 大語言模型中的常用評估指標
大語言模型中的常用評估指標
大語言模型中的常用評估指標
EM
EM 是 exact match 的簡稱,所以就很好理解,em 表示預測值和答案是否完全一樣。
defcalc_em_score(answers,prediction): em=0 foransinanswers: #刪掉標點符號 ans_=remove_punctuation(ans) prediction_=remove_punctuation(prediction) ifans_==prediction_: #只有在預測和答案完全一樣時em值為1,否則為0 em=1 break returnem
F1
分別計算準確率和召回率, F1 是準確率和召回率的調和平均數。
defcalc_f1_score(answers,prediction): f1_scores=[] foransinanswers: #分詞后的答案,分詞方法參見附錄2 ans_segs=mixed_segmentation(ans,rm_punc=True) #分詞后的預測 prediction_segs=mixed_segmentation(prediction,rm_punc=True) #計算答案和預測之間的最長公共子序列,參見附錄1 lcs,lcs_len=find_lcs(ans_segs,prediction_segs) iflcs_len==0: f1_scores.append(0) continue #準確率和lcs_len/len(prediction_segs)成正比 precision=1.0*lcs_len/len(prediction_segs) #召回率和lcs_len/len(ans_segs)成正比 recall=1.0*lcs_len/len(ans_segs) #準確率和召回率的調和平均數 f1=(2*precision*recall)/(precision+recall) f1_scores.append(f1) returnmax(f1_scores)
對于準確率和召回率增加下了解。看一個例子,如下圖所示,方框代表全集,黃色圈代表正確結果集合,斜紋圈代表返回的預測結果。這樣就構成了如下幾個部分:
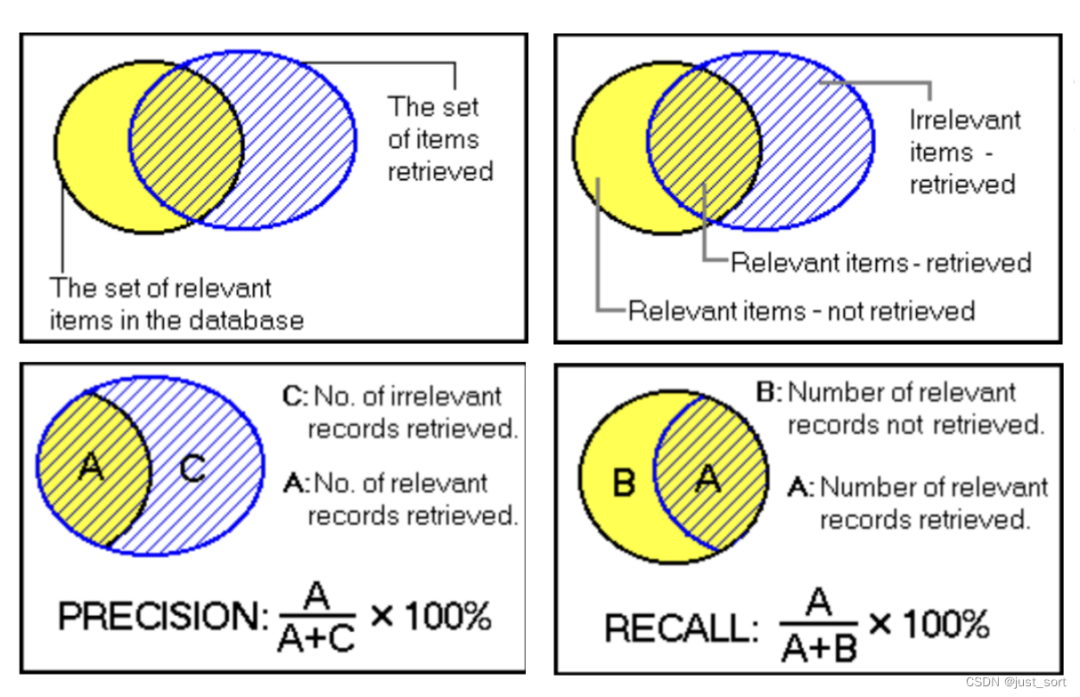
在這里插入圖片描述
方框代表全集;
黃色圈代表正確結果集合;
斜紋圈代表返回的預測結果,也叫召回結果;
A 代表正確的、召回的部分,也叫 True Positive(TP);
C代表錯誤的、召回的部分,也叫 False Positive (FP);
B代表錯誤的、沒召回的部分,也叫 False Negative (FN);
方框之內、兩個圓圈之外的部分,代表正確的、沒召回的部分,叫 True Negative (FN);
這時再來看 F1 的計算,就更直觀了:

