") 從零開始:入門雙目視覺你需要了解的知識
從零開始:入門雙目視覺你需要了解的知識
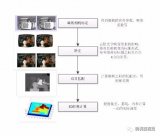
雙目立體視覺是計算機視覺中的一個重要領(lǐng)域,它利用兩個相機拍攝同一場景的不同視角的圖像,通過計算圖像之間的對應(yīng)關(guān)系,恢復(fù)出場景的三維結(jié)構(gòu)信息。雙目立體視覺的基本步驟包括雙目標定、立體校正、立體匹配和三維重建。本文將介紹這些步驟,幫助你學(xué)會從雙目標定到立體匹配的基本流程。
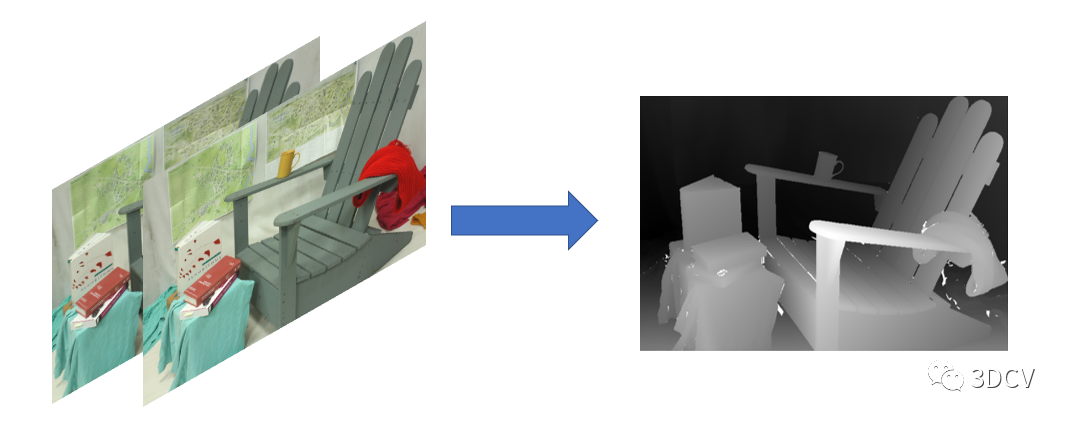
雙目相機標定
雙目標定是指確定兩個相機之間的幾何關(guān)系,包括內(nèi)參矩陣、外參矩陣和基礎(chǔ)矩陣。內(nèi)參矩陣描述了相機的內(nèi)部參數(shù),如焦距、主點坐標和畸變系數(shù)。外參矩陣描述了相機的外部參數(shù),如旋轉(zhuǎn)矩陣和平移向量。基礎(chǔ)矩陣描述了兩個圖像平面之間的對極幾何關(guān)系,即任意一點在一個圖像平面上的投影與另一個圖像平面上的對應(yīng)點所在的直線滿足一個線性方程。
雙目標定的方法有很多,常用的是基于棋盤格圖案的張氏標定法,它利用多幅不同角度拍攝的棋盤格圖像,通過提取角點坐標和求解最小二乘問題,得到兩個相機的內(nèi)參矩陣和外參矩陣,進而計算出基礎(chǔ)矩陣。

tip:除了傳統(tǒng)的標定方法的張正友標定法,還有什么標定方法?
傳統(tǒng)的標定方法:除了張正友標定法還包括椎體標定法、光柵板標定法、點追蹤標定法等,這些方法通常需要事先準備一些特定的標定物體和設(shè)備,采集一定數(shù)量的標定圖像或者對標定物體進行特殊處理,然后通過求解投影矩陣和外參矩陣等參數(shù),計算出相機的內(nèi)部參數(shù)和外部參數(shù)。
自標定方法:也稱為自標定技術(shù)或自動標定技術(shù),它是一種無需特定標定物體和設(shè)備,通過對場景中的特征點或輪廓線進行跟蹤、匹配和分析,利用統(tǒng)計學(xué)或優(yōu)化算法實現(xiàn)相機標定的方法。這種方法與傳統(tǒng)標定方法相比,具有更高的自動化程度和更廣泛的適應(yīng)性,但在精度和穩(wěn)定性上稍有不足。
