 PyTorch教程-14.7。單發多框檢測
PyTorch教程-14.7。單發多框檢測
在第 14.3 節到第 14.6 節中,我們介紹了邊界框、錨框、多尺度目標檢測和目標檢測數據集。現在我們準備使用這些背景知識來設計一個目標檢測模型:單次多框檢測(SSD)(Liu et al. , 2016)。該模型簡單、快速、應用廣泛。雖然這只是大量目標檢測模型中的一種,但本節中的一些設計原則和實現細節也適用于其他模型。
14.7.1。模型
圖 14.7.1提供了單次多框檢測設計的概述。該模型主要由一個基礎網絡和幾個多尺度特征圖塊組成。基礎網絡用于從輸入圖像中提取特征,因此可以使用深度 CNN。例如,原始的單次多框檢測論文采用在分類層之前截斷的VGG網絡 (Liu et al. , 2016),而 ResNet 也被普遍使用。通過我們的設計,我們可以讓基礎網絡輸出更大的特征圖,從而生成更多的錨框來檢測更小的物體。隨后,每個多尺度特征圖塊從前一個塊減少(例如,減半)特征圖的高度和寬度,并使特征圖的每個單元增加其在輸入圖像上的感受野。
回想一下14.5 節中深度神經網絡通過圖像的分層表示進行多尺度目標檢測的設計 。由于靠近圖 14.7.1頂部的多尺度特征圖較小但具有較大的感受野,因此它們適用于檢測較少但較大的對象。
簡而言之,通過其基礎網絡和多個多尺度特征圖塊,單次多框檢測生成不同數量的不同大小的錨框,并通過預測這些錨框的類別和偏移量(因此邊界盒);因此,這是一個多尺度目標檢測模型。

圖 14.7.1作為多尺度目標檢測模型,單次多框檢測主要由一個基礎網絡和幾個多尺度特征圖塊組成。
下面,我們將描述圖14.7.1中不同塊的實現細節。首先,我們討論如何實現類和邊界框預測。
14.7.1.1。類別預測層
讓對象類的數量為q. 然后anchor boxes有 q+1類,其中類 0 是背景。在某種程度上,假設特征圖的高度和寬度是h和w, 分別。什么時候a以這些特征圖的每個空間位置為中心生成anchor boxes,一共 hwaanchor boxes需要分類。由于參數化成本可能很高,這通常會使完全連接層的分類變得不可行。回想一下我們在8.3 節中如何使用卷積層的通道來預測類別。單次多框檢測使用相同的技術來降低模型的復雜性。
具體來說,類預測層使用卷積層而不改變特征圖的寬度或高度。這樣,在特征圖的相同空間維度(寬度和高度)下,輸出和輸入之間可以存在一一對應關系。更具體地說,輸出特征映射的通道在任何空間位置(x, y) 表示以 (x,y) 輸入特征圖。為了產生有效的預測,必須有a(q+1)輸出通道,其中對于相同的空間位置,具有索引的輸出通道i(q+1)+j 代表類別的預測j (0≤j≤q) 對于錨框i (0≤i
下面我們定義這樣一個類預測層,指定a和 q分別通過參數num_anchors和num_classes。該層使用了3×3填充為1的卷積層。該卷積層的輸入和輸出的寬度和高度保持不變。
14.7.1.2。邊界框預測層
邊界框預測層的設計與類預測層的設計類似。唯一的區別在于每個錨框的輸出數量:這里我們需要預測四個偏移量而不是q+1類。
14.7.1.3。連接多個尺度的預測
正如我們提到的,單次多框檢測使用多尺度特征圖來生成錨框并預測它們的類別和偏移量。在不同的尺度下,特征圖的形狀或以同一單元為中心的錨框數量可能會有所不同。因此,不同尺度的預測輸出的形狀可能會有所不同。
在下面的例子中,我們構建了兩種不同比例的特征圖,Y1并且Y2,對于同一個小批量,其中 的高度和寬度Y2是 的一半Y1。讓我們以類別預測為例。Y1假設分別為和中的每個單元生成 5 個和 3 個錨框Y2。進一步假設對象類的數量為 10。對于特征圖Y1和Y2類預測輸出中的通道數為5×(10+1)=55 和3×(10+1)=33,其中任一輸出形狀為(批量大小、通道數、高度、寬度)。
我們可以看到,除了 batch size 維度,其他三個維度都有不同的大小。為了連接這兩個預測輸出以實現更高效的計算,我們將把這些張量轉換為更一致的格式。
請注意,通道維度包含具有相同中心的錨框的預測。我們先把這個維度移到最里面。由于批量大小對于不同的尺度保持不變,我們可以將預測輸出轉換為具有形狀的二維張量(批量大小,高度×寬度×通道數)。然后我們可以沿著維度 1 以不同的比例連接這些輸出。
通過這種方式,即使 和Y1在Y2通道、高度和寬度方面具有不同的大小,我們仍然可以將這兩個預測輸出以兩個不同的尺度連接起來,用于同一個小批量。
14.7.1.4。下采樣塊
為了檢測多個尺度的對象,我們定義了以下下采樣塊down_sample_blk,將輸入特征圖的高度和寬度減半。實際上,該塊應用了8.2.1 節中 VGG 塊的設計。更具體地說,每個下采樣塊由兩個3×3填充為 1 的卷積層后跟一個2×2步幅為 2 的最大池化層。我們知道,3×3填充為 1 的卷積層不會改變特征圖的形狀。然而,隨后的2×2max-pooling 將輸入特征圖的高度和寬度減半。對于這個下采樣塊的輸入和輸出特征圖,因為1×2+(3?1)+(3?1)=6,輸出中的每個單元都有一個6×6輸入的感受野。因此,下采樣塊在其輸出特征圖中擴大了每個單元的感受野。
