現(xiàn)有的純軟件方法無法實(shí)現(xiàn)理想的編排,因?yàn)樗鼈兊目蓴U(kuò)展性有限,并且浪費(fèi) CPU 資源。我們主張采用一種新方法,將服務(wù)器內(nèi)編排完全卸載到網(wǎng)卡。我們提出了RingLeader,一個(gè)新的可編程網(wǎng)卡,具有新穎的硬件單元,用于軟件通知請(qǐng)求負(fù)載平衡和可編程調(diào)度,以及一個(gè)新的輕量級(jí) OS-NIC 接口,可實(shí)現(xiàn) NIC-CPU 緊密協(xié)調(diào)并支持 NIC 輔助 CPU 調(diào)度。基于 100 Gbps FPGA 原型的詳細(xì)實(shí)驗(yàn)表明,與包括 Shinjuku 和 Caladan 在內(nèi)的最先進(jìn)的純軟件協(xié)調(diào)器相比,我們獲得了更好的可擴(kuò)展性、效率、延遲和吞吐量。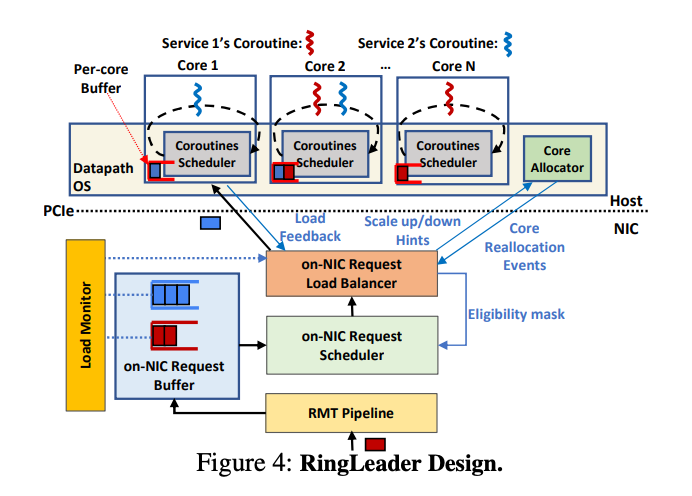 ?
?RDMA
標(biāo)題:SRNIC: A Scalable Architecture for RDMA NICs
?
?RDMA
標(biāo)題:SRNIC: A Scalable Architecture for RDMA NICs作者:Zilong Wang, Hong Kong University of Science and Technology; Layong Luo and Qingsong Ning, ByteDance; Chaoliang Zeng, Wenxue Li, and Xinchen Wan, Hong Kong University of Science and Technology等
>摘要符合設(shè)想的RDMA需要具有高度可擴(kuò)展性:在不可避免丟包的大型數(shù)據(jù)中心網(wǎng)絡(luò)中表現(xiàn)良好(即高網(wǎng)絡(luò)可擴(kuò)展性),并支持每臺(tái)服務(wù)器大量高性能連接(即高可擴(kuò)展性)。商用RoCEv2 NIC(RNIC)缺乏可擴(kuò)展性,因?yàn)樗鼈円蕾囉跓o損、有限規(guī)模的網(wǎng)絡(luò)結(jié)構(gòu),只支持少量高性能連接。在本文中,我們旨在通過設(shè)計(jì)SRNIC(一種可擴(kuò)展RDMA NIC架構(gòu))來解決連接可擴(kuò)展性挑戰(zhàn),同時(shí)保持商用RNIC的高性能和低CPU開銷,以及IRN的高網(wǎng)絡(luò)可擴(kuò)展性。我們對(duì)SRNIC的關(guān)鍵見解是,通過仔細(xì)的協(xié)議和架構(gòu)協(xié)同設(shè)計(jì),可以將RNIC中的片上數(shù)據(jù)結(jié)構(gòu)及其內(nèi)存需求降至最低,從而提高連接可擴(kuò)展性。在此基礎(chǔ)上,我們分析了RDMA概念模型中涉及的所有數(shù)據(jù)結(jié)構(gòu),并通過RDMA協(xié)議頭修改和架構(gòu)創(chuàng)新(包括無緩存QP調(diào)度器和無內(nèi)存選擇性重傳)盡可能多地刪除它們。我們使用FPGA實(shí)現(xiàn)了一個(gè)功能齊全的SRNIC原型。實(shí)驗(yàn)表明,SRNIC在芯片上實(shí)現(xiàn)了10K性能連接,在標(biāo)準(zhǔn)化連接可擴(kuò)展性(即每1MB內(nèi)存的性能連接數(shù))方面比商用RNIC高18倍,同時(shí)實(shí)現(xiàn)了97 Gbps吞吐量和3.3μs延遲,CPU開銷低于5%,并保持了高網(wǎng)絡(luò)可擴(kuò)展性。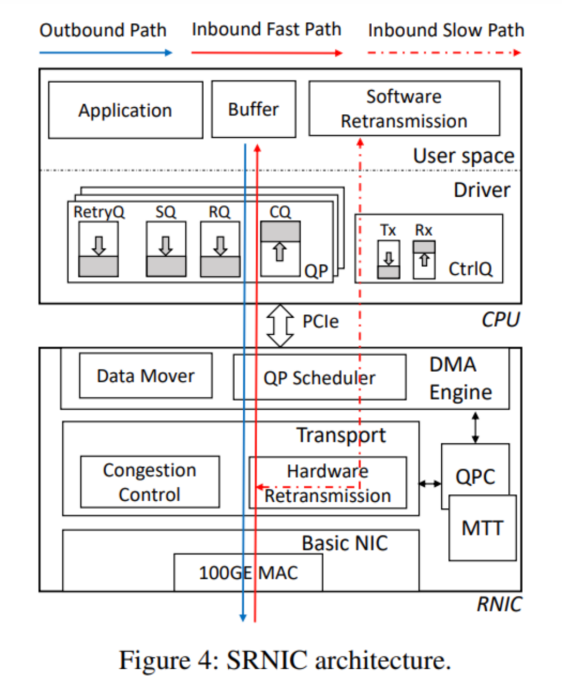 標(biāo)題:Hostping: Diagnosing Intra-host Network Bottlenecks in RDMA Servers
