") 分庫分表的21條法則速來碼住(上)
分庫分表的21條法則速來碼住(上)
(一)好好的系統(tǒng),為什么要分庫分表?
還是不著急實(shí)戰(zhàn),咱們先介紹下在分庫分表架構(gòu)實(shí)施過程中,會(huì)接觸到的一些通用概念,了解這些概念能夠幫助理解市面上其他的分庫分表工具,盡管它們的實(shí)現(xiàn)方法可能存在差異,但整體思路基本一致。因此,在開始實(shí)際操作之前,我們有必要先掌握這些通用概念,以便更好地理解和應(yīng)用分庫分表技術(shù)。
我們結(jié)合具體業(yè)務(wù)場景,以t_order表為例進(jìn)行架構(gòu)優(yōu)化。由于數(shù)據(jù)量已經(jīng)達(dá)到億級(jí)別,查詢性能嚴(yán)重下降,因此我們采用了分庫分表技術(shù)來處理這個(gè)問題。具體而言,我們將原本的單庫分成了兩個(gè)庫,分別為DB_1和DB_2,并在每個(gè)庫中再次進(jìn)行分表處理,生成t_order_1和t_order_2兩張表,實(shí)現(xiàn)對(duì)訂單表的分庫分表處理。
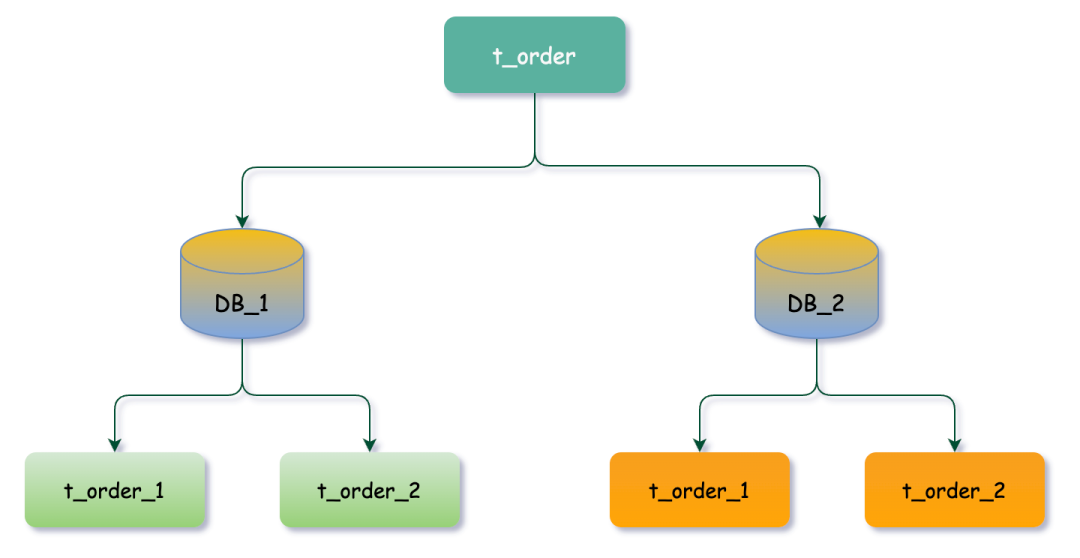
數(shù)據(jù)分片
通常我們?cè)谔岬椒謳旆直淼臅r(shí)候,大多是以水平切分模式(水平分庫、分表)為基礎(chǔ)來說的,數(shù)據(jù)分片它將原本一張數(shù)據(jù)量較大的表 t_order 拆分生成數(shù)個(gè)表結(jié)構(gòu)完全一致的小數(shù)據(jù)量表(拆分表) t_order_0、t_order_1、···、t_order_n,每張表只存儲(chǔ)原大表中的一部分?jǐn)?shù)據(jù)。

數(shù)據(jù)節(jié)點(diǎn)
數(shù)據(jù)節(jié)點(diǎn)是數(shù)據(jù)分片中一個(gè)不可再分的最小單元(表),它由數(shù)據(jù)源名稱和數(shù)據(jù)表組成,例如上圖中 DB_1.t_order_1、DB_2.t_order_2 就表示一個(gè)數(shù)據(jù)節(jié)點(diǎn)。

邏輯表
邏輯表是指具有相同結(jié)構(gòu)的水平拆分表的邏輯名稱。