在下面的例子中,我們構建的下采樣塊改變了輸入通道的數量,并將輸入特征圖的高度和寬度減半。
14.7.1.5。基礎網絡塊
基礎網絡塊用于從輸入圖像中提取特征。為簡單起見,我們構建了一個由三個下采樣塊組成的小型基礎網絡,每個塊的通道數加倍。給定一個256×256輸入圖像,這個基礎網絡塊輸出32×32特征圖(256/23=32).
14.7.1.6。完整模型
完整的單次多框檢測模型由五個塊組成。每個塊生成的特征圖用于 (i) 生成錨框和 (ii) 預測這些錨框的類別和偏移量。在這五個塊中,第一個是基礎網絡塊,第二到第四個是下采樣塊,最后一個塊使用全局最大池化將高度和寬度都降低到1。從技術上講,第二到第五個塊是圖 14.7.1中的所有那些多尺度特征圖塊。
現在我們為每個塊定義前向傳播。與圖像分類任務不同,此處的輸出包括 (i) CNN 特征圖 Y,(ii) 在當前尺度下使用生成的錨框,以及 (iii)為這些錨框Y預測的類別和偏移量(基于)。Y
回想一下,在圖 14.7.1中,靠近頂部的多尺度特征圖塊用于檢測較大的對象;因此,它需要生成更大的錨框。sizes在上面的前向傳播中,在每個多尺度特征圖塊中,我們通過調用函數的參數(在第 14.4 節multibox_prior中描述)傳入一個包含兩個尺度值的列表。下面將0.2和1.05之間的區間平均分為五個部分,以確定五個塊處較小的刻度值:0.2、0.37、0.54、0.71和0.88。然后它們的較大比例值由下式給出 0.2×0.37=0.272, 0.37×0.54=0.447, 等等。
現在我們可以定義完整的模型TinySSD如下。
我們創建一個模型實例并使用它對小批量數據執行前向傳播256×256圖片X。
如本節前面所示,第一個塊輸出 32×32特征圖。回想一下,第二到第四個下采樣塊將高度和寬度減半,第五個塊使用全局池化。由于沿特征圖的空間維度為每個單元生成 4 個錨框,因此在所有五個尺度上總共 (322+162+82+42+1)×4=5444為每個圖像生成錨框。
14.7.2。訓練
現在我們將解釋如何訓練用于目標檢測的單發多框檢測模型。
14.7.2.1。讀取數據集并初始化模型
首先,讓我們閱讀 第 14.6 節中描述的香蕉檢測數據集。
香蕉檢測數據集中只有一類。定義模型后,我們需要初始化其參數并定義優化算法。
14.7.2.2。定義損失函數和評估函數
物體檢測有兩種類型的損失。第一個損失涉及錨框的類別:它的計算可以簡單地重用我們用于圖像分類的交叉熵損失函數。第二個損失涉及正(非背景)錨框的偏移:這是一個回歸問題。然而,對于這個回歸問題,這里我們不使用 第 3.1.3 節中描述的平方損失。相反,我們使用?1范數損失,預測值與真實值之間差異的絕對值。掩碼變量 bbox_masks在損失計算中過濾掉負錨框和非法(填充)錨框。最后,我們將anchor box class loss和anchor box offset loss相加得到模型的損失函數。
我們可以使用準確性來評估分類結果。由于使用?1對于偏移量的范數損失,我們使用平均絕對誤差來評估預測的邊界框。這些預測結果是從生成的錨框和它們的預測偏移量中獲得的。
14.7.2.3。訓練模型
在訓練模型時,我們需要生成多尺度錨框 ( anchors) 并在前向傳播中預測它們的類別 ( cls_preds) 和偏移量 ( )。然后我們根據標簽信息對生成的anchor boxes的bbox_predsclasses( cls_labels)和offsets( )進行標注。最后,我們使用類別和偏移量的預測值和標記值來計算損失函數。為了簡潔的實現,這里省略了測試數據集的評估。bbox_labelsY
14.7.3。預言
在預測期間,目標是檢測圖像上所有感興趣的對象。下面我們讀取并調整測試圖像的大小,將其轉換為卷積層所需的四維張量。
使用multibox_detection下面的函數,預測的邊界框是從錨框及其預測的偏移量中獲得的。然后使用非最大抑制來去除相似的預測邊界框。
最后,我們將所有置信度為 0.9 或更高的預測邊界框顯示為輸出。
14.7.4。概括
Single shot multibox detection是一種多尺度目標檢測模型。通過其基礎網絡和多個多尺度特征圖塊,單次多框檢測生成不同數量的不同大小的錨框,并通過預測這些錨框(即邊界框)的類別和偏移量來檢測不同大小的對象。
在訓練單次多框檢測模型時,損失函數是根據錨框類別和偏移量的預測值和標記值計算的。
14.7.5。練習
你能通過改進損失函數來改進單次多框檢測嗎?例如,替換?1平滑的范數損失?1預測偏移量的標準損失。此損失函數使用圍繞零的平方函數來實現平滑度,它由超參數控制σ:
什么時候σ非常大,這個損失類似于 ?1規范損失。當它的值越小,損失函數越平滑。
此外,在實驗中我們使用交叉熵損失進行類別預測:表示為pj真實類別的預測概率j,交叉熵損失是 ?log?pj. 我們還可以使用焦點損失 (Lin等人,2017 年):給定超參數 γ>0和α>0,此損失定義為:
正如我們所見,增加γ可以有效地減少分類良好的例子的相對損失(例如,pj>0.5) 因此訓練可以更多地關注那些被錯誤分類的困難示例。
由于篇幅限制,我們在本節中省略了單次多框檢測模型的一些實現細節。能否在以下幾個方面進一步改進模型:
當一個對象與圖像相比小得多時,模型可以將輸入圖像調整得更大。
通常有大量的負錨框。為了使類別分布更加平衡,我們可以對負錨框進行下采樣。
在損失函數中,為類損失和偏移損失分配不同的權重超參數。
使用其他方法來評估對象檢測模型,例如單發多框檢測論文 (Liu et al. , 2016)中的方法。
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1)
%matplotlib inline
from mxnet import autograd, gluon, image, init, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
def cls_predictor(num_anchors, num_classes):
return nn.Conv2D(num_anchors * (num_classes + 1), kernel_size=3,
padding=1)
def bbox_predictor(num_inputs, num_anchors):
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
def bbox_predictor(num_anchors):
return nn.Conv2D(num_anchors * 4, kernel_size=3, padding=1)
def forward(x, block):
return block(x)
Y1 = forward(torch.zeros((2, 8, 20, 20)), cls_predictor(8, 5, 10))
Y2 = forward(torch.zeros((2, 16, 10, 10)), cls_predictor(16, 3, 10))
Y1.shape, Y2.shape
(torch.Size([2, 55, 20, 20]), torch.Size([2, 33, 10, 10]))
def forward(x, block):
block.initialize()
return block(x)
Y1 = forward(np.zeros((2, 8, 20, 20)), cls_predictor(5, 10))
Y2 = forward(np.zeros((2, 16, 10, 10)), cls_predictor(3, 10))
Y1.shape, Y2.shape
((2, 55, 20, 20), (2, 33, 10, 10))
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
def flatten_pred(pred):
return npx.batch_flatten(pred.transpose(0, 2, 3, 1))
def concat_preds(preds):
return np.concatenate([flatten_pred(p) for p in preds], axis=1)
concat_preds([Y1, Y2]).shape
torch.Size([2, 25300])
concat_preds([Y1, Y2]).shape
(2, 25300)
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2))
return nn.Sequential(*blk)
def down_sample_blk(num_channels):
blk = nn.Sequential()
for _ in range(2):
blk.add(nn.Conv2D(num_channels, kernel_size=3, padding=1),
nn.BatchNorm(in_channels=num_channels),
nn.Activation('relu'))
blk.add(nn.MaxPool2D(2))
return blk
forward(torch.zeros((2, 3, 20, 20)), down_sample_blk(3, 10)).shape
torch.Size([2, 10, 10, 10])
forward(np.zeros((2, 3, 20, 20)), down_sample_blk(10)).shape
(2, 10, 10, 10)
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
forward(torch.zeros((2, 3, 256, 256)), base_net()).shape
torch.Size([2, 64, 32, 32])
def base_net():
blk = nn.Sequential()
for num_filters in [16, 32, 64]:
blk.add(down_sample_blk(num_filters))
return blk
forward(np.zeros((2, 3, 256, 256)), base_net()).shape