標(biāo)題:Hostping: Diagnosing Intra-host Network Bottlenecks in RDMA Servers作者:Kefei Liu, BUPT; Zhuo Jiang, ByteDance Inc.; Jiao Zhang, BUPT and Purple Mountain Laboratories; Haoran Wei, BUPT and ByteDance Inc.; Xiaolong Zhong, BUPT; Lizhuang Tan, ByteDance Inc.; Tian Pan and Tao Huang, BUPT and Purple Mountain Laboratories
>摘要在RDMA網(wǎng)絡(luò)中,主機(jī)內(nèi)網(wǎng)絡(luò)被認(rèn)為是健壯的,但很少受到關(guān)注。然而,隨著RNIC(RDMA網(wǎng)卡)線路速率快速提升至數(shù)百G,主機(jī)內(nèi)網(wǎng)絡(luò)成為網(wǎng)絡(luò)應(yīng)用潛在的性能瓶頸。主機(jī)內(nèi)網(wǎng)絡(luò)瓶頸可能導(dǎo)致主機(jī)內(nèi)帶寬降低和主機(jī)內(nèi)延遲增加,這會(huì)嚴(yán)重影響網(wǎng)絡(luò)性能。然而,當(dāng)發(fā)生主機(jī)內(nèi)瓶頸時(shí),由于缺乏監(jiān)控系統(tǒng),它們很難被發(fā)現(xiàn)。此外,現(xiàn)有的瓶頸診斷機(jī)制無法有效診斷主機(jī)內(nèi)瓶頸。在本文中,我們根據(jù)長(zhǎng)期的故障排除經(jīng)驗(yàn)分析了主機(jī)內(nèi)瓶頸的癥狀,并提出了 Hostping——首個(gè)專用于主機(jī)內(nèi)網(wǎng)絡(luò)的瓶頸監(jiān)控和診斷系統(tǒng),可實(shí)現(xiàn)低開銷分鐘級(jí)主機(jī)內(nèi)故障定位,有效提升RDMA數(shù)據(jù)中心集群的算力平穩(wěn)輸出能力。Hostping 的核心思想是在主機(jī)內(nèi)的 RNIC 和端點(diǎn)之間進(jìn)行環(huán)回測(cè)試,以測(cè)量主機(jī)內(nèi)延遲和帶寬。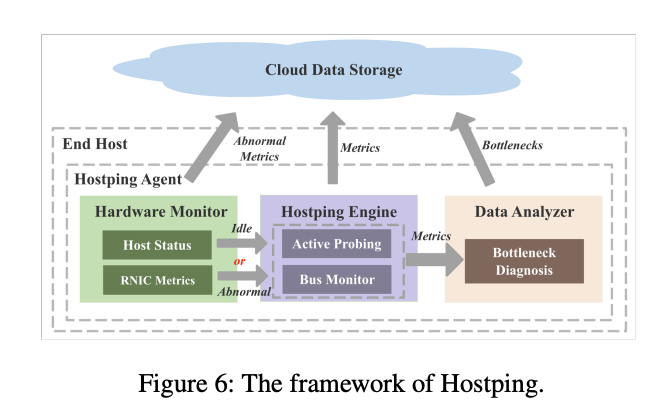 標(biāo)題:Understanding RDMA Microarchitecture Resources for Performance Isolation
標(biāo)題:Understanding RDMA Microarchitecture Resources for Performance Isolation作者:Xinhao Kong and Jingrong Chen, Duke University; Wei Bai, Microsoft; Yechen Xu, Shanghai Jiao Tong University; Mahmoud Elhaddad, Shachar Raindel, and Jitendra Padhye, Microsoft; Alvin R. Lebeck and Danyang Zhuo, Duke University