比如我們將訂單表t_order 分表拆分成 t_order_0 ··· t_order_9等10張表,這時(shí)我們的數(shù)據(jù)庫中已經(jīng)不存在 t_order這張表,取而代之的是若干的t_order_n表。
分庫分表通常對(duì)業(yè)務(wù)代碼都是無侵入式的,開發(fā)者只專注于業(yè)務(wù)邏輯SQL編碼,我們?cè)诖a中SQL依然按 t_order來寫,而在執(zhí)行邏輯SQL前將其解析成對(duì)應(yīng)的數(shù)據(jù)庫真實(shí)執(zhí)行的SQL。此時(shí) t_order 就是這些拆分表的邏輯表。
業(yè)務(wù)邏輯SQL
select * from t_order where order_no='A11111'
真實(shí)執(zhí)行SQL
select * from DB_1.t_order_n where order_no='A11111'
真實(shí)表
真實(shí)表就是在數(shù)據(jù)庫中真實(shí)存在的物理表DB_1.t_order_n。
廣播表
廣播表是一類特殊的表,其表結(jié)構(gòu)和數(shù)據(jù)在所有分片數(shù)據(jù)源中均完全一致。與拆分表相比,廣播表的數(shù)據(jù)量較小、更新頻率較低,通常用于字典表或配置表等場景。由于其在所有節(jié)點(diǎn)上都有副本,因此可以大大降低JOIN關(guān)聯(lián)查詢的網(wǎng)絡(luò)開銷,提高查詢效率。
需要注意的是,對(duì)于廣播表的修改操作需要保證同步性,以確保所有節(jié)點(diǎn)上的數(shù)據(jù)保持一致。
廣播表的特點(diǎn) :
- 在所有分片數(shù)據(jù)源中,廣播表的數(shù)據(jù)完全一致。因此,對(duì)廣播表的操作(如插入、更新和刪除)會(huì)實(shí)時(shí)在每個(gè)分片數(shù)據(jù)源中執(zhí)行一遍,以保證數(shù)據(jù)的一致性。
- 對(duì)于廣播表的查詢操作,僅需要在任意一個(gè)分片數(shù)據(jù)源中執(zhí)行一次即可。
- 與任何其他表進(jìn)行JOIN操作都是可行的,因?yàn)橛捎趶V播表的數(shù)據(jù)在所有節(jié)點(diǎn)上均一致,所以可以訪問到任何一個(gè)節(jié)點(diǎn)上的相同數(shù)據(jù)。
什么樣的表可以作為廣播表呢?
