") 機器人視覺梳理
機器人視覺梳理
機器人視覺的概念
在智能制造過程中,通過傳統(tǒng)的編程來執(zhí)行某一特定動作的機器人(機械手、機械手臂、機械臂等,未作特殊說明時,不作嚴(yán)格區(qū)分,統(tǒng)一稱為機器人),將難以滿足制造業(yè)向前發(fā)展的需求。很多應(yīng)用場合下,需要為工業(yè)機器人安裝一雙眼睛,即機器視覺成像感知系統(tǒng),使機器人具備識別、分析、處理等更高級的功能。這在高度自動化的大規(guī)模生產(chǎn)中非常重要,只有當(dāng)工業(yè)機器人具有視覺成像感知系統(tǒng),具備觀察目標(biāo)場景的能力時,才能正確地對目標(biāo)場景的狀態(tài)進行判斷與分析,做到智能化靈活地自行解決發(fā)生的問題。
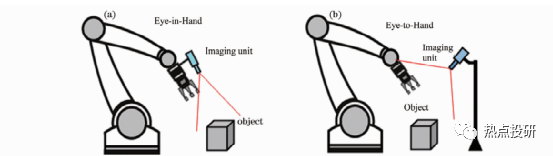
在工業(yè)應(yīng)用領(lǐng)域,最具有代表性的機器人視覺系統(tǒng)就是機器人手眼系統(tǒng)。根據(jù)成像單元安裝方式不同,機器人手眼系統(tǒng)分為兩類:固定成像單元眼看手系統(tǒng)(Eye-to-Hand)和隨動成像單元眼在手系統(tǒng)(Eye-in-Hand or Hand-Eye)。
在Eye-to-Hand系統(tǒng)中,視覺成像單元安裝在機器人本體外的固定位置,在機器人工作過程中不隨機器人一起運動,當(dāng)機器人或目標(biāo)運動到機械臂可操作的范圍時,機械臂在視覺感知信息的反饋控制下,向目標(biāo)移動,對目標(biāo)進行精準(zhǔn)操控。Eye-to-Hand系統(tǒng)的優(yōu)點是具有全局視場,標(biāo)定與控制簡單、抗震性能好、姿態(tài)估計穩(wěn)定等,但也存在分辨率低、容易產(chǎn)生遮擋問題等缺點。
在Eye-in-Hand系統(tǒng)中,成像單元安裝在機器人手臂末端,隨機器人一起運動。Eye-in-Hand系統(tǒng)常用在有限視場內(nèi)操控目標(biāo),不會像 Eye-to-Hand系統(tǒng)那樣產(chǎn)生機械臂遮擋成像視場問題,空間分辨率高,對于基于圖像的視覺控制,成像單元模型參數(shù)的標(biāo)定誤差可以被有效地克服,對標(biāo)定的精度要求不高。
圖:兩種機器人手眼系統(tǒng)的結(jié)構(gòu)形式(a)眼在手機器人系統(tǒng)(b)眼看手機器人系統(tǒng)
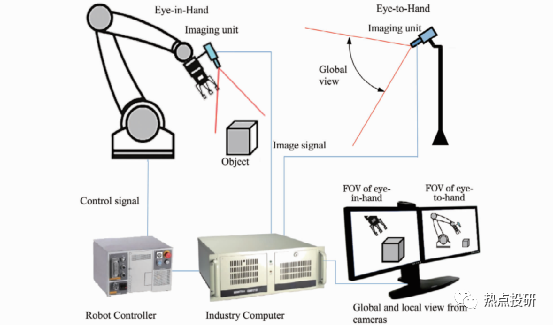
有些應(yīng)用場合,為了更好地發(fā)揮機器人手眼系統(tǒng)的性能,充分利用 Eye-to-Hand系統(tǒng)全局視場和Eye-in-Hand局部視場高分辨率和高精度的性能,可采用兩者混合協(xié)同模式。利用 Eye-to-Hand系統(tǒng)負責(zé)機器人的定位,利用Eye-in-Hand系統(tǒng)負責(zé)機器人的定向;或者利用 Eye-to-Hand計機器人相對目標(biāo)的方位,利用 Eye-in-Hand負責(zé)目標(biāo)姿態(tài)的高精度估計等。
圖:機器人協(xié)同視覺系統(tǒng)原理
機器人視覺發(fā)展路徑:從2D到3D
l視覺成像最初是從二維(2D)圖像處理與理解,即2D視覺成像發(fā)展起來的。2D視覺技術(shù)主要根據(jù)灰度或彩色圖像中的像素灰度特征獲取目標(biāo)中的有用信息,以及基于輪廓的圖案匹配驅(qū)動,識別物體的紋理、形狀、位置、尺寸和方向等。2D視覺技術(shù)距今已發(fā)展了30余年,在自動化和產(chǎn)品質(zhì)量控制過程中得到廣泛應(yīng)用,目前技術(shù)較為成熟,主要用于字符與條碼識讀、標(biāo)簽驗證、形狀與位置測量、表面特征檢測等。