>摘要近年來,RDMA 在云中得到了廣泛采用,以加速first-party workloads,并通過釋放 CPU 周期來節(jié)省成本。現(xiàn)在,云提供商正致力于在通用客戶VM 中支持 RDMA,以使 third-party workloads受益。為此,云提供商必須提供強(qiáng)大的性能隔離,以便一個(gè)租戶的 RDMA 工作負(fù)載不會(huì)對(duì)另一個(gè)租戶的 RDMA 性能產(chǎn)生不利影響。盡管在公有云中的網(wǎng)絡(luò)性能隔離方面已經(jīng)做出了很多努力,但我們發(fā)現(xiàn) RDMA 因其復(fù)雜的 NIC 微架構(gòu)資源(例如NIC 緩存)帶來了獨(dú)特的挑戰(zhàn)。在本文中,我們旨在系統(tǒng)地了解 RNIC 微架構(gòu)資源對(duì)性能隔離的影響。我們提出了一個(gè)模型來表示 RDMA 操作如何使用 RNIC 資源。使用此模型,我們開發(fā)了一個(gè)測(cè)試套件來評(píng)估 RDMA 性能隔離解決方案。最后,根據(jù)測(cè)試結(jié)果,我們總結(jié)了設(shè)計(jì)未來 RDMA 性能隔離解決方案的新見解。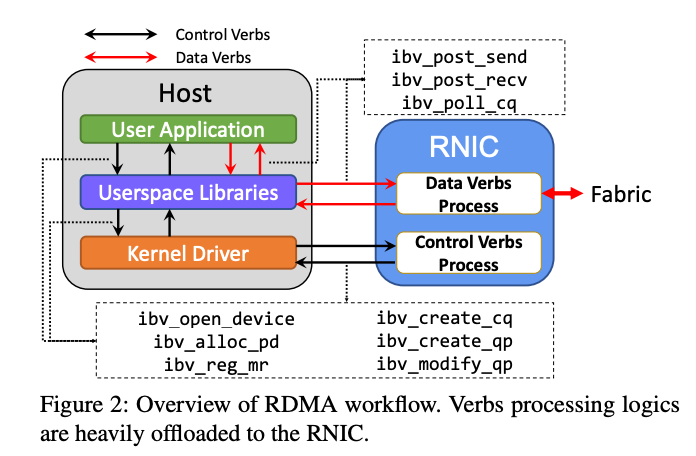 標(biāo)題:Empowering Azure Storage with RDMA
標(biāo)題:Empowering Azure Storage with RDMA作者:Wei Bai, Shanim Sainul Abdeen, Ankit Agrawal, Krishan Kumar Attre, Paramvir Bahl, Ameya Bhagat, Gowri Bhaskara, Tanya Brokhman, Lei Cao, Ahmad Cheema, Rebecca Chow, Jeff Cohen, Mahmoud Elhaddad等
>摘要網(wǎng)絡(luò)是在云存儲(chǔ)服務(wù)中實(shí)現(xiàn)高性能和高可靠性的關(guān)鍵。在Azure中,我們選擇遠(yuǎn)程RDMA作為傳輸方式,旨在為存儲(chǔ)前端流量(計(jì)算虛擬機(jī)和存儲(chǔ)集群之間)和后端流量(存儲(chǔ)集群內(nèi))啟用它,以充分發(fā)揮其優(yōu)勢(shì)。由于計(jì)算和存儲(chǔ)集群可能位于Azure區(qū)域內(nèi)的不同數(shù)據(jù)中心,因此需要在區(qū)域范圍內(nèi)支持RDMA。這項(xiàng)工作展示了我們?cè)诓渴饏^(qū)域內(nèi)RDMA以支持Azure中的存儲(chǔ)工作負(fù)載方面的經(jīng)驗(yàn)。基礎(chǔ)設(shè)施的高度復(fù)雜性和異構(gòu)性帶來了一系列新的挑戰(zhàn),例如不同類型的RDMA網(wǎng)絡(luò)接口卡之間的互操作性問題。為了應(yīng)對(duì)這些挑戰(zhàn),我們對(duì)網(wǎng)絡(luò)基礎(chǔ)設(shè)施做了一些更改。今天,Azure中大約70%的流量是RDMA,所有Azure公共區(qū)域都支持區(qū)域內(nèi)RDMA。RDMA幫助我們實(shí)現(xiàn)了顯著的磁盤I/O性能改進(jìn)和CPU內(nèi)核節(jié)省。 ?
?數(shù)據(jù)中心
標(biāo)題:Flattened Clos: Designing High-performance Deadlock-free Expander Data Center Networks Using Graph Contraction
?
