 百度飛槳PP-YOLOE ONNX 在LabVIEW中的部署推理(含源碼)
百度飛槳PP-YOLOE ONNX 在LabVIEW中的部署推理(含源碼)
前言
PP-YOLOE是百度基于其之前的PP-YOLOv2所改進的卓越的單階段Anchor-free模型,超越了多種流行的YOLO模型。如何使用python進行該模型的部署,官網已經介紹的很清楚了,但是對于如何在LabVIEW中實現該模型的部署,筆者目前還沒有看到相關介紹文章,所以筆者在實現PP-YOLOE ONNX 在LabVIEW中的部署推理后,決定和各位讀者分享一下如何使用LabVIEW實現PP-YOLOE的目標檢測。
一、什么是PP-YOLO
- PP-YOLOE官方代碼地址:https://github.com/PaddlePaddle/PaddleDetection
- PP-YOLOE論文地址:https://arxiv.org/pdf/2203.16250.pdf

PP-YOLOE是百度基于其之前的PP-YOLOv2所改進的卓越的單階段Anchor-free模型,超越了多種流行的YOLO模型。PP-YOLOE,有更高的檢測精度且部署友好。
PP-YOLOE基于anchor-free的架構,使用強大的backbone和neck,引入了CSPRepResStage,ET-head 和動態標簽分配算法TAL。針對不同應用場景,提供了不同大小的模型。即s/m/l/x,可以通過width multiplier和depth multiplier配置。PP-YOLOE避免了使用諸如Deformable Convolution或者Matrix NMS之類的特殊算子,以使其能輕松地部署在多種多樣的硬件上。
PP-YOLOE-l在COCO test-dev2017達到了51.6的mAP, 同時其速度在Tesla V100上達到了78.1 FPS。
PP-YOLOE提供了一鍵轉出 ONNX 格式,可順暢對接 ONNX 生態。本文主要實現百度PP-YOLOE ONNX 在LabVIEW上的部署推理。
二、環境搭建
1、部署本項目時所用環境
- 操作系統:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- AI視覺工具包:techforce_lib_opencv_cpu-1.0.0.73.vip
- onnx工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.16.vip【1.0.0.16及以上版本】
2、LabVIEW工具包下載及安裝
- AI視覺工具包下載與安裝參考:
https://blog.csdn.net/virobotics/article/details/123656523 - onnx工具包下載與安裝參考:
https://blog.csdn.net/virobotics/article/details/124998746
三、模型的獲取與轉化
注意:本教程已經為大家提供了PP-YOLOE的模型,可跳過本步驟,直接進行步驟四-推理。若是想要了解PP-YOLO的onnx模型如何獲取,則可繼續閱讀本部分內容。
PP-YOLOE并沒有直接提供onnx模型,但是我們可以通過paddle2onnx實現onnx模型的導出。
1、安裝paddle
- PPYOLO需要使用百度paddle框架,我們打開百度飛槳官網:https://www.paddlepaddle.org.cn/,在下方的快速安裝選擇適合自己版本的paddlepaddle

