 從仿真器的角度理解Verilog語言1
從仿真器的角度理解Verilog語言1
要想深入理解Verilog就必須正視Verilog語言同時具備硬件特性和軟件特性。在當下的教學過程中,教師和教材都過于強調Verilog語言的硬件特性和可綜合特性。將Verilog語言的行為級語法只作為語法設定來介紹,忽略了Verilog語言的軟件特性和仿真特性。使得初學者無法理解Verilog語言在行為級語法(過程塊、賦值和延遲)背后隱藏的設計思想。本文嘗試從仿真器的角度對Verilog語言的語法規則進行一番解讀。
“精分”的Verilog語言
在集成電路的設計流程中,Verilog源文件有兩個主要作用:綜合和仿真。在圖1中,數字①②③④標注的位置都可以使用Verilog作為設計的描述方法。
·綜合工具讀入源文件,通過綜合算法將設計轉化為網表,比如DC。能夠綜合的特性要求Verilog語言能夠描述信號的各種狀態(0,1,x,z)、信號和模塊的連接(例化)以及模塊的邏輯(賦值以及各種運算符)。
·仿真器讀入源文件,生成一個可執行程序用于仿真硬件的行為,比如VCS。能夠仿真的特性要求Verilog語言又具有軟件特性,對每一條語句的執行語義和順序給出定義(延遲語句)。同時,軟件特性使得Verilog語言更加靈活,具備了豐富的行為級仿真能力(條件分支、循環等)。
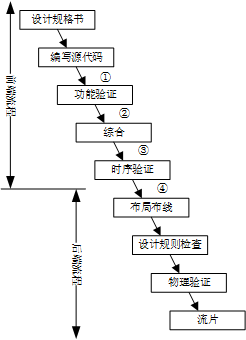
圖1. 集成電路設計流程
為了滿足綜合和仿真的雙重要求,Verilog語言的語法規則必須要同時滿足硬件和軟件的特質。編寫Verilog代碼的時候,不僅需要從硬件的角度去思考這一段代碼會轉換為什么樣的硬件電路,還要從軟件的角度去思考這一段代碼在仿真器如何表現。如此日復一日,隱隱有精神分裂之感。Verilog代碼與硬件電路的關系已經在大量的書籍中得到了充分的論述。本文重點聊一聊從軟件的角度如何理解Verilog。
從軟件的角度理解Verilog并不是要把Verilog看成一種可執行程序,試圖去理解每一條語句對應的語義。如果這樣做,就陷入更深的誤區而不能自拔。很多的語句規則和規定也會變得混亂而不可理解。在試圖從軟件角度理解Verilog語言之前,必須要堅定Verilog是一種硬件描述語言的觀點。
從軟件的角度理解Verilog的本質是理解Verilog語言在軟件仿真器中的行為。Verilog語言本身是不能執行的。實際上,Verilog提供了一套描述硬件電路行為的規范。這套規范的設計與仿真器的設計是相互適應的。仿真器根據Verilog文件產生一個可執行的仿真程序。這個仿真程序才是真正的軟件程序。
在目前的教學過程中,Verilog的硬件特性得到了充分的強調。在開始學習Verilog的第一天,很多同學就會被老師們教育:Verilog描述的是硬件,Verilog不是軟件。這般強調的目標是為了避免大家將Verilog語言與純粹的軟件語言(C,java,python等)混為一談。但是同時也有些矯枉過正。對于Verilog的軟件特性只介紹是什么而不介紹為什么,而且幾乎不涉及仿真器的內容。在講授Verilog語言的時候,也只能含糊地從語義的角度介紹Verilog的各種語法規則。不論是數字電路、集成電路設計等課程都不會給學生介紹仿真器的基本結構和運行機制。
