 【核芯觀察】ChatGPT背后的算力芯片(二)
【核芯觀察】ChatGPT背后的算力芯片(二)
【核芯觀察】是電子發燒友編輯部出品的深度系列專欄,目的是用最直觀的方式令讀者盡快理解電子產業架構,理清上、中、下游的各個環節,同時迅速了解各大細分環節中的行業現狀。以ChatGPT為首的AI大模型在今年以來可以說是最熱的賽道,而AI大模型對算力的需求爆發,也帶動了AI服務器中各種類型的芯片需求,所以本期核芯觀察將關注ChatGPT背后所用到的算力芯片產業鏈,梳理目前主流類型的AI算力芯片產業上下游企業以及運作模式。
接上期ChatGPT背后的算力芯片(一)
AI大模型領域中,用于訓練和推理的AI服務器主要用到CPU、GPU、FPGA、ASIC等這幾類芯片,因此本期主要針對該幾類芯片的細分產業鏈,以及AI服務器整體市場格局做具體的分析。
AI服務器市場格局
根據IDC的數據,2022年全球服務器市場規模1230億美元,同比增長20.0%,預計到2027年全球服務器市場規模將達到1780億美元。中國市場方面,2022年服務器市場規模為273.4億美元。
AI服務器方面,2022年市場規模202億美元,同比增長29.8%,占服務器市場規模的比例為16.4%,同比提升1.2個百分點。在2022年上半年的數據中,浪潮、戴爾、惠普、聯想、新華三分別位居全球AI服務器市場前五,市場份額分別為15.1%、14.1%、7.7%、5.6%、4.7%。
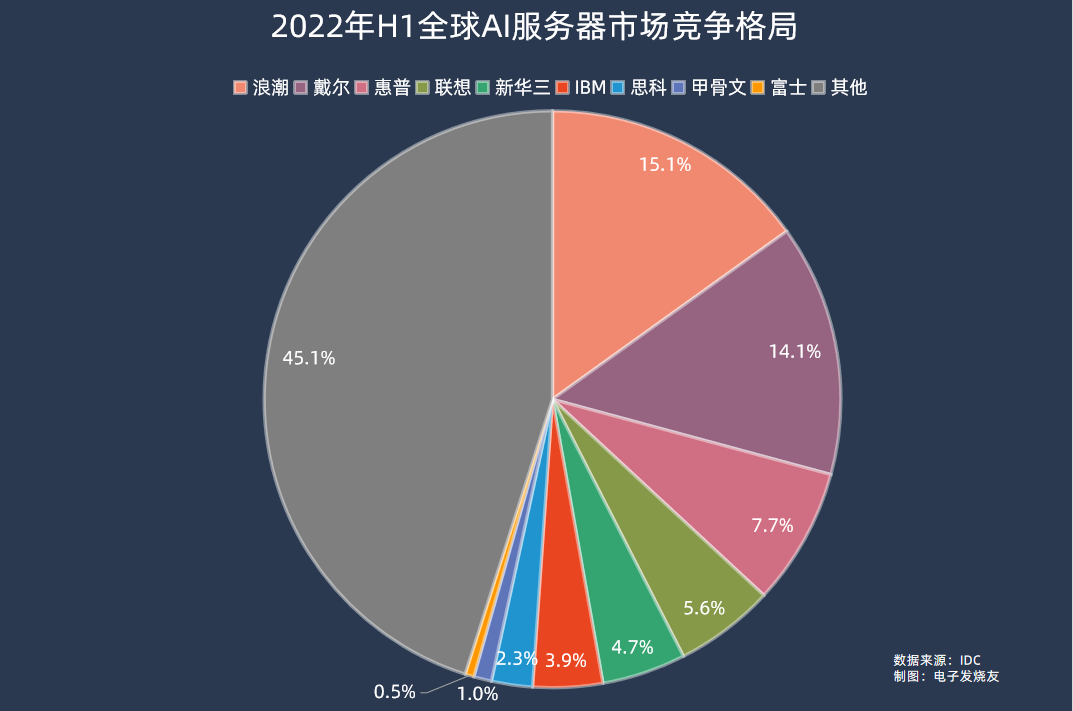
IDC預計,到2026年全球AI服務器市場規模將達到355億美元,對應2022-2026年的復合年均增長率為15.1%。
不過,2023年以來對于AICG大模型訓練和推理的需求開始進入爆發期,相關應用對于AI服務器的部署需求激增,因此AI服務器占到整個服務器市場的比例將穩步上升,AI服務器市場規模在未來幾年的復合年均增長率將有望突破20%。
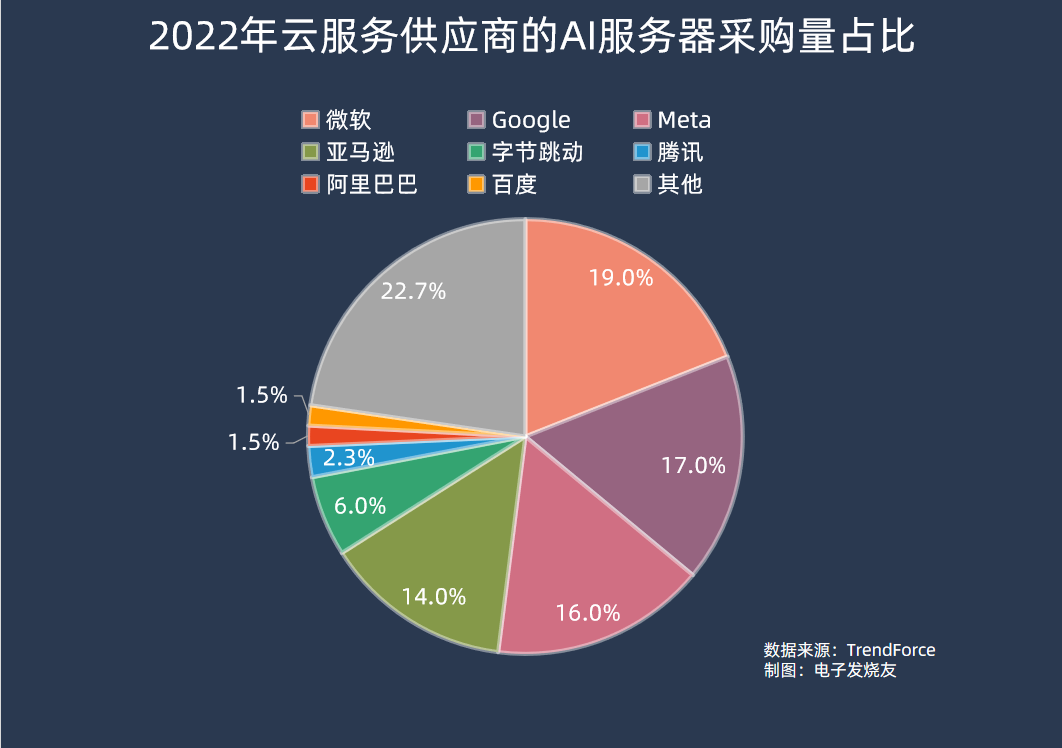
在采購端,集邦咨詢數據顯示,2022年AI服務器采購量中,北美四大云端供應商Microsoft、Google、Meta、AWS合計占比66.2%;而國內廠商方面,字節跳動采購力度最大,占比達6.2%,其余騰訊、阿里巴巴、百度分別占2.3%、1.5%、1.5%。
從當前生成式AI大模型的進展來看,去年在AI服務器采購量中排名較前的公司,部分也是在生成式AI大模型上較為領先的。ChatGPT所屬的OpenAI公司正是由微軟獨家提供云計算支持,而谷歌也有自己的PaLM 2、Meta自家的LLaMA等AI大模型,排名第四的亞馬遜則是傳統云計算大廠。
國內廠商盡管此前也有布局相關的AI大模型技術,不過投入規模普遍較小,直到今年ChatGPT的爆火,可能才真正帶動國內廠商往大規模落地的方向投入,AI服務器采購量也將會在今年有明顯增幅。
AI服務器產業鏈
