 重新思考邊緣負載均衡
重新思考邊緣負載均衡
目標
Netflix的云網關團隊一直致力于幫助系統減少錯誤,獲得更高的可用性,并提高故障恢復能力。因為Netflix每秒有超過一百萬次請求,即使是很低的錯誤率也會影響到會員體驗,所以每一點提升都有幫助。
因此,我們向Zuul和其他團隊學習,改進負載均衡實現,以進一步減少由服務器過載引起的錯誤。
背景
Zuul以前用基于輪詢的Ribbon負載均衡器[3],并基于某些過濾機制將連接失敗率高的服務器列入黑名單。
過去幾年里,我們做了一些改進和定制,比如向最近上線的服務器發送較少流量,以避免過載。這些改進已經取得了顯著效果,但對于某些問題比較多的原始集群,還是會看到與負載相關的錯誤率遠高于預期。
如果集群中所有服務器都過載,那選擇哪一臺服務器幾乎沒有什么區別,不過現實中我們經常看到只有某個服務器子集過載的情況。例如:
服務器冷啟動后(在紅黑部署和觸發自動伸縮期間)。
由于大量動態屬性/腳本/數據更新或大型GC事件,服務器暫時變慢/阻塞。
服務器硬件問題。經常會看到某些服務器運行得總是比其他服務器慢,有可能是由于鄰居節點占用太多資源,也可能因為硬件不同。
指導原則
在開始一個項目時,需要記住一些原則,從而幫助指導在設計軟件時需要做出的大大小小的決定,這個項目基于的原則如下。
在現有負載均衡器框架的約束下工作
我們已經將之前定制的負載均衡器集成到了Zuul代碼庫中,從而使得無法與Netflix的其他團隊共享這些定制。因此,我們決定這次基于約束條件并做出額外投資,從一開始就考慮復用,從而能夠直接在其他系統中使用,減少重新發明輪子的代價。
向他人學習
嘗試在他人的想法和實現基礎上構建,例如之前在Netflix其他IPC棧中試用的"二選一(choice-of-2)"和"試用期(probation)"算法。
避免分布式狀態
選擇本地決策,避免跨集群協調狀態的彈性問題、復雜性和滯后。
避免客戶端配置和手動調優
多年來基于Zuul的操作經驗表明,將服務配置的部分置于不屬于同一團隊的客戶服務中會導致問題。
一個問題是,客戶端配置往往與服務端不斷變化的現實不同步,或者在不同團隊擁有的服務之間引入耦合的變更管理。
例如,用于服務X的EC2實例類型升級,導致該集群所需節點減少。因此,現在服務Y中的"每臺主機最大連接數"客戶端配置應該增加,以反映新增加的容量。應該先對客戶端進行更改,還是先對服務端進行更改,還是同時對兩者進行更改?更有可能的是,完全忘了要改配置,從而導致更多問題。
盡可能不要配置靜態閾值,而是采用基于當前流量、性能和環境變化的自適應機制。