訂單管理系統(tǒng)中,往往需要查詢統(tǒng)計(jì)某個(gè)城市地區(qū)的訂單數(shù)據(jù),這就會(huì)涉及到省份地區(qū)表t_city與訂單流水表DB_n.t_order_n進(jìn)行JOIN查詢,因此可以考慮將省份地區(qū)表設(shè)計(jì)為廣播表,核心理念就是 避免跨庫JOIN操作 。
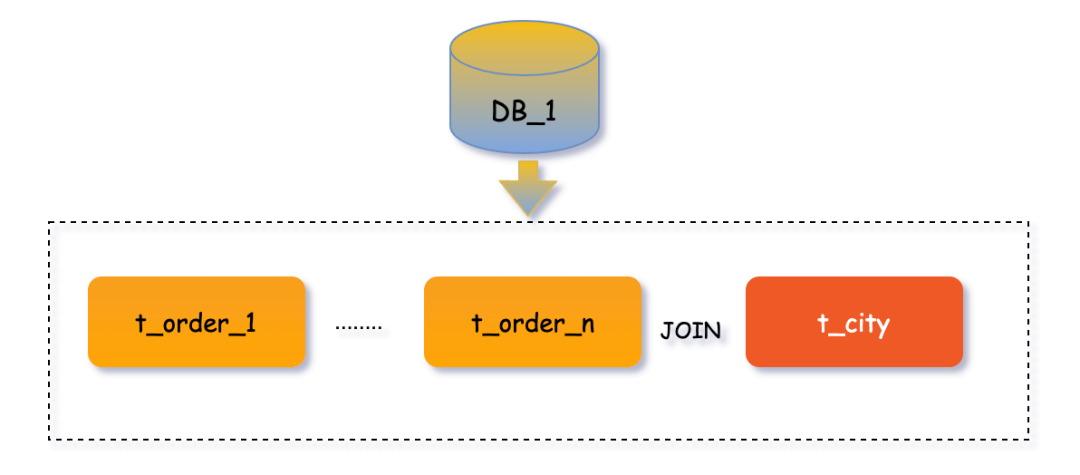
注意 :上邊我們提到廣播表在數(shù)據(jù)插入、更新與刪除會(huì)實(shí)時(shí)在每個(gè)分片數(shù)據(jù)源均執(zhí)行,也就是說如果你有1000個(gè)分片數(shù)據(jù)源,那么修改一次廣播表就要執(zhí)行1000次SQL,所以盡量不在并發(fā)環(huán)境下和業(yè)務(wù)高峰時(shí)進(jìn)行,以免影響系統(tǒng)的性能。
單表
單表指所有的分片數(shù)據(jù)源中僅唯一存在的表(沒有分片的表),適用于數(shù)據(jù)量不大且無需分片的表。
如果一張表的數(shù)據(jù)量預(yù)估在千萬級(jí)別,且沒有與其他拆分表進(jìn)行關(guān)聯(lián)查詢的需求,建議將其設(shè)置為單表類型,存儲(chǔ)在默認(rèn)分片數(shù)據(jù)源中。
分片鍵
分片鍵決定了數(shù)據(jù)落地的位置,也就是數(shù)據(jù)將會(huì)被分配到哪個(gè)數(shù)據(jù)節(jié)點(diǎn)上存儲(chǔ)。因此,分片鍵的選擇非常重要。
比如我們將 t_order 表進(jìn)行分片后,當(dāng)插入一條訂單數(shù)據(jù)執(zhí)行SQL時(shí),需要通過解析SQL語句中指定的分片鍵來計(jì)算數(shù)據(jù)應(yīng)該落在哪個(gè)分片中。以表中order_no字段為例,我們可以通過對(duì)其取模運(yùn)算(比如 order_no % 2)來得到分片編號(hào),然后根據(jù)分片編號(hào)分配數(shù)據(jù)到對(duì)應(yīng)的數(shù)據(jù)庫實(shí)例(比如 DB_1 和 DB_2)。拆分表也是同理計(jì)算。