我們將AI服務器產業鏈分拆成上中下游,上游主要包括三個方面,數據處理(CPU、GPU、FPGA、ASIC)、傳輸(光模塊)、存儲(DRAM、NAND Flash);中游主要是服務器整機供應商;下游則是云服務供應商、互聯網、AI軟件公司等。
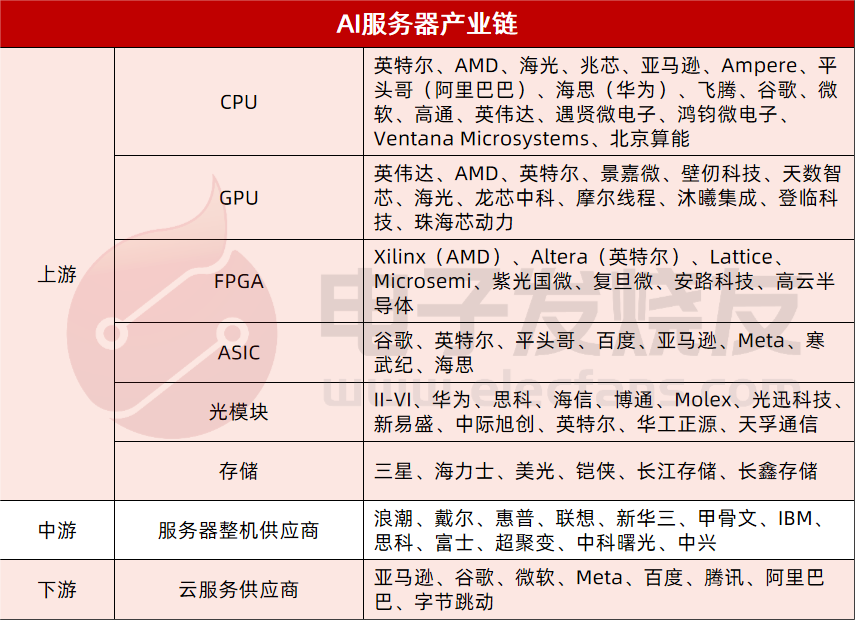
上游
CPU:英特爾、AMD、海光、兆芯、亞馬遜、Ampere、平頭哥(阿里巴巴)、海思(華為)、飛騰、谷歌、微軟、高通、英偉達、遇賢微電子、鴻鈞微電子、Ventana Microsystems、北京算能
GPU:英偉達、AMD、英特爾、景嘉微、壁仞、天數智芯、海光、龍芯中科、摩爾線程、沐曦集成、登臨科技、珠海芯動力
FPGA:Xilinx(AMD)、Altera(英特爾)、Lattice、Microsemi、紫光國微、復旦微、安路科技、高云半導體
ASIC:谷歌、英特爾、平頭哥、百度、亞馬遜、Meta、寒武紀、海思
光模塊:II-VI、華為、思科、海信、博通、Molex、光迅科技、新易盛、中際旭創、英特爾、華工正源、天孚通信
存儲:三星、海力士、美光、鎧俠、長江存儲、長鑫存儲
中游
服務器整機供應商:浪潮、戴爾、惠普、聯想、新華三、甲骨文、IBM、思科、富士、超聚變、中科曙光、中興
下游
亞馬遜、谷歌、微軟、Meta、百度、騰訊、阿里巴巴、字節跳動、
AI服務器中的主要算力芯片之CPU
服務器CPU市場現狀
前文提到,在AI大模型領域中包括訓練和推理兩個不同領域,而訓練和推理所需要進行的操作是不同的。在訓練過程中,AI模型需要進行大規模矩陣運算,在構建神經網絡的過程中需要并行計算能力;在推理的過程中,需要對大量已經訓練好的模型進行實時推理以及預測工作,主要用到的是邏輯控制、串行計算能力,并對響應速度有較高要求。因此更加適合推理和預測的CPU,在推理服務器中的使用量較大。
這從成本分析中也能夠看到,根據IDC的報告,CPU在推理型服務器中的成本占比為25%,在訓練型服務器中的成本占比則僅為9.8%。而在對AI服務器進行推理和訓練工作的負載比例預測中,IDC數據顯示2021年AI服務器用于推理和訓練的負載占比分別是40.9%和59.1%,預測到2025年推理和訓練的比例將變為60.8%和39.2%,也就是說隨著AI大模型的成熟,AI服務器用于推理的比例會越來越高。
那么按照這個數據估算,2021年CPU在整體AI服務器中的成本占比平均約為16%,到2025年這個數字則會上升至19%左右。因此,在整體AI服務器市場高速增長的情況下,CPU需求的增長更是較為可觀的。
目前x86依然是服務器CPU市場的絕對主流,主要的兩家服務器CPU廠商英特爾和AMD在2021年和2022年分別占據服務器CPU市場份額的92.5%和90.6%,不過可以看到隨著Arm架構服務器CPU的崛起,x86架構CPU在服務器市場的份額即將跌破9成。
細分看x86服務器CPU市場,目前是由英特爾和AMD兩大玩家壟斷,當然國內也有海光、兆芯獲得x86永久授權,目前也有推出x86服務器CPU,但性能劣勢較大,市場份額可以忽略。