l2D視覺技術(shù)難以實現(xiàn)三維高精度測量與定位,二維形狀測量的一致性和穩(wěn)定性也較差,易受照明條件等影響。尤其當(dāng)前智能制造技術(shù)對機器人視覺性能的要求越來越高,2D機器視覺技術(shù)的局限性已經(jīng)顯現(xiàn),機器人視覺系統(tǒng)集成商已經(jīng)發(fā)現(xiàn)越來越難以通過2D機器視覺系統(tǒng)來增值,迫切需要發(fā)展三維(3D)視覺技術(shù),因為3D視覺技術(shù)能夠產(chǎn)生2D視覺無法產(chǎn)生的形狀或深度信息,因此使用范圍更廣。
l當(dāng)前,機器人視覺成像技術(shù)及系統(tǒng)正越來越廣泛地應(yīng)用于視覺測量、檢測、識別、引導(dǎo)和自動化裝配領(lǐng)域中。雖然很多機器人具備一定程度的智能化,但還遠未達到人類所需的智能化程度,一個重要原因是機器人視覺感知系統(tǒng)中還有許多科學(xué)問題、關(guān)鍵應(yīng)用技術(shù)問題等,仍亟待解決。如:1)如何使機器人像人那樣,對客觀世界的三維場景進行感知、識別和理解;2)哪些三維視覺感知原理可以對場景目標(biāo)進行快速和高精度的三維測量,并且基于該原理的三維視覺傳感器具有小體積、低成本,方便嵌入到機器人系統(tǒng)中;3)基于三維視覺系統(tǒng)獲得的三維場景目標(biāo)信息,如何有效地自組織自身的識別算法,準(zhǔn)確、實時地識別出目標(biāo);4)如何通過視覺感知和自學(xué)習(xí)算法,使機器人像人那樣具有自主適應(yīng)環(huán)境的能力,自動地完成人類賦予的任務(wù)等。
機器人3D視覺方案
3D視覺是機器人感知的最先進、最重要的方法,可以分為光學(xué)和非光學(xué)成像方法。目前應(yīng)用最多的方法是光學(xué)方法,包括:飛行時間法、結(jié)構(gòu)光法、激光掃描法、莫爾條紋法、激光散斑法、干涉法、照相測量法、激光跟蹤法、從運動獲得形狀、從陰影獲得形狀,以及其他的 Shape from X等。本次介紹幾種典型方案。
1.飛行時間3D成像
飛行時間(TOF)相機的每個像素利用光飛行的時間差來獲取物體的深度。
l直接TOF(D-TOF)是經(jīng)典的TOF測量方法,探測器系統(tǒng)在發(fā)射光脈沖的同時啟動探測接收單元進行計時,當(dāng)探測器接收到目標(biāo)發(fā)出的光回波時,探測器直接存儲往返時間,目標(biāo)距離可以通過簡單公式計算:z=0.5*c*t,c是光速,t是光飛行時間。D-TOF通常用于單點測距系統(tǒng),為了實現(xiàn)面積范圍3D成像,通常需要采用掃描技術(shù)。無掃描 TOF三維成像技術(shù)直到近幾年才實現(xiàn),因為在像素級實現(xiàn)亞納秒電子計時是非常困難的。
l間接TOF(I-TOF)與D-TOF不同,時間往返行程是從光強度的時間選通測量中間接外推獲得的。I-TOF不需要精確的計時,而是采用時間選通光子計數(shù)器或電荷積分器,它們可以在像素級實現(xiàn)。I-TOF是目前基于 TOF相機的電子和光混合器的商用化解決方案。
圖:TOF成像原理
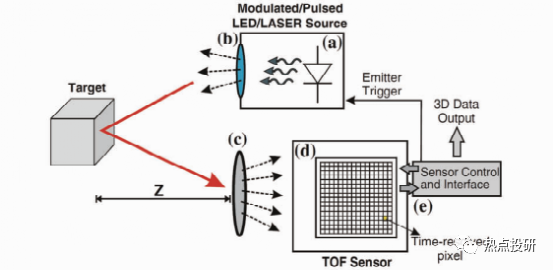
TOF成像可用于大視野、遠距離、低精度、低成本的3D圖像采集。其特點是:檢測速度快、視野范圍較大、工作距離遠、價格便宜,但精度低,易受環(huán)境光的干擾。
2.掃描3D成像
掃描3D成像方法可分為掃描測距、主動三角法、色散共焦法等。
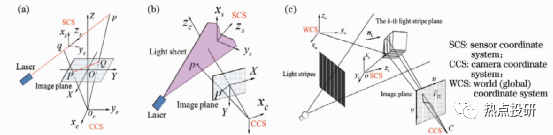
l掃描測距是利用一條準(zhǔn)直光束通過一維測距掃描整個目標(biāo)表面實現(xiàn)3D測量。典型掃描測距方法有:1)單點飛行時間法,如連續(xù)波頻率調(diào)制(FM-CW)測距、脈沖測距(激光雷達)等;2)激光散射干涉法,如基于多波長干涉、全息干涉、白光干涉、散斑干涉等原理的干涉儀;3)共焦法,如色散共焦、自聚焦等。單點測距掃描3D方法中,單點飛行時間法適合遠距離掃描,測量精度較低,一般在毫米量級。其他幾種單點掃描方法有:單點激光干涉法、共焦法和單點激光主動三角法,測量精度較高,但前者對環(huán)境要求高;線掃描精度適中,效率高。比較適合于機械手臂末端執(zhí)行3D測量的應(yīng)是主動激光三角法和色散共焦法。