此外,國內長期不重視電子設計自動化(EDA)工具的研究,不重視設計方法學和設計流程的探索和演進,習慣拿來主義。最終導致我國嚴重缺乏EDA專業相關人才儲備。任課教師普遍對工具背后的軟件機制不清楚,也只有避免講Verilog的軟件屬性,才能避免課堂上的尷尬。在這樣的教學方式下,學生很難對Verilog語言甚至HDL語言建立起正確的理解和知識體系。
仿真器基本架構
Verilog語言確實不是一種可執行語言。圖2展示了利用Verilog源文件進行仿真的過程。絕大多數仿真器都遵循這一思路,比如VCS、iVerilog、ModelSim、Vivado和Quartus等。首先,準備Verilog源文件以及一些Verilog庫文件(標準單元等)。仿真器接收這些Verilog文件并將其轉化為可執行的仿真源文件(C/C++等)。在這一過程中,仿真器解析Verilog文件的語法結構,并且根據Verilog語法的規范,將語法結構轉化為仿真器中的事件響應函數或代碼段。這些函數和代碼段與仿真器框架源文件一起成為可執行仿真程序的源文件。接下類這些源文件經過編譯得到可執行的仿真程序。VCS和iVerilog可以看到生成的可執行文件。ModelSim、Vivado和Quartus使用GUI管理設計流程,從而將這個可執行文件屏蔽了,使其對于用戶可透明。用戶可以在工程中找到生成的可執行文件。最后,運行可執行的仿真程序,進行軟件仿真。
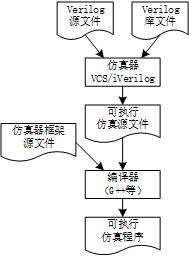
圖2 從Verilog源文件到可執行仿真程序的流程
可執行仿真源文件和仿真器框架源文件一般是不可見的。不過在開源軟件(例如iVerilog)中可以找到生成可執行仿真源文件的代碼。
仿真程序通常采用基于事件的仿真架構。這種仿真架構的核心是事件隊列。事件隊列中按照事件的響應時間排列著一系列的事件。響應時間相同的事件之間不應該有決定性的事件依賴關系。如果需要確定這些事件之間的順序,可以引入Δ時間。響應時間為t+Δ的事件必然晚于響應時間為t的事件。但是從仿真時間上,仍然表現為在相同時刻響應。
事件隊列按照時間先后順序逐個響應事件隊列中的事件。每一個事件,除了標注事件響應時間,還會標注事件類型以及其他需要的參數。通過事件類型,仿真引擎可以找到對應的響應函數。其他的參數則作為事件響應函數的輸入參數。事件響應函數會產生新的事件。這些新的事件還會插入到事件隊列中,并且按照其響應時間排序。
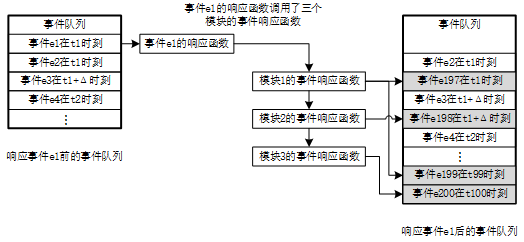
圖3 事件隊列仿真框架的示意圖
圖3展示仿真引擎響應一個事件的過程。仿真引擎響應事件隊列中的第一個事件e1。事件e1被從隊列中移除。事件隊列從事件e2開始。仿真引擎根據e1的類型找到了事件響應函數。這個響應函數又調用了3個模塊中的事件響應函數。這些事件響應函數模擬硬件電路的行為,并且產生了新的事件。模塊1產生了事件e197和e199,分別插入到t1時刻和t99時刻;模塊2產生了事件e198,插入t1+Δ時刻;模塊3產生了事件e200,插入t100時刻。
通過“讀出第一個事件-響應事件-插入新事件”的循環,事件隊列可以一直運行下去,直到事件隊列為空或者達到了仿真結束的時間。另一方面,在仿真開始的時候,必須向事件隊列中插入起始事件,從而開始仿真循環。
Verilog仿真器提供了仿真引擎(在圖2中的仿真器框架源文件部分),所以大家在寫Verilog的時候不用去自己“造輪子”。但是仿真引擎并不知道事件和響應函數的對應關系以及響應函數的具體功能。仿真器的工作就是將Verilog文件轉化為仿真響應函數并且與仿真引擎進行連接。生成的可執行仿真源文件和仿真器框架文件一起構成了完整的仿真器。
