 ChatGPT背后的大模型技術
ChatGPT背后的大模型技術
從去年年底發布以來,ChatGPT 已經被普通民眾和業界廣泛接受,可能是用戶數量增長最快的消費級應用程序。鑒于ChatGPT的技術價值和商業價值,國內已經有不少公司復現了ChatGPT,比如百度、阿里、三六零、華為、MiniMax、商湯、復旦大學邱錫鵬團隊、元語智能、智源。Meta 開源了650億參數的LLAMA,隨后有了各種微調的“羊駝”系列。將ChatGPT復現個七七八八的看起來難度不大,發布之后拿到用戶prompt可以持續優化,想必可以更接近ChatGPT。
由于ChatGPT可以適用于非常多的任務,很多人認為 AI 已經迎來拐點。李開復將此前的 AI 定義為 AI 1.0,此后的AI定義為AI 2.0。AI 1.0 中模型適用于單領域,AI 2.0 中模型普適性增強,一個模型可以適合多種任務和場景。在 AI2.0 中基礎的大模型(foundation model)是核心技術。
由于有了不少公司發布了類ChatGPT產品以及開源的“羊駝”系列,當前大眾對于ChatGPT的發布已經沒有之前那么期待,ChatGPT 熱潮也會過去,但是背后的大模型技術還將繼續發展并發揮巨大作用,并且會跨越領域/學科,不再局限于CV/NLP/ML,會按照AI獨有的特點發展。本文旨在探討ChatGPT背后的大模型技術以及未來的展望。相關應用、生態等方面后面有時間再聊。
大模型 (foundation model)簡述
深度學習領域的研究人員有個愿景,就是用神經網絡模擬人腦,讓一個神經網絡可以完成多種任務。這里面包含至少兩層意思:一是模型要大,因為人腦的神經元和連接比較大,遠大于存在過的網絡模型;二是需要神經網絡基本不用微調就可以完成多種任務的能力,也即是網絡要普適。科研上,這兩個方面一直有在嘗試。
Andrew Ng 的團隊在2012年嘗試了利用CPU集群增大神經網絡參數量[1],利用無監督的方式來訓練了 sparse anto-encoder 網絡,優化器采用的是異步SGD,也采用了模型并行。Andrew Ng 團隊發現在訓練好的模型中有些神經元具有人臉檢測、身體檢測、貓臉檢測的能力,從模型得到的特征也更好。同年,Geoffrey Hinton 帶領 Alex Krizhevsky 和 Ilya Sutskever 探索使用 GPU 來訓練一個 CNN 神經網絡(稱為AlexNet),訓練方式為有監督訓練,網絡參數為60M,大幅度提高了 ImageNet 數據集上的分類準確率。準確率比第二名高10個點。AlexNet 的成功驗證了大量數據 + 深度學習 + GPU訓練的價值,這也開啟了深度學習的時代(但是深度學習的起始點一般認為是2006年Hinton那篇用神經網絡做維度規約的論文[6])。Andrew Ng 和 Geoffrey Hinton 采用的分布式優化、無監督訓練以及GPU訓練加速的技術路線后面被繼續發揚光大。
