 詳解英偉達芯片在自動駕駛的軟件移植設計開發
詳解英偉達芯片在自動駕駛的軟件移植設計開發
NIVIDIA DRIVE Orin 系列作為一個萬用 SOC 芯片,可以用于各種不同的感知和通用計算任務,其優質的大算力、運行性能、完備的兼容性,以及豐富的 I/O 接口,可以減少系統開發的復雜度。這些特性使得 Orin 系列的芯片特別適合應用在自動駕駛系統。
整體上看,Orin系列芯片頂層SOC架構的模塊主要由三部分處理單元組成:即 CPU、GPU 和硬件加速器組成。以當前較火的Orin-x作為典型說明英偉達芯片在其軟件模塊開發中是如何進行調用的。
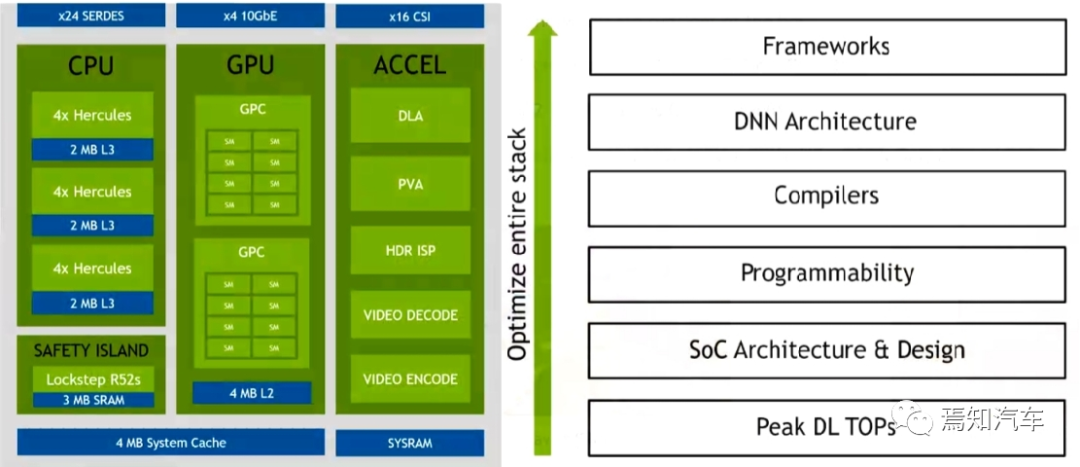
1、CPU:
Orin-x中CPU包括 12 個 Cortex-A78,可以提供通用的目標高速計算兼容性。同時,Arm Cortex R52 基于功能安全設計(FSI),可以提供獨立的片上計算資源,這樣就可以不用增加額外的 CPU(ASIL D)芯片用來提供功能安全等級。
CPU 族群所支持的特性包括 Debug 調試,電源管理,Arm CoreLink 中斷控制器,錯誤檢測與報告。
CPU 需要對芯片進行整體性能監控,每個核中的性能監控單元提供了六個計算單元,每 個單元可以計算處理器中的任何事件。基于 PMUv3 架構上,在每個 Runtime 期間這些計算 單元會收集不同的統計值并運行在處理器和存儲系統上。
2、GPU:
NVIDIA Ampere GPU 可以提供先進的并行處理計算架構。開發者可以使用 CUDA 語言進行開發(后續將對CUDA架構進行詳細說明),并支持 NVIDIA 中各種不同的工具鏈(如開發 Tensor Core 和 RT Core 的應用程序接口)。一個深度學習接口優化器和實時運行系統可以傳遞低延遲和高效輸出。Ampere GPU 同時可以提供如下一些的特性來實現對高分辨率、高復雜度的圖像處理能力(如實時光流追蹤)。
稀疏化:
細粒度結構化稀疏性使吞吐量翻倍,減少對內存消耗。浮點處理能力:每個時鐘周期內可實現 2 倍 CUDA 浮點性能。
緩存:
流處理器架構可以增加 L1 高速緩存帶寬和共享內存,減少緩存未命中延遲。提升異步計算能力,后 L2 緩存壓縮。
3、Domain-Specific:
特定域硬件加速器(DSAs、DLA、PVA)是一組特殊目的硬件引擎,實現計算引擎多任務、高效、低功率等特性。計算機視覺和深度學習簇包括兩個主要的引擎:可編程視覺加速器 PVA 和深度學習加速器 DLA(而在最新的中級算力 Orin n 芯片則取消了 DLA 處理器)。