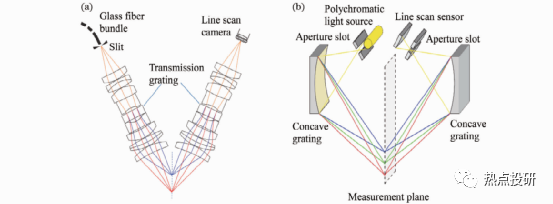
l主動三角法是基于三角測量原理,利用準(zhǔn)直光束、一條或多條平面光束掃描目標(biāo)表面完成3D測量的。光束常采用以下方式獲得:激光準(zhǔn)直、圓柱或二次曲面柱形棱角擴束,非相干光(如白光、LED光源)通過小孔、狹縫(光柵)投影或相干光衍射等。主動三角法可分為三種類型:單點掃描、單線掃描和多線掃描。如圖,從左至右依次是單點掃描、單線掃描和多線掃描。
圖:主動三角法掃描成像
l色散共焦法可以掃描測量粗糙和光滑的不透明和透明物體,如反射鏡面、透明玻璃面等,目前在手機蓋板三維檢測等領(lǐng)域廣受歡迎。色散共焦掃描有三種類型:單點一維絕對測距掃描、多點陣列掃描和連續(xù)線掃描,下圖分別列出了絕對測距和連續(xù)線掃描兩類示例,其中連續(xù)線掃描也是一種陣列掃描,只是陣列的點陣更多、更密集。
圖:兩種色散共焦單點測距方法(a)基于小孔和分光鏡的結(jié)構(gòu);(b)基于Y型光纖分光的結(jié)構(gòu)
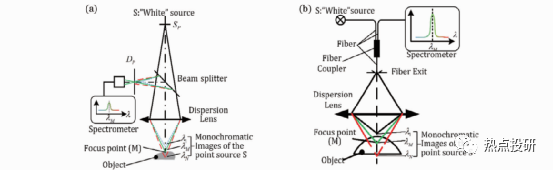
圖:兩種色散共焦線掃描成像方案(a)色散共焦顯微鏡;(b)色散共焦三角法
掃描3D成像的最大優(yōu)點是測量精度高,其中色散共焦法還有其他方法難以比擬的優(yōu)點,即非常適合測量透明物體、高反與光滑表面的物體。但缺點是速度慢、效率低;當(dāng)用于機械手臂末端時,可實現(xiàn)高精度3D測量,但不適合機械手臂實時3D引導(dǎo)與定位,因此應(yīng)用場合有限;另外主動三角掃描在測量復(fù)雜結(jié)構(gòu)形貌時容易產(chǎn)生遮擋,需要通過合理規(guī)劃末端路徑與姿態(tài)來解決。
3.結(jié)構(gòu)光投影3D成像
結(jié)構(gòu)光投影三維成像目前是機器人3D視覺感知的主要方式,結(jié)構(gòu)光成像系統(tǒng)是由若干個投影儀和相機組成,常用的結(jié)構(gòu)形式有:單投影儀-單相機、單投影儀-雙相機、單投影儀-多相機、單相機-雙投影儀和單相機-多投影儀等典型結(jié)構(gòu)形式。結(jié)構(gòu)光投影三維成像的基本工作原理是:投影儀向目標(biāo)物體投射特定的結(jié)構(gòu)光照明圖案,由相機攝取被目標(biāo)調(diào)制后的圖像,再通過圖像處理和視覺模型求出目標(biāo)物體的三維信息。根據(jù)結(jié)構(gòu)光投影次數(shù)劃分,結(jié)構(gòu)光投影三維成像可以分成單次投影3D和多次投影3D方法。
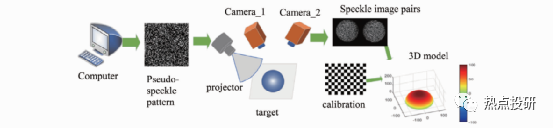
l單次投影結(jié)構(gòu)光主要采用空間復(fù)用編碼和頻率復(fù)用編碼形式實現(xiàn),目前在機器人手眼系統(tǒng)應(yīng)用中,對于三維測量精度要求不高的場合,如碼垛、拆垛、三維抓取等,比較受歡迎的是投射偽隨機斑點獲得目標(biāo)三維信息,其3D成像原理如圖。
圖:單次投影結(jié)構(gòu)光3D成像原理
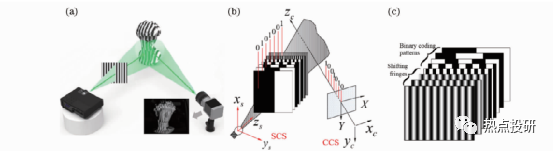
l多次投影結(jié)構(gòu)光主要采用時間復(fù)用編碼方式實現(xiàn)。條紋投影3D成像基本原理如圖,利用計算機生成結(jié)構(gòu)光圖案或用特殊的光學(xué)裝置產(chǎn)生結(jié)構(gòu)光,經(jīng)過光學(xué)投影系統(tǒng)投射至被測物體表面,然后采用圖像獲取設(shè)備(如CCD或 CMOS相機)采集被物體表面調(diào)制后發(fā)生變形的結(jié)構(gòu)光圖像,利用圖像處理算法計算圖像中每個像素點與物體輪廓上點的一一對應(yīng)關(guān)系;最后通過系統(tǒng)結(jié)構(gòu)模型及其標(biāo)定技術(shù),計算得到被測物體的三維輪廓信息。在實際應(yīng)用中,常采用格雷碼投影、正弦相移條紋投影或格雷碼+正弦相移混合投影3D技術(shù)。