接下來,分析一下Verilog的語法結構(過程塊、賦值和延遲)如何變成仿真器的源文件。
過程塊
always過程塊是Verilog最基本的行為級描述結構。通過在always語句中設置敏感列表,可以在恰當的時刻觸發過程塊內的操作。敏感列表中使用的條件主要是信號沿(上升沿、下降沿)以及信號值變化兩種。如果敏感列表有多個條件,這些條件是“或”的關系,也就說只要有一個條件滿足,always過程塊中的語句就會執行一次。
對應到仿真器中,always過程塊的語義就是給仿真中的特定事件綁定響應函數。always過程塊中的語句序列是事件響應函數的函數體,而always語句的敏感列表確定了這個事件響應函數與哪些事件綁定。
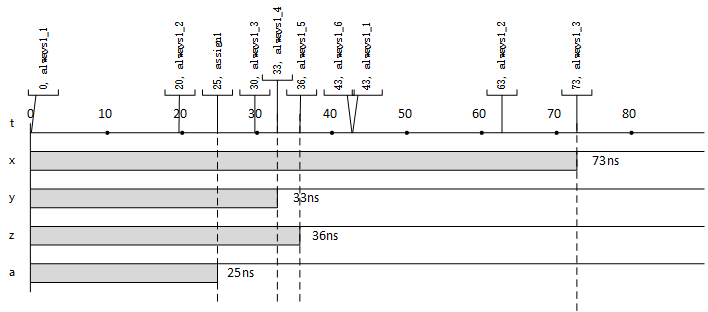
例如下面的D觸發器。
always @ (posedge clk) begin
q <= d;
end
經過仿真器的轉換就變成為如下的響應函數:
function always_block1 :
q = d;
這個響應函數會與clk信號的上升沿事件(positive)進行綁定。當響應clk信號的上升沿事件的時候,仿真器會調用always_block1這個函數。
一個條件可以被綁定多個事件響應函數。比如時鐘信號的事件可以與所有的always塊的事件響應函數綁定。當時鐘信號的事件發生的時候,與其綁定的事件響應函數會逐個被調用。如果一個信號在多個always過程塊中都被賦值,那么一個變量會被多個事件響應函數修改。在硬件上,這些響應函數之間應該是并發的,沒有先后關系。但是,串行執行函數的軟件是做不到的這樣的并發的。在仿真器中,always過程塊之間也是有順序的。Verilog規定,always塊之間的執行順序是按照always塊在Verilog文件中的先后順序。這僅僅是為了適應軟件仿真器所引入的設定。
如果敏感列表中有多個條件,表示always塊與這些信號都綁定。如果always塊沒有執行敏感列表或者是給出一個星號(*),表示always塊應該與過程塊中所有的右值變量綁定。在這種情況下,由每個事件都直接觸發事件響應函數可能會引起重復響應,即在某個時刻事件響應函數被多次觸發的情況。為了避免這樣的錯誤,仿真器中引入了仿真階段的概念。同一個仿真階段中響應的事件,響應時間必須,而且Δ時間也必須相同。在同一個仿真階段中,每個事件響應信號只能被觸發一次。每個仿真階段中,首先在事件隊列中找到需要響應事件,然后累計需要調用的事件響應函數。最后再依次調用這些事件響應函數。這樣就保證了同一個時間的信號變化只會觸發同一個always過程塊一次。
除了always過程塊,在Verilog中還定義了其他的過程塊。與always過程塊不同,這些過程塊不由信號的事件觸發,而是要單獨在事件隊列上插入事件,并且與過程塊轉化成的響應函數綁定。initial過程塊只在仿真開始的時候執行一次。也就是說,如果定義initial過程塊,那么事件隊列上的第一個事件就是initial過程塊的事件。repeat過程塊和forever過程塊在事件響應函數結束時向電路中添加觸發下一次響應函數的事件。這個事件在下一個Δ時刻就會響應,由此往復。當重復了足夠多次數后,repeat過程塊會停止向事件隊列中添加事件,從而結束repeat語句。forever過程塊的循環不會結束。