當需要靜態閾值時,與其讓服務團隊將閾值配置協調到每個客戶端,不如讓服務在運行時進行通信,以避免跨團隊邊界推動更改的問題。
負載均衡方法
主要的想法是,雖然服務器延遲的最佳數據來源是客戶端視圖,但服務器利用率的最佳數據來源是服務器本身。結合這兩種數據源,可以得到最有效的負載均衡。
我們基于一組互補機制,其中大多數已經被其他人開發和使用過,只是以前可能沒有以這種方式組合。
用于在服務器之間進行選擇的二選一算法(choice-of-2 algorithm)。
基于服務器利用率的負載均衡器視圖進行主負載均衡。
基于服務器利用率的服務器視圖進行二次均衡。
基于試用期和基于服務器世代的機制,避免新啟動的服務器過載。
隨著時間推移,收集的服務器統計數據衰減為零。
Join-the-Shortest-Queue和服務器報告利用率相結合
我們選擇支持常用的Join-the-shortest-queue(JSQ)算法,并將服務器報告的利用率作為第二算法,以嘗試結合兩者達到最佳效果。
JSQ的問題
Join-the-shortest-queue對于單個負載均衡器非常有效,但如果跨負載均衡器集群使用,則會出現嚴重問題。負載均衡器會傾向于在同一時間選擇相同的低利用率服務器,從而造成超載,然后轉移到下一個利用率最低的服務器并造成超載,以此類推……
通過結合使用JSQ和二選一算法,可以在很大程度上消除羊群問題,除了負載均衡器沒有完整的服務器使用信息之外,其他方面都很好。
JSQ通常僅從本地負載均衡器計算到服務器的正在使用的連接數量來實現,但是當有10到100個負載均衡器節點時,本地視圖可能會產生誤導。
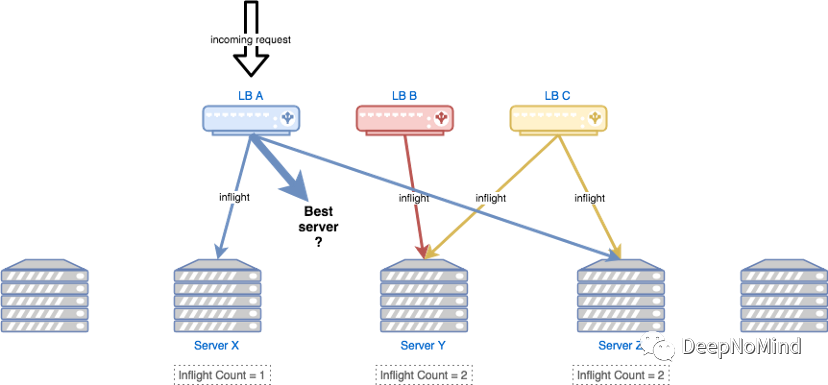
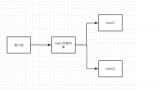
單個負載平衡器的觀點可能與實際情況大不相同
例如,在上圖中,負載均衡器A有一個到服務器X的請求和一個到服務器Z的請求,但沒有到服務器Y的請求。所以當它收到新請求時,基于本地數據,選擇利用率最小的服務器,會選擇服務器Y,但這不是正確的選擇。服務器Y實際上負載最重,其他兩個負載均衡器目前都有請求發送到服務器Y上,但負載均衡器A沒有辦法知道。
這說明單個負載均衡器的觀點與實際情況完全不同。
在只依賴客戶端視圖時遇到的另一個問題是,對于大型集群(特別是與低流量相結合時),負載均衡器通常只有幾個活躍連接,和集群中的某個子集交互。因此,當它選擇哪個服務器負載最少時,通常只是在若干個它認為負載都是0的服務器之間進行選擇,而并沒有關于所選服務器的利用率的數據,所以只能盲猜。
