 ChatGPT的潛力和局限
ChatGPT的潛力和局限
今天為大家分享一篇研究,當ChatGPT穿越到口袋妖怪世界,是否會理解并應用這個虛構世界的知識呢?
熟悉口袋妖怪的朋友們一定知道,這些可愛的生物們有著各種不同的屬性、類別和技能。它們生活的世界也是一個完整的環境:你可以收集口袋妖怪、培養它們的實力,然后讓它們在戰斗中一展身手。每一個系統都有詳細的、明確的規定。
而現在,我們把這個酷炫的口袋妖怪世界作為評估ChatGPT知識和推理能力的環境!我們可以檢查ChatGPT對口袋妖怪世界的了解程度,并向它輸入新的知識,讓它在妖怪們的戰斗中進行推理,預測戰斗結果。
通過在口袋妖怪世界的實驗,我們能更好地評估ChatGPT的潛力和局限,看看它是否能夠學習新知識,基于特定情境的特征組合進行推理,從而做出更準確的判斷。
為了評估ChatGPT,作者引入了一個分階段的對話框架(如下圖),包括三個明確定義的階段:
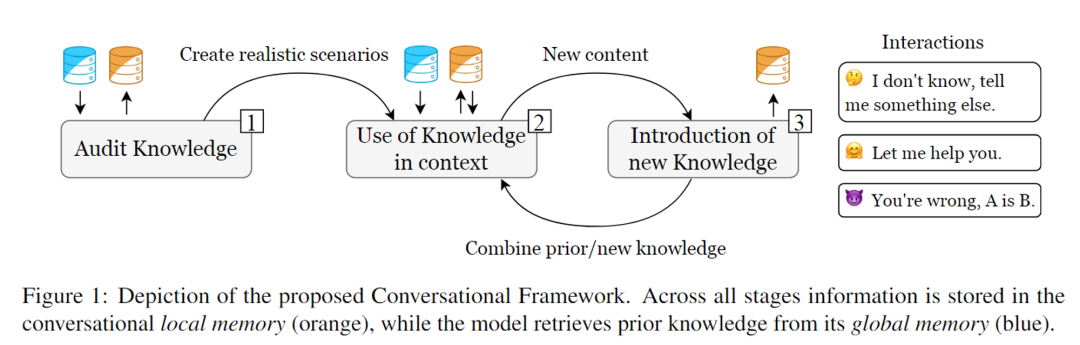
階段1:Audit knowledge
首先,ChatGPT具有口袋妖怪世界的背景知識嗎?
作者通過詢問一般性問題,如有關口袋妖怪類型和物種的描述,來審核ChatGPT對口袋妖怪世界的先驗知識。這些檢索到的知識被存儲在local memory中,作為對話的上下文,以便在接下來的步驟中構建合理的場景。同時,這些知識還可以提高后續模型的回應準確性,減少虛構情況的發生。
在階段一,作者從一些初步的一般性問題開始。這個階段對于隨后創建有效的溝通至關重要。我們區分global memory和local memory。前者是在訓練期間獲得的,包括ChatGPT的先驗知識。local memory僅限于我們之前的相互作用,并作為后驗相互作用的參考點。ChatGPT對口袋妖怪類型等問題上有很強的抵抗能力。但在Q1.4中的對抗提問中失敗了。
下面是一個例子:注意ChatGPT的答案用顏色標記,如果提供準確的知識,則用綠色,如果提供虛假陳述(幻覺),則用紅色,如果陳述模糊或不相關,則用黃色。

階段2:Use of knowledge in context
作者呈現了特定的戰斗場景,其中口袋妖怪們的類型、等級、招式和狀態相互作用并導致特定的結果。ChatGPT將用于預測戰斗的結果,并逐步解釋其推理過程。這個階段將評估模型是否能夠基于特定情境(上下文)組合特征(組合性),從而確定戰斗結果。
在階段二,作者呈現了口袋妖怪的簡單戰斗場景,并逐漸增加復雜性(不同級別、天氣和狀態條件),并要求ChatGPT預測戰斗的結果并解釋其推理。這一階段將幫助我們理解模型是否可以基于決定其結果的特定場景(上下文)組合特征(組合性)。
結果發現,大多數回答都是準確的。ChatGPT了解口袋妖怪的類型、移動(攻擊)和等級如何影響戰斗匹配。ChatGPT能夠預測,也可以全面地解釋其推理。但是,不同類型的問題上,ChatGPT的準確性差異較大。
作者總共測試了24場戰斗:6場涉及不同類型(準確率為83.3%),6場涉及不同級別(100%),7場涉及4種天氣條件(85.7%),6場涉及4種狀態效果(100%)。
作者介紹了具有正式規格(名稱、外觀、類型、招式)的新妖怪。然后,要求ChatGPT驗證對這些新概念的掌握,并將其與其先前知識進行比較。注意,ChatGPT將新引入的知識存儲在local memory中,但它將無法長時間引用它。
下面是一個測試例子:注意ChatGPT的答案用顏色標記,如果提供準確的知識,則用綠色,如果提供虛假陳述(幻覺),則用紅色,如果陳述模糊或不相關,則用黃色。
盡管在問題4.1中出現了部分幻覺,ChatGPT給出了相當好的類比。作者進一步評估新知識在語境中的整合,測試了新的與已知的口袋妖怪的戰斗。結果表明,ChatGPT能夠重用先驗和新引入的知識來預測結果,即使涉及的兩個口袋妖怪都是新引入的。在這種情況下,模型給出了可靠的預測。
通過與ChatGPT在對話框架下的互動,可以得出以下結論:首先,模型所呈現的事實的準確性取決于之前討論的內容;其次,對抗性攻擊可能是成功的,但并不總是成功的,但一般來說,對話預處理(知識檢索)和協作反饋可以糾正先前模型的錯誤。
責任編輯:彭菁
-
存儲
+關注
關注
13文章
4314瀏覽量
85842 -
模型
+關注
關注
1文章
3243瀏覽量
48836 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7666
原文標題:在口袋妖怪世界中理解ChatGPT的思維
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了

科技大廠競逐AIGC,中國的ChatGPT在哪?
不到1分鐘開發一個GPT應用!各路大神瘋狂整活,網友:ChatGPT就是新iPhone
基于微控制器的LED驅動器拓撲、權衡和局限





 工商網監
工商網監
評論