基于主動視覺的標定方法:主要包括基于結(jié)構(gòu)光的方法和基于視覺后處理的方法。前者是通過光源和被測物體之間的互動關(guān)系,實現(xiàn)對相機內(nèi)部參數(shù)和外部參數(shù)的標定;后者則是利用數(shù)字圖像處理技術(shù)進行后處理,從而提高標定結(jié)果的精度和可靠性。這些方法因其高精度、高速度、無需接觸、非侵入性等優(yōu)點,在各種工業(yè)自動化、機器人視覺等領(lǐng)域都有廣泛應(yīng)用。但是標定過程復(fù)雜,設(shè)備成本高昂。
去畸變
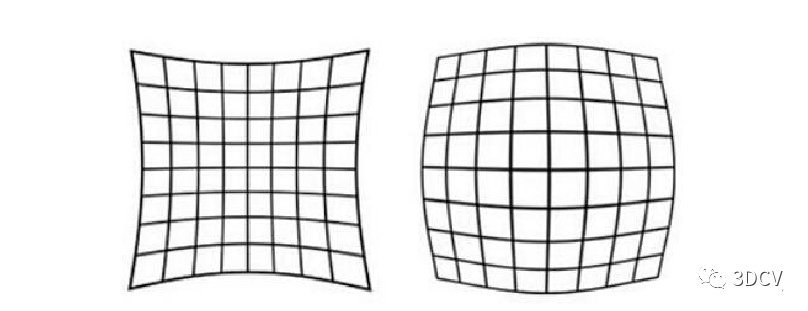
標定板法是最常用的一種方法,它可以根據(jù)標定板上的特征點計算出相機的畸變參數(shù),然后通過畸變參數(shù)對圖像進行畸變校正。自適應(yīng)分類法是一種基于圖像邊緣的方法,它可以通過檢測圖像邊緣來估計畸變參數(shù),然后對圖像進行畸變校正。以圖像邊緣為基礎(chǔ)的方法是一種基于圖像邊緣的方法,它可以通過檢測圖像邊緣來估計畸變參數(shù),然后對圖像進行畸變校正。以特征點為基礎(chǔ)的方法是一種基于特征點匹配的方法,它可以通過匹配特征點來估計畸變參數(shù),然后對圖像進行畸變校正。以直線為基礎(chǔ)的方法是一種基于直線匹配的方法,它可以通過匹配直線來估計畸變參數(shù),然后對圖像進行畸變校正。
tip:假如已經(jīng)通過張正友標定獲取了相機的內(nèi)外參數(shù),接下來去畸變都可以使用什么算法?
如果已經(jīng)獲取了相機的內(nèi)部參數(shù)和外部參數(shù),可以使用 OpenCV 庫中提供的 undistort() 函數(shù)對圖像進行去畸變處理。在這種情況下,對于常見的徑向畸變,undistort() 函數(shù)在默認情況下使用張正友畸變模型進行去畸變處理。具體實現(xiàn)過程如下:
根據(jù)所給的相機內(nèi)部參數(shù)和外部參數(shù),計算出投影矩陣 Q,即將相機坐標系下的三維點轉(zhuǎn)換到像素坐標系下的映射矩陣。
根據(jù) Q 矩陣和畸變系數(shù),計算出相機坐標系下的徑向畸變和切向畸變的校正系數(shù)。
通過校正系數(shù)對輸入的圖像進行去畸變處理。

極線校正(立體校正)
在雙目視覺中,極線校正是一項關(guān)鍵的預(yù)處理步驟,極線校正的主要目標是將左右圖像的極線對齊,并且使對應(yīng)的像素在同一行上。這樣,當進行立體匹配時,我們只需要在一條極線上搜索對應(yīng)像素,而無需在整個圖像上進行搜索。這極大地降低了計算復(fù)雜度,并提高了匹配的效率。
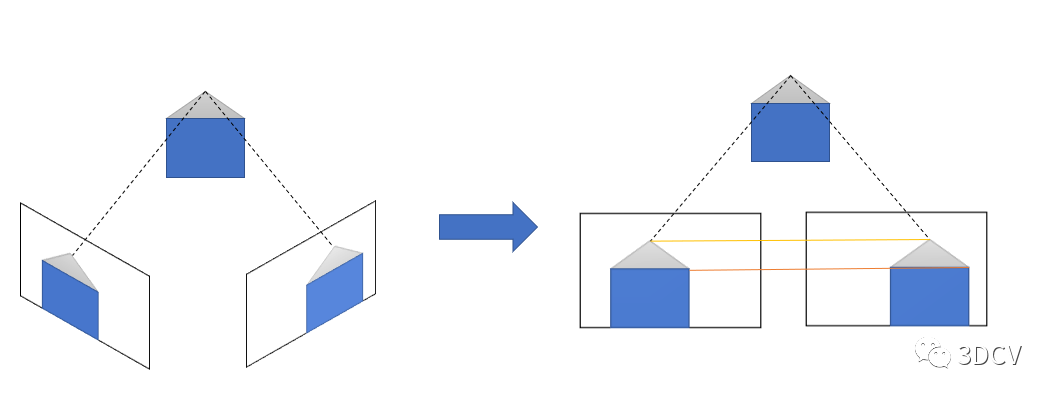
tip:有沒有不需要極線校正的立體匹配算法?極線校正是立體匹配必須要提前進行的步驟嗎?