這個問題的解決方案是與所有其他負載均衡器共享所有活躍連接數狀態……但這樣就需要解決分布式狀態問題。
考慮到獲得的好處要大于付出的成本,因此我們通常只將分布式可變狀態作為最后手段:
分布式狀態增加了部署和金絲雀發布等任務的運維開銷和復雜性。
彈性風險與數據損壞的爆炸半徑相關(1%負載均衡器上數據損壞讓人煩惱,但100%負載均衡器上數據損壞會造成停機)。
在負載均衡器之間實現P2P分布式狀態系統的成本,或者運維一個具有處理大量讀寫流量所需的性能和彈性憑證的單一數據庫的成本。
另一種更簡單的解決方案(也是我們選擇的),是依賴于服務器向每個負載均衡器報告資源使用情況……
服務器報告使用率
服務器主動上報其使用率的好處是可以提供所有使用了該服務器的負載均衡器的完整信息,從而避免JSQ的不完整問題。
對此有兩種實現方式:
運行狀況檢查端點主動輪詢每個服務器的當前利用率。
被動跟蹤來自服務器的響應,并標注其當前利用率數據。
我們選擇第二種方式,其實現簡單,可以頻繁更新數據,避免了N個負載均衡器每隔幾秒鐘輪詢M個服務器所帶來的額外開銷。
被動策略的影響是,負載均衡器向一臺服務器發送請求的頻率越高,獲得的該服務器的利用率數據就越新。因此RPS越高,負載均衡的有效性就越高。但反過來,RPS越低,負載均衡的效果就越差。
這對我們來說不是問題,但對于通過特定負載均衡器處理低RPS(同時通過另一個負載均衡器處理高RPS)的服務來說,主動輪詢運行狀況檢查可能更有效。臨界點是負載均衡器向每個服務器發送的RPS低于運行狀況檢查的輪詢頻率。
服務端實現
我們在服務端通過簡單跟蹤活躍請求計數來實現,將其轉換為該服務器配置的最大百分比,并將其作為HTTP響應報頭:
X-Netflix.server.utilization:
服務器可以指定可選的目標利用率,從而標識預期在正常條件下運行的利用率百分比,負載均衡器基于這一數據進行粗粒度過濾,后面會詳細介紹。
我們嘗試使用活躍計數以外的指標,例如操作系統報告的cpu利用率和平均負載,但發現它們會引起振蕩,原因似乎是因為它們是基于滾動平均值計算的,因此有一定的延遲。所以我們決定現在只用相對簡單的實現,即只計算活躍請求。
用二選一算法代替輪詢
由于我們希望能夠通過比較服務器的統計數據來選擇服務器,因此不得不拋棄現有的簡單輪詢實現。
我們在Ribbon算法中嘗試的一個替代方案是JSQ與ServerListSubsetFilter相結合,以減少分布式JSQ的羊群問題。這樣可以得到合理的結果,但是結果在目標服務器之間的請求分布仍然過于分散。