- cmd中執行以下命令安裝:
python -m pip install paddlepaddle-gpu==2.3.1.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
2、安裝依賴的庫
- 從github上下載PaddleDetection并解壓到目錄,下載地址:https://github.com/PaddlePaddle/PaddleDetection ,將paddledetection根目錄添加到環境變量。
- 在PaddleDetection-release-2.4文件夾中打開cmd,輸入以下指令安裝需要的庫
pip3 install -U pip && pip3 install -r requirements.txt
3、安裝pycocotools
pip install pycocotools
若安裝pycocotools時遇到ERROR: Could not build wheels for pycocotools ……,則可以使用以下指令來安裝:
pip install pycocotools-windows
4、導出onnx模型
(1)導出推理模型
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --output_dir=output_inference -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
(2) 安裝paddle2onnx
pip install paddle2onnx
(3) 轉換成onnx格式
paddle2onnx --model_dir output_inference/ppyoloe_crn_l_300e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ppyoloe_crn_l_300e_coco.onnx
至此已成功導出PP-YOLOE ONNX模型
注意: ONNX模型目前只支持batch_size=1
四、在LabVIEW實現PP-YOLOE的部署推理
本項目整體的文件結構如下圖所示,各位讀者可在文章末尾鏈接處下載整個項目源碼。如您想要探討更多關于LabVIEW與人工智能技術,歡迎加入我們:705637299
1、LabVIEW調用PP-YOLOE實現目標檢測pp-yolox_main.vi
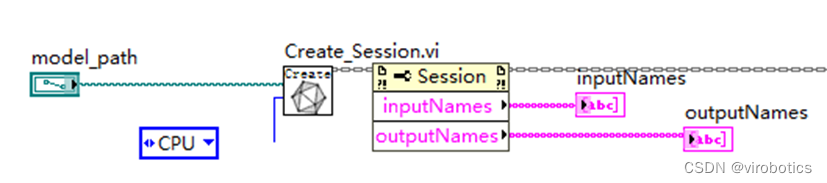
本例中使用LabvVIEW ONNX工具包中的Create_Session.vi載入onnx模型,可選擇使用cpu,cuda進行推理加速。