在這個(gè)過程中,order_no 就是 t_order 表的分片鍵。也就是說,每一條訂單數(shù)據(jù)的 order_no 值決定了它應(yīng)該存放的數(shù)據(jù)庫實(shí)例和表。選擇一個(gè)適合作為分片鍵的字段可以更好地利用水平分片帶來的性能提升。
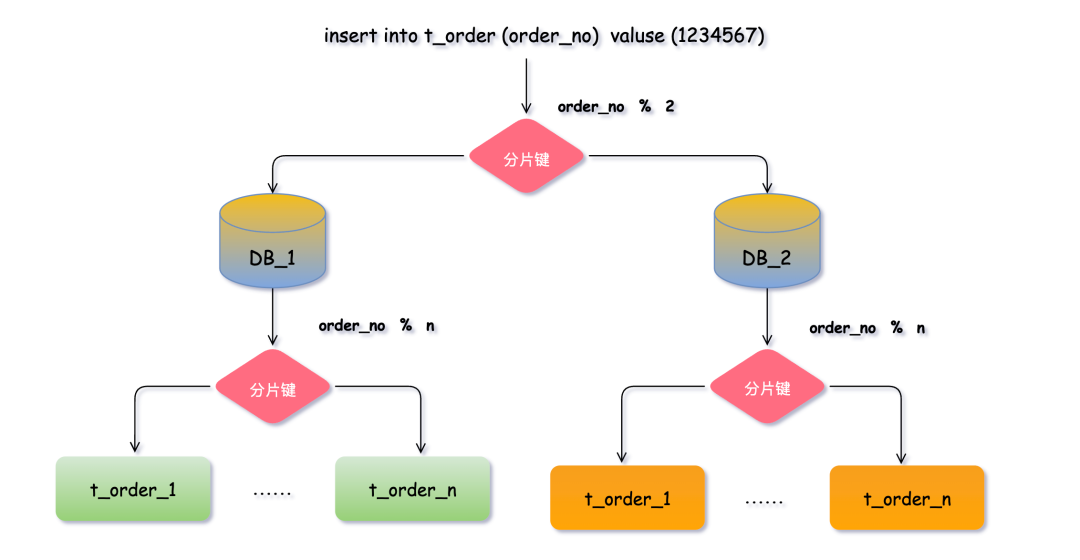
這樣同一個(gè)訂單的相關(guān)數(shù)據(jù)就會(huì)落在同一個(gè)數(shù)據(jù)庫、表中,查詢訂單時(shí)同理計(jì)算,就可直接定位數(shù)據(jù)位置,大幅提升數(shù)據(jù)檢索的性能,避免了全庫表掃描。
不僅如此 ShardingSphere 還支持根據(jù)多個(gè)字段作為分片健進(jìn)行分片,這個(gè)在后續(xù)對(duì)應(yīng)章節(jié)中會(huì)詳細(xì)講。
分片策略
分片策略來指定使用哪種分片算法、選擇哪個(gè)字段作為分片鍵以及如何將數(shù)據(jù)分配到不同的節(jié)點(diǎn)上。
分片策略是由分片算法和分片健組合而成,分片策略中可以使用多種分片算法和對(duì)多個(gè)分片鍵進(jìn)行運(yùn)算。
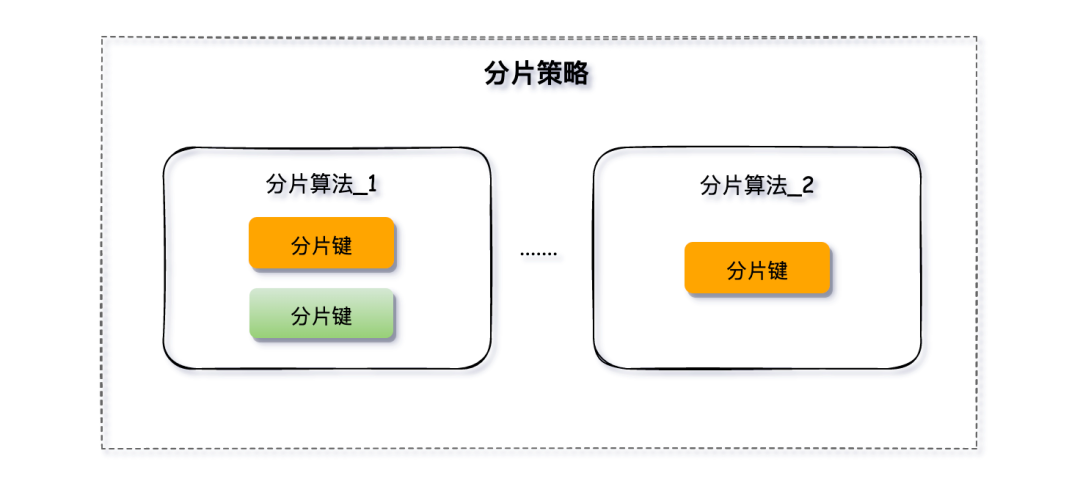
分庫、分表的分片策略配置是相對(duì)獨(dú)立的,可以各自使用不同的策略與算法,每種策略中可以是多個(gè)分片算法的組合,每個(gè)分片算法可以對(duì)多個(gè)分片健做邏輯判斷。
分片算法
分片算法則是用于對(duì)分片鍵進(jìn)行運(yùn)算,將數(shù)據(jù)劃分到具體的數(shù)據(jù)節(jié)點(diǎn)中。
常用的分片算法有很多:
- 哈希分片 :根據(jù)分片鍵的哈希值來決定數(shù)據(jù)應(yīng)該落到哪個(gè)節(jié)點(diǎn)上。例如,根據(jù)用戶 ID 進(jìn)行哈希分片,將屬于同一個(gè)用戶的數(shù)據(jù)分配到同一個(gè)節(jié)點(diǎn)上,便于后續(xù)的查詢操作。
- 范圍分片 :分片鍵值按區(qū)間范圍分配到不同的節(jié)點(diǎn)上。例如,根據(jù)訂單創(chuàng)建時(shí)間或者地理位置來進(jìn)行分片。