因此,我們參考了Netflix另一個團隊的早期經驗,并實現了"二選一(Choice-of-2)"算法。這樣做的優點是實現簡單,使負載均衡器的cpu成本較低,并能提供良好的請求分布。
根據綜合因素進行選擇
為了在服務器之間進行選擇,我們比較了3個不同的因素:
客戶端運行狀況: 該服務器連接相關錯誤的滾動百分比。
服務器利用率: 該服務器的最新利用率數據。
客戶端利用率: 從當前負載均衡器發送到該服務器的活躍請求數。
這3個因素被用來為每個服務器計算分數,然后比較總分數選擇獲勝者。
像這樣使用多個因素確實會使實現更加復雜,但可以避免僅依賴一個因素可能出現的邊際問題。
例如,如果一臺服務器開始出現故障并拒絕所有請求,那么上報的利用率將會低得多(因為拒絕請求比接受請求開銷更小),如果這是唯一考慮的因素,那么所有負載均衡器將開始向那臺壞服務器發送更多請求。客戶端運行狀況因素緩解了這種情況。
過濾
當隨機選擇2臺服務器進行比較時,會過濾掉任何超過安全利用率配置和運行狀況閾值的服務器。
每個請求都會進行這種過濾,以避免定期過濾會出現的過時問題。為了避免在負載均衡器上造成較高的cpu負載,我們盡力而為(best-effort)嘗試N次來隨機選擇一個可用服務器,然后在必要時回退到未篩選的服務器。
當服務器池中有很大一部分存在長期問題時,這樣的篩選非常有用。在這種情況下,隨機選擇2個服務器通常會出現選擇了2個壞服務器進行比較的情況。
但缺點是這依賴于靜態配置閾值,而這是我們試圖避免的。測試結果讓我們相信這點依賴是值得的,即使只依賴一些通用(非特定于服務的)閾值。
試用期
對于任何沒有發送響應給負載均衡器的服務器,一次只允許一個活躍請求,隨后會過濾掉這些試用服務器,直到收到來自它們的響應。
這有助于避免新啟動的服務器還沒有機會顯示使用率數據之前就因大量請求而超載。
基于服務器世代的預熱
我們基于服務器世代在服務器啟動的前90秒內逐步增加流量。
這是另一種有用的機制,就像試用期一樣,可以在微妙的發布后增加一些關于服務器過載的警告。
統計衰變
為確保服務器不會被永久列入黑名單,我們將衰減率應用到所有用于負載均衡的統計數據上(目前是30秒的線性衰減)。例如,如果一個服務器的錯誤率上升到80%,停止向它發送流量,使用的數據將在30秒內衰減為零,比方說15秒后是會是40%)。
運維影響
差距更大的請求分布
不用輪詢進行負載均衡的負面影響是,以前服務器之間的請求分布非常均衡,現在服務器之間的負載差距更大。
"二選一"算法在很大程度上能緩解這種情況(與跨集群中所有服務器或服務器子集的JSQ相比),但不可能完全避免。
