 讓文獻檢索進入AI模式
讓文獻檢索進入AI模式
查閱文獻是進行科學研究的一項基本工作。據統計,科研人員查找消化科學技術資料的時間約占整個科研時間的51%。將文獻制作成一個知識庫或數據庫,使用人工智能方法,減輕科研人員查找和閱讀文獻的“負擔”嗎?5月30日,基于人工智能的科學研究論壇2023中關村論壇正式發布了基于猛犸語言模型+向量數據庫的——science navigator(文獻數據庫)。
這是通過對話提問的方式搜索、閱讀、分析、管理文獻的結果。這一成果由北京科學智能研究院、中國科學院計算機網絡信息中心、墨奇科技共同開發。
說:“在最初的“搜索式”利用“搜索式”搜索引擎和網絡搜索到,以及到目前人工智能技術的跨越式發展,我們大型語言理解和問答模式問題的能力在人類的智能水平接近的首次看見”。墨奇科技副總裁孟卓飛表示,文獻知識庫的發布恰逢搜索模式進入對話時代的發展趨勢。
文獻知識庫的性能優勢可以用多、快、好、節約四個字來形容。孟卓飛介紹,“多”體現在“多模,多模,多數據”中。“快速”意味著“快速質疑,快速引入,快速重復”。“好”體現為“更實時的數據,更可靠的引用,更專業的理解”。“省”是顯著降低了極限系統優化、自身向量算法和數據計算的成本。
文獻知識庫的發展方向是將更多的實驗數據包含在矢量數據庫中。這時,科學實驗的設計原理,實驗方式,實驗結論及結論后對應的思考都可以作為質疑對象。孟卓飛得益于大模型和矢量數據庫科研人員提出方向性問題拆卸機器的問題,將完成提出的設計模擬實驗等一系列程序,可以到內容中得出的結果問題的反省和反復釋放科研人員時間精力在進一步解決關鍵問題和創新的想法。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據庫
+關注
關注
7文章
3842瀏覽量
64547 -
文獻檢索
+關注
關注
0文章
2瀏覽量
1400
發布評論請先 登錄
相關推薦
企業AI算力租賃模式的好處
構建和維護一個高效、可擴展的AI算力基礎設施,不僅需要巨額的初期投資,還涉及復雜的運維管理和持續的技術升級。而AI算力租賃模式為企業提供了一種靈活、高效且成本可控的解決方案。下面,AI
APM32F10xx進入低功耗模式的問題分析
近日,在學習APM32開發板關于PMU模塊的內容,看到很多內容都是調用WFI內核指令進入低功耗模式,于是自己想嘗試調用WFE內核指令進入低功耗模式,但在APM32F10xx中,我運用按

TLV320AIC3106如何在不進行音頻采集或播放時讓芯片進入低功耗模式?
我使用的是TLV320AIC3106我想在不進行音頻采集或播放時讓芯片進入低功耗模式,查閱資料,低功耗相關的是旁路,沒有看懂,請問有了解相關情況的嗎?
發表于 10-10 07:12

軟件系統的數據檢索設計
軟件系統的數據檢索設計 隨著業務量加大,數據檢索量也會日益增多,為了減輕數據庫壓力,本系統采用ElasticSearch來實現數據檢索功能。 簡單來說,Elasticsearch 是一個實時的分布式
如何讓ESP8266變成AP模式?
請問除了smartconfig之外,我想讓ESP8266變成AP模式,再用手機APP與ESP8266對連后由手機輸入家中的路由器的SSID與Password給ESP8266
然后讓ESP8266轉為station
發表于 07-15 08:16
ESP32有時可以進入省電模式,有時不可以進入省電模式,為什么?
測試esp-idf v3.3 中的例子power_save。
發現ESP32有時可以進入省電模式,有時不可以進入省電模式。感覺省電模式很不穩
發表于 06-26 07:14
TC397進入SCR模式的條件是什么?
請問tc397 進入SCR模式, 可以在power down的工況,然后只給EVRSB提供3.3V供電,進入SCR模式嘛? 如果不可以的話,需要怎么實現呢?
發表于 05-31 06:36
stm8l與LIS3DH加速計通過I2C進行通信,是否可以讓STM8L152進入停機模式呢?
最近在用STM8L152調試加速計LIS3DH時,通過I2C通信,加速計后臺監測加速度,如果超過一定閾值則產生外部中斷喚醒單片機,此時我是否可以讓STM8L152進入停機模式呢?該怎么初始化停機
發表于 05-13 08:22
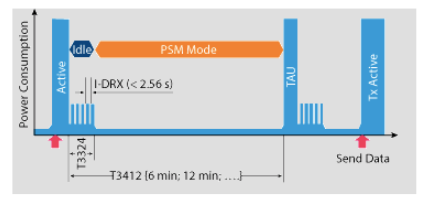
NB-IoT PSM模式的進入和退出分析
那么UE在處理數據后什么時候進入PSM模式?這是由另一個計時器活動計時器(t3324,0到255秒)決定的。UE完成數據處理后,釋放RRC連接使其空閑,同時啟動活動計時器。在計時器超時之后,UE進入上述的PSM
SCR模式下如何通過TC397喚醒TLF35584進入NORMAL模式?
我通過TC397SPI把TLF35584進入了SLEEP模式,然后TC397也進入了standby模式,SCR模式下我如何通過TC397喚醒
發表于 02-02 08:11
無法讓TLE9255進入普通模式怎么解決?
你好,我正在嘗試將 TLE9255 設置為普通模式。 但是,即使在我發出 SPI 命令之后,收發器仍未進入正常模式。 此收發器需要任何開機延遲嗎? 如果可能,請分享一個示例代碼,以便我 CAN
發表于 01-26 07:15
如何讓TLE9271進入開發模式的設置?
我想問一下讓 TLE9271 進入開發模式的設置。 我看到文檔建議在開機時將 FO3 引腳拉到 GND 以進入開發模式。 當我遵循這個建議時
發表于 01-26 06:40





 工商網監
工商網監
評論