- 取模分片 :將分片鍵值對(duì)分片數(shù)取模,將結(jié)果作為數(shù)據(jù)應(yīng)該分配到的節(jié)點(diǎn)編號(hào)。例如, order_no % 2 將訂單數(shù)據(jù)分到兩個(gè)節(jié)點(diǎn)之一。
- .....
實(shí)際業(yè)務(wù)開發(fā)中分片的邏輯要復(fù)雜的多,不同的算法適用于不同的場景和需求,需要根據(jù)實(shí)際情況進(jìn)行選擇和調(diào)整。
綁定表
綁定表是那些具有相同分片規(guī)則的一組分片表,由于分片規(guī)則一致所產(chǎn)生的的數(shù)據(jù)落地位置相同,在JOIN聯(lián)合查詢時(shí)能有效避免跨庫操作。
比如:t_order 訂單表和 t_order_item 訂單項(xiàng)目表,都以 order_no 字段作為分片鍵,并且使用 order_no 進(jìn)行關(guān)聯(lián),因此兩張表互為綁定表關(guān)系。
使用綁定表進(jìn)行多表關(guān)聯(lián)查詢時(shí),必須使用分片鍵進(jìn)行關(guān)聯(lián),否則會(huì)出現(xiàn)笛卡爾積關(guān)聯(lián)或跨庫關(guān)聯(lián),從而影響查詢效率。
當(dāng)使用 t_order 和 t_order_item 表進(jìn)行多表聯(lián)合查詢,執(zhí)行如下聯(lián)合查詢的邏輯SQL。
SELECT * FROM t_order o JOIN t_order_item i ON o.order_no=i.order_no
如果不配置綁定表關(guān)系,兩個(gè)表的數(shù)據(jù)位置不確定就會(huì)全庫表查詢,出現(xiàn)笛卡爾積關(guān)聯(lián)查詢,將產(chǎn)生如下四條SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_no=i.order_no
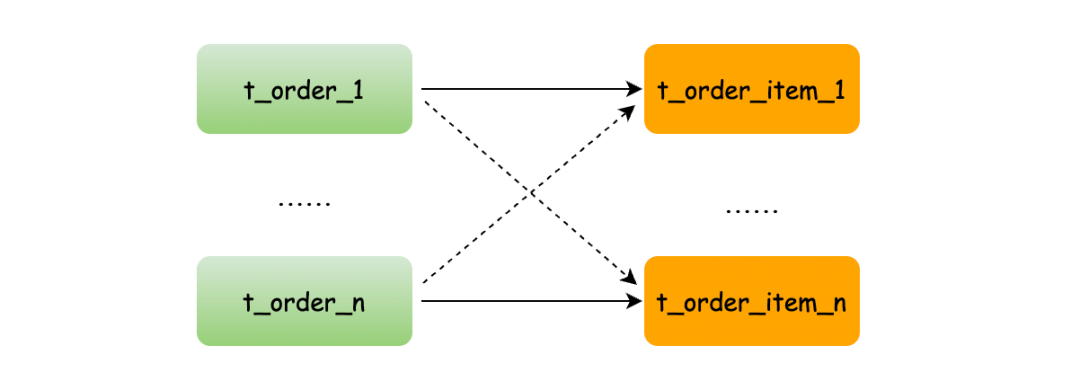