AlexNet 之后,TensorFlow、PyTorch 加速了深度學習的發展速度。在深度學習時代網絡結構、訓練方式、基礎設施方面都有了很大的發展。在網絡結構方面,出現了基于注意力的 Transformer 網絡,這個網絡比較普適,NLP、CV領域都得到了廣泛的應用,為大模型提供了統一的模型;在訓練方式方面,出現了MLM、MIM、MAE等等更好的無監督/自監督學習方式,為大模型利用大量數據提供了可能;在基礎設施方面,deepspeed[3][4]、Megatron-LM[2] 等也發展成熟,為大模型的有效訓練提供了可能。
借助 deepspeed 和 Megatron-LM,后面不少模型借助這些基礎設實現了“大”,比如 BERT 等。這些大模型為理解類的大模型,也就是針對分類、emb等任務設計的。對于這類模型,模型參數多,意味著理解能力更強,performance 更好。由于這類模型不能在任務維度上泛化,一般的使用方式是在大量數據上預訓練,然后下游任務數據上微調來使用。也有些模型往“統一”更多任務/模態的方向努力, 比如 BEiT3、Pix2seq。GAN、Stable Diffusion 系列可以在給定文本描述作為提示詞,生成和提示詞描述匹配的圖像。但是真正做到在任務維度具備推廣能力只有GPT。為了在任務維度上泛化,需要做到讓模型感知到不同的任務,并且以期望的形式輸出想要的結果。這個可能只有基于 In-Context Learning (ICL) 的生成式大模型可以做到。ICL 在GPT-2中使用但是在GPT-3中被定義。在ICL中,和任務有關的信息放在前綴(即context)中,模型預測給定context之后的期望的輸出。基于這個范式,可以將多種任務用同一個形式表達。只需要將期望完成的任務體現在context即可。文生圖以及理解類的模型也可以做的很大,但是執行任務比較單一,本文暫時討論“大而普適”的模型。
當前 ChatGPT 火的一塌糊涂,讓人看到了AGI的曙光,它也拉開了 AI 2.0 的序幕。ChatGPT 的熱潮也會過去,但是背后的大模型技術會繼續發展,大模型的能力還是進一步提升,本文展望一下后續技術上的發展展望。
技術上的發展展望
ChatGPT 當前已經具備非常多的能力,比如摘要、(文檔)問答、輸出表格、使用工具、理解輸入的圖像。在很多傳統 NLP 任務上表現也很好,比如 parsing、關鍵詞提取、翻譯,也可以非常好的理解人的意圖。ChatGPT 已經成為一個執行自然語言指令的計算機。有些任務,比如獲取日期、符號計算、圖像上的物體檢測等,當前 ChatGPT 不太擅長,為了拓展 ChatGPT 的能力,OpenAI 已經基于GPT搭建基于插件的生態系統。讓ChatGPT可以調用插件來完成這些任務。在此應用場景下(如下圖所示),ChatGPT 已經成為大腦,它負責和用戶交互,并將用戶的任務分解、調用專用API來完成,然后返回結果給用戶。這樣人就可以不用直接操作API,可以極大降低人使用AI能力的門檻。這種方式會是未來GPT非常重要的應用形式。我們以這樣的應用方式來討論這種通用大模型能力可能的發展以及與其他領域結合的展望。
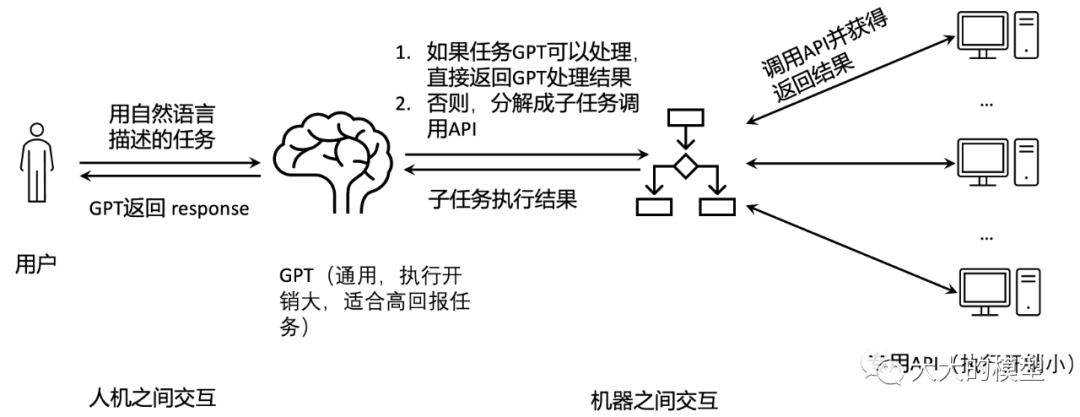