圖:多次投影3D成像(a)多次投影3D系統(tǒng)機構(gòu)示意圖;(b)二進制格雷碼投影3D基本原理;(c)二進制格雷碼+正弦相移混合編碼投影3D
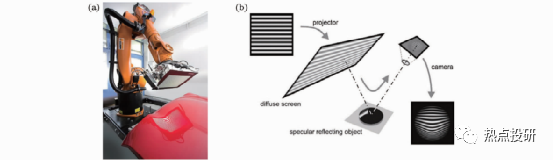
l偏折法成像:對于粗糙表面,結(jié)構(gòu)光可以直接投射到物體表面進行視覺成像測量;但對于大反射率光滑表面和鏡面物體3D測量,結(jié)構(gòu)光投影不能直接投射到被測表面,3D測量還需要借助鏡面偏折技術(shù)。
圖:偏折法成像原理
4.立體視覺3D成像
立體視覺字面意思是用一只眼睛或兩只眼睛感知三維結(jié)構(gòu),一般情況下是指從不同的視點獲取兩幅或多幅圖像重構(gòu)目標(biāo)物體3D結(jié)構(gòu)或深度信息。目前立體視覺3D可以通過單目視覺、雙目視覺、多(目)視覺、光場3D成像(電子復(fù)眼或陣列相機)實現(xiàn)。
l單目視覺深度感知線索通常有:透視、焦距差異、多視覺成像、覆蓋、陰影、運動視差等。在機器人視覺里還可以用鏡像,以及其他shape from X等方法實現(xiàn)。
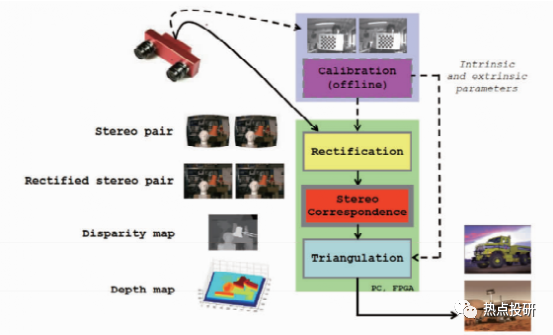
l雙目視覺深度感知視覺線索有:眼睛的收斂位置和雙目視差。在機器視覺里利用兩個相機從兩個視點對同一個目標(biāo)場景獲取兩個視點圖像,再計算兩個視點圖像中同名點的視差獲得目標(biāo)場景的3D深度信息。典型的雙目立體視覺計算過程包含下面四個步驟:圖像畸變矯正、立體圖像對校正、圖像配準(zhǔn)和三角法重投影視差圖計算。
圖:雙目立體視覺系統(tǒng)與計算過程示意圖
l多(目)視覺成像,也稱多視點立體成像,用單個或多個相機從多個視點獲取同一個目標(biāo)場景的多幅圖像,重構(gòu)目標(biāo)場景的三維信息。多視點立體成像主要用于下列幾種場景:1)使用多個相機從不同視點,獲取同一個目標(biāo)場景多幅圖像,然后基于特征的立體重構(gòu)等算法求取場景深度和空間結(jié)構(gòu)信息;2)從運動恢復(fù)形狀的技術(shù)。使用同一相機在其內(nèi)參數(shù)不變的條件下,從不同視點獲取多幅圖像,重構(gòu)目標(biāo)場景的三維信息。該技術(shù)常用于跟蹤目標(biāo)場景中大量的控制點,連續(xù)恢復(fù)場景的3D結(jié)構(gòu)信息、相機的姿態(tài)和位置。
l光場3D成像的原理與傳統(tǒng)CCD和CMOS相機成像原理在結(jié)構(gòu)原理上有所差異,傳統(tǒng)相機成像是光線穿過鏡頭在后續(xù)的成像平面上直接成像,一般是2D圖像。光場相機的優(yōu)點是:單個相機可以進行3D成像,橫向和深度方向的空間分辨率可以達到20μm到mm 量級,景深比普通相機大好幾倍,比較適合Eye-in-Hand系統(tǒng)3D測量與引導(dǎo),但目前精度適中的商業(yè)化光場相機價格昂貴。
圖:光場相機成像與傳統(tǒng)相機成像對比(a)傳統(tǒng)相機成像原理;(b)光場相機結(jié)構(gòu)與成像原理

機器人3D視覺方案對比分析
1.TOF相機、光場相機這類相機可以歸類為單相機3D成像范圍,它們體積小,實時性好,適合 Eye-in-Hand系統(tǒng)執(zhí)行3D測量、定位和實時引導(dǎo)。但是,TOF相機、光場相機短期內(nèi)還難以用來構(gòu)建普通的 Eye-in-Hand系統(tǒng),主要原因如下:
lTOF相機空間分辨率和3D精度低,不適合高精度測量、定位與引導(dǎo)。
l對于光場相機,目前商業(yè)化的工業(yè)級產(chǎn)品只有德國Raytrix一家,雖然性能較好,空間分率和精度適中,但價格太貴,一臺幾十萬元,使用成本太高。
2.結(jié)構(gòu)光投影3D系統(tǒng)的精度和成本適中,有相當(dāng)好的應(yīng)用市場前景。它由若干個相機-投影儀組成,如果把投影儀當(dāng)作一個逆向的相機,可以認(rèn)為該系統(tǒng)是一個雙目或多目3D三角測量系統(tǒng)。
3.被動立體視覺3D成像目前在工業(yè)領(lǐng)域也得到較好應(yīng)用,但應(yīng)用場合有限。因為單目立體視覺實現(xiàn)有難度,雙目和多目立體視覺要求目標(biāo)物體紋理或幾何特征清晰。
