 基于 RNN 的解碼器架構如何建模
基于 RNN 的解碼器架構如何建模
Vaswani 等人在其名作 Attention is all you need 中首創了基于 transformer的編碼器-解碼器模型,如今已成為自然語言處理 (natural language processing,NLP) 領域編碼器-解碼器架構的事實標準。
最近基于 transformer 的編碼器-解碼器模型訓練這一方向涌現出了大量關于預訓練目標函數的研究,例如T5、Bart、Pegasus、ProphetNet、Marge 等,但它們所使用的網絡結構并沒有改變。
本文的目的是詳細解釋如何用基于 transformer 的編碼器-解碼器架構來對序列到序列 (sequence-to-sequence)問題進行建模。我們將重點關注有關這一架構的數學知識以及如何對該架構的模型進行推理。在此過程中,我們還將介紹 NLP 中序列到序列模型的一些背景知識,并將基于 transformer的編碼器-解碼器架構分解為編碼器和解碼器這兩個部分分別討論。我們提供了許多圖例,并把基于 transformer的編碼器-解碼器模型的理論與其在 transformers 推理場景中的實際應用二者聯系起來。請注意,這篇博文不解釋如何訓練這些模型 —— 我們會在后續博文中涵蓋這一方面的內容。
基于 transformer 的編碼器-解碼器模型是表征學習和模型架構這兩個領域多年研究成果的結晶。本文簡要介紹了神經編碼器-解碼器模型的歷史,更多背景知識,建議讀者閱讀由 Sebastion Ruder 撰寫的這篇精彩 博文。此外,建議讀者對自注意力 (self-attention) 架構有一個基本了解,可以閱讀 Jay Alammar 的 這篇博文 復習一下原始 transformer 模型。
截至本文撰寫時, transformers 庫已經支持的編碼器-解碼器模型有:T5、Bart、MarianMT以及Pegasus,你可以從 這兒 獲取相關信息。
本文分 4 個部分:
背景-簡要回顧了神經編碼器-解碼器模型的歷史,重點關注基于 RNN 的模型。
編碼器-解碼器-闡述基于 transformer 的編碼器-解碼器模型,并闡述如何使用該模型進行推理。
編碼器-闡述模型的編碼器部分。
解碼器-闡述模型的解碼器部分。
每個部分都建立在前一部分的基礎上,但也可以單獨閱讀。
背景
自然語言生成 (natural language generation,NLG) 是 NLP 的一個子領域,其任務一般可被建模為序列到序列問題。這類任務可以定義為尋找一個模型,該模型將輸入詞序列映射為目標詞序列,典型的例子有摘要和翻譯。在下文中,我們假設每個單詞都被編碼為一個向量表征。因此,個輸入詞可以表示為個輸入向量組成的序列:
因此,序列到序列問題可以表示為找到一個映射,其輸入為個向量的序列,輸出為個向量的目標序列。這里,目標向量數是先驗未知的,其值取決于輸入序列:
Sutskever 等 (2014) 的工作指出,深度神經網絡 (deep neural networks,DNN)“盡管靈活且強大,但只能用于擬合輸入和輸出維度均固定的映射。”
因此,要用使用 DNN 模型解決序列到序列問題就意味著目標向量數必須是先驗已知的,且必須獨立于輸入。這樣設定肯定不是最優的。因為對 NLG 任務而言,目標詞的數量通常取決于輸入內容,而不僅僅是輸入長度。例如,一篇 1000 字的文章,根據內容的不同,有可能可以概括為 200 字,也有可能可以概括為 100 字。
2014 年,Cho 等人 和 Sutskever 等人 提出使用完全基于遞歸神經網絡 (recurrent neural networks,RNN) 的編碼器-解碼器模型來解決序列到序列任務。與 DNN 相比,RNN 支持輸出可變數量的目標向量。下面,我們深入了解一下基于 RNN 的編碼器-解碼器模型的功能。
在推理過程中,RNN 編碼器通過連續更新其隱含狀態對輸入序列進行編碼。我們定義處理完最后一個輸入向量后的編碼器隱含狀態為。因此,編碼器主要完成如下映射:
然后,我們用來初始化解碼器的隱含狀態,再用解碼器 RNN 自回歸地生成目標序列。
下面,我們進一步解釋一下。從數學角度講,解碼器定義了給定隱含狀態下目標序列的概率分布:
根據貝葉斯法則,上述分布可以分解為每個目標向量的條件分布的積,如下所示:
因此,如果模型架構可以在給定所有前驅目標向量的條件下對下一個目標向量的條件分布進行建模的話:
那它就可以通過簡單地將所有條件概率相乘來模擬給定隱藏狀態下任意目標向量序列的分布。
那么基于 RNN 的解碼器架構如何建模
呢?