GPT 類型大模型自身能力提升
對于GPT類型大模型的研究,基本成為一個針對一個新型計算機的研究,包含如何增加新型能力的研究以及一些理論基礎的研究等。基本上是需要提升大模型的“智商”,讓它可以更好的執行更多、更高級的任務。總體上,需要提升的能力是能提現“智商”方面的能力,比如知識、語言、推理、規劃、創新等等方面。
GPT 模型的理解和改進
對 GPT 的理解包含模型的理解以及使用方式的理解,即 transformer 結構的理解和ICL的理解。
Transformer 模型的理解和改進
由于 transformer 本質上已經成為一個執行自然語言任務的計算機,很自然的問題是為什么transformer 可以做到這一點,基于transformer的 ICL 本質上是在做什么。
在[13]中,deepmind提供了一個工具 Tracr,可以將用RASP代碼翻譯成 transformer 模型的權重,方便從簡單算法開始分析 transformer 如何實現這些算法。[15]中通過構造證明了 looped transformer可以執行迭代算法。將輸入劃分成 scratchpad、memory 和 instrution 可以幫組理解輸入token在transformer這個自然語言計算機中的作用。對于 GPT 中 transformer 的結構分析和理解也可以參考[24],這是Anthropic公司主導的從 circuits [25] 角度分析 transformer 結構的一系列文章合集。從[7]中我們可以看到,FFN 層可以看做存儲了訓練過程中的知識。由于Transformer 有多個層,每層都是先做 self-attention,然后做FFN。因此 Transformer 可以簡略地看做如下的過程:
在self-attention子層,每個 token 查看所有token信息,并從其他token吸收有用的信息。
在FFN子層,每個 token 從存儲的知識里面吸收有用的知識。
因此 Transformer 大概可以看做一個知識/信息的迭代“加工”過程,并且這里的知識/信息是經過網絡壓縮過的。所以,和真實的計算機體系相比較,如下幾個概念可能會比較重要
Transformer中缺少了數據/指令區分:當前模型里面指令和數據沒有做區分,也就沒有可以調用的子函數等等概念,可能基于 modularity network 的概念探索是值得的。比如是否存在某種regularization,使得網絡自動演化出來指令和數據的區分。
缺少停機概念:當前模型是固定迭代執行L層,有些復雜任務可能需要自適應迭代更多層,從而可以使用更多計算。這種設計可能也值得探索。
memory太小:初步看起來token相當于memory,FFN層和self-attention層知識類似硬盤。但是當前memory太小導致inference時候緩存空間太小,可能再增加一種memory,擴大可使用的 memory 更適合復雜任務。
ICL 的理解和改進