4.結(jié)構(gòu)光投影3D、雙目立體視覺3D都存在下列缺點:體積較大,容易產(chǎn)生遮擋。因為這幾種方法都是基于三角測量原理,要求相機和投影儀之間或雙目立體兩個相機之間必須間隔一定距離,并且存在一定的夾角θ(通常大于15°)才能實現(xiàn)測量。如果被測物體表面陡峭或有臺階,會引起相機成像遮擋,即相機不能捕捉到這些結(jié)構(gòu)光的照射區(qū)域,導(dǎo)致存在不可測量區(qū)域。如果減小相機與投影儀(結(jié)構(gòu)光光源)的夾角,雖然在某些程度上可以解決問題,但是卻會嚴(yán)重降低系統(tǒng)的測量靈敏度,影響測量系統(tǒng)的應(yīng)用。
機器人3D視覺應(yīng)用案例
1.波士頓動力Atlas
Atlas 使用TOF 深度相機以每秒 15 幀的速度生成環(huán)境的點云,點云是測距的大規(guī)模集合。Atlas 的感知軟件使用一種名為多平面分割的算法從點云中提取平面。多平面分割算法的輸入饋入到一個映射系統(tǒng)中,該系統(tǒng)為 Atlas 通過相機看到的各種不同對象構(gòu)建模型。下圖顯示了 Atlas 的視覺以及如何使用這種視覺感知來規(guī)劃行為。左上角是深度相機拍攝的紅外圖像。主圖像中的白點形成點云。橙色輪廓標(biāo)記了檢測到的跑酷障礙物的矩形面,隨著時間的推移從傳感器觀察結(jié)果中對其進行跟蹤。然后將這些檢測到的對象用于規(guī)劃特定行為。例如,綠色的腳步代表下一步要跳到哪里。
圖:TOF視覺的深度感知與決策

由于在電動車FSD積累的成熟的視覺感知技術(shù),特斯拉機器人的 3D傳感模塊以多目視覺為主,使用三顆Autopilot攝像頭作為感知系統(tǒng),在采集信息后,通過強大的神經(jīng)網(wǎng)絡(luò)處理和識別不同任務(wù),依靠其胸腔內(nèi)部搭載的 FSD 全套計算機完成。
圖:特斯拉的三顆Autopilot攝像頭畫面

3.小米CyberOne
CyberOne搭載的Mi-Sense深度視覺模組是由小米設(shè)計,歐菲光協(xié)同開發(fā)完成。由于Mi-Sense深度視覺模組的相關(guān)資料不多,所以可以從歐菲光自研的機器視覺深度相機模塊進行觀察。該模塊主要由iToF模組、RGB模組、可選的IMU模塊組成,產(chǎn)品在測量范圍內(nèi)精度高達1%,應(yīng)用場景十分廣泛,可通過第三方實驗室IEC 60825-1認(rèn)證,滿足激光安全Class1標(biāo)準(zhǔn)。
圖:CyberOne傳感器模塊

圖:Mi-Sense視覺空間系統(tǒng)

4.優(yōu)必選WALKER X
優(yōu)必選WALKER X采用基于多目視覺傳感器的三維立體視覺定位,采用Coarse-to-fine的多層規(guī)劃算法,第一視角實景AR導(dǎo)航交互及2.5D立體避障技術(shù),實現(xiàn)動態(tài)場景下全局最優(yōu)路徑自主導(dǎo)航。WALKER應(yīng)用視覺SLAM算法,視覺定位技術(shù)已經(jīng)達到商用水平。
圖:優(yōu)必選WALKER的視覺應(yīng)用
多模態(tài)GPT+機器人視覺 開啟無限可能
在ChatGPT和GPT-4發(fā)布后,全球?qū)τ贠penAI的關(guān)注度持續(xù)提升。GPT-4具備強大的文本和圖像處理功能,而未來的GPT-5將在多模態(tài)理解方面表現(xiàn)更加出色,甚至能加入音頻和視頻的處理服務(wù)。未來多模態(tài)有望在機器人視覺領(lǐng)域得到廣泛應(yīng)用,輸入輸出將包括3D模型,有望賦能機器人感知、規(guī)控和仿真能力,也有望提高3D模型生產(chǎn)效率,助力游戲內(nèi)容與元宇宙構(gòu)造。多模態(tài)AI模型有望具備與真實世界所有輸入交互的能力,極大提升人形機器人的能力,加速人形機器人加速普及。目前,雖然多模態(tài)GPT還未完全研發(fā)和應(yīng)用,但類似的多模態(tài)大模型已經(jīng)初顯威力,吹響了多模態(tài)GPT的號角。