?數(shù)據(jù)中心
標(biāo)題:Flattened Clos: Designing High-performance Deadlock-free Expander Data Center Networks Using Graph Contraction作者:Shizhen Zhao, Qizhou Zhang, Peirui Cao, Xiao Zhang, and Xinbing Wang, Shanghai Jiao Tong University; Chenghu Zhou, Shanghai Jiao Tong University and Chinese Academy of Sciences
>摘要Flattened Clos (FC),一種拓?fù)?路由協(xié)同設(shè)計(jì)方法,用于消除expander網(wǎng)絡(luò)中由 PFC 引起的死鎖。FC的拓?fù)浣Y(jié)構(gòu)和路由設(shè)計(jì)分為三步:1)將每個(gè)ToR交換機(jī)在邏輯上劃分為k個(gè)虛擬層,只在相鄰虛擬層之間建立連接;2) 生成用于路由的虛擬上下路徑;3) 利用圖形收縮對(duì)虛擬多層網(wǎng)絡(luò)和虛擬上下路徑進(jìn)行平面化。FC 的設(shè)計(jì)是無死鎖的,并使用真實(shí)的測(cè)試平臺(tái)和數(shù)據(jù)包級(jí)仿真驗(yàn)證了這一特性。與EDST(edge-disjoint-spanning-tree)路由相比,F(xiàn)C 將平均跳數(shù)減少了至少 50%,并將網(wǎng)絡(luò)吞吐量提高了2 - 10倍以上。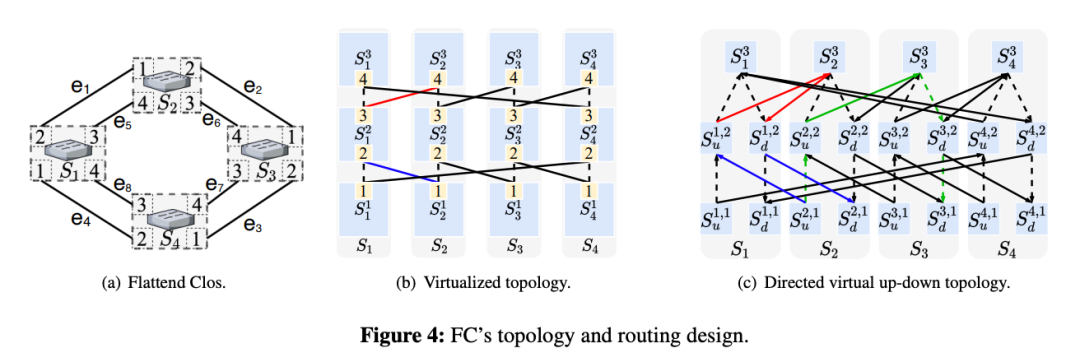 ?標(biāo)題:Scalable Tail Latency Estimation for Data Center Networks
?標(biāo)題:Scalable Tail Latency Estimation for Data Center Networks作者:Kevin Zhao, University of Washington; Prateesh Goyal, Microsoft Research; Mohammad Alizadeh, MIT CSAIL; Thomas E. Anderson, University of Washington
>摘要該論文主要研究了如何為超大規(guī)模數(shù)據(jù)中心網(wǎng)絡(luò)提供流級(jí)尾延遲性能的快速估計(jì)。網(wǎng)絡(luò)尾部延遲通常是云應(yīng)用性能的一個(gè)關(guān)鍵指標(biāo),它會(huì)受到多種因素的影響,包括網(wǎng)絡(luò)負(fù)載、機(jī)架間流量偏差、流量突發(fā)、流量大小分布、超額訂閱和拓?fù)洳粚?duì)稱等。像ns-3 和 OMNeT++ 這樣的網(wǎng)絡(luò)模擬器可以提供準(zhǔn)確的答案,但很難并行化,即使是中等規(guī)模的單個(gè)配置也需要數(shù)小時(shí)或數(shù)天來回答 what if 問題。MimicNet 展示了如何使用機(jī)器學(xué)習(xí)來提高模擬性能,不過每個(gè)配置都包含一個(gè)很長(zhǎng)的訓(xùn)練步驟,并且對(duì)工作量和拓?fù)湟恢滦缘募僭O(shè)通常在實(shí)踐中并不適用。本文主要介紹了解決上述問題的技術(shù),為具有通用流量矩陣和拓?fù)涞拇笮途W(wǎng)絡(luò)提供快速性能估計(jì)。其中一個(gè)關(guān)鍵步驟是將問題分解成大量并行獨(dú)立的單鏈路模擬,通過仔細(xì)結(jié)合這些鏈路級(jí)模擬可以準(zhǔn)確估計(jì)整個(gè)網(wǎng)絡(luò)的端到端流量級(jí)性能分布。