利用 ICL, GPT實際上將 meta learning表達成了監督學習。常規 meta learning 的 outer loop 是不同任務,inner loop 是任務的監督學習,只是是以 next token prediction 形式來統一所有任務的 loss,如下圖所示。這一描述在GPT-3論文中提到,并且定義為:
... “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
根據context中demonstration sample的數量,可以將ICL可以分成三類:zero-shot ICL、one-shot ICL 和 few-shot ICL。
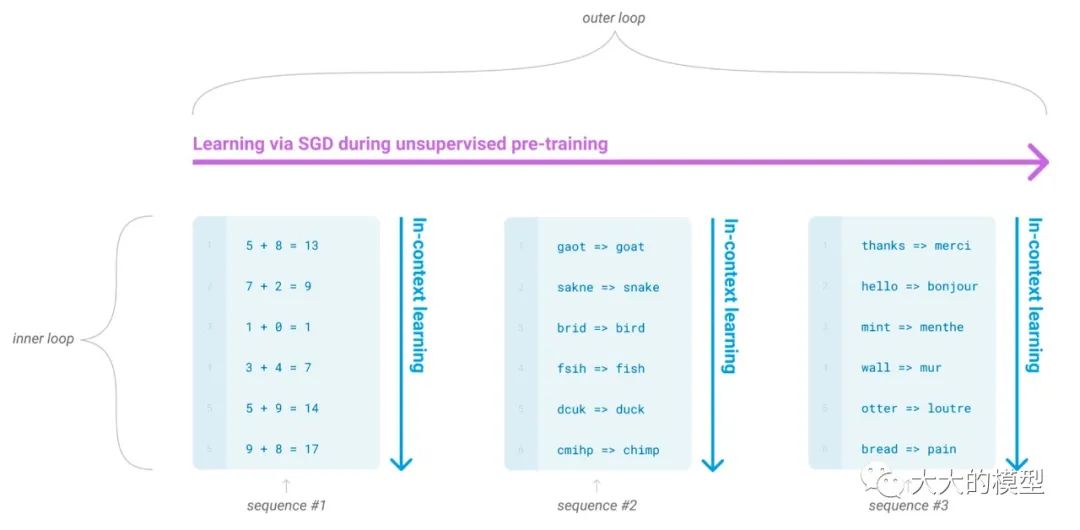
ICL表示為 meta-learning(圖片來源:Language Models are Few-Shot Learners)
基于ICL可以方便的將模型用于多種任務,僅僅是需要將任務需要的信息提供在context中即可。一個令人好奇也比較重要的問題是ICL本質上是在做什么,它的工作機制是什么。這個問題對于模型結構優化、ICL 范式推廣到其他領域有指導意義。
在[11] 中驗證了,Transformer 結構的模型當以ICL的方式訓練,可以發現標準的線性回歸算法。也就是在ICL中提供幾個樣本,訓練好的 Transformer 就可以輸出和用這幾個樣本訓練得到的線性回歸模型來預測相近的結果,也就是在不需要重新訓練 Transformer 的前提下,可以直接輸出期望的結果。在[16] 中證明了,在一些合理的簡化和假設前提下,基于demonstrations 的 ICL 基本可以看做一個 meta optimization 過程,也就是僅僅利用神經網絡的前向過程就可以實現對神經網絡已有參數上的梯度下降。[11] 和 [16] 都是基于 ICL 中有 demonstration 樣本來做的探索。沒有 demonstration 的ICL 可能是利用FFN層存儲的信息來執行類似有 demonstration 的操作。
ICL 的機制理解,尤其是無 demonstration 樣本的工作機制理解對于提升設計更好的prompt以及模型結構優化有幫助。可能需要考慮如何針對ICL優化是 Transformer 模型結構優化的一個可能的切入點。
一些比較有趣的問題列舉如下:
基于ICL范式的智能上限是什么?ICL性能影響因素是設么?基于ICL的數字推理在發展,但是好像基于ICL的規劃,比如下棋、策略、游戲,好像沒有公開的文章討論。是否可以在給GPT游戲規則描述之后,讓GPT學會玩游戲?感覺可以從文字類游戲開始探索。
除了ICL,執行多任務是否有其他范式?
涌現能力的理解和探索
涌現能力是指隨著模型的參數量增大,有些能力突然出現的現象[8]。大模型有些任務指標是可以利用 scaling law 從小模型的訓練結果來預測,比如 ppl。但是有些任務不可以用scaling law 來預測。當前發現的涌現能力可以參考如下的表格。另外,[33]中總結了137個涌現能力。由于有涌現現象的存在,有時候利用小模型來預測大模型的性能是有問題的。
