 基于純視覺的感知方法
基于純視覺的感知方法
背景 近年來,基于純視覺的感知方法由于其較高的信噪比和較低的成本,在自動駕駛領域占有重要地位。其中,鳥瞰圖(BEV)感知已成為主流的方法。在以視覺為中心的自動駕駛任務中,BEV表示學習是指將周圍多個攝像頭的連續幀作為輸入,然后將像平面視角轉換為鳥瞰圖視角,在得到的鳥瞰圖特征上執行諸如三維目標檢測、地圖視圖語義分割和運動預測等感知任務。 BEV感知性能的提高取決于如何快速且精準地獲取道路和物體特征表示。圖1中展示了現有的兩類基于不同交互機制的BEV感知管道:(a)后交互和(b)中間交互。后交互管道[1]在每個相機視角上獨立地進行感知,然后將感知結果在時間和空間上融合到一個統一的BEV特征空間中。中間交互管道[2,3,4]是最近使用得最廣泛的方案,它將所有的相機視角圖像耦合輸入到網絡中,通過網絡將它們轉換到BEV空間,然后直接輸出結果。中間交互管道中的特征提取、空間轉換和BEV空間的學習都有一個明確的順序。
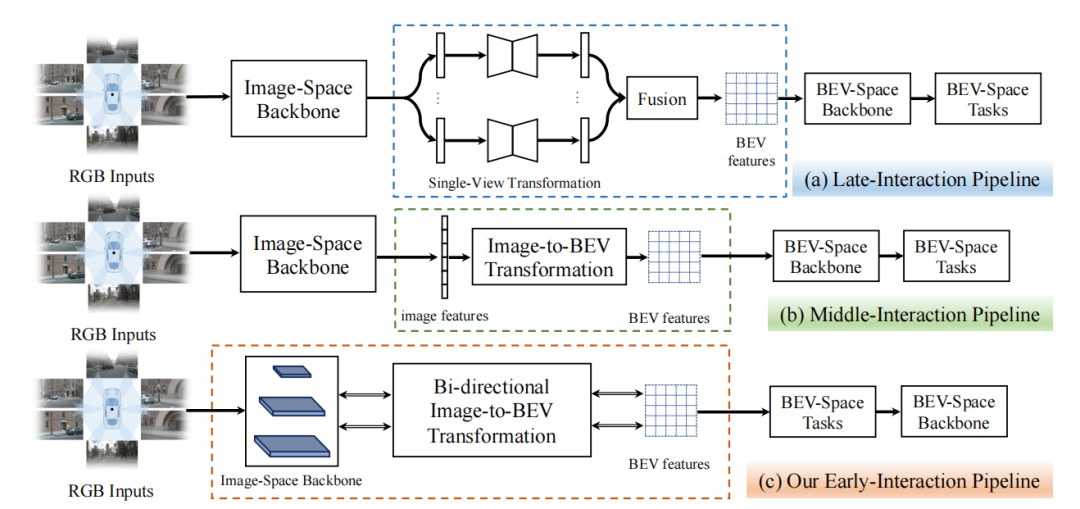
圖1:后交互、中間交互和我們提出的前置交互框架示意圖 基于視覺的BEV感知的核心挑戰是從仿射視角(Perspective View, PV)向鳥瞰圖視角(BEV)的轉換。然而,利用現有的兩種交互策略將PV轉換到BEV仍然存在許多問題:(1) 圖像空間backbone只依次提取不同分辨率的圖像特征,而沒有融合任何跨分辨率的信息;(2) 現有的交互策略中核心模塊的計算量主要由圖像空間backbone占據,但它不包含任何BEV空間信息,導致大量的計算并沒有執行PV到BEV轉換這一關鍵任務;(3) 后交互策略和中間交互策略的前向處理中的信息流是單向的,信息從圖像空間流到BEV空間,而BEV空間中的信息并沒有有效地影響圖像空間中的特征。為了解決這些問題,我們提出了一種新的基于Transformer的雙向前置交互框架,以有效地將多尺度圖像特征聚合成更好的BEV特征表示,并執行BEV語義分割任務。 與現有的兩種策略相比,我們提出的前置交互方法具有明顯的優勢。