同時(shí)盡可能利用對(duì)稱性來獲得額外的加速,但不依賴機(jī)器學(xué)習(xí),因此沒有訓(xùn)練延遲。在 ns-3 需要 11到 27 小時(shí)來模擬 5 秒的網(wǎng)絡(luò)行為的大規(guī)模網(wǎng)絡(luò)上,新技術(shù)只需 1 到 2 分鐘內(nèi)便可完成運(yùn)行,尾流完成時(shí)間的準(zhǔn)確度在 9% 以內(nèi)。 標(biāo)題:Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning
標(biāo)題:Shockwave: Fair and Efficient Cluster Scheduling for Dynamic Adaptation in Machine Learning作者:Pengfei Zheng and Rui Pan, University of Wisconsin-Madison; Tarannum Khan, The University of Texas at Austin; Shivaram Venkataraman, University of Wisconsin-Madison; Aditya Akella, The University of Texas at Austin
>摘要動(dòng)態(tài)自適應(yīng)已成為加速分布式機(jī)器學(xué)習(xí) (ML) 訓(xùn)練的關(guān)鍵技術(shù)。最近的研究表明,動(dòng)態(tài)調(diào)整模型結(jié)構(gòu)或超參數(shù)可以在不犧牲準(zhǔn)確性的情況下顯著加速訓(xùn)練。然而,現(xiàn)有的 ML 集群調(diào)度器并不是為處理動(dòng)態(tài)適應(yīng)而設(shè)計(jì)的。研究表明,當(dāng)訓(xùn)練吞吐量在動(dòng)態(tài)適應(yīng)下隨時(shí)間變化時(shí),現(xiàn)有方案無法提供公平性并降低系統(tǒng)效率。Shockwave是一個(gè)基于兩個(gè)關(guān)鍵思想的未來規(guī)劃調(diào)度程序。首先,Shockwave 將經(jīng)典市場(chǎng)理論從靜態(tài)設(shè)置擴(kuò)展到動(dòng)態(tài)設(shè)置,共同優(yōu)化效率和公平性。第二,Shockwave 利用隨機(jī)動(dòng)態(tài)規(guī)劃來處理動(dòng)態(tài)變化。我們?yōu)?Shockwave 構(gòu)建了一個(gè)系統(tǒng),并通過跟蹤驅(qū)動(dòng)模擬和集群實(shí)驗(yàn)驗(yàn)證了其性能。結(jié)果表明,對(duì)于具有動(dòng)態(tài)適應(yīng)性的 ML 作業(yè)軌跡,與現(xiàn)有的公平調(diào)度方案相比,Shockwave 將 makespan 提高了 1.3 倍,公平性提高了 2 倍。 標(biāo)題:Protego: Overload Control for Applications with Unpredictable Lock Contention
標(biāo)題:Protego: Overload Control for Applications with Unpredictable Lock Contention作者:Inho Cho, MIT CSAIL; Ahmed Saeed, Georgia Tech; Seo Jin Park, Mohammad Alizadeh, and Adam Belay, MIT CSAIL