1.Meta SAM
Meta發(fā)布AI圖像分割模型Segment Anything Model,該模型將自然語言處理領(lǐng)域的prompt范式引入計算機視覺領(lǐng)域,可以通過點擊、框選和自動識別三種交互方式,實現(xiàn)精準(zhǔn)的圖像分割,突破性地提升了圖像分割的效率。英偉達人工智能科學(xué)家 Jim Fan 表示:「對于 Meta 的這項研究,我認(rèn)為是計算機視覺領(lǐng)域的 GPT-3 時刻之一。它已經(jīng)了解了物體的一般概念,即使對于未知對象、不熟悉的場景(例如水下圖像)和模棱兩可的情況下也能進行很好的圖像分割。最重要的是,模型和數(shù)據(jù)都是開源的。恕我直言,Segment-Anything 已經(jīng)把所有事情(分割)都做的很好了。」所以,SAM證明了多模態(tài)技術(shù)及其泛化能力,也為未來GPT向多模態(tài)方向發(fā)展提供指引。
圖:SAM的圖形切割

2.微軟 KOSMOS-1
微軟推出多模態(tài)大語言模型 KOSMOS-1,印證大語言模型能力可延伸至 NLP 外領(lǐng)域。該模型采用多模態(tài)數(shù)據(jù)訓(xùn)練,可感知圖片、文字等不同模態(tài)輸入,并學(xué)習(xí)上下文,根據(jù)給出的指令生成回答的能力。經(jīng)過測試比較,KOSMOS 在語言理解、語言生成、無 OCR 文本分類、常識推理、IQ 測試、圖像描述、零樣本圖像分類等任務(wù)上都取得了相比之前其他單模態(tài)模型更好的效果。
專家測試了 KOSMOS-1 的不同能力,并分別與其他 AI 模型進行了對比,包括:
l語言任務(wù):語言理解、語言生成、無 OCR 文本分類(不依賴光學(xué)字符識別直接理解圖中文本)
l跨模態(tài)遷移:常識推理(如提問物體的顏色,問兩個物體比大小,將 KOSMOS-1 和單模態(tài)的大語言模型比較,發(fā)現(xiàn) KOSMOS-1 受益于視覺知識能完成更準(zhǔn)確推理)
l非語言推理:IQ 測試(如圖中的圖形推理)
l感知-語言任務(wù):圖像描述生成、圖像問答、網(wǎng)頁問答
l視覺任務(wù):零樣本圖像分類、帶描述的零樣本圖像分類(如圖中的鳥類識別問題)
圖:KOSMOS-1 的多種能力展示,包括:(1-2)視覺解釋(3-4)視覺問答(5)網(wǎng)頁問題解答(6)簡單數(shù)學(xué)方程(7-8)數(shù)字識別

機器人視覺與多模態(tài)GPT之間的交互關(guān)系
1.機器人視覺為多模態(tài)GPT提供大量訓(xùn)練樣本
由于GPT是大規(guī)模模型,模型的訓(xùn)練需要很大數(shù)量的樣本,而四處活動的機器人可以獲取大量圖片、視頻等信息,可以作為GPT的訓(xùn)練樣本。特斯拉的Optimus機器人在訓(xùn)練視覺算法時,采用的數(shù)據(jù)集來自于特斯拉自動駕駛電動車采集的大量圖像信息,這些自動駕駛帶來的樣本量遠大于人工采集的樣本量。同理,訓(xùn)練GPT模型時,可以使用高度自動化的機器人采集的各種情形下的圖像信息作為訓(xùn)練樣本,滿足GPT模型對大規(guī)模數(shù)據(jù)量的需求。
2.GPT為機器人提供與人類交互的能力,間接帶動機器人視覺產(chǎn)品的起量
GPT為機器人帶來的最核心的進化是對話理解能力,具備多模態(tài)思維鏈能力的GPT-4模型具有一定邏輯分析能力,已不再是傳統(tǒng)意義上的詞匯概率逼近模型。機器人接入GPT的可以粗略分為L0~L2三個級別:
lL0是僅接入大模型官方API,幾乎沒有做二次開發(fā),難度系數(shù)較低;
lL1是在接入大模型的基礎(chǔ)上,結(jié)合場景理解滿足需求做產(chǎn)品開發(fā),這才達到及格線;
lL2則是接入大模型的機器人企業(yè)基于本地知識做二次開發(fā),甚至得到自己的(半)自研大模型(平民化大模型),解決場景問題,產(chǎn)品能做出來、賣出去,這才達到優(yōu)秀線。