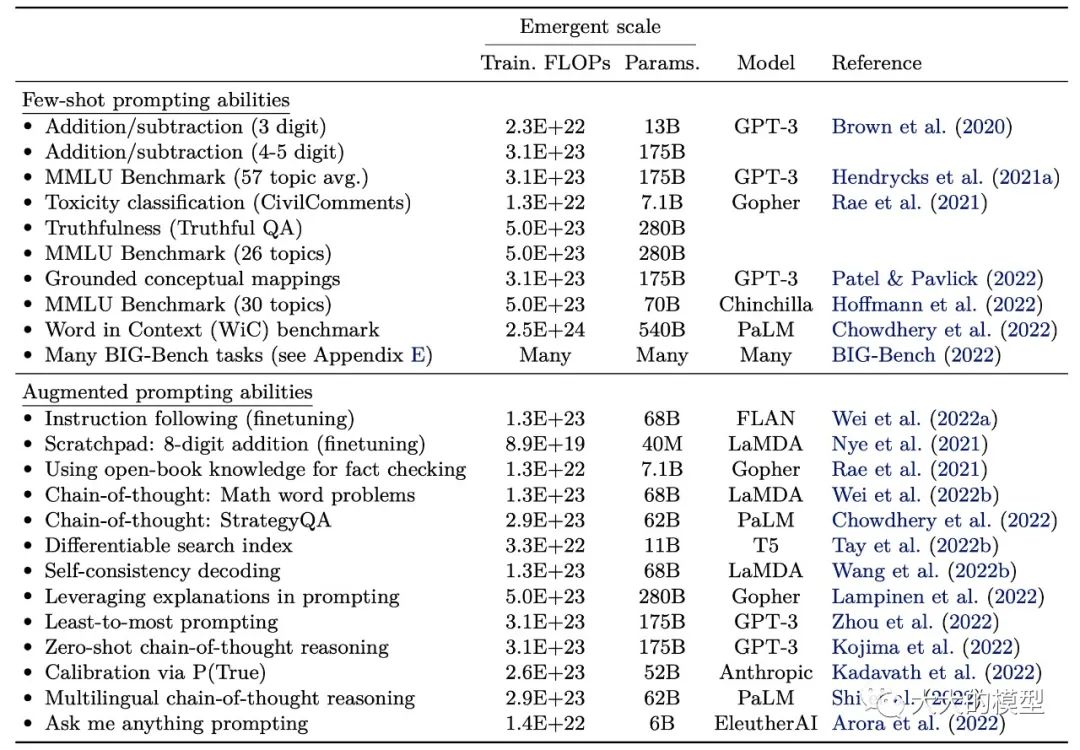
涌現能力舉例(圖片來源:Emergent Abilities of Large Language Models)
智能涌現的原因暫時還沒有得到完美的解釋。但是可以借鑒在簡單問題上的分析來理解涌現能力。比如,[9]中分析了小模型上模加(modular addition)任務上出現的頓悟能力。在這個任務上,訓練過程中測試誤差在訓練過程中會突然下降,也就是泛化能力突然增強,看起來像是神經網絡“頓悟”了。
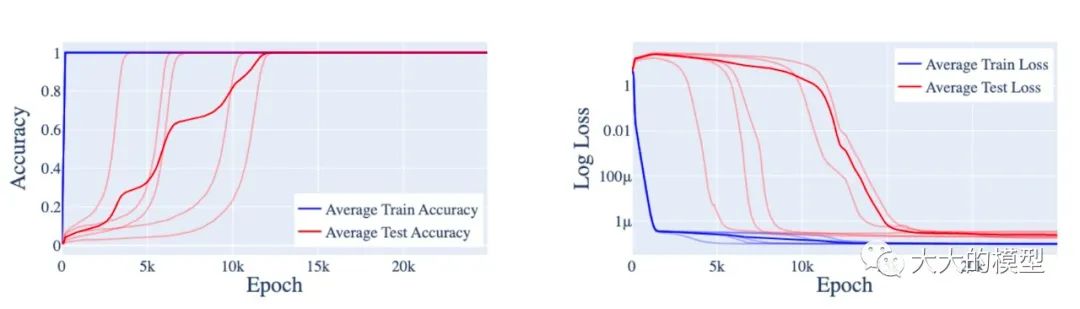
頓悟現象:訓練過程先是過擬合,然后泛化,看起來是模型突然“頓悟”了。(圖片來自:Progress measures for grokking via mechanistic interpretability)
為了解釋這種現象,作者基于逆向實驗分析將訓練大概分成3個階段,分別是memorization, circuit formation, and cleanup。在 memorization 階段神經網絡主要是記住訓練的樣本,在 circuit formation 階段神經網絡主要是形成一些有用的子結構,這些子結構可以提升泛化性能,在 cleanup 階段主要是清理到記憶的訓練樣本。頓悟是發生在 circuit formation 之后。針對大模型的涌現能力,一個可能的猜想是:有用的子結構需要占用比較多的參數,因此需要在模型規模達到一定程度才能出現。更深入和細致的分析可能會帶來模型結構以及訓練正則方面的優化,可能會降低涌現能力需要的最小參數量,讓小的模型也具備當前大的模型的能力。
推理、規劃能力方面的發展
GPT 當前已經具備一定的推理能力,推理能力當前還非常依賴 ICL 里面prompt的內容和形式,尤其是依賴CoT。使用方法還是在prompt里面展示幾個例子給模型,激發模型對于這種類型問題知識提取,以幫助解決問題。當前 Google Brain 的 Denny Zhou對于大模型的推理研究比較多,他們提出了 chain of thought、self consistency 等,也對ICL有一些理論分析。但是 CoT 的存在本身可能說明當前大模型還不太完善。因為訓練數據里面有類似CoT的這些例子。理想一點,模型應該自動“回憶”起來完成這個任務需要的例子,而不是讓用戶輸入。
長遠目標可能是讓大模型具有推理、規劃能力,提升大模型心智能力水平,以使得大模型具備策略類能力。比如為用戶自動規劃行程(尤其是帶有約束條件)、針對某些問題給出策略、將用戶任務分解為插件可以執行的子任務、證明數學定理等,可以極大提升大模型的普適程度。提升推理能力,專門針對代碼問題訓練可能會提升大模型的推理能力,但是這個判斷的依據并未在論文里面找到。