>摘要現(xiàn)代數(shù)據(jù)中心應(yīng)用程序是并發(fā)的,因此它們需要同步來控制對(duì)共享數(shù)據(jù)的訪問。本文介紹了Protego系統(tǒng)用于防止鎖爭(zhēng)用問題。Protego提供了一種新的準(zhǔn)入控制策略,可以防止出現(xiàn)鎖爭(zhēng)用時(shí)的計(jì)算擁塞。關(guān)鍵思想是在基于信用的準(zhǔn)入控制算法中使用觀察到的吞吐量的邊際改進(jìn),而不是 CPU 負(fù)載或延遲測(cè)量,該算法調(diào)節(jié)對(duì)服務(wù)器的傳入請(qǐng)求的速率。Protego還引入了一種新的延遲感知同步抽象,稱為ASQM(Active synchronization Queue Management),允許應(yīng)用程序在延遲超過延遲目標(biāo)時(shí)中止請(qǐng)求。Protego 目前已經(jīng)應(yīng)用于兩個(gè)真實(shí)的應(yīng)用程序 Lucene 和 Memcached,并表明它在避免擁塞崩潰的同時(shí),比最先進(jìn)的過載控制系統(tǒng)實(shí)現(xiàn)了高達(dá)3.3倍的吞吐量和低12.2倍的99%延遲。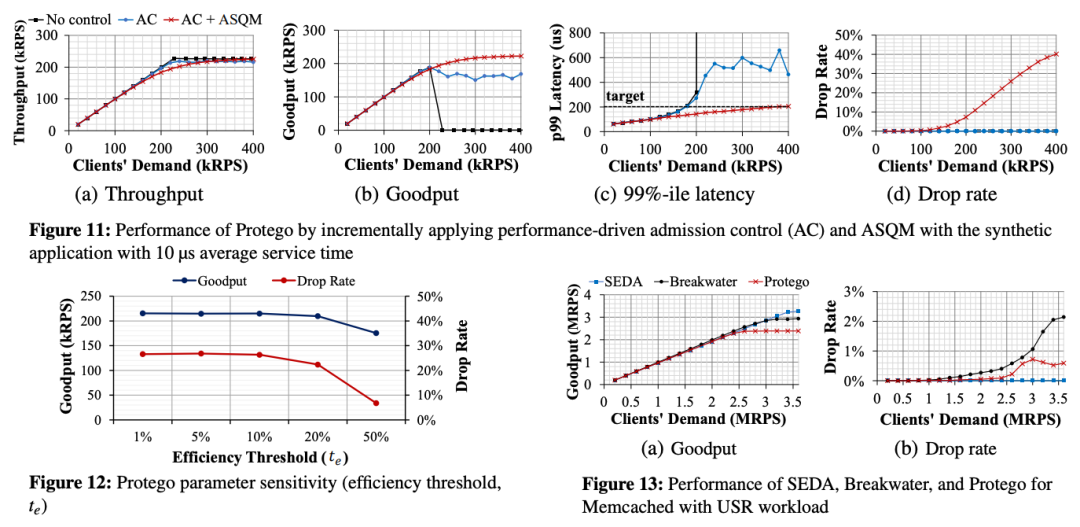 GPU標(biāo)題:Transparent GPU Sharing in Container Clouds for Deep Learning Workloads
GPU標(biāo)題:Transparent GPU Sharing in Container Clouds for Deep Learning Workloads作者:Bingyang Wu and Zili Zhang, Peking University; Zhihao Bai, Johns Hopkins University; Xuanzhe Liu and Xin Jin, Peking University
>摘要容器廣泛用于數(shù)據(jù)中心的資源管理。在容器云中支持深度學(xué)習(xí) (DL) 訓(xùn)練的一種常見做法是將 GPU 靜態(tài)綁定到整個(gè)容器。由于生產(chǎn)中 DL 作業(yè)的資源需求多種多樣,大量 GPU 未得到充分利用。因此,GPU 集群的 GPU 利用率較低,導(dǎo)致作業(yè)完成時(shí)間較長(zhǎng),因?yàn)樾枰抨?duì)。TGS(Transparent GPU Sharing)是一個(gè)為容器云中的 DL 訓(xùn)練提供透明 GPU 共享的系統(tǒng)。與最近用于 GPU 共享的應(yīng)用層解決方案形成鮮明對(duì)比的是,TGS 在容器下的操作系統(tǒng)層運(yùn)行。TGS 利用自適應(yīng)速率控制和透明統(tǒng)一內(nèi)存來同時(shí)實(shí)現(xiàn)高 GPU 利用率和性能隔離。它確保生產(chǎn)作業(yè)不會(huì)受到共享 GPU 上的機(jī)會(huì)作業(yè)的很大影響。我們構(gòu)建了 TGS 并將其與 Docker 和 Kubernetes 集成。實(shí)驗(yàn)表明 (i) TGS 對(duì)生產(chǎn)作業(yè)的吞吐量影響很小;(ii) TGS為機(jī)會(huì)作業(yè)提供了與最先進(jìn)的應(yīng)用層解決方案AntMan相似的吞吐量,并且與現(xiàn)有的操作系統(tǒng)層解決方案MPS相比,其吞吐量提高了15倍。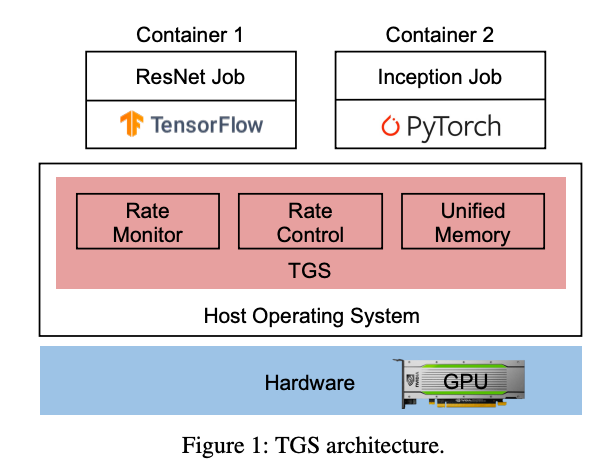 ?標(biāo)題:ARK: GPU-driven Code Execution for Distributed Deep Learning
?標(biāo)題:ARK: GPU-driven Code Execution for Distributed Deep Learning作者:Changho Hwang, KAIST, Microsoft Research; KyoungSoo Park, KAIST; Ran Shu, Xinyuan Qu, Peng Cheng, and Yongqiang Xiong, Microsoft Research