早在2013年左右,市場就有傳聞稱AMD放棄x86服務器CPU業務,AMD的退出,導致英特爾在x86服務器CPU中出貨量占比一度超過99%。而2017年伴隨Zen架構的EPYC CPU推出,AMD重返服務器CPU市場,并在幾年間快速搶占英特爾原有的市場份額。

Counterpoint數據顯示,2021年英特爾在服務器CPU市場中的份額為80.71%,而到了2022年份額下降至70.77%;另一邊的AMD,2021年在服務器CPU市場中的份額為11.74%,到了2022年份額幾乎翻倍,逼近20%。
另外Arm架構CPU在服務器市場近年來增長迅速。根據Counterpoint的調研,2022年僅亞馬遜以及Ampere兩家的Arm CPU在服務器市場中已經占據4.7%的市場份額,而2021年這兩家的Arm服務器CPU僅有2.9%的份額,盡管基數較小,但同比增速超過60%,顯然未來還有很大增長空間。
目前Arm服務器CPU的玩家眾多,由于自研Arm 服務器CPU能夠帶來效率提升,不少云服務供應商也開始自研Arm CPU。除了前面提到的亞馬遜外,阿里巴巴、華為已經將自研的Arm服務器CPU應用在自家云服務器上,谷歌、微軟等也早有傳聞正在開發自研Arm服務器CPU。
芯片廠商方面,Ampere目前是Arm服務器CPU市場中占比較高的,另外還有英偉達、高通、飛騰等廠商目前推出了Arm服務器CPU產品,國內近年也有遇賢微電子和鴻鈞微電子兩家初創公司正在基于Arm Neoverse N2開發云原生服務器CPU。
另外RISC-V架構的CPU也正在進軍服務器領域,芯片初創企業Ventana Microsystems在2022年12月發布了全球首款面向服務器的RISC-V CPU Veyron V1;北京算能在今年平頭哥玄鐵RISC-V生態大會上發布了首款64核RISC-V服務器處理器SOPHON SG2042。
服務器CPU發展趨勢
CPU目前的發展趨勢主要是圍繞微架構和制造工藝持續升級迭代。以x86服務器CPU的兩大巨頭為例,按照兩家的服務器產品路線規劃圖,一般都會以1-2年為周期進行換代升級,從英特爾數據中心(DCG)業務收入來看,通常新產品上市會帶動相關業務持續2-3個季度的高增長。
縱觀服務器CPU的發展,核心數量是一個較為明顯的變化。2023年1月英特爾發布的第四代Xeon服務器處理器系列中最高定位的W9-3495X配備了56個核心,睿頻為4.8 GHz,L3緩存為105MB,支持112條PCIe通道及八通道DDR5-4800內存。
AMD在2022年年11月發布了最新的第四代EPYC系列服務器CPU,最高定位的9654P配備了高達96個核心,共192線程,最高頻率3.7GHz,L3緩存高達384MB,支持128條PCIe 5.0通道以及12通道DDR5-4800內存。