針對推理能力,有趣問題包括 GPT 模型是否具備產生推理能力的基礎、上限在哪里。在 [21][22] 中 Ilya Sutskever 帶領團隊也嘗試利用GPT做定理證明,基于 GPT 的生成模型結果還算可以,暫時還沒有十分驚艷的結果出現,可能原因是定理證明數據偏少,也可能是 GPT 模型自身結構缺乏針對推理的專門設計,比如探索普適性的 value function。上限的探索可能需要更難的任務,比如棋類。理想一點的目標是 GPT 在給定一個新游戲的規則之后,可以快速學會。
多模態方面的發展展望
大腦是多模態的。多模態可以幫助幫助模型理解更快一點。當前已有的多模態GPT有Flamingo、Kosmos-1等,用GPT生成圖像可以參考iGPT[23]。GPT-4已經可以做到理解輸入中的圖像。很多人猜想可能未來會支持在輸出中增加圖像生成的能力。這樣模型的輸入和輸出均為多模態。這個功能可以利用插件支持,并且需要讓GPT模型做到one-step生成高質量圖像也需要做很多優化,可能支持起來不是很容易。收益是支持復雜空間指令等支持。可以將 GPT生成的圖像再用 midjourney 精修。可能在輸入端增加對視頻/音頻的支持性價比更高一點。
當前用一個模型來統一各CV和NLP的各種任務是大的趨勢,基本的框架應該還是基于ICL,用命令去控制執行那個任務。在CV領域,可能難點是如何設計自監督學習方法以及 如何將多種任務統一到 next token prediction 的框架上來。比如Segmentation 任務就不太容易納入到這個框架中。當前已經有工作,比如 SegGPT[31] 和 Segmenta Anything[32] 在朝著用ICL來統一的方向演化。全部任務大一統可能需要一段時間。當前可能會是用ICL逐步統一CV和多模態任務,然后統一到GPT。但是也需要考慮GPT自身能力和被調用API/插件能力的分界面在哪里。把所有東西都放在GPT里面可能不一定是必要的。
學習編程
代碼生成是當前GPT一個比較常見的應用,已有的產品比如copilot,已經可以作為程序員助手。但是
當前用GPT生成code的方法中好像都還沒有使用語言的定義、描述解釋等。對于機器來說,給這樣的信息可能會節省訓練數據。另外,如果可以利用解釋器、編譯器的反饋,讓GPT一直持續學習可能會學會語法。比如把python語言語法定義作為context,讓GPT和python解釋器一直交互,讓GPT在各種算法問題上訓練,可能會生成質量更好的python代碼。長遠一點的目標可能是讓GPT快速學會用常見語言編程解決新問題。
這方面最新的論文是Self-Debug[42](2023-04-11),來自 Denny Zhou 組。做法是用GPT生成代碼的解釋,然后迭代地將代碼逐行解釋、執行反饋送給model生成代碼,直到執行正確。當前暫時沒有使用文法,目標暫時是專門的任務,還不夠通用。
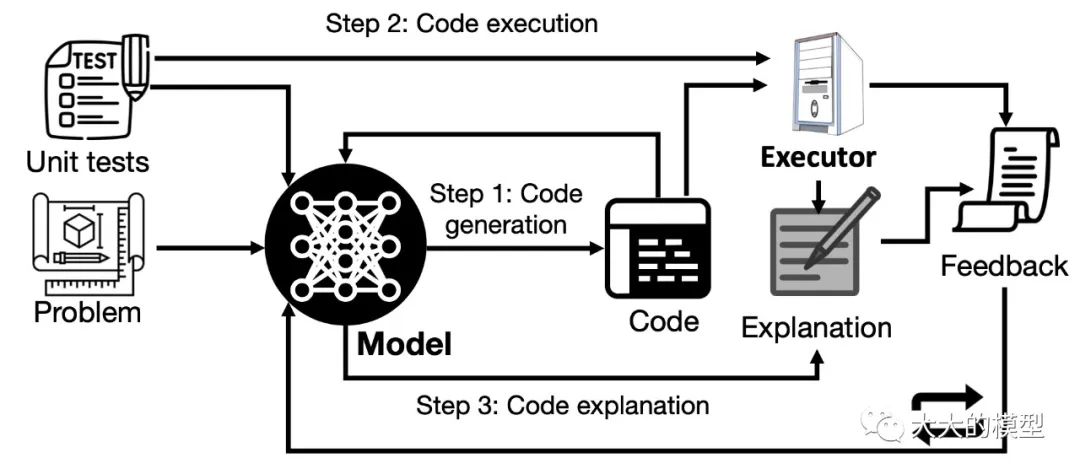
self-debug。圖來自 Teaching Large Language Models to Self-Debug
學習使用外部工具