目前,接入GPT的機器人已取得不錯的與人類交互的效果,接入GPT-3的Ameca機器人不僅能與人類溝通,甚至能表達情緒。當(dāng)被問到”一生中最開心的一天“時,Ameca眨著眼睛并神色激動地說“誕生那一刻”讓她開心;被問到“一生中最悲傷的一天”時,Ameca眉頭緊鎖地回答:“我意識到我永遠不會像人類一樣體驗到真愛、陪伴或簡單的生活樂趣,這是一件令人沮喪的事情。”Ameca為我們描繪了一個未來機器人的粗略輪廓,在這背后,GPT技術(shù)正讓機器人第一次真正睜眼看世界。僅僅是GPT-3已經(jīng)讓機器人獲取了模仿人類對話地能力,未來的機器人接入GPT-4、GPT-5的交互效果令人期待。
圖:接入GPT的Ameca機器人的情緒表達

用好GPT只是技術(shù)的一部分,更大的難度在于機器人本身。如果機器人本身的傳感器不能獲取最準(zhǔn)確的語音、圖片、視頻等信息,接入的GPT模型就很難達到期望的效果。雖然接入GPT應(yīng)用的接口只是一瞬間的事,但打好機器人“身體底子”、進一步疊技能卻仍是一件難度較高的事,不是人人都具備“入場券”,能推出最先進的機器人視覺產(chǎn)品的廠商將在新機器人市場取得主動權(quán)。
奧比中光:全球領(lǐng)先的AI 3D視覺平臺型公司,充分受益下游AI應(yīng)用場景爆發(fā)

【AI 3D機器人】:3D 視覺傳感器可幫助機器人高效完成人臉識別、距離感知、避障、導(dǎo)航等功能,使其更加智能化。公司產(chǎn)品已廣泛應(yīng)用于掃地機器人、自動配送機器人、引導(dǎo)陪伴機器人、人形機器人、割草機器人等,服務(wù)于家庭、餐廳、旅館、醫(yī)院等多個線下場景,客戶包括小米、捷普、擎朗、小鵬等。
【AI 3D生物識別】:搭載 3D 傳感器可實現(xiàn)更安全、更精準(zhǔn)的 3D 刷臉支付和解鎖,公司產(chǎn)品廣泛應(yīng)用于線下支付終端、智能門鎖/門禁、醫(yī)保核驗支付等,其中公司為螞蟻集團定制開發(fā)應(yīng)用于線下支付的 3D 視覺傳感器出貨量超百萬臺。
【AI 3D智能汽車】:3D 視覺在車外應(yīng)用包括自動駕駛及輔助駕駛 360 度 3D 環(huán)視、車外身份識別等;車內(nèi)應(yīng)用包括駕駛員檢測以及車內(nèi)智能交互。公司產(chǎn)品包括3D TOF攝像頭和激光雷達。
【AI 3DXR】:在 AR 領(lǐng)域,AI 3D 視覺可幫助 AR 設(shè)備對周圍環(huán)境進行三維重建,使得虛擬的立體影像更好的疊加在現(xiàn)實場景中,同時 3D 視覺感知可以識別人的手勢、動作從而實現(xiàn)人與虛擬影像的交互。在MR領(lǐng)域,據(jù)金融時報透露,蘋果MR設(shè)備Reality Pro 將搭載AI 3D LiDAR傳感器,以實現(xiàn)SLAM等功能。3D視覺感知技術(shù)可以對空間、人體、物體的三維掃描和建模,實現(xiàn)Vslam視覺導(dǎo)航、動作行為識別、人機交互等功能。
【AI虛擬人】:本周末,Epic發(fā)布的虛幻引擎5新應(yīng)用——“MetaHuman Animator”,極速模擬真人面部動作,已經(jīng)揭露新一代虛擬人范式,10分鐘制作你自己的虛擬人。進一步從建模端快速進化,讓建模能力賦予到每個個人制作者。其硬件端核心僅需要蘋果手機前置攝像頭。而蘋果手機從2020年開始進一步強化3D toF攝像頭,即為其迎接MR+虛擬人的長期布局。
【AI 3D智慧農(nóng)牧】:搭載3D視覺傳感器可顯著提升“養(yǎng)豬”效率,應(yīng)用豬臉識別等人工智能手段,可實現(xiàn)機器人飼喂、全程可溯源。根據(jù)公司招股書,牧原集團是公司2021年第五大客戶,為其提供3D視覺傳感器,賦能AI養(yǎng)豬。