(1)查看模型
我們可以使用netron 查看ppyoloe_crn_s_300e_coco.onnx的網絡結構,瀏覽器中輸入鏈接:https://netron.app/,點擊Open Model,打開相應的網絡模型文件即可。
查看模型屬性,可看到模型的輸入輸出如下圖所示:
我們發現,該模型有兩個輸入和兩個輸出,所以推理時候需要有兩個輸入,需要用到我們的多輸入處理vi,run.vi
- 可以看到圖片輸入大小為640x640
- 第一個輸出為8400x6[6分別為classese_id,cofidence,框]
(2)實現過程
- 讀取圖片并進行圖像預處理(-1到1的歸一化)
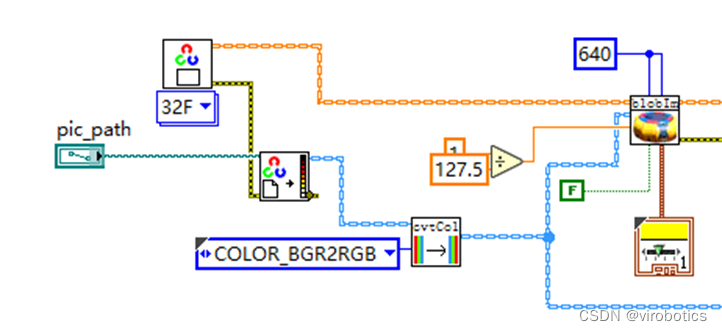
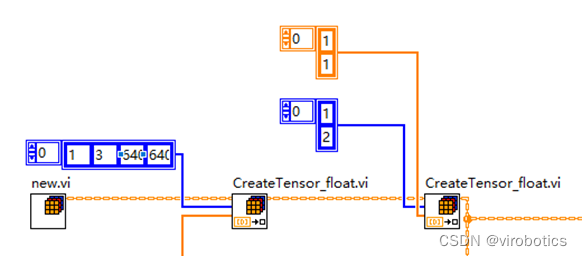
- 初始化一個Vector_Value,新增兩個輸入tensor(圖片及scal_factor)
- 加載模型并選擇加速類型(cpu、CUDA、tensorRt)
- 實現多輸入推理
- 獲取第一層的輸出
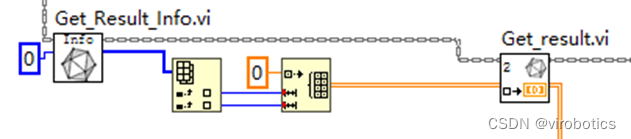
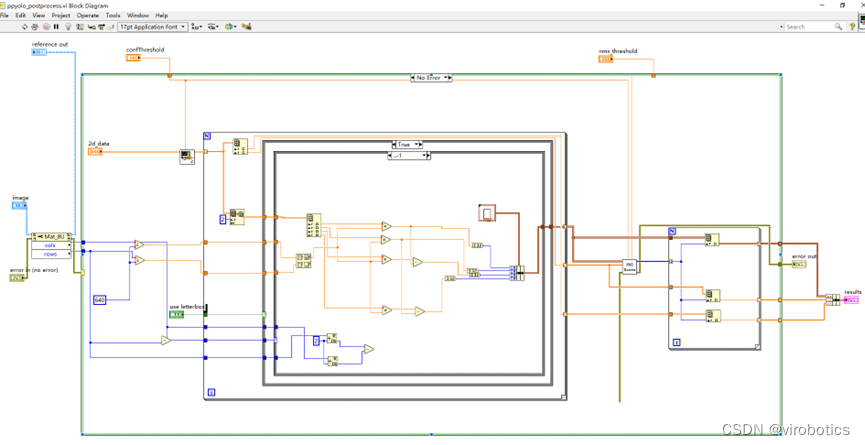
- 進行后處理
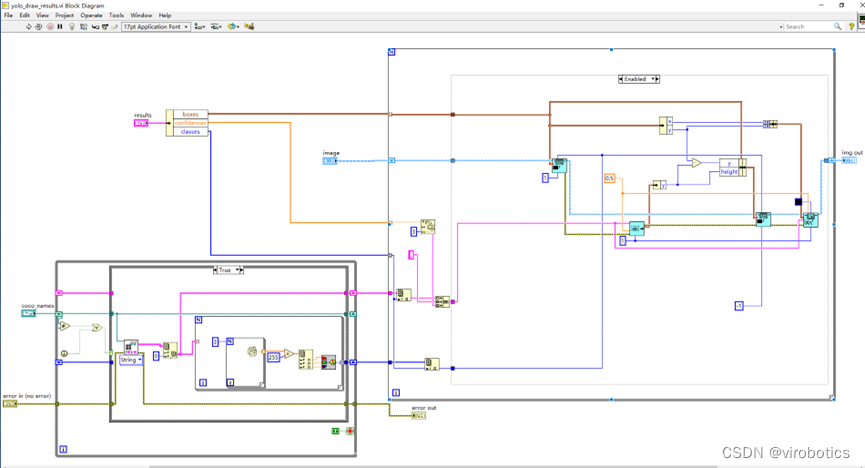
- 繪制檢測出的目標及及置信度
(3)項目運行
配置本項目所需環境。在文章末尾鏈接處下載整個項目源碼,將我們已經轉化好的onnx模型放置到model文件夾中,打開pp_yolo_main.vi,在前面板中修改程序中加載的模型路徑為實際模型路徑,本項目中已經將PP-YOLOE onnx模型【ppyoloe_crn_s_300e_coco.onnx】放置到了model文件夾中,如需其他模型,讀者也可自行放置到model文件及下,實現模型的加載。修改檢測圖片的路徑為實際圖片路徑,運行程序,可得到目標檢測的結果。
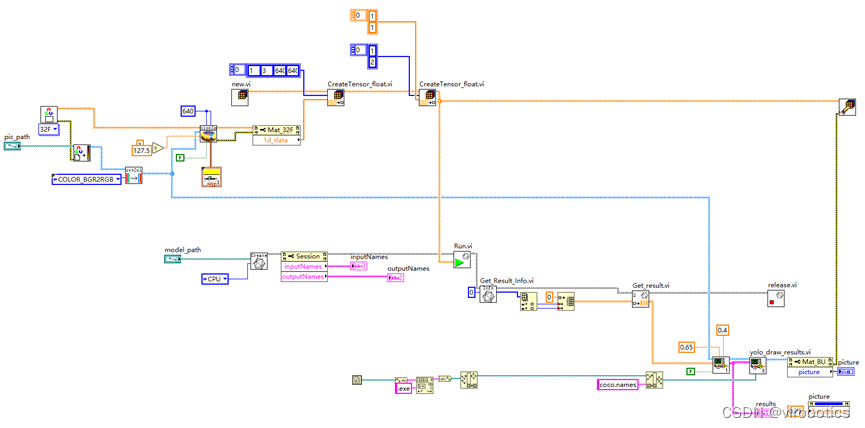
- 主程序源碼如下:
- 運行結果如下:
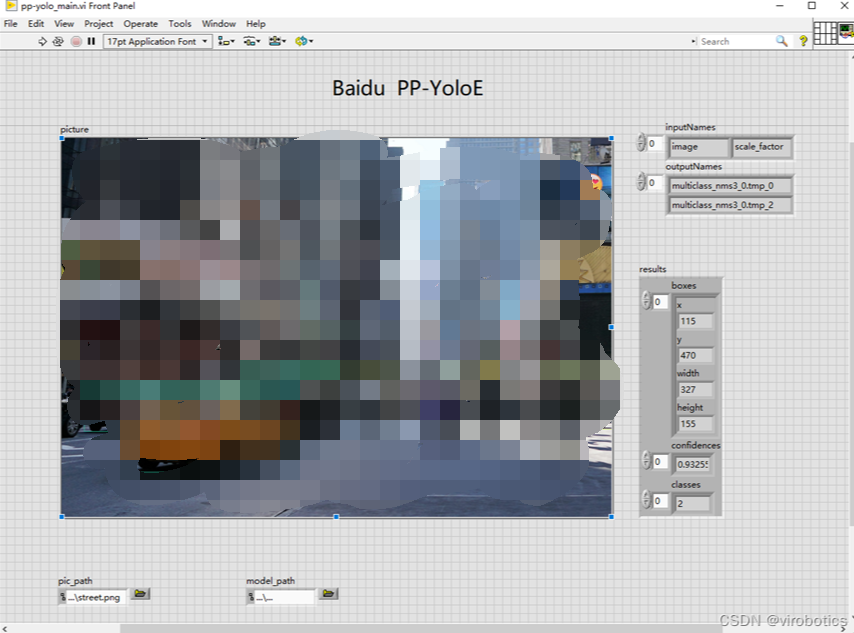
大家也可以檢測其他圖片來測試檢測效果。
2、LabVIEW調用PP-YOLOE實現實時目標檢測ppyolo_camera.vi
實時檢測過程,我們可以選擇使用CUDA實現推理加速,整個程序的實現過程和加載圖片進行檢測基本一致。
(1)LabVIEW調用PP-YOLOE實時目標檢測源碼