>摘要目前最先進(jìn)的深度學(xué)習(xí) (DL) 應(yīng)用程序傾向于橫向擴(kuò)展到大量并行 GPU。然而,我們觀察到跨 GPU 的集體通信開銷通常是分布式 DL 性能的關(guān)鍵限制因素。它通過頻繁傳輸小數(shù)據(jù)塊來充分利用網(wǎng)絡(luò)帶寬,這也會(huì)在 GPU 上產(chǎn)生大量 I/O 開銷,從而干擾 GPU 上的計(jì)算。根本原因在于基于 CPU 的通信事件處理效率低下以及無法通過 GPU 線程控制 GPU 內(nèi)部的 DMA 引擎。為了解決這個(gè)問題,我們提出了一個(gè) GPU 驅(qū)動(dòng)的代碼執(zhí)行系統(tǒng),該系統(tǒng)利用 GPU 控制的硬件 DMA 引擎進(jìn)行 I/O 卸載。我們的自定義 DMA 引擎流水線處理多個(gè) DMA 請(qǐng)求以支持高效的小型數(shù)據(jù)傳輸,同時(shí)消除了 GPU 內(nèi)核上的 I/O 開銷。與僅由 CPU 啟動(dòng)的現(xiàn)有 GPU DMA 引擎不同,我們讓 GPU 線程直接控制 DMA 操作,其中 GPU 驅(qū)動(dòng)自己的執(zhí)行流并自主處理通信事件,而無需 CPU 干預(yù),更高效。我們的原型 DMA 引擎從小至 8KB 的消息大小(吞吐量提高 3.9 倍)的線速,通信延遲僅為 4.3 微秒(快 9.1 倍),同時(shí)它對(duì) GPU 上的計(jì)算幾乎沒有干擾,在實(shí)際訓(xùn)練工作負(fù)載中實(shí)現(xiàn)了1.8倍的吞吐量。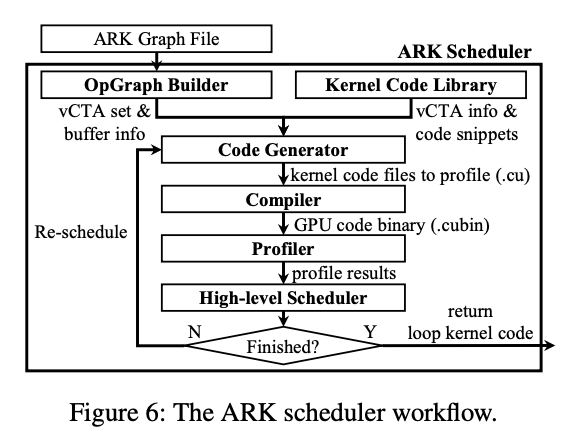 標(biāo)題:BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
標(biāo)題:BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing作者:Tianfeng Liu, Tsinghua University, Zhongguancun Laboratory, ByteDance; Yangrui Chen, The University of Hong Kong, ByteDance; Dan Li, Tsinghua University, Zhongguancun Laboratory; Chuan Wu, The University of Hong Kong; Yibo Zhu, Jun He, and Yanghua Peng, ByteDance; Hongzheng Chen, ByteDance, Cornell University; Hongzhi Chen and Chuanxiong Guo, ByteDance
>摘要現(xiàn)有系統(tǒng)在使用 GPU 訓(xùn)練具有數(shù)十億個(gè)節(jié)點(diǎn)和邊的大型圖形時(shí)效率低下,主要瓶頸是為 GPU 準(zhǔn)備數(shù)據(jù)的過程——子圖采樣和特征檢索。本文提出了 BGL,一種分布式 GNN 訓(xùn)練系統(tǒng),旨在通過幾個(gè)關(guān)鍵思想解決瓶頸問題。首先是提出了一個(gè)動(dòng)態(tài)緩存引擎來最小化特征檢索流量。通過共同設(shè)計(jì)緩存策略和采樣順序,我們找到了低開銷和高緩存命中率的最佳平衡點(diǎn)。其次改進(jìn)了圖分區(qū)算法,以減少子圖采樣期間的跨分區(qū)通信。最后,仔細(xì)的資源隔離減少了不同數(shù)據(jù)預(yù)處理階段之間的爭(zhēng)用。在各種 GNN 模型和大型圖形數(shù)據(jù)集上進(jìn)行的大量實(shí)驗(yàn)表明,BGL 的平均性能明顯優(yōu)于現(xiàn)有 GNN 訓(xùn)練系統(tǒng) 1.9 倍。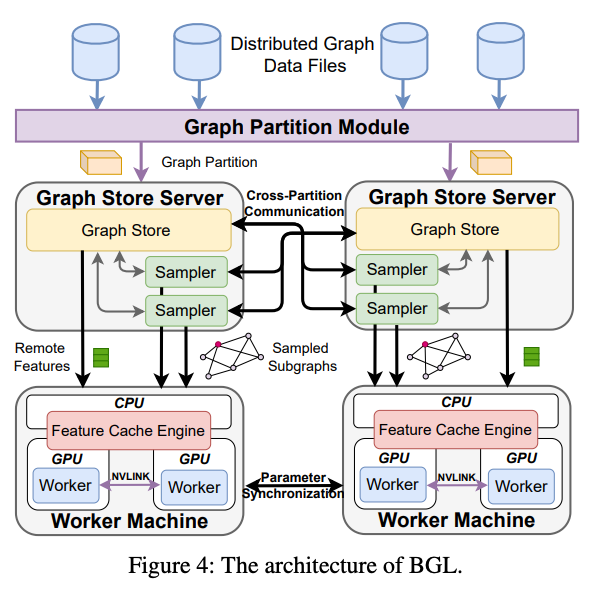 ?標(biāo)題:Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training