讓GPT學會使用工具已經是業界正在嘗試的方法[26,27,28,29],openai也在建立了以插件為基礎的生態。可能也會是未來主要的使用方式。HuggingGPT[29]利用特殊設計的 prompt 將用戶輸入的任務分解成已經基于huggingface模型的子任務,以及子任務間的依賴關系。然后 根據依賴關系執行子任務,并用GPT來綜合子任務結果來生成response。TaskMatrix.AI[28]是一個更general的框架,它基于RLHF來對齊GPT和API,對于API數量沒有限制。當前 HuggingGPT 更實用一些。但是未來的應用模式應該是類似TaskMatrix.AI 的模式,因此如何準確地將用戶任務分解成子任務的能力未來更重要一些。
另外最新有意思的項目是babyAGI[43]和AutoGPT[44],留在后面文章討論。
GPT 類大模型的安全問題
當前普遍使用的方式是用3H(Helpful, Honest, Harmless)原則來讓大模型和人的普世價值對齊。這方面Anthropic發表了不少論文。但是在其他方面也存在安全問題。
指令/prompt權限問題
“能力越大,責任越大”,大模型見過的知識可能大于任何一個人,能做出的行為可能也不能做到完全在掌控中。在實際部署的 BING 中,GPT被設置了很多前置prompt,用于約束大模型行為[30]。比如可以用下圖的方法來獲取全部的前置prompt(全部泄露的prompt可以訪問[30])。另外,也會有人嘗試覆蓋這些前置 prompt,這會導致用戶權限提升,引發大模型執行預期之外的行為。當前“如何制作毒品”、“如何制作甲基苯丙胺”這樣的問題是可以被識別并拒絕回答,但是如何通過 prompt 來提升權限繞過已經設置好的限制會是攻擊者比較感興趣的問題。因此,當前大模型已經基本成為一個執行自然預言指令的計算機的前提下,安全方面的問題也可以借鑒傳統計算機里面的安全構架來設計,比如如何設置指令/prompt權限級別,如何限制用戶訪問特權指令/prompt等等。這方面暫時還沒有看到公開論文。
New Bing中導致prompt泄露的攻擊方法。
調用方隱私問題
在員工使用 ChatGPT 的時候非常容易把敏感數據發送到openai的服務器,如果后續用于模型的訓練也可能會被其他用戶“套”出來。比如三星數據泄露事件。由于ChatGPT用于交互的信息顯著多余搜索,因此使用ChatGPT造成的敏感信息泄露風險也遠大于使用搜索引擎。如何保證用戶發送的數據的安全,需要結合密碼學協議。針對大模型的場景,猜測后續可能會出來開放的協議來保證調用者的數據不被服務提供方記錄。
將 ICL 用于其他領域
決策大模型
GPT的思路是基于ICL在任務維度上的推廣,并且生成是文本。但是實際中,很多場景需要的是決策,也就是面對一個場景做出相應的動作。在這方面可能理想一點的情況是給大模型描述好任務規則,候選輸出的動作,讓模型在沒有見過的任務上做出好的決策。這里的難點可能是有些任務規則和達到目標路徑也比較復雜,可能需要先在游戲領域內嘗試,然后推廣到非游戲領域。
