 CVPR 2023:視覺重定位,同等精度下速度提升300倍
CVPR 2023:視覺重定位,同等精度下速度提升300倍
本次分享的論文來自CVPR 2023(Highlight),作者來自鼎鼎大名的Niantic Labs,是一個很有名的VR游戲開發公司,做了增強現實游戲Ingress和位置發現應用Field Trip和pokemon go手游。
論文題目:Accelerated Coordinate Encoding:Learning to Relocalize in Minutes using RGB and Poses
論文鏈接:https://arxiv.org/pdf/2305.14059.pdf
代碼主頁:https://github.com/nianticlabs/ace
01介紹
本文是一篇基于學習的視覺定位算法,更具體的是通過網絡學習回歸圖像密集像素三維坐標,建立2D-3D對應后放在魯棒姿態估計器(RANSAC PNP + 迭代優化)中估計相機六自由度姿態。
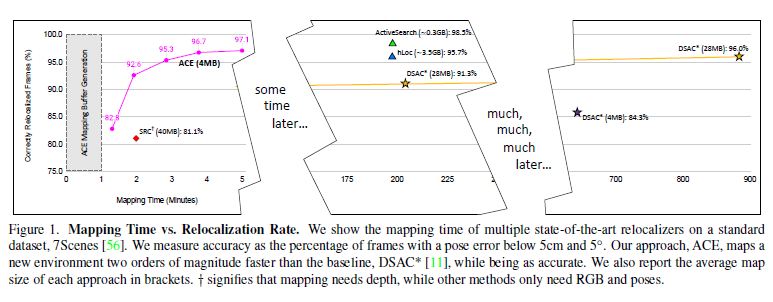
與以往基于學習的視覺定位算法的區別在于:以前的方法往往需要數小時或數天的訓練,而且每個新場景都需要再次進行訓練,使得該方法在大多數應用程序中不太現實,所以在本文中作者團隊提出的方法改善了這一確定,使得可以在不到5分鐘的時間內實現同樣的精度。
具體的,作者講定位網絡分為場景無關的特征backbone和場景特定的預測頭。而且預測頭不使用傳統的卷積網絡,而是使用MLP,這可以在每次訓練迭代中同時對數千個視點進行優化,導致穩定和極快的收斂。
此外使用一個魯棒姿態求解器的curriculum training替代有效但緩慢的端到端訓練。
其方法在制圖方面比最先進的場景坐標回歸快了300倍!
curriculum training:Curriculum training是一種訓練方法,訓練時向模型提供訓練樣本的難度逐漸變大。在對新數據進行訓練時,此方法需要對任務進行標注,將任務分為簡單、中等或困難,然后對數據進行采樣。
把原來的卷積網絡預測頭換成MLP預測頭的動機是什么?作者認為場景坐標回歸可以看作從高維特征向量到場景空間三維點的映射,與卷積網絡相比,多層感知器(MLP)可以很好地表示這種映射,而且訓練一個特定場景的MLP允許在每次訓練迭代中一次優化多個(通常是所有可用的)視圖,這會導致非常穩定的梯度,使其能夠在非常積極的、高學習率的機制下操作。把這個和curriculum training結合在一起,讓網絡在后期訓練階段burn in可靠的場景結構,使其模擬了端到端訓練方案,以此會極大提升訓練速度和效率。
02主要貢獻
(1)加速坐標編碼(ACE),一個場景坐標回歸算法,可以在5分鐘內映射一個新場景,以前最先進的場景坐標回歸系統需要數小時才能達到相當的重定位精度。
(2)ACE將場景編碼成4MB的網絡權重,以前的場景坐標回歸系統需要7倍的存儲空間。
(3)只需要RGB圖像和對應的pose進行訓練,以前的依賴于像深度圖或場景網格這樣的先驗知識來進行。
03方法
算法的目標是估計給定的RGB圖像I的相機姿態h。定義的相機姿態為一個剛體變換,其將相機空間下的坐標ei映射到場景空間的坐標yi,即yi = h*ei。
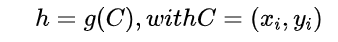
其中C表示2D像素位置和3D場景坐標之間的對應,g表示一個魯棒的姿態估計器。
設計的網絡學習預測給定2D圖像點對應的3D場景點,即:
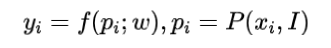
其中f表示學習到的權重參數化的網絡,表示從圖像I的像素位置附近提取的圖像patch,所以f是一個patchs到場景坐標的映射。
網絡在訓練時在所有建圖圖像用他們的ground truth 作為監督進行訓練:
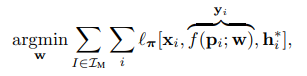
3.1 通過解關聯梯度進行高效訓練