(2)LabVIEW調用PP-YOLOE實現實時目標檢測結果

可以看到使用CUDA進行推理加速,速度還是很快的。
五、完整項目下載鏈接
鏈接:https://blog.csdn.net/virobotics/article/details/126231434?spm=1001.2014.3001.5501
總結
以上就是今天要給大家分享的內容,希望對大家有用。如果有問題可以在評論區里討論,提問前請先點贊支持一下博主哦。
**如果文章對你有幫助,歡迎?關注、
審核編輯 黃宇
-
LabVIEW
+關注
關注
1974文章
3656瀏覽量
324279 -
目標檢測
+關注
關注
0文章
209瀏覽量
15632
發布評論請先 登錄
相關推薦
Graphcore攜手百度飛槳 共建全球軟硬AI生態

不是“重復”造輪子,百度飛槳框架2.0如何俘獲人心 精選資料分享
芯微AI芯片加持百度飛槳,攜手加速AI應用落地
Imagination和百度飛槳宣布在全球人工智能(AI)生態系統方面開展合作
百度飛槳在Graphcore IPU上實現訓練與推理全面支持

NVIDIA攜手百度飛槳 共創多元AI開發生態
百度飛槳承辦的WAVE SUMMIT+2022深度學習開發者峰會即將開啟

Imagination人工智能 IP 與飛槳完成 I 級兼容性測試 致力于AI產業化落地
在 NGC 上玩轉新一代推理部署工具 FastDeploy,幾行代碼搞定 AI 部署
圖為科技聯合百度飛槳、英偉達共同推出AI軟硬一體快速部署方案


Imagination+百度飛槳模型部署實戰 Workshop 邀您參加

【報名有獎】Imagination+百度飛槳模型部署實戰 Workshop 邀您參加
Imagination人工智能 IP 與飛槳完成 I 級兼容性測試 致力于AI產業化落地





 工商網監
工商網監
評論