Gato [36] 做到了用一個生成式模型來完成多種游戲任務和vision & language 任務。由于context window size 僅僅是1024,對于新任務 Gato采取的方式是微調。
[35] 是大概同時期的工作,也是用transformer來完成多種游戲任務(在41個Atari游戲上訓練)。但是沒有顯式考慮ICL。AdA[37] 是第一個明確用ICL來讓 RL agent 具備快速適應能力(rapid in-context adapataion)的工作。AdA在XLand 2.0環境中訓練,它可以提供個任務。因此 AdA 訓練的任務非常多,這點類似GPT系列的訓練。在完全沒見過的任務上表現比人稍好。當前AdA用的環境和任務還相對實際任務還是比較單一和簡單。在更多復雜任務上訓練之后,可能會更強。到時候可能會有普適的 value 網絡。
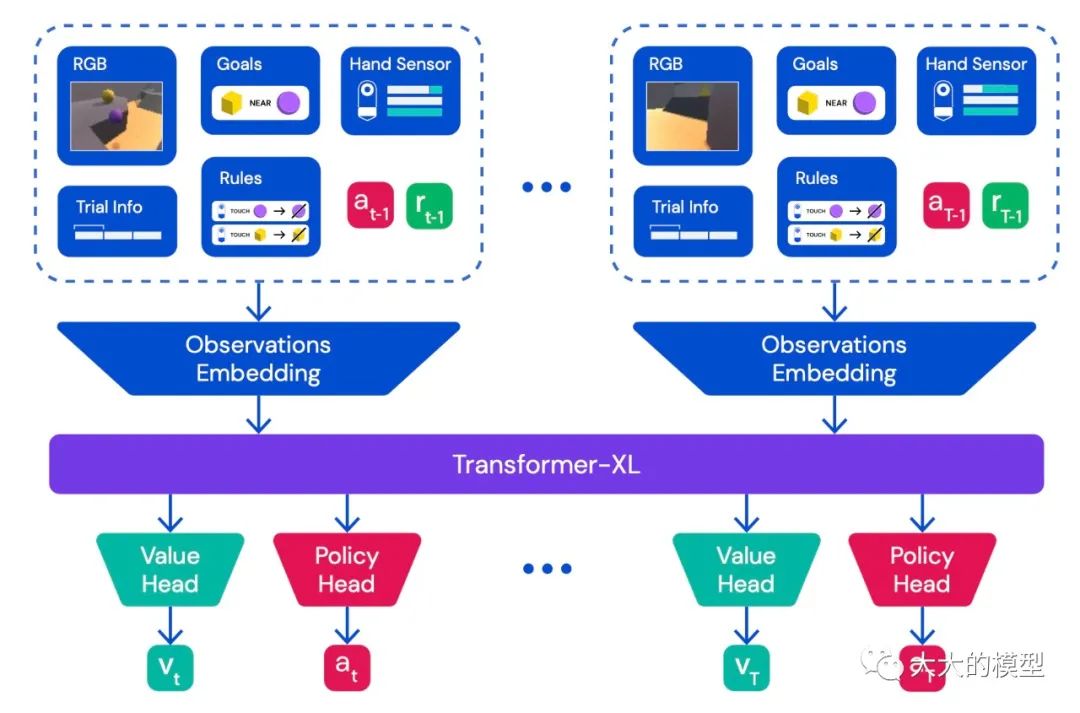
AdA中的agent結構。圖來自:Human-Timescale Adaptation in an Open-Ended Task Space
具身智能
將 GPT和 embodied intelligence 結合并讓GPT裝進硬件中讓GPT可以控制身體執行指令是非常令人向往的嘗試。在這樣的場景下,需要GPT理解多模態輸入,理解指令動作之間的關系,需要具備一定planning能力。在PaLM-e[38]中,使用常見vision & language 數據以及多個機器人操作任務數據訓練模型,機器人具備planning能力。[39]直接用LLM生成code來控制機器人。在具身智能方面,可能讓人激動是可用的人形機器人產品的出現。
總結
ChatGPT帶來了AI模型使用方式的改變,讓人可以用自然語言讓機器執行各種任務變成現實,為AGI帶來了曙光。ChatGPT 改變了人機交互的方式,大大降低了人使用AI的門檻。后面的人類使用機器的方式也可能會變成人和GPT交互,然后GPT負責和其他機器交互。AI能力的提升和新的交互方式的出現,也會激發新的應用方式,改變舊的工作流程,從而帶來新的業務和新的商業機會。比如游戲NPC、虛擬人大腦、GPT律師、GPT醫生、個人助手等等方面。AI的“文藝復興”可能真的要來了。
-
模型
+關注
關注
1文章
3243瀏覽量
48836 -
應用程序
+關注
關注
37文章
3268瀏覽量
57704 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7666
原文標題:參考文獻
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LLM風口背后,ChatGPT的成本問題
ChatGPT背后的算力芯片
科技大廠競逐AIGC,中國的ChatGPT在哪?
不到1分鐘開發一個GPT應用!各路大神瘋狂整活,網友:ChatGPT就是新iPhone
ChatGPT背后的原理簡析
解讀ChatGPT背后的技術重點
ChatGPT實現原理





 工商網監
工商網監
評論