從計算角度講,模型按序將前一時刻的內部隱含狀態和前一時刻的目標向量映射到當前內部隱含狀態和一個logit 向量(下圖中以深紅色表示):
此處,為 RNN 編碼器的輸出。隨后,對 logit 向量進行softmax操作,將其變換為下一個目標向量的條件概率分布:
更多有關 logit 向量及其生成的概率分布的詳細信息,請參閱腳注。從上式可以看出,目標向量的分布是其前一時刻的目標向量及前一時刻的隱含狀態的條件分布。而我們知道前一時刻的隱含狀態依賴于之前所有的目標向量,因此我們可以說 RNN 解碼器隱式(或間接) 地建模了條件分布。
目標向量序列的概率空間非常大,因此在推理時,必須借助解碼方法對 =對 進行采樣才能高效地生成最終的目標向量序列。
給定某解碼方法,在推理時,我們首先從分布中采樣出下一個輸出向量; 接著,將其添加至解碼器輸入序列末尾,讓解碼器 RNN 繼續從中采樣出下一個輸出向量,如此往復,整個模型就以自回歸的方式生成了最終的輸出序列。
基于 RNN 的編碼器-解碼器模型的一個重要特征是需要定義一些特殊向量,如(終止符) 和 (起始符) 向量。向量通常意味著中止,出現這個即“提示”編碼器輸入序列已結束; 如果它出現在目標序列中意味著輸出結束,一旦從 logit 向量中采樣到,生成就完成了。向量用于表示在第一步解碼時饋送到解碼器 RNN 的輸入向量。為了輸出第一個 logit,需要一個輸入,而由于在其之前還沒有生成任何輸入,所以我們饋送了一個特殊的輸入向量到解碼器 RNN。好,有點繞了!我們用一個例子說明一下。
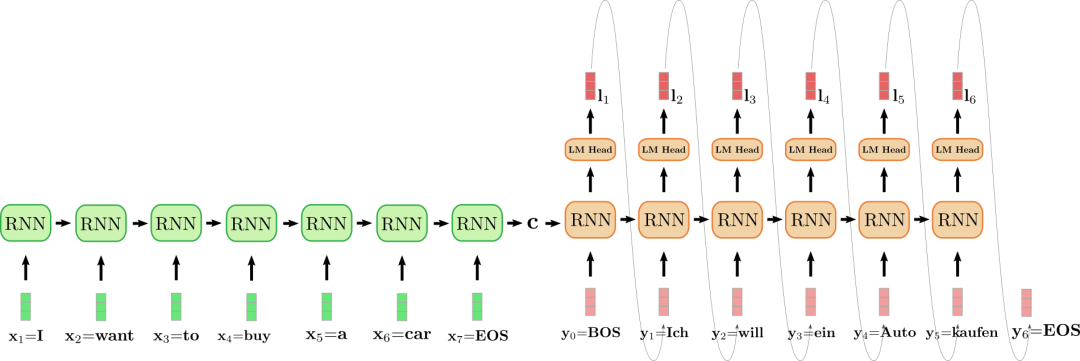
上圖中,我們將編碼器 RNN 編碼器展開,并用綠色表示; 同時,將解碼器 RNN 展開,并用紅色表示。
英文句子I want to buy a car,表示為,,,,,,)。將其翻譯成德語: “Ich will ein Auto kaufen",表示為,,,,,,)。首先,編碼器 RNN 處理輸入向量并更新其隱含狀態。請注意,對編碼器而言,因為我們只對其最終隱含狀態感興趣,所以我們可以忽略它的目標向量。然后,編碼器 RNN 以相同的方式依次處理輸入句子的其余部分:、、、、、,并且每一步都更新其隱含狀態,直到遇到向量。在上圖中,連接展開的編碼器 RNN 的水平箭頭表示按序更新隱含狀態。編碼器 RNN 的最終隱含狀態,由表示,其完全定義了輸入序列的編碼,并可用作解碼器 RNN 的初始隱含狀態。可以認為,解碼器 RNN 以編碼器 RNN 的最終隱含狀態為條件。
為了生成第一個目標向量,將向量輸入給解碼器,即上圖中的。然后通過語言模型頭 (LM Head)前饋層將 RNN 的目標向量進一步映射到 logit 向量,此時,可得第一個目標向量的條件分布:
最終采樣出第一個目標詞(如圖中連接和 的灰色箭頭所示)。接著,繼續采樣出第二個目標向量:
依此類推,一直到第 6 步,此時從中采樣出,解碼完成。輸出目標序列為, 即上文中的 “Ich will ein Auto kaufen”。
綜上所述,我們通過將分布分解為和 的表示來建模基于 RNN 的 encoder-decoder 模型:
在推理過程中,利用高效的解碼方法可以自回歸地生成目標序列。
基于 RNN 的編碼器-解碼器模型席卷了 NLG 社區。2016 年,谷歌宣布用基于 RNN 的編碼器-解碼器單一模型完全取代其原先使用的的含有大量特征工程的翻譯服務 (參見此處)。
然而,基于 RNN 的編碼器-解碼器模型存在兩個主要缺陷。首先,RNN 存在梯度消失問題,因此很難捕獲長程依賴性,參見Hochreiter 等 (2001) 的工作。其次,RNN 固有的循環架構使得在編碼時無法進行有效的并行化,參見Vaswani 等 (2017) 的工作。
論文的原話是“盡管 DNN 具有靈活性和強大的功能,但它們只能應用于輸入和目標可以用固定維度的向量進行合理編碼的問題”,用在本文時稍作調整。
這同樣適用于卷積神經網絡 (CNN)。雖然可以將可變長度的輸入序列輸入 CNN,但目標的維度要么取決于輸入維數要么需要固定為特定值。
在第一步時,隱含狀態被初始化為零向量,并與第一個輸入向量一起饋送給 RNN。
神經網絡可以將所有單詞的概率分布定義為。首先,其將輸入轉換為嵌入向量,該向量對應于 RNN 模型的目標向量。隨后將送給“語言模型頭”,即將其乘以詞嵌入矩陣(即),得到和詞表中的每個向量的相似度得分,生成的向量稱為 logit 向量,最后再通過 softmax 操作歸一化成所有單詞的概率分布:。
波束搜索 (beam search) 是其中一種解碼方法。本文不會對不同的解碼方法進行介紹,如對此感興趣,建議讀者參考 此文。
Sutskever 等 (2014) 的工作對輸入順序進行了逆序,對上面的例子而言,輸入向量變成了 (,,,,,,)。其動機是讓對應詞對之間的連接更短,如可以使得和 之間的連接更短。該研究小組強調,將輸入序列進行逆序是他們的模型在機器翻譯上的性能提高的一個關鍵原因。
責任編輯:彭菁
-
解碼器
+關注
關注
9文章
1143瀏覽量
40741 -
建模
+關注
關注
1文章
305瀏覽量
60774 -
rnn
+關注
關注
0文章
89瀏覽量
6891
原文標題:背景 | 基于 Transformers 的編碼器-解碼器模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TD-SCDMA Turbo 解碼器設計
基于DTMF的解碼器設計
基于DTMF的解碼器設計
高清解碼器的作用
監控解碼器作用
為什么編解碼器需要解碼器模型


什么叫解碼器?
PyTorch教程-10.6. 編碼器-解碼器架構

基于transformer的編碼器-解碼器模型的工作原理
基于 Transformers 的編碼器-解碼器模型
神經編碼器-解碼器模型的歷史





 工商網監
工商網監
評論