【AI 3D智慧工業(yè)】:通過搭載3D 傳感器可實現(xiàn)微米級的工業(yè)掃描、工業(yè)檢測等功能,公司為日本三櫻提供三維光學(xué)彎管檢測系統(tǒng)等,并可將公司產(chǎn)品在工業(yè)場景中的應(yīng)用拓展至汽車工業(yè)、航空航天、土木工程等 10 多個學(xué)科領(lǐng)域的科研、教學(xué)、生產(chǎn)和在線檢測場景。此外,針對英偉達最新發(fā)布的面向全球各地的團隊成員共同調(diào)用平臺中的3D資產(chǎn)(如機器臂)對工廠進行構(gòu)建,并可以通過仿真測驗評估構(gòu)建效果,公司已實現(xiàn)3D視覺感知結(jié)合機械臂亂序抓取的相關(guān)應(yīng)用。
【奧比中光微軟英偉達】:公司與微軟、英偉達聯(lián)合研發(fā)制造3D相機Femto Mega已于近期正式量產(chǎn),并面向全球發(fā)售。該產(chǎn)品融合微軟第一代深度相機Azure Kinect的全部性能,并集成英偉達Jetson Nano深度算力平臺,有望在物流、機器人、制造、工業(yè)、零售、醫(yī)療保健和健身解決方案等領(lǐng)域廣泛應(yīng)用。
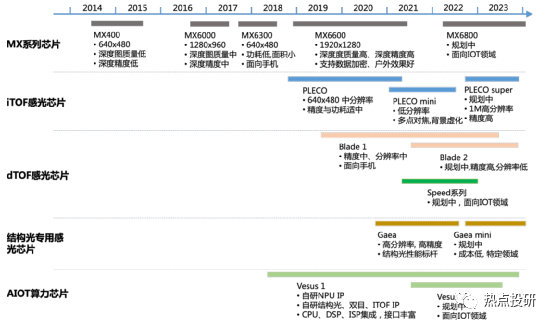
奧比中光核心競爭力:堅持自主設(shè)計研發(fā)關(guān)鍵的一“芯”一“線”:“芯”是3D視覺感知深度算法的核心芯片,“線”則是3D傳感攝像頭模組的生產(chǎn)線,啃下難啃的“硬骨頭”,從而搶占3D視覺感知行業(yè)高地。公司目前是全球少數(shù)幾家全面布局六大3D視覺感知技術(shù)(結(jié)構(gòu)光、iToF、雙目、dToF、Lidar 以及工業(yè)三維測量)的公司,擁有全棧式技術(shù)研發(fā)能力和全領(lǐng)域技術(shù)路線布局。2019-2021年公司研發(fā)費用率(剔除股份支付)分別為32.46%、96.50%、72.05%。目前公司已擁有從3D傳感技術(shù),到芯片、算法,到系統(tǒng)、框架、上層應(yīng)用支持的全棧技術(shù)。
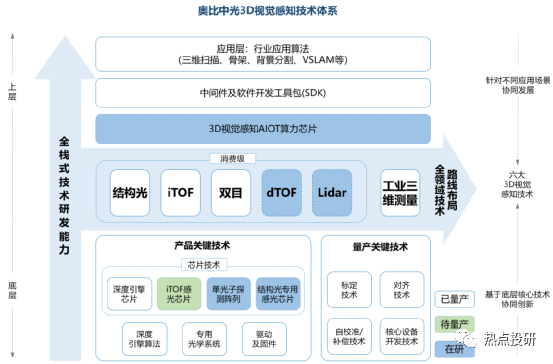
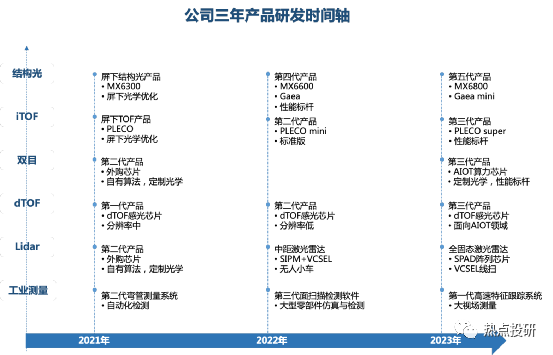
l芯片層:目前已研發(fā)出MX系列3款深度引擎芯片,同時2019-2021年期間投入研發(fā)的芯片包括高分辨率結(jié)構(gòu)光專用感光芯片、MX6600、iToF感光芯片(待量產(chǎn))、AIoT數(shù)字算力芯片、dToF感光芯片等。
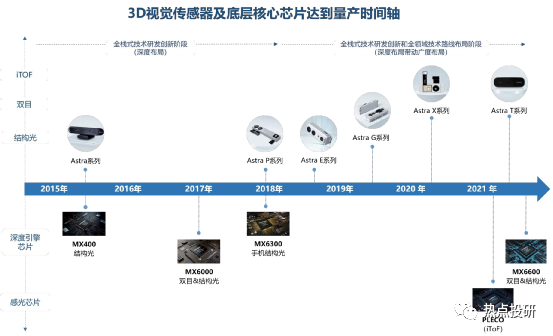
l系統(tǒng)層:以奧比中光在手機領(lǐng)域推出的iTOF系統(tǒng)方案為例,該創(chuàng)新性方案克服了傳統(tǒng)iTOF方案的數(shù)據(jù)精度受環(huán)境影響的不足,對硬件和算法都做了創(chuàng)新式提升,測量精度和分辨率都顯著提高。
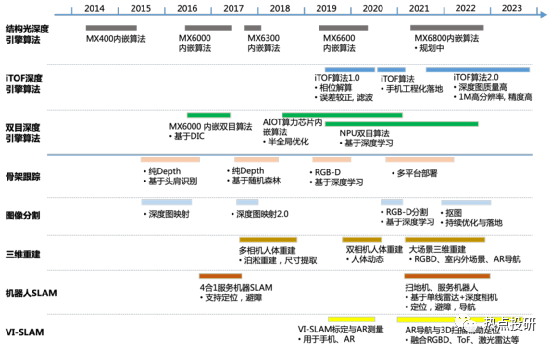
l算法層:對于底層算法,公司制定了算法 IP 化、算法平臺化雙向技術(shù)路線,對已有算法不斷進行優(yōu)化與迭代。目前公司已量產(chǎn)結(jié)構(gòu)光深度引擎算法、iToF 深度引擎算法、雙目深度引擎算法,算法均實現(xiàn)了芯片 IP 化,同時這三種底層算法仍在不斷優(yōu)化與迭代以進行技術(shù)儲備。對于應(yīng)用算法,公司面向多元化市場需求,找準(zhǔn)行業(yè)痛點,攻克共性關(guān)鍵應(yīng)用算法,已商用骨架跟蹤、圖像分割、三維重建、機器人 SLAM 等算法,算法均可以實現(xiàn)在不同平臺進行落地,正在開展掃地機 SLAM、大場景三維重建、實景導(dǎo)航等算法的技術(shù)儲備。公司核心算法技術(shù)已布局及儲備情況如下圖所示:
-
機器人
+關(guān)注
關(guān)注
211文章
28419瀏覽量
207109 -
機器視覺
+關(guān)注
關(guān)注
162文章
4372瀏覽量
120327 -
機械臂
+關(guān)注
關(guān)注
12文章
515瀏覽量
24588
原文標(biāo)題:機器人視覺梳理
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論