而在2017年AMD推出第一代EPYC處理器的時候,最多能提供32個核心。不過除了堆核心之外,更重要的是如何實現集成多核心。在第一代EPYC中,AMD就采用了MCM(multi-chip module多芯片模塊)架構,由4個相同的die(晶片)構成一個CPU,單個die包含8個核心加上緩存、Infinity Fabric總線控制器等,也被稱為CCD(Core Complex Die)。在每個CCD中包含2個由核心和緩存組成的CCX(Core Complex)、2個DDR內存控制器、用于CCD間互聯和CPU間互聯的Infinity Fabric總線。
這樣設計的好處是,由于大規模的芯片面積通過多個CCD來達成,所以與相同核心性能下的大型單一芯片相比,盡管面積要大10%以上,但由于小die良率高,制造測試成本大幅降低。以32核CPU為例,采用多CCD設計要比大規模單芯片成本下降40%以上,同時也就更容易做到多核心。
而第二代EPYC中AMD進一步將I/O功能模塊從CCD中剝離出來,單獨做成一個I/O die位于芯片中間,最多可以有8個CCD圍繞I/O die,這也被稱為Chiplet(芯粒),這種做法讓第二代EPYC的CCD數量最高相比一代翻倍。
正是由于多核設計,以及成本上的優勢,Chiplet的設計也成為了當下服務器CPU的一個大趨勢,英特爾在今年的第四代Xeon服務器CPU中也采用了Chiplet設計,按照英特爾的路線圖,未來第五代 Xeon SierraForest更是將會有144個內核。
另一方面是,隨著大數據時代中AI、邊緣計算等場景下網絡數據更加海量,同時還需要更加實時的處理,所以除了使用CPU資源來進行高速協議處理和運算之外,還可以將網卡集成到芯片上,比如CPU、FPGA、ASIC等。于是包含CPU、高性能網絡接口和可編程加速引擎等的芯片被稱為DPU(數據處理芯片)。
通常基于多核CPU的DPU是基于Arm架構的CPU,目前包括英偉達、博通等廠商都在大力推動DPU在數據中心的應用。
AI服務器中的主要算力芯片之 GPU
市場現狀
GPU最初是為了處理計算器圖形或游戲畫面渲染等工作而被開發出來,但由于其高并行計算的特性和處理大規模數據的能力強,也被拓展用于通用計算等領域。
所有目前GPU主要是分成傳統GPU以及GPGPU(通用GPU)兩個領域,GPU主要是為圖像服務,因此內置了多種模塊,包括視頻編解碼加速核心、2D加速核心等;GPGPU則專為專業計算領域服務,相比于傳統GPU,GPGPU削減了圖形處理能力,將其并行計算的能力全部投入到通用計算領域,增加比如專用向量、張量、矩陣運算指令等,著重提升浮點運算的精度和性能,在服務器中作為加速卡,通過CPU協調進行計算,在AI、高性能計算等領域廣泛應用。
今年以來由于生成式AI大模型的火爆,AI服務器中使用到的高端GPGPU產品持續短缺,有企業表示AI服務器價格不到一年時間漲幅近20倍。英偉達A100 GPU市場價格也隨著暴漲,兩個月漲幅高達50%。
在AI服務器中,GPU的使用量相比其他應用的服務器要更高,比如一般的AI服務器單臺會配備2顆CPU以及4-8顆GPGPU,部分高端服務器甚至可以配備16顆GPGPU。而高端GPU的單價較高,因此在AI服務器中的價值量也較高。電子發燒友網推算,GPU在訓練型AI服務器中的成本占比平均超過70%,在推理型服務器中的占比也有25%左右。