PVA 是第二代 NVIDIA 視覺DSP架構,它是一種特殊應用指令矢量處理器,這種處理器是專門針對計算機視覺、ADAS、ADS、虛擬現實系統。PVA 有一些關鍵的要素可以很好的適配預測算法領域,且功耗和延遲性都很低。Orin-x需要通過內部的R核(Cortex-R5)子系統可以用于 PVA 控制和任務監控。一個 PVA 簇可以完成如下任務:雙向量處理單元(VPU)帶有向量核,指令緩存和 3 矢量數據存儲單元。每個單元有 7 個可見的插槽,包含可標量和向量指令。此外,每個 VPU 還含有 384 KBytes的3端口存儲容量。
DLA 是一個固定的函數引擎,可用于加速卷積神經網絡中的推理操作。Orin-x 單獨設置了 DLA 用于實現第二代 NVIDIA 的 DLA架構。DLA支持加速 CNN 層的卷積、去卷積、激活、池化、局部歸一化、全連接層。最終支持優化結構化稀疏、深度卷積、一個專用的硬件調度器,以最大限度地提高效率。
那么,怎樣利用英偉達自身的GPU和CPU上的算力進行有效的計算機視覺開發能力探測呢?
GPU的軟件架構
自動駕駛領域使用的 AI 算法多為并行結構。AI 領域中用于圖像識別的深度學習、用于決策和推理的機器學習以及超級計算都需要大規模的并行計算,更適合采用 GPU 架構。由于神經網絡的分層級數(通常隱藏層的數量越多,神經網絡模擬的結果越精確)會很大程度的影響其在預測結果。擅長并行處理的 GPU 可以很好的對神經網絡算法進行處理和優化。因為,神經網絡中的每個計算都是獨立于其他計算的,這意味著任何計算都不依賴于任何其他計算的結果,所有這些獨立的計算都可以在 GPU 上并行進行。通常 GPU 上進行的單個卷積計算要比 CPU 慢,但是對于整個任務來說,CPU 幾乎是串行處理方式,需要要逐個依次完成,因此,其速度要大大慢于 GPU。因此,卷積運算可以通過使用并行編程方法和GPU來加速。
英偉達通過 CPU+GPU+DPU 形成產品矩陣,全面發力數據中心市場。利用 GPU 在AI 領域的先天優勢,英偉達借此切入數據中心市場。針對芯片內部帶寬以及系統級互聯等 諸多問題,英偉達推出了 Bluefield DPU 和 Grace CPU,提升了整體硬件性能。
對于英偉達的GPU而言,一個 GPC 中有一個光柵引擎(ROP)和 4 個紋理處理集群(TPC),每個引擎可以訪問所有的存儲。
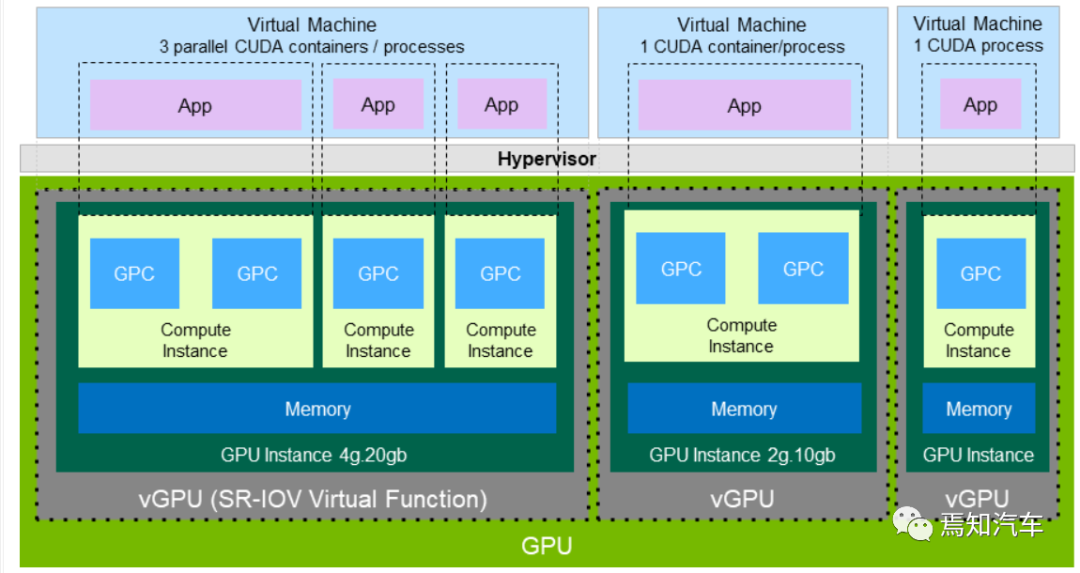