因此,在運維方面確實需要考慮這一點,特別是在金絲雀分析中,我們通常比較請求計數、錯誤率、cpu等的絕對值。
越慢的服務器接收的流量越少
顯然這是預期效果,但對于習慣于輪詢的團隊來說,流量是平等分配的,這對運維方面會產生連鎖反應。
由于跨原始服務器的流量分布現在依賴于它們的利用率,如果一些服務器正在運行效率更高或更低的不同構建,那么將接收到更多或更少的流量。所以:
當集群采用紅黑部署時,如果新的服務器組性能下降,那么該組的流量比例將小于50%。
同樣的效果可以在金絲雀集群中看到,基線組可能會接收到與金絲雀組不同的流量。所以當我們著眼于指標時,最好著眼于RPS和CPU的組合(例如RPS在金絲雀中可能更低,而CPU相同)。
更低效的異常值檢測。我們通常會自動監控集群中的異常服務器(通常是由于硬件問題導致啟動速度變慢的虛擬機)并終止它們,當由于負載均衡而接收較少流量時,這種檢測就更加困難。
滾動動態數據更新
從輪詢遷移到新的負載均衡器取得了很好的效果,可以很好的配合動態數據和屬性的分階段更新。
最佳實踐是每次在一個區域(數據中心)部署數據更新,以限制意外問題的爆發半徑。
即使數據更新本身沒有引起任何問題,服務器應用更新的行為也會導致短暫的負載高峰(通常與GC相關)。如果此峰值同時出現在集群中所有服務器上,則可能導致負載下降以及向上游傳播大量錯誤。在這種情況下,因為所有服務器的負載都很高,負載均衡器幾乎無法提供幫助。
然而,如果考慮與自適應負載均衡器結合使用,一個解決方案是在集群服務器之間進行滾動數據更新。如果只有一小部分服務器同時應用更新,那么只要還有足夠服務器能夠承載流量,負載均衡器就可以短暫減少到這些服務器的流量。
合成負載測試結果
在開發、測試和調優負載均衡器時,我們廣泛使用了合成負載測試場景,這在使用真實集群和網絡驗證有效性時非常有用,可以作為單元測試之后的可重復步驟,但還沒有使用真實用戶流量。
測試的更多細節在后面的附錄中列出,現總結要點如下:
與輪詢實現相比,啟用了所有功能的新負載均衡器在負載下降和連接錯誤方面降低了幾個數量級。
平均和長尾延遲有了實質性改善(與輪詢實現相比減少了3倍)。
服務器本身由于添加了特性,顯著增加了價值,減少了一個數量級的錯誤以及大部分延遲。
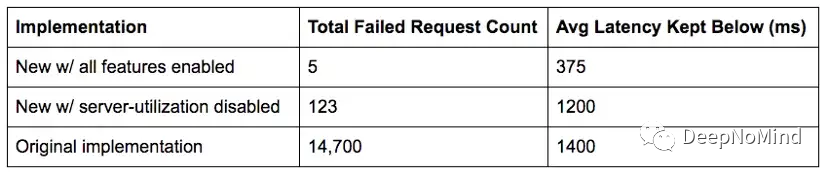
結果比較
對實際生產流量的影響
我們發現,只要服務器能夠處理,新負載均衡器就能非常有效的將盡可能多的流量分配到每個服務器。這對于在間歇和持續降級的服務器之間進行路由具有很好的效果,無需任何人工干預,從而避免工程師在半夜被叫醒處理重大生產問題。