按照2021年AI服務器用于推理和訓練的負載占比分別是40.9%和59.1%推算,GPU在AI服務器中的成本占比平均為51.6%,隨著AI大模型訓練的成熟,對訓練服務器需求下降,到2025年這個比例預計會降至42.6%。但可能由于整體服務器規模的提升,依然保持GPU單位數量需求的高速增長。
據Verified Market Research數據,2021年,全球GPU市場規模為334.7億美元,預計2030年將達到4773.7億美元,2021年到2030年的復合年均增長率高達34.35%。
3D Center數據顯示,英偉達在2022年第二季度獨立GPU市場份額為79%,AMD則占20%的市場份額,合計99%。英特爾則憑借在PC端的優勢占據剩下1% 的市場份額。
而在企業細分市場,根據IDC的數據,2021年英偉達的市場份額高達91.4%,AMD份額僅為8.5%,英偉達GPU產品幾乎壟斷企業市場。
國內方面,2021年GPU服務器以91.9%的份額占國內加速服務器市場的主導地位,IDC預計2024年中國GPU服務器市場規模將達到64億美元。
但目前國內市場同樣是以英偉達為主導,國內GPU廠商普遍營收不高,產品市場化處于起步階段。其中國內GPU龍頭景嘉微目前產品主要應用在軍用、信創等領域,民用產品與國際領先水平差距較大。同時自2017年起,國內開始誕生不少GPU初創企業,普遍集中于GPGPU賽道,比如天數智芯、壁仞科技、沐曦集成電路、登臨科技、摩爾線程等,部分產品已經量產,并可應用于AI服務器。
比如去年9月浪潮AI服務器搭載壁仞科技高端通用GPU芯片BR104,在權威AI基準評測MLPerf V2.1的自然語言處理(BERT)和圖像識別(ResNet50)兩項AI任務中取得了8卡和4卡整機的全球最佳性能。
總體來看,國內GPU廠商在AI服務器市場目前競爭力還不足,但隨著美國對高端GPU的出口管制,以及ChatGPT帶動的生成式AI大模型熱潮,國產GPGPU或許會迎來新一輪的發展機會。
AI服務器GPU發展趨勢
GPU用于通用計算的概念最早是在2003年SIGGRAPH大會上首次被提出,隨后的幾年里,業界通過用統一的流處理器取代GPU中原有的不同著色單元的設計釋放了GPU的計算能力,可編程的GPU也就隨之誕生。
后續伴隨線性代數、物理仿真和光線跟蹤等各類算法向GPU芯片移植,GPU由專用圖形顯示向通用計算逐漸轉型。2007年,英偉達首次推出通用并行計算架構CUDA(Compute Unified Device Architecture,統一計算設備架構),正式令GPU作為通用并行數據處理加速器,也就是GPGPU。
CUDA架構對于GPGPU而言意義非凡,進行通用計算無需先映射到圖形API中,大大降低了CUDA的開發門檻,為GPGPU的應用起到了巨大的推動作用,這也為英偉達筑建起了高不可及的生態壁壘。