每個 TPC 包含兩路流式多媒體處理器(SM),每個 SM 有 128 個 CUDA cores,被分為 4 個單獨的處理模塊,每個模塊都有自己的指令緩沖區、調度程序和張量核心。每個TPC 也包含一個變形引擎、兩個紋理單元和兩個光線追蹤核心(RT Core)。
GPC是一種專門針對硬件模塊開發的光柵、陰影、紋理結構和計算的單元。GPU的核心圖像處理函數就是在 GPC 中實現的。在 GPC 中,SM 的 CUDA 核可以執行像素級/矢量級/幾何陰影的計算。紋理結構單元執行紋理濾波和加載/存儲獲取、數據保存到存儲器。
特殊的函數單元(SFUs)可以處理先驗的和圖像的內插指令。
Tensor Cores 執行矩陣乘法來極大加速深度學習推理。RTcore 單元通過加速邊界體積層次結構(BVH)的遍歷和光流追蹤過程中的場景幾何交叉可以輔助光流追蹤性能。
最后,多元引擎處理可以處理頂點提取、鑲嵌、視角轉換、屬性建立和視頻流輸出。SM幾何級、像素級處理執行性能可以確保其高適配性。這就可以很好地用于用戶接口和復雜的應用開發,Ampere GPU 的功率也得到了優化,可以確保其在環境提供低功耗下還能保持較高性能。
核心通用編程架構CUDA
CUDA(Compute Unified Device Architecture,統一計算架構) 作為連接 AI 的中心節點,CUDA+GPU 系統極大推動了 AI 領域的發展。搭載英偉達 GPU 硬件的工作站(Workstation)、服務器(Server)和云(Cloud)通過 CUDA軟件系統以及開發的 CUDA-XAI 庫,為自動駕駛系統 AI 計算所需要的機器學習、深度學習的訓練(Train)和推理(Inference)提供了對應的軟件工具鏈,來服務眾多的框架、云服務等等,是整個英偉達系列芯片軟件開發中必不可少的一環。
CUDA 是一個基于英偉達 GPU 平臺上面定制的特殊計算體系/算法,一般只能在英偉達的 GPU 系統上使用。這里從開發者角度我們講講在英偉達 Orin 系列芯片中如何在 CUDA架構上進行不同軟件級別開發。
1、CUDA 架構及數據處理解析
如下圖表示了 CUDA 架構示意圖,表示了CPU,GPU,應用程序,CUDA 開發庫,運行環境,驅動之間的關系如上圖所示。
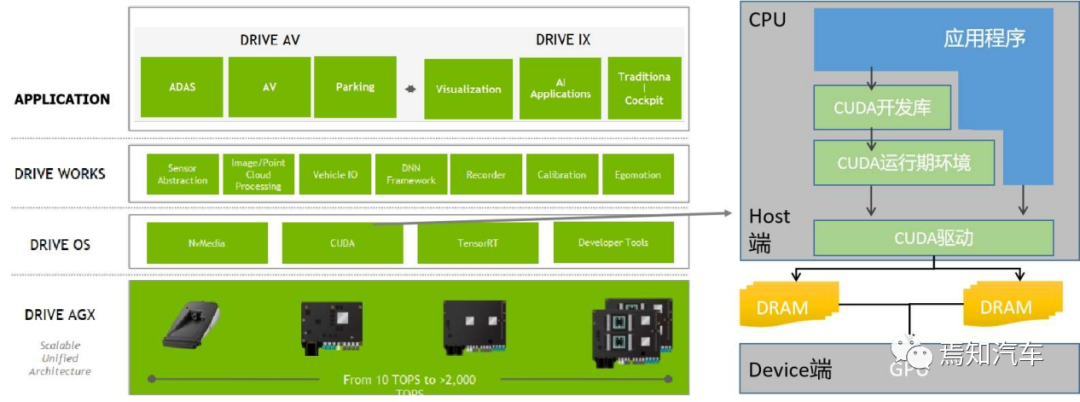
那么,如何在涵蓋 CPU 和 GPU 模塊中利用 CUDA 本身的編程語言進行開發調用呢?
從CUDA 體系結構的組成來說,它包含了三個部分:開發庫、運行期環境和驅動。