首先,我們提出的雙向前置交互方法可以融合全局上下文信息和局部細節,從而能夠向BEV空間傳遞更豐富的語義信息。其次,我們提出PV到BEV的轉換不僅可以是圖像特征提取后,而且可以在提取過程中進行逐步轉換,于是,通過我們提出的雙向交叉注意力機制,信息流可以隱式地進行雙向交互,從而對齊PV和BEV中的特征。此外,我們的方法可以將跨空間對齊學習擴散到整個框架中,即圖像網絡學習不僅可以學習到良好的特征表示,而且可以起到跨空間對齊的作用。 方法
整體框架
BAEFormer的整體框架如圖2所示,總共包含兩個部分:(1)雙向前置交互編碼器,用于提取圖像特征并將其從PV轉換為BEV;(2)將低分辨率BEV特征上采樣到高分辨率BEV特征的解碼器,用于執行下游任務。
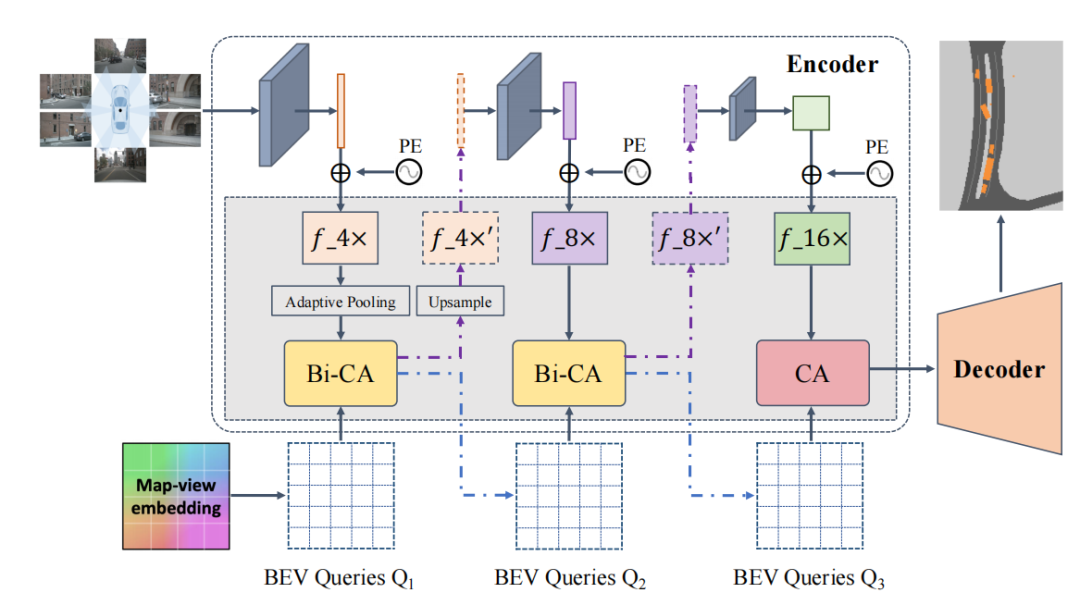
圖2:BAEFormer整體框架圖
前置交互
對于前置交互模塊,我們使用EfficientNet[5]的預訓練模型來提取環視圖像的特征,特征提取器包含三層,分別提取圖像的4x,8x,16x分辨率的特征。4x分辨率的特征首先被提取出來,通過一個降采樣模塊之后和BEV特征進行交互得到更新之后的4x分辨率特征,將更新之后的4x特征上采樣,并作為特征提取器的下一層的輸入來提取8x分辨率特征。以此類推,我們得到更新之后的8x特征并作為特征提取器最后一層的輸入,由此得到16x圖像特征。我們的多尺度前置交互方法可以充分利用分層預訓練的模型來整合多尺度圖像特征。同時,BEV的空間信息可以流入主干網絡,使前置交互主干網絡承擔了部分異質空間對齊的功能。
雙向交叉注意力
如圖3中所示,我們提出的雙向交叉注意力模型包含兩個分支,一個用于多視圖圖像特征的精細化,另一個用于BEV特征的精細化。 首先,N個環視圖像特征首先被編碼為查詢特征,鍵特征和值特征,其中c表示特征維度,h和w分別表示特征的高和寬。相似的,BEV特征編碼也被轉換為查詢特征,鍵特征和值特征。于是圖像特征和BEV特征的交叉注意力可以表示為: 整個Transformer模塊就可以使用下式計算: 其中,和表示第l層的輸入,和表示第l層的輸出。LN(?)表示層歸一化操作,MLP(?)表示有2個全連接層和一個非線性層的多層感知機模塊,MHBiCA(?)表示擁有多頭交叉注意力機制的BiCA(?)模塊。