很難說明在正常運行時的影響,但在生產事故中甚至在某些服務的正常穩態運行中,可以看到對應的影響。
事故發生時
最近的事故涉及到服務中的錯誤,該錯誤導致越來越多的服務器線程隨著時間的推移而阻塞。從服務器啟動的那一刻起,每小時都會阻塞幾個線程,直到最終達到最大負載并造成負載下降。
在下面的服務器RPS圖表中,可以看到在凌晨3點之前,服務器負載分布差距較大,這是由于負載均衡器向阻塞線程數量較多的服務器發送較少流量的緣故。然后,在凌晨3點25分之后,自動縮放啟動更多服務器,由于這些服務器還沒有任何線程阻塞,每個服務器收到的RPS大約是現有服務器的兩倍,可以成功處理更多流量。
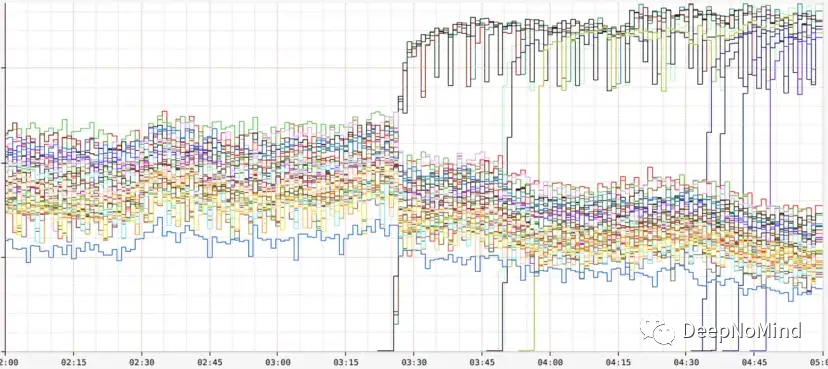
每服務器RPS
現在,如果我們看一下同一時間范圍內每臺服務器的錯誤率圖表,可以看到,在整個事故過程中,所有服務器的錯誤分布是相當均勻的,盡管某些服務器的容量比其他服務器小得多。這表明負載均衡器在有效工作,而由于集群整體可用容量太小,因此所有服務器都被推到稍稍超過其有效容量的位置。
然后,當自動縮放啟動新服務器時,新服務器處理了盡可能多的流量,以至于出現了與集群其他部分相同的錯誤。
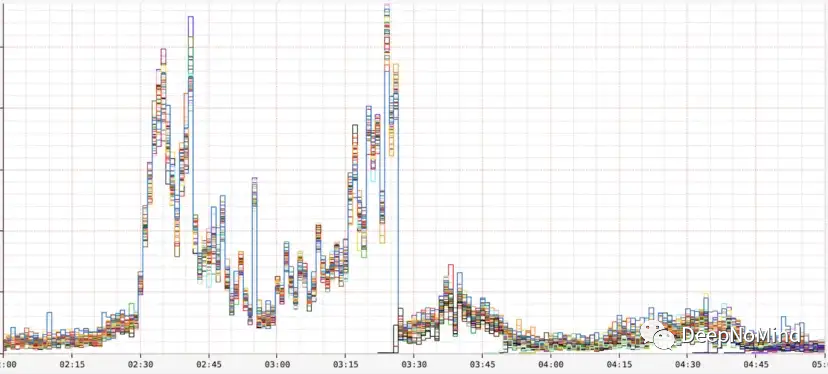
每服務器每秒錯誤
因此,綜上所述,負載均衡器在向服務器分配流量方面非常有效,但在這種情況下,沒有啟動足夠的新服務器,從而導致沒法將整體錯誤水平降至零。
穩態
我們還看到,在某些服務中,由于GC事件而出現幾秒鐘的負載下降,因此穩態噪聲顯著降低。從這里可以看出,啟用新的負載均衡器后,錯誤大幅減少:
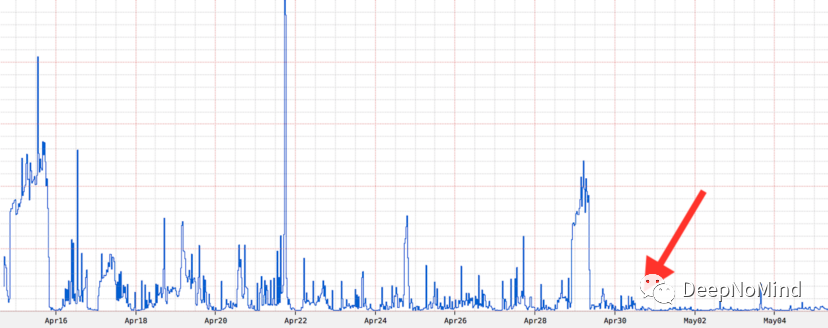
啟用新負載均衡器前后數周內與負載相關的錯誤率
告警中的差距
一個意料之外的影響是突出了我們自動告警中的一些差距。一些基于服務錯誤率的現有告警,以前會在漸進式問題只影響到集群的一小部分時發出告警,現在因為錯誤率一直很低,告警會晚得多,或者根本不發出告警。這意味著,有時沒法將影響集群的大問題通知給團隊。解決方案是增加對利用率指標的偏差而不僅僅是錯誤指標的額外告警來彌補這些差距。
結論
本文并不是為Zuul做宣傳(盡管它是一個偉大的系統),只是為代理/服務網格/負載均衡社區分享和增加了一個有趣的方法。Zuul是測試、實施和改進這些類型負載均衡方案的偉大系統,以Netflix的需求和規模來運行,使我們有能力證明和改進這些方法。