“Developer Lib 開發庫”是基于 CUDA 技術所提供的應用開發庫。例如高度優化的通用數學庫,即cuBLAS、cuSolver 和 cuFFT。核心庫,例如 Thrust 和 libcu++;通信庫, 例如 NCCL 和 NVSHMEM,以及其他可以在其上構建應用程序的包和框架。
“Runtime 運行期環境”提供了應用開發接口和運行期組件,包括基本數據類型的定義和各類計算、類型轉換、內存管理、設備訪問和執行調度等函數。
“Driver 驅動部分”是 CUDA 使能 GPU 的設備抽象層,提供硬件設備的抽象訪問接口。CUDA 提供運行期環境也是通過這一層來實現各種功能的。
目前于 CUDA 開發的應用必須有 NVIDIA CUDA-enable 的硬件支持。對于 CUDA 執行過程而言,CPU 擔任的工作是為控制 GPU 執行,調度分配任務,并能做一些簡單的計算,而大量需要并行計算的工作都交給 GPU 實現。
在 CUDA 架構下,一個程序分為兩個部份:host 端和 device 端。Host 端是指在 CPU 上執行的部份,而 device 端則是在顯示芯片(GPU)上執行的部份。Device 端的程序又稱為 "kernel"。通常 host 端程序會將數據準備好后,復制到顯卡的內存中,再由顯示芯片執行 device 端程序,完成后再由 host 端程序將結果從顯卡的內存中取回。這里需要注意的是,由于 CPU 存取顯存時只能透過 PCI Express 接口,因此速度較慢 (PCI Express x16 的理論帶寬是雙向各 4GB/s),因此不能經常進行,以免降低效率。
基于以上分析可知,針對大量并行化問題,采用 CUDA 來進行問題處理,可以有效隱藏內存的延遲性 latency,且可以有效利用顯示芯片上的大量執行單元,同時處理上千個線程 thread 。因此,如果不能處理大量并行化的問題,使用 CUDA 就沒辦法達到最好的效率了。
對于這一應用瓶頸來說,英偉達也在數據存取上做出了較大的努力提升。一方面,優化的CUDA 改進了 DRAM 的讀寫靈活性,使得GPU與CPU的機制相吻合。另一方面,CUDA提供了片上(on-chip)共享內存,使得線程之間可以共享數據。應用程序可以利用共享內存來減少 DRAM 的數據傳送,更少的依賴 DRAM 的內存帶寬。
此外,CUDA 還可以在程序開始時將數據復制進 GPU 顯存,然后在 GPU 內進行計算,直到獲得需要的數據,再將其復制到系統內存中。為了讓研發人員方便使用 GPU 的算力,英偉達不斷優化 CUDA 的開發庫及驅動系統。操作系統的多任務機制可以同時管理 CUDA 訪問 GPU 和圖形程序的運行庫,其計算特性支持利用 CUDA 直觀地編寫 GPU 核心程序。