賦值語句
Verilog語言提供了阻塞賦值和非阻塞賦值兩種賦值語句。
a = b; // 阻塞賦值
a <= b; // 非阻塞賦值
按照語法定義,阻塞賦值會阻塞之后語句的執行;非阻塞賦值則不會阻塞之后語句的執行。阻塞語句達成的效果是下一條語句執行之前信號a已經變修改。非阻塞賦值達成的效果是,信號a的值只有到整個過程塊執行完,才會被修改。需要注意的是,非阻塞賦值雖然被延后,但是所賦的值仍是之前得到的值。
這一段話著實令人感到疑惑。現在我們從軟件仿真器的角度重新來解析賦值語句。賦值語句其實包含兩個過程:評估和更新。評估過程確定了需要賦給信號的值,而更新過程才真正的修改了信號的值。評估過程和更新過程是相互獨立的。這兩個過程中的關聯只有需要賦的值。
阻塞賦值的評估過程和更新過程是連續執行的,評估之后立即更新。所以,在執行下一條語句的時候,信號已經被修改了。在轉換成仿真器代碼時,阻塞賦值不需要特殊處理。例如
always @(a, b, c) begin : add_mux1
t = a + b;
d = t * c;
end
上述代碼轉化后的事件響應函數為
function add_mux1 :
t = a + b;
d = t * c;
非阻塞賦值的評估過程和更新過程是分開的。過程塊中執行到賦值語句的時候,只進行了評估過程,確定需要賦給信號的值,然后繼續向后執行。更新過程被延后到整個過程塊執行之后。例如
always @(a, b, c) begin : add_mux2
t <= a + b;
d <= t * c;
end
上述代碼轉化后的事件響應函數為
function add_mux2 :
t_update = a + b;
d_update = t * c;
t = t_update;
d = d_update;
當阻塞賦值和非阻塞賦值混合的時候,也遵循同樣的規則。例如
always @(a, b, c) begin : add_mux3
t <= a + b;
d = t * c;
end
上述代碼轉化后的事件響應函數為
function add_mux3 :
t_update = a + b;
d = t * c;
t = t_update;
對信號的賦值會產生一個事件,事件表示被賦值的信號發生了變化。如果有其他的過程塊依賴于被賦值的信號,那么這個事件會被添加到事件隊列中;反之,這個事件會被忽略。事件的響應時間為當前時間加Δ。賦值語句是仿真引擎能夠持續運行的關鍵。大部分always塊都是通過賦值語句向事件隊列添加新的事件的。
-
仿真
+關注
關注
50文章
4082瀏覽量
133607 -
軟件
+關注
關注
69文章
4944瀏覽量
87491 -
Verilog
+關注
關注
28文章
1351瀏覽量
110100
發布評論請先 登錄
相關推薦
Verilog語言中阻塞和非阻塞賦值的不同
明德揚至簡設計法--verilog的綜合器和仿真器
5 1仿真器
Aldec 多語言仿真器鎖定主流用戶
模擬/混合信號仿真器
VERILOG仿真器
Verilog硬件描述語言參考手冊免費下載

使用Vivado仿真器進行混合語言仿真的一些要點

從仿真器的角度對Verilog語言的語法規則進行解讀
解碼國產EDA數字仿真器系列之二 | 如何實現全面的SystemVerilog語法覆蓋?





 工商網監
工商網監
評論