有許多不同方法可以改善負載均衡,而這個方法對我們來說效果很好,大大減少了與負載有關的錯誤率,并極大改善了真實流量的負載均衡。
然而,對于任何軟件系統來說,都應該根據自己組織的限制和目標來做決定,并盡量避免追求完美。
附錄--合成負載測試的結果
測試場景
這個負載測試場景重現了這樣一種情況: 小型原始集群正在進行紅黑部署,而新部署的集群存在冷啟動問題或某種性能退化(通過人為在新部署的服務器上為每個請求注入額外延遲和cpu負載來模擬)。
該測試將4000 RPS發送到一個大型Zuul集群(200個節點),該集群反過來代理到一個小型Origin集群(20個實例),幾分鐘后,啟用第二個緩慢的Origin集群(另外20個實例)。
啟用所有功能
以下是啟用了所有功能的新負載均衡器的指標圖表。
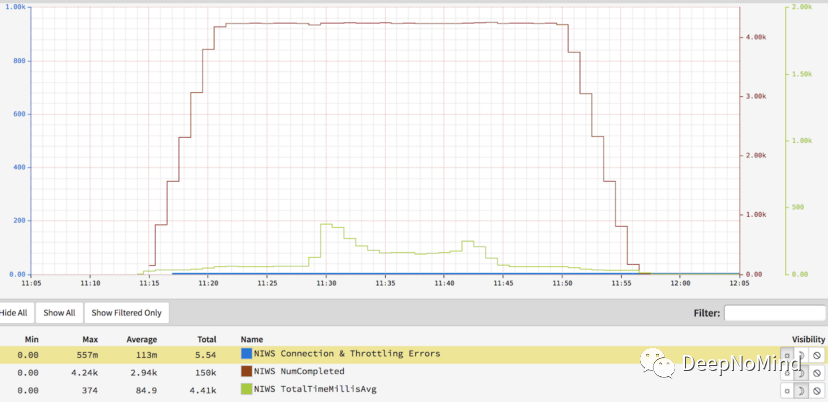
啟用新負載均衡器所有功能進行負載測試
作為參考,看看流量是如何在較快和較慢的服務器組之間分配的,可以看到,負載均衡器把發送到較慢組的比例減少到15%左右(預期50%)。
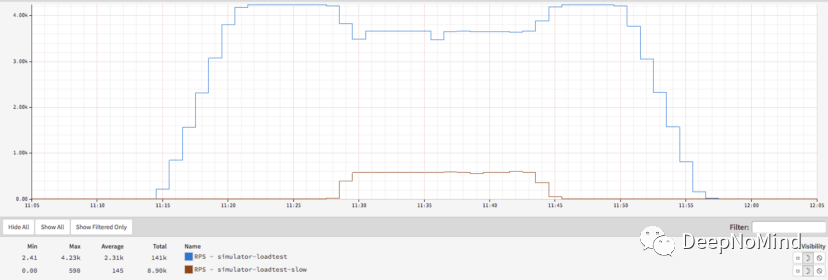
正常集群和慢速集群之間的流量分布
禁用服務器利用率
還是新負載均衡器,但禁用了服務器利用率功能,因此只有客戶端數據被用于均衡。
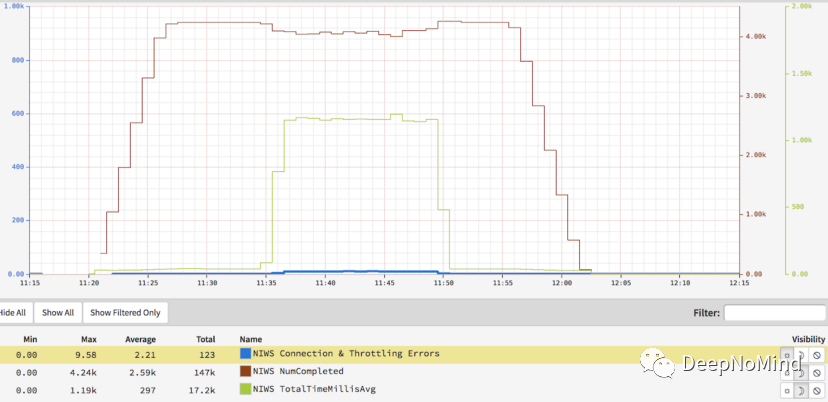
使用新負載均衡器進行負載測試,但禁用了服務器利用率特性
原始實現
這是最初的輪詢負載均衡器與服務器黑名單功能。
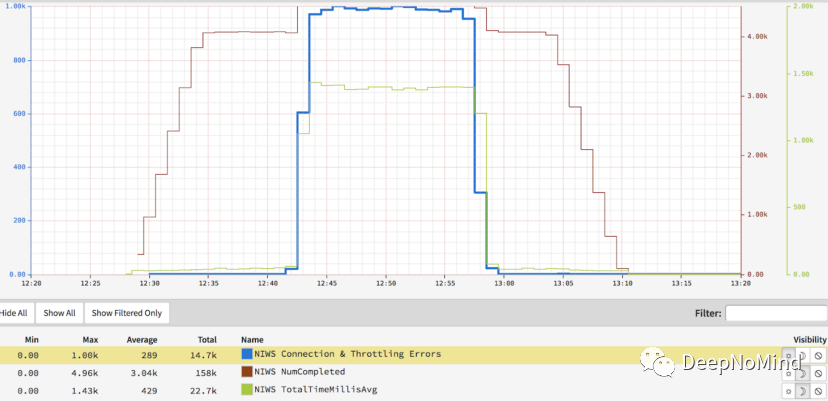
使用原始負載均衡器進行負載測試
審核編輯:湯梓紅
-
均衡器
+關注
關注
9文章
215瀏覽量
30363 -
服務器
+關注
關注
12文章
9233瀏覽量
85637 -
負載均衡
+關注
關注
0文章
112瀏覽量
12373 -
Netflix
+關注
關注
0文章
90瀏覽量
11222
原文標題:重新思考邊緣負載均衡
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于C-V2X邊緣服務器的動態負載均衡算法及研究

服務器負載均衡有幾種類型,做負載均衡好在哪
apache反向代理和負載均衡總結

Apacheproxy負載均衡和Session復制
解密負載均衡技術和負載均衡算法
高性能負載均衡的分類和算法
負載均衡是如何工作的?
常見的幾種負載均衡技術介紹





 工商網監
工商網監
評論