作者認為以往的方法在每次訓練迭代中優化了成千上萬個patch的預測,但它們都來自同一幅圖像,因此它們的損失和梯度將是高度相關的。所以這篇文章的關鍵思想是在整個訓練集上隨機化patches,并從許多不同的視圖中構造batch,這種方法可以解關聯batch中的梯度,從而得到穩定的訓練,而且對高學習率具有魯棒性,并最終實現快速收斂。
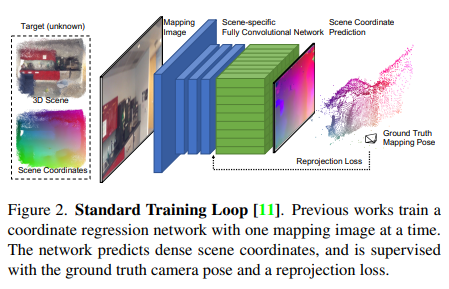
以往的方法的網絡如下圖所示,一次一副圖像,切圖像特征編碼器和預測頭解碼器都是CNN
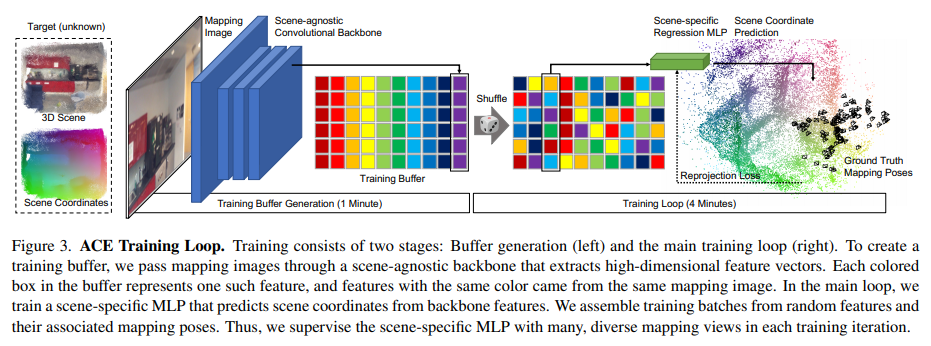
作者將網絡拆分為卷積主干和多層感知器(MLP)頭,如下圖所示:
所以網絡拆分成兩部分:
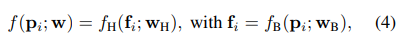
其中是用來預測表示圖像特征的高維向量,是用來預測場景坐標的回歸頭
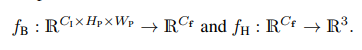
作者認為可以用場景無關的卷積網絡實現一個通用的特征提取器,可以使用一個MLP而不是另一個卷積網絡來實現。這樣做因為在預測patch對應的場景坐標時是不需要空間上下文的,也就是說,與backbone不同,不需要訪問鄰近的像素來進行計算,因此可以用所有圖像中的隨機樣本構建的訓練batch,具體就是通過在所有圖像上運行預訓練的backbone來構建一個固定大小的訓練緩沖區,這個緩沖區包含數以百萬計的特征及其相關像素位置、相機內參和ground truth ,在訓練的第一分鐘就產生了這個緩沖。然后開始在緩沖區上迭代主訓練循環,即在每個epoch的開始,shuffle緩沖區以混合所有圖像數據的特征,在每個訓練步驟中,構建數千個特征batch,這可能同時計算數千個視圖的參數更新,這樣不僅梯度計算對于MLP回歸頭非常高效,而且梯度也是不相關的,這允許使用高學習速度來快速收斂。
3.2 課程(Curriculum)訓練
課程(Curriculum)訓練:比如像我們上課一樣,開始會講一些簡單的東西,然后再慢慢深入學習復雜的東西,類比網絡,就是開始給寬松的閾值,讓網絡學習簡單的知識,后續隨著訓練時間的進行,增大閾值,讓網絡學習復雜且魯棒的知識。
具體的,在整個訓練過程中使用一個移動的內閾值,開始時是寬松的,隨著訓練的進行,限制會越來越多,使得網絡可以專注于已經很好的預測,而忽略在姿態估計過程中RANSAC會過濾掉的不太精確的預測。
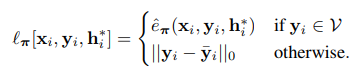
這種損失優化了所有有效坐標預測的魯棒重投影誤差π,有效的預測指在圖像平面前方10cm到1000m之間,且重投影誤差低于1000px。
再使用tanh夾持重投影誤差:
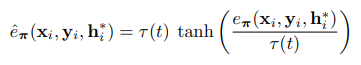
根據在訓練過程中變化的閾值τ動態地重新縮放tanh:
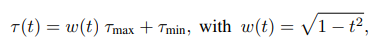
其中t∈(0,1)表示相對訓練進度。這個課程訓練實現了一個循環的τ閾值時間表,τ閾值在訓練開始時保持在附近,在訓練結束時趨于。
3.3 Backbone訓練
backbone可以使用任何密集的特征描述網絡。作者提出了一種簡單的方法來訓練一個適合場景坐標回歸的特征描述網絡。為了訓練backbone,采用DSAC*的圖像級訓練,并將其與課程訓練相結合。用N個回歸頭并行地訓練N個場景,而不是用一個回歸頭訓練一個場景的backbone。這種瓶頸架構使得backbone預測適用于廣泛場景的特性。在ScanNet的100個場景上訓練1周,得到11MB的權重,可用于在任何新場景上提取密集的描述符。
04實驗
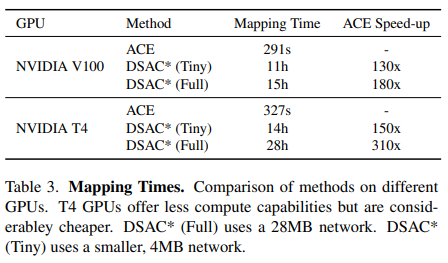
主要在兩個室內數據集7Scenes和12Scenes和一個室外數據集Cambridge上進行訓練測試:
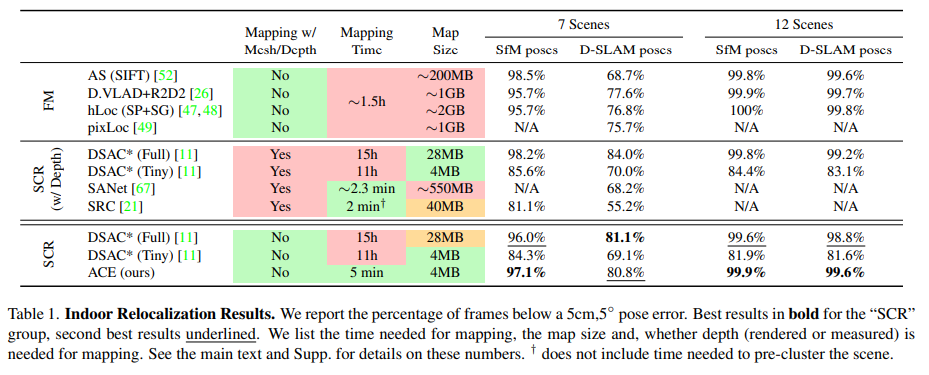
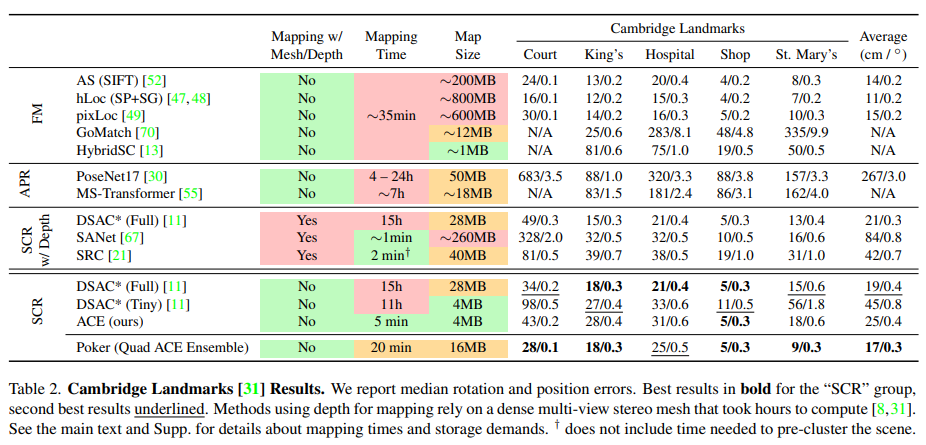
和DSAC*比較了在建圖訓練上的時間損耗:
以及在無地圖定位數據集(自己構建的 WaySpots)上的定位結果:


05總結
這是一個能夠在5分鐘內訓練新環境的重定位算法。
與之前的場景坐標回歸方法相比,將建圖的成本和存儲消耗降低了兩個數量級,使得算法具有實用性。
-
算法
+關注
關注
23文章
4622瀏覽量
93055 -
視覺
+關注
關注
1文章
147瀏覽量
23983 -
卷積網絡
+關注
關注
0文章
42瀏覽量
2184
原文標題:前沿丨CVPR 2023:視覺重定位,同等精度下速度提升300倍
文章出處:【微信號:gh_c87a2bc99401,微信公眾號:INDEMIND】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
直線電機定位精度和重復定位精度
視覺定位方案求助,謝
深圳CCD視覺檢測定位系統有什么特點?
CCD視覺定位系統在紫外激光打標機上的應用
高精度定位技術需求日益凸顯,和SKYLAB了解一下高精度定位方案
iOS 12正式版即將推出,高負載下app啟動速度最高提升至2倍
自動駕駛檢測器可同時實現3D檢測精讀和速度的提升
教你們視覺SLAM如何去提高定位精度
CVPR 2021華為諾亞方舟實驗室發表30篇論文 |CVPR 2021

華為DATS路面感知響應速度提升100倍

HighLight:視覺重定位,同等精度下速度提升300倍

CVPR 2023 | 完全無監督的視頻物體分割 RCF

激光焊接視覺定位引導方法






 工商網監
工商網監
評論