事實上,并不一定需要進行極線校正才能進行立體匹配。以下幾種算法可以在無需進行極線校正的情況下進行立體匹配:
基于特征的匹配算法:這類算法利用圖像中的特征點(如SIFT,SURF等)進行匹配,在匹配過程中可以抵消一定角度的視角變化,無需極線校正。代表算法有SIFT立體匹配、SURF立體匹配等。
基于區(qū)塊的匹配算法:這類算法將圖像分割成多個區(qū)塊,然后在兩個圖像中的對應(yīng)區(qū)塊中尋找最相似的區(qū)塊進行匹配。匹配過程中也可以抵消一定的視角變化,無需極線校正。代表算法有區(qū)塊匹配算法等。
基于光流的匹配算法:這類算法通過計算兩個圖像之間的光流場來尋找匹配,光流計算過程可以抵消一定視角變化,所以也無需進行極線校正。代表算法有Lucas-Kanade光流算法等。
基于深度學(xué)習的匹配算法:這類算法利用深度學(xué)習網(wǎng)絡(luò)對立體圖像對進行端到端的學(xué)習和匹配,網(wǎng)絡(luò)在訓(xùn)練過程中可以學(xué)習視角變化,所以也無需進行極線校正。代表算法有PBC-Net等。
所以,總的來說,盡管極線校正可以簡化立體匹配的難度,但并不是立體匹配一定要提前進行的步驟。使用上述幾種算法都可以在無需進行極線校正的情況下實現(xiàn)立體匹配。
立體匹配
立體匹配是指尋找兩個圖像中相同物體或場景的對應(yīng)點,從而計算出它們之間的視差。視差是指同一物體在兩個圖像中投影點之間的水平距離,它與物體到相機的距離成反比,因此可以用來估計物體的深度。
立體匹配的方法有很多,以下是一些常見的立體匹配算法:
基于塊匹配的算法:這是一種經(jīng)典的立體匹配算法,它將圖像分成小的塊,然后在兩個攝像機圖像中搜索具有最小差異的塊對應(yīng)區(qū)域。常見的塊匹配算法包括貪婪匹配算法(例如最小絕對差異、最小均方差)和自適應(yīng)窗口匹配算法(例如自適應(yīng)支持窗口)。
基于特征匹配的算法:這些算法使用圖像中的特征點或特征描述符來進行匹配。特征點可以是角點、邊緣點或其他具有顯著性的圖像點。常見的特征匹配算法包括尺度不變特征變換(SIFT)、加速穩(wěn)健特征(SURF)和特征點匹配算法(例如RANSAC)。
基于能量優(yōu)化的算法:這些算法將立體匹配問題建模為能量最小化問題。通過定義能量函數(shù)和約束條件,可以使用動態(tài)規(guī)劃、圖割(graph cut)或消息傳遞等方法來求解最優(yōu)匹配。常見的能量優(yōu)化算法包括圖割算法、Belief Propagation算法和Semi-Global Matching(SGM)算法。
深度圖生成
視差圖是由兩個不同位置的相機所拍攝到的兩張圖像組成的。深度圖則是通過視差圖來計算出物體所處的深度。以下是幾種生成深度圖的算法:
基線三角化:通過已知的相機位置和視差圖的像素坐標之間的關(guān)系,使用三角化方法計算出物體深度。
統(tǒng)計學(xué)方法:通過對大量的視差數(shù)據(jù)進行簡單統(tǒng)計,去除誤差和離群點得到物體深度。
基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的方法:使用卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練模型,對輸入的視差圖進行處理,得到物體的深度圖。
基于深度學(xué)習和立體視覺的融合方法:將深度卷積神經(jīng)網(wǎng)絡(luò)(DCNN)和立體視覺算法結(jié)合起來進行深度圖生成,提高深度圖的精度和魯棒性。
tip:深度圖和視差圖有什么區(qū)別?
視差圖指存儲立體校正后單視圖所有像素視差值的二維圖像,是左圖和右圖對應(yīng)點的x差值,單位一般是像素單位。深度圖是在視差圖基礎(chǔ)上生成的圖像,它的像素值表示場景中各點到相機的距離。深度圖是一種單通道灰度圖像,其中像素值越小表示物體距離相機越近,像素值越大表示物體距離相機越遠。深度圖可以用于計算物體的三維坐標,也可用于機器視覺和計算機圖形學(xué)中的三維重建、虛擬現(xiàn)實等領(lǐng)域。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100851 -
矩陣
+關(guān)注
關(guān)注
0文章
423瀏覽量
34570 -
視覺
+關(guān)注
關(guān)注
1文章
147瀏覽量
23975
原文標題:從零開始:入門雙目視覺你需要了解的知識
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于SoC的雙目視覺ADAS解決方案
鉅芯發(fā)布業(yè)內(nèi)首顆智能雙目視覺芯片
【W(wǎng)RTnode2R申請】雙目視覺隨動平臺
從零開始入門IT編程之路
基于SoC的雙目視覺ADAS解決方案
如何從零開始入門FPGA?
LabVIEW雙目視覺 【轉(zhuǎn)載】
基于神經(jīng)網(wǎng)絡(luò)的雙目視覺傳感器建模
從零開始學(xué)電路基礎(chǔ)
雙目視覺立體匹配算法研究
雙目視覺傳感器的現(xiàn)場標定技術(shù)
一種基于圖像處理的雙目視覺校準方法
雙目視覺簡介及算法一般流程
雙目立體視覺是什么?單目視覺與雙目立體視覺的區(qū)別?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論