隨后,GPU的發展就在架構迭代中進行,一般來說,評價一個GPU的性能參數包括微架構、制程、圖形處理器數量、流處理器數量、顯存容量/位寬/帶寬/頻率、核心頻率等等,其中微架構的設計是GPU性能提升的關鍵所在。
GPU微架構(Micro Architecture)是兼容特定指令集的物理電路構成,由流處理器、紋理映射單元、光柵化處理單元、光線追蹤核心、張量核心、緩存等部件共同組成。圖形渲染過程中的圖形函數主要用于繪制各種圖形及像素、實現光影處理、3D坐標變換等過程,期間涉及大量同類型數據(如圖像矩陣)的密集、獨立的數值計算,而GPU結構中眾多重復的計算單元就是為適應于此類特點的數據運算而設計的。
微架構的設計對GPU性能的提升發揮著至關重要的作用,也是GPU研發過程中最關鍵的技術壁壘。以英偉達為例,其最新的H100GPU相比于A100,1.2倍的性能提升來自于核心數目的提升,5.2倍的性能提升則來自于微架構的設計。
除此之外,由于海量數據的需求,GPU的互聯以及顯存帶寬都需要持續提升,包括HBM顯存、英偉達NVLink高速GPU互連技術等,都在快速迭代中。目前最新的NVLink-C2C可以提供處理器與加速器之間高達900GB/s的高帶寬數據傳輸,以及快速同步和高頻更新下的超低延遲性能。最新的HBM 3高帶寬顯存標準則可以提供最高819GB/s的數據傳輸速率,目前英偉達H100、AMD Instinct MI300加速卡已經采用了HBM3標準的顯存。
下一期內容,我們將會繼續對AI大模型中使用到的FPGA、ASIC這些細分領域產業做進一步的分析梳理,記得關注我們~
值得一提的是,電子發燒友網主辦的第七屆人工智能大會將在2023年8月23日正式召開,
在過去的三屆大會中,我們舉辦的“中國人工智能卓越創新獎”評選活動得到了業界的普遍認可和廣泛好評。2023年我們將繼續這一殊榮的評選,舉辦“2023第四屆中國人工智能卓越創新獎”評選活動,旨在發掘和表彰人工智能領域優秀人才、企業、技術以及產品。
“2023第四屆中國人工智能卓越創新獎”獎項提名于即日起到6月30日截至,提名詳情可掃描下方二維碼了解。

-
算力
+關注
關注
1文章
977瀏覽量
14809 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7666
發布評論請先 登錄
相關推薦
AI算力芯片供電電源測試利器:費思低壓大電流系列電子負載

存算一體架構創新助力國產大算力AI芯片騰飛
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
淺析三大算力之異同

從多核到眾核, 賽昉科技RISC-V+NoC IP子系統為算力芯片賦能

揭秘芯片算力:為何它如此關鍵?
【核芯觀察】IMU慣性傳感器上下游產業梳理(二)

【核芯觀察】充電樁上下游產業梳理(二)
高算力芯片:未來科技的加速器?


是德科技智能算力‘芯’技術研討會回顧
ChatGPT算力芯片如何做算力輸出





 工商網監
工商網監
評論