(2, 64, 32, 32)
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1,1))
else:
blk = down_sample_blk(128, 128)
return blk
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 4:
blk = nn.GlobalMaxPool2D()
else:
blk = down_sample_blk(128)
return blk
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]
for i in range(5):
# Equivalent to the assignment statement `self.blk_i = get_blk(i)`
setattr(self, f'blk_{i}', get_blk(i))
setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i],
num_anchors, num_classes))
setattr(self, f'bbox_{i}', bbox_predictor(idx_to_in_channels[i],
num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# Here `getattr(self, 'blk_%d' % i)` accesses `self.blk_i`
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
anchors = torch.cat(anchors, dim=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
class TinySSD(nn.Block):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
for i in range(5):
# Equivalent to the assignment statement `self.blk_i = get_blk(i)`
setattr(self, f'blk_{i}', get_blk(i))
setattr(self, f'cls_{i}', cls_predictor(num_anchors, num_classes))
setattr(self, f'bbox_{i}', bbox_predictor(num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# Here `getattr(self, 'blk_%d' % i)` accesses `self.blk_i`
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
anchors = np.concatenate(anchors, axis=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
net = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
output anchors: torch.Size([1, 5444, 4])
output class preds: torch.Size([32, 5444, 2])
output bbox preds: torch.Size([32, 21776])
net = TinySSD(num_classes=1)
net.initialize()
X = np.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
output anchors: (1, 5444, 4)
output class preds: (32, 5444, 2)
output bbox preds: (32, 21776)
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)
Downloading ../data/banana-detection.zip from http://d2l-data.s3-accelerate.amazonaws.com/banana-detection.zip...
read 1000 training examples
read 100 validation examples
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)
Downloading ../data/banana-detection.zip from http://d2l-data.s3-accelerate.amazonaws.com/banana-detection.zip...