?標(biāo)題:Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training作者:Jie You, Jae-Won Chung, and Mosharaf Chowdhury, University of Michigan
>摘要我們觀察到優(yōu)化深度神經(jīng)網(wǎng)絡(luò)((DNN)訓(xùn)練的常見做法通常會(huì)導(dǎo)致能效低下,而能源消耗和性能優(yōu)化之間需要存在權(quán)衡。Zeus是一種優(yōu)化框架,可通過自動(dòng)為重復(fù)出現(xiàn)的 DNN 訓(xùn)練作業(yè)找到最佳作業(yè)和 GPU 級(jí)配置來進(jìn)行權(quán)衡。Zeus 將在線探索-開發(fā)方法與實(shí)時(shí)能量分析相結(jié)合,避免了對(duì)昂貴的離線測(cè)量的需要,同時(shí)適應(yīng)了數(shù)據(jù)隨時(shí)間的變化。評(píng)估表明,Zeus 可以針對(duì)不同的工作負(fù)載將 DNN 訓(xùn)練的能效提高 15.3%–75.8%。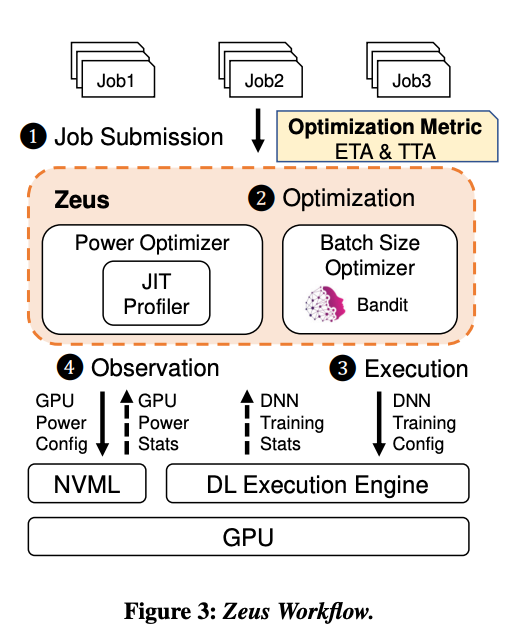
審核編輯 :李倩
-
gpu
+關(guān)注
關(guān)注
28文章
4760瀏覽量
129132 -
可編程
+關(guān)注
關(guān)注
2文章
872瀏覽量
39864 -
網(wǎng)絡(luò)通信
+關(guān)注
關(guān)注
4文章
809瀏覽量
29860
原文標(biāo)題:NSDI '23熱點(diǎn)論文:可編程、RDMA、數(shù)據(jù)中心、GPU有哪些新動(dòng)態(tài)?(附下載)
文章出處:【微信號(hào):SDNLAB,微信公眾號(hào):SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
當(dāng)CPU/GPU遭遇數(shù)據(jù)中心功耗天花板,SDAccel來了
數(shù)據(jù)中心是什么
Mali-Valhall系列GPU可編程內(nèi)核
基于現(xiàn)場(chǎng)可編程芯片的動(dòng)態(tài)下載應(yīng)用研究
可編程SoC(SoPC),什么是可編程SoC(SoPC)
如何利用可編程邏輯實(shí)現(xiàn)數(shù)據(jù)中心互連 DCI互連盒架構(gòu)解讀
可編程邏輯實(shí)現(xiàn)數(shù)據(jù)中心互連

使用Xilinx可編程邏輯實(shí)現(xiàn)數(shù)據(jù)中心互連
可編程技術(shù)在網(wǎng)絡(luò)芯片上的應(yīng)用
可編程時(shí)代下網(wǎng)絡(luò)芯片如何應(yīng)用可編程技術(shù)
Xilinx可編程芯片設(shè)計(jì)首次推出自適應(yīng)計(jì)算加速平臺(tái)
可編程技術(shù)在網(wǎng)絡(luò)芯片的應(yīng)用,可增強(qiáng)網(wǎng)絡(luò)的靈活性
數(shù)據(jù)中心將進(jìn)入完全可編程時(shí)代
展望2024數(shù)據(jù)中心基礎(chǔ)設(shè)施
動(dòng)態(tài)可編程增益放大器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論