在這里插入圖片描述
precision 代表著召回結果中的正確比例,評估的是召回的準確性;recall 代表正確召回結果占完整結果的比例,考慮的是召回的完整性;F1 既考慮了正確性,又考慮了完整性。
Accuracy 和 Accuracy norm
有了上面對 TP、FP、TN、FN 的定義,這里可以直接給出 Accuracy 的計算公式:
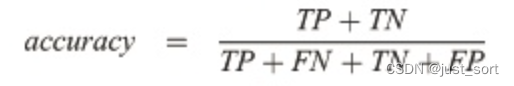
在這里插入圖片描述
可以看出 accuracy 代表正確的(正確的、召回的部分 + 正確的、沒召回的部分)比例。適合于離散的結果、分類任務,比如選擇題。
但是看 lm-evaluation-harness 中的 accuracy 又不完全遵循上面的定義:
defprocess_results(self,doc,results):
gold=doc["gold"]
#分數最高的作為預測結果和目標答案做對比
acc=1.0ifnp.argmax(results)==goldelse0.0
#考慮選項長度
completion_len=np.array([float(len(i))foriindoc["choices"]])
acc_norm=1.0ifnp.argmax(results/completion_len)==goldelse0.0
return{
"acc":acc,
"acc_norm":acc_norm,
}
lm-evaluation-harness 在計算acc時,先用模型為每個選項計算出的分數(例如,對數似然值)中,選出其中最大的作為預測結果。如果預測結果對應的選項索引和真實的正確選項索引相同,那么 accuracy 就是 1,否則為0;
Accuracy norm(歸一化準確率),這個指標在計算過程中,會對模型計算出的每個選項的分數進行歸一化。歸一化的方法是將每個選項的分數除以選項的長度(字符數)。這樣就得到了一個考慮了選項長度影響的新的分數列表。根據這個新的分數選取最大的分數的選項作為答案。
Perplexity 困惑度
困惑度(perplexity)的基本思想是:模型對于一個測試集中的句子,計算這個句子中詞組合出現的概率,概率越高,困惑度越低,模型性能就證明是越好。
1、一個句子的概率,有如下定義,x 代表一個字符,它們組合在一起構成一個句子,句子的概率就等于詞的概率相乘:

在這里插入圖片描述
unigram 對應只考慮一個詞出現概率的算法,相當于詞出現概率相互獨立;
bigram 對應條件概率考慮連續的兩個詞的概率;
而 trigram 對應條件概率考慮連續的三個詞的概率。
2、困惑度的計算:
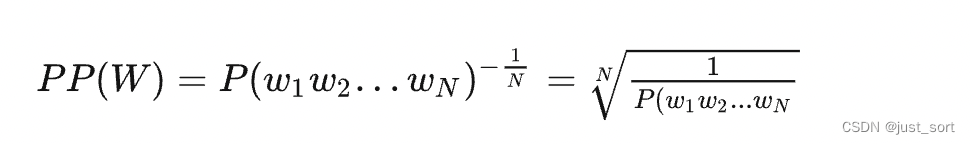
在這里插入圖片描述
#輸入一個句子sentence #輸入模型算出的uni_gram_dict【unigram,單詞的概率表】和bi_gram_dict【bigram,兩個詞的概率表】 #返回困惑度 defperplexity(sentence,uni_gram_dict,bi_gram_dict): #分詞 sentence_cut=list(jieba.cut(sentence)) #句子長度 sentence_len=len(sentence_cut) #詞匯量 V=len(uni_gram_dict p=1#概率初始值 k=0.5# ngram 的平滑值,平滑方法:Add-k Smoothing (k<1) ????for?i?in?range(sentence_len-1): ????????two_word?=?"".join(sentence_cut[i:i+2]) ????????#?(bi_gram_dict.get(two_word,0)+k)/(uni_gram_dict.get(sentence_cut[i],0)?即兩個詞的條件概率 ????????p?*=(bi_gram_dict.get(two_word,0)+k)/(uni_gram_dict.get(sentence_cut[i],0)+k*V) ????#?p?是?sentence?的概率 ????#?返回困惑度 ????return?pow(1/p,?1/sentence_len)
所以對一個句子的困惑度就是該模型得出的句子出現的概率的倒數,再考慮句子長度對該倒數做一個幾何平均數。
對于一個正確的句子,如果模型得出的困惑度越低,代表模型性能越好。
進一步參考資料
概述NLP中的指標
附錄
附錄1、最長公共子序列
#最長公共子序列 deffind_lcs(s1,s2): #申請一個二維矩陣,維度為len(s1)+1和len(s2)+1 #m[i+1][j+1]表示s2[i]和s2[i]位置對齊時,前面的以對齊位置為終點的最長公共子序列長度 m=[[0foriinrange(len(s2)+1)]forjinrange(len(s1)+1)] mmax=0 p=0 foriinrange(len(s1)): forjinrange(len(s2)): #動態規劃算法:以 s2[i]和 s2[j]位置對齊時, #如果s1[i]不等于s2[j],以對齊位置為終點的最長公共子序列長度為0, #如果s1[i]等于s2[j],以對齊位置為終點的最長公共子序列長度為 #以s2[i-1]和s2[j-1]位置對齊和為終點的最長公共子序列長度加1 ifs1[i]==s2[j]: m[i+1][j+1]=m[i][j]+1 ifm[i+1][j+1]>mmax: mmax=m[i+1][j+1] p=i+1 #返回最長的公共子序列和其長度 returns1[p-mmax:p],mmax
附錄2、分詞
#考慮英文和數字的分詞 #例子:tvb電視臺已于2006年買下播映權-> #['tvb','電','視','臺','已','于','2006','年','買','下','播','映','權'] defmixed_segmentation(in_str,rm_punc=False): in_str=str(in_str).lower().strip() segs_out=[] #storeenglishandnumber,everyelementisachar temp_str="" sp_char=['-',':','_','*','^','/','\','~','`','+','=', ',','。',':','?','!','“','”',';','’','《','》','……','·','、', '「','」','(',')','-','~','『','』'] forcharinin_str: ifrm_puncandcharinsp_char: continue ifre.search(r'[u4e00-u9fa5]',char)orcharinsp_char: iftemp_str!="": ss=nltk.word_tokenize(temp_str) segs_out.extend(ss) temp_str="" segs_out.append(char) else: temp_str+=char #handlinglastpart iftemp_str!="": ss=nltk.word_tokenize(temp_str) segs_out.extend(ss) returnsegs_out
-
計算
+關注
關注
2文章
450瀏覽量
38806 -
模型
+關注
關注
1文章
3244瀏覽量
48845 -
語言模型
+關注
關注
0文章
524瀏覽量
10277
原文標題:大語言模型中的常用評估指標
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

【大語言模型:原理與工程實踐】核心技術綜述
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
使用單值評估指標進行優化
基于免疫網絡的信息安全風險評估模型
網絡安全評估指標優化模型

機器學習算法常用指標匯總

機器學習模型評估的11個指標
清華大學大語言模型綜合性能評估報告發布!哪個模型更優秀?






 工商網監
工商網監
評論