read 1000 training examples
read 100 validation examples
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
net.initialize(init=init.Xavier(), ctx=device)
trainer = gluon.Trainer(net.collect_params(), 'sgd',
{'learning_rate': 0.2, 'wd': 5e-4})
cls_loss = nn.CrossEntropyLoss(reduction='none')
bbox_loss = nn.L1Loss(reduction='none')
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
cls = cls_loss(cls_preds.reshape(-1, num_classes),
cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1)
bbox = bbox_loss(bbox_preds * bbox_masks,
bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox
cls_loss = gluon.loss.SoftmaxCrossEntropyLoss()
bbox_loss = gluon.loss.L1Loss()
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
cls = cls_loss(cls_preds, cls_labels)
bbox = bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks)
return cls + bbox
def cls_eval(cls_preds, cls_labels):
# Because the class prediction results are on the final dimension,
# `argmax` needs to specify this dimension
return float((cls_preds.argmax(dim=-1).type(
cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
def cls_eval(cls_preds, cls_labels):
# Because the class prediction results are on the final dimension,
# `argmax` needs to specify this dimension
return float((cls_preds.argmax(axis=-1).astype(
cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((np.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# Sum of training accuracy, no. of examples in sum of training accuracy,
# Sum of absolute error, no. of examples in sum of absolute error
metric = d2l.Accumulator(4)
net.train()
for features, target in train_iter:
timer.start()
trainer.zero_grad()
X, Y = features.to(device), target.to(device)
# Generate multiscale anchor boxes and predict their classes and
# offsets
anchors, cls_preds, bbox_preds = net(X)
# Label the classes and offsets of these anchor boxes
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)
# Calculate the loss function using the predicted and labeled values
# of the classes and offsets
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.mean().backward()
trainer.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.numel())
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
class err 3.29e-03, bbox mae 3.08e-03
4339.3 examples/sec on cuda:0

num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
for epoch in range(num_epochs):
# Sum of training accuracy, no. of examples in sum of training accuracy,
# Sum of absolute error, no. of examples in sum of absolute error
metric = d2l.Accumulator(4)
for features, target in train_iter:
timer.start()
X = features.as_in_ctx(device)
Y = target.as_in_ctx(device)
with autograd.record():
# Generate multiscale anchor boxes and predict their classes and
# offsets
anchors, cls_preds, bbox_preds = net(X)
# Label the classes and offsets of these anchor boxes
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors,
Y)
# Calculate the loss function using the predicted and labeled
# values of the classes and offsets
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.backward()
trainer.step(batch_size)
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.size,
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.size)
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter._dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
class err 3.56e-03, bbox mae 3.78e-03
966.8 examples/sec on gpu(0)

X = torchvision.io.read_image('../img/banana.jpg').unsqueeze(0).float()
img = X.squeeze(0).permute(1, 2, 0).long()
img = image.imread('../img/banana.jpg')
feature = image.imresize(img, 256, 256).astype('float32')
X = np.expand_dims(feature.transpose(2, 0, 1), axis=0)
def predict(X):
net.eval()
anchors, cls_preds, bbox_preds = net(X.to(device))
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
def predict(X):
anchors, cls_preds, bbox_preds = net(X.as_in_ctx(device))
cls_probs = npx.softmax(cls_preds).transpose(0, 2, 1)
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
[09:37:33] src/operator/nn/./cudnn/./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (set the environment variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
def display(img, output, threshold):
d2l.set_figsize((5, 5))
fig = d2l.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[:2]
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
display(img, output.cpu(), threshold=0.9)

def display(img, output, threshold):
d2l.set_figsize((5, 5))
fig = d2l.plt.imshow(img.asnumpy())
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[:2]
bbox = [row[2:6] * np.array((w, h, w, h), ctx=row.ctx)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
display(img, output, threshold=0.9)

-
檢測
+關注
關注
5文章
4492瀏覽量
91521 -
pytorch
+關注
關注
2文章
808瀏覽量
13238
發布評論請先 登錄
相關推薦
關于多列列表框的應用
UCGUI多文本框
多列列表框與組合框配合使用
新樹型框擴展模塊+例程(iouioupp要的支持多樹型框)

基于PyTorch的深度學習入門教程之DataParallel使用多GPU
解讀目標檢測中的框位置優化
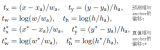

labview多列列表框寫入數據
氣密性檢測儀:單工位與多工位之間的區別






 工商網監
工商網監
評論