2、CUDA 編程開發
英偉達系列芯片的應用基礎是提供一套豐富且成熟的 SDK 和庫,可以基于它們構建應用程序。CUDA 這種計算架構通過優化的各類調度算法和軟件框架,實際為開發者提供了快速可調用的底層編程代碼,可以確保開發者在編程過程中能夠最快速最有效的直接調用GPU 并行計算資源,從而最大化提升 GPU 的計算效率,助力英偉達 GPU 方便且高效地發揮其并行計算能力。
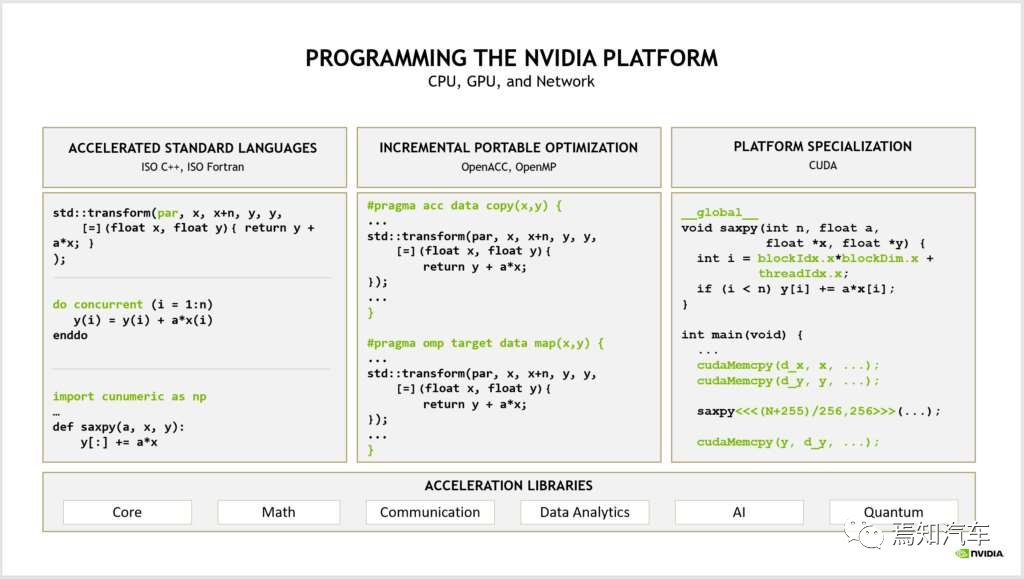
CUDA 是一種類 C 語言,本身也兼容 C 語言,所以適合普通開發者在其上編寫和移植自己的代碼和算法。總體來講,英偉達在編程方式上分成了如下三種不同的模式。如下圖表示了各種編程語言之間的關系:
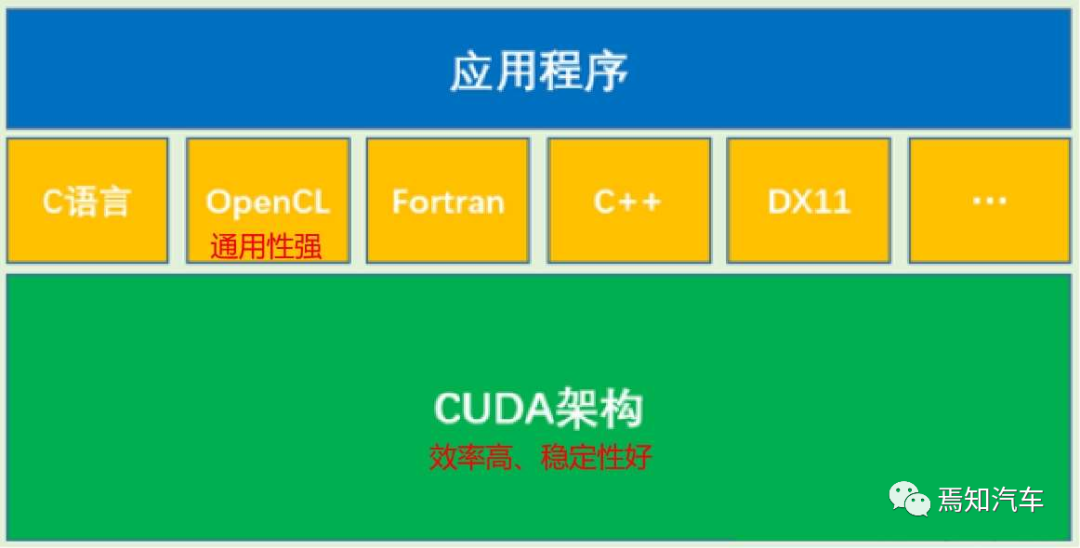
? 針對文本主題通常采用標準語言并行開發;針對性能優化的平臺專用語言,如 C++、Fortran、OpenCL 等;其中,OpenCL 也可以實現對 GPU 計算能力的調用,但由于其通用性較強,整體優化效果不如 CUDA, 在大規模計算中劣勢很大。CUDA 架構是 OpenCL 的運行平臺之一,OpenCL僅僅是為 CUDA 架構提供了一個可編程的 API 而已。也就是相當于 API 與執行架構之間的關系。
針對如上標準語言和專用語言所定制的編譯器指令,可以通過啟用增量性能優化來彌合這兩種方式之間的差距。從而在性能、生產率和代碼可移植性方面進行權衡。
如下圖表示了一種典型的 CUDA 架構優化后相對于 CPU、GPU 在軟件編程上的性能提升。
為什么CUDA能夠起到比CPU和GPU更好的運算效果呢?
實際上是對于同一個計算輸入采用的不同計算方法。舉個例子,考慮1至100的累加,如果是CPU,最終運算量計算結果則是需要調用執行同一個累加函數100次;而GPU如果并行計算如果有4核,則是4個主線同時運算這個算式,則計算量則是前者的1/4;而CUDA計算模式則可以看成優化的GPU,即在這種常規的累加計算上,也會采用一些“討巧”的方式進行。比如考慮累加的首尾兩側加起來都是100(比如1+99,2+98,3+97...),因此,只需要考慮這種計算的累加次數就可以直接很快計算出結果了。從這個例子上看,CUDA的計算方式至少可以比單純地GPU減少一半的計算量。
3、CUDA的典型數學庫