而配置綁定表關(guān)系后再進(jìn)行關(guān)聯(lián)查詢時(shí),分片規(guī)則一致產(chǎn)生的數(shù)據(jù)就會(huì)落到同一個(gè)庫表中,那么只需在當(dāng)前庫中 t_order_n 和 t_order_item_n 表關(guān)聯(lián)即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
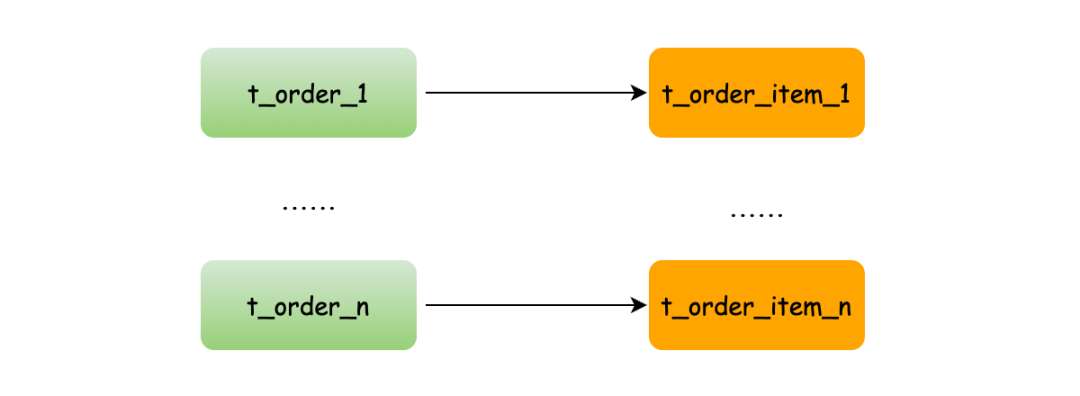
注意 :在關(guān)聯(lián)查詢時(shí)
t_order它作為整個(gè)聯(lián)合查詢的主表。所有相關(guān)的路由計(jì)算都只使用主表的策略,t_order_item表的分片相關(guān)的計(jì)算也會(huì)使用t_order的條件,所以要保證綁定表之間的分片鍵要完全相同。
-
SQL
+關(guān)注
關(guān)注
1文章
766瀏覽量
44164 -
路由
+關(guān)注
關(guān)注
0文章
278瀏覽量
41862 -
架構(gòu)
+關(guān)注
關(guān)注
1文章
515瀏覽量
25491
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
數(shù)據(jù)庫分區(qū)、分庫和分表
談分布式數(shù)據(jù)庫中間件之分庫分表
10條PCB設(shè)計(jì)黃金法則
買大硬盤的6條法則
利用Mycat實(shí)現(xiàn)MySQL讀寫分離、分庫分表最佳實(shí)踐
數(shù)據(jù)庫分庫分表基礎(chǔ)和實(shí)踐
你們知道為什么要分庫分表嗎
優(yōu)化MySQL數(shù)據(jù)庫中樸實(shí)無華的分表和花里胡哨的分庫
你是否知道分庫分表需要哪些要素?
什么是分庫分表?為什么分庫分表?什么情況下會(huì)用分庫分表呢?
PCB布局的十條設(shè)計(jì)法則
分庫分表的21條法則速來碼住(下)
分庫分表后復(fù)雜查詢的應(yīng)對(duì)之道:基于DTS實(shí)時(shí)性ES寬表構(gòu)建技術(shù)實(shí)踐
軟件系統(tǒng)數(shù)據(jù)庫的分庫分表設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論