類似于CPU編程庫,CUDA庫作為一系列接口的集合,只需要編寫host代碼,調用相應API即可實現各種函數功能,這樣可以節約很多開發時間。并且CUDA的庫都是經過大量的編程能力強的大拿經過不斷優化形成的,因此我們完全可以信任這些庫能夠達到很好的性能。當然,完全依賴于這些庫而對CUDA性能優化一無所知也是不行的,我們依然需要手動做一些改進來挖掘出更好的性能。
CUDA上常用的庫包括如下幾種:
cuSPARSE線性代數庫,主要針對稀疏矩陣之類的
cuBLAS是CUDA標準的線性代數庫,該庫沒有專門針對稀疏矩陣的操作
cuFFT傅里葉變換,用于內核加載時機和方式
cuRAND隨機數,用于隨機數的計算。
cuBLASLt
cuBLASLt 使用新的 FP8 數據類型公開混合精度乘法運算。這些操作還支持 BF16 和 FP16 偏差融合,以及 FP16 偏差與 GELU 激活融合,用于具有 FP8 輸入和輸出數據類型的 GEMM。
在性能方面,與 A100 上的 BF16 相比,FP8 GEMM 在 H100 PCIe 和 SXM 上的速度分別提高了 3 倍和 4.5 倍。CUDA Math API 提供 FP8 轉換以方便使用新的 FP8 矩陣乘法運算。
cuBLAS 12.0 擴展了 API 以支持 64 位整數問題大小、前導維度和向量增量。這些新函數與其對應的 32 位整數函數具有相同的 API,只是它們在名稱中具有 _64 后綴并將相應的參數聲明為 int64_t。
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result);
對應的 64 位整數如下:
cublasStatus_t cublasIsamax_64(cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);
cuFFT
在計劃初始化期間,cuFFT 執行一系列步驟(包括試探法)是用來確定使用了哪些內核以及內核模塊如何加載。從 CUDA 12.0 開始,cuFFT 使用 CUDA 并行線程執行 (PTX) 匯編形式而不是二進制形式交付了大部分內核。
當cuFFT 計劃初始化時,cuFFT 內核的 PTX 代碼在運行時由 CUDA 設備驅動程序加載并進一步編譯為二進制代碼。由于新的實施,第一個可用的改進將為 NVIDIA Maxwell、NVIDIA Pascal、NVIDIA Volta 和 NVIDIA Turing 架構啟用許多新的加速內核。
cuSPARSE
為了減少稀疏矩陣乘法 (SpGEMM) 所需的工作空間,NVIDIA 發布了兩種內存使用率較低的新算法。第一種算法計算中間產物數量的嚴格界限,而第二種算法允許將計算分成塊。這些新算法有利于使用較小內存存儲設備的客戶。
最新INT8 已支持添加到 cusparseGather、cusparseScatter 和 cusparseCsr2cscEx2幾種不同的函數模塊中。
最后需要說明的是,最新版本中的CUDA也加入了延遲加載作為其中一部分。隨后的 CUDA 版本繼續增強和擴展它。從應用程序開發的角度來看,選擇延遲加載不需要任何特定的東西。現有的應用程序可以按原樣使用延遲加載。延遲加載是一種延遲加載內核和 CPU 端模塊直到應用程序需要加載的技術。默認是在第一次初始化庫時搶先加載所有模塊。這不僅可以顯著節省設備和主機內存,還可以縮短算法的端到端執行時間。
總結
本文從英偉達中的幾個核心軟件模塊GPU和CUDA開發角度分析了其在整個軟件框架構建,軟件算法調度及軟件函數構建和應用上進行了詳細的分析。重點是可以很好的掌握整個Orin系列的軟件架構,與前序文章的硬件架構相呼應。當然,從整個軟件開發的完整流程上,本文還只是入門級的說明,對于精細化的開發還是遠遠不夠的。后續文章我們將從操作系統Drive OS/驅動模塊Drive Work等角度進行更為詳細的分析。
-
soc
+關注
關注
38文章
4188瀏覽量
218612 -
英偉達
+關注
關注
22文章
3815瀏覽量
91491 -
自動駕駛
+關注
關注
784文章
13896瀏覽量
166694
原文標題:詳解英偉達芯片在自動駕駛的軟件移植設計開發
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達CEO稱若特斯拉自動駕駛芯片項目失敗,愿提供幫助
英偉達何以成為車廠自動駕駛開發的首選
AI/自動駕駛領域的巔峰會議—國際AI自動駕駛高峰論壇
不懼特斯拉威脅,英偉達研發自動駕駛汽車芯片
英偉達DRIVE AGX Xavier開發套件就是一個用于構建自動駕駛系統的平臺
英偉達開源自動駕駛算法,其芯片性能高7倍于Xavier
Einride將使用英偉達自動駕駛計算平臺
英偉達最新推出的自動駕駛芯片Atlan詳解

自動駕駛備受關注 小馬智行完成D輪融資 英偉達將量產自動駕駛芯片DRIVE Orin
自動駕駛芯片現狀盤點 國產自動駕駛芯片發展面臨的機遇和挑戰
擴充自動駕駛中國團隊,英偉達開放上百個職位
高通自動駕駛靠軟件開發革新力壓英偉達自動駕駛芯片





 工商網監
工商網監
評論