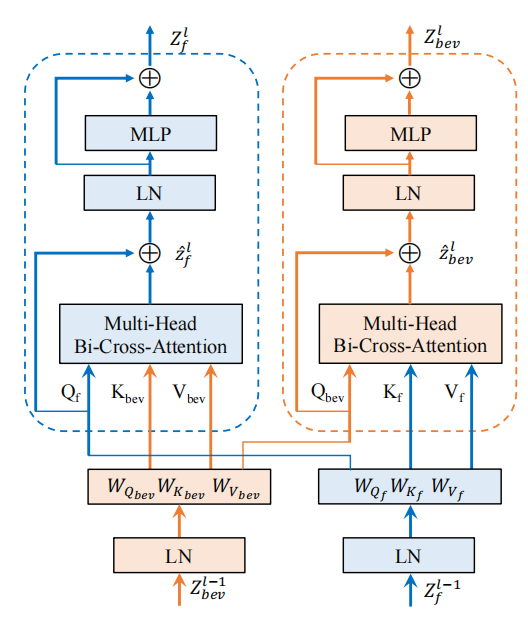
圖3:雙向交叉注意力框架圖 實驗結果 表1展示了BAEFormer方法和之前的方法在兩種設置下的性能、參數和推理速度的對比結果。可以看出,BAEFormer在使用相同輸入分辨率(224x480)的設置下,在精度上超過了現有的實時方法。同時,雖然先前的BEVFormer[2]實現了高性能,但它非常耗時,模型參數高達68.1M。我們的BAEFormer在大輸入圖像分辨率(504x1056)下的運行速度比BEVFormer快12倍,而參數量大約是它的1/12。
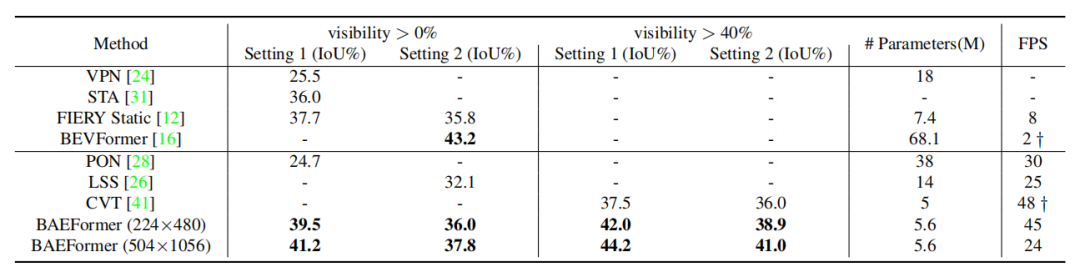
表1:nuScenes數據集上車輛類別的語義分割結果
消融實驗
表2展示了我們在nuScenes數據集上對車輛類別進行的不同交互方式的消融實驗。實驗結果表明,我們的BAEFormer方法可以將雙向交叉注意力機制和前置交互方式充分地結合以得到更好的BEV特征表示。
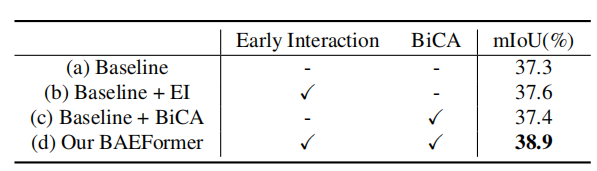
表2:不同交互方式的消融實驗 表3展示了具有不同輸入分辨率和圖像特征尺度的模型的mIoU性能和內存使用情況。結果說明,使用多尺度特征可以帶來更好的性能;增大輸入圖像分辨率可以提高性能,但會帶來顯存的劇增;我們發現,如(j)-(n)所示,在交互過程中,輸入圖像的分辨率對最終的精度沒有太大的影響;因此我們可以在提高輸入圖像分辨率來提升性能的同時,通過對交互時的圖像特征進行降采樣來保證計算量是可控的。
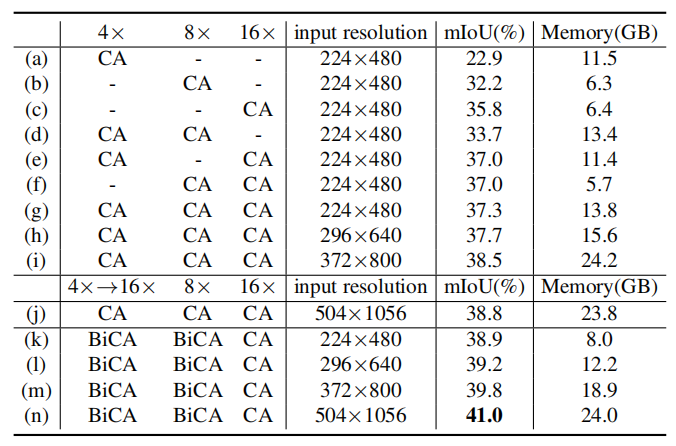
表3: 不同輸入分辨率和不同圖像特征尺度的組合
可視化結果
圖4展示了BEV下的可視化結果,可以看出BAEFormer對比baseline模型,不僅對于近處物體漏檢(紅色圈)的數目有效減少,且對于遠處物體(綠色圈)也能進行有效的感知,進一步說明了我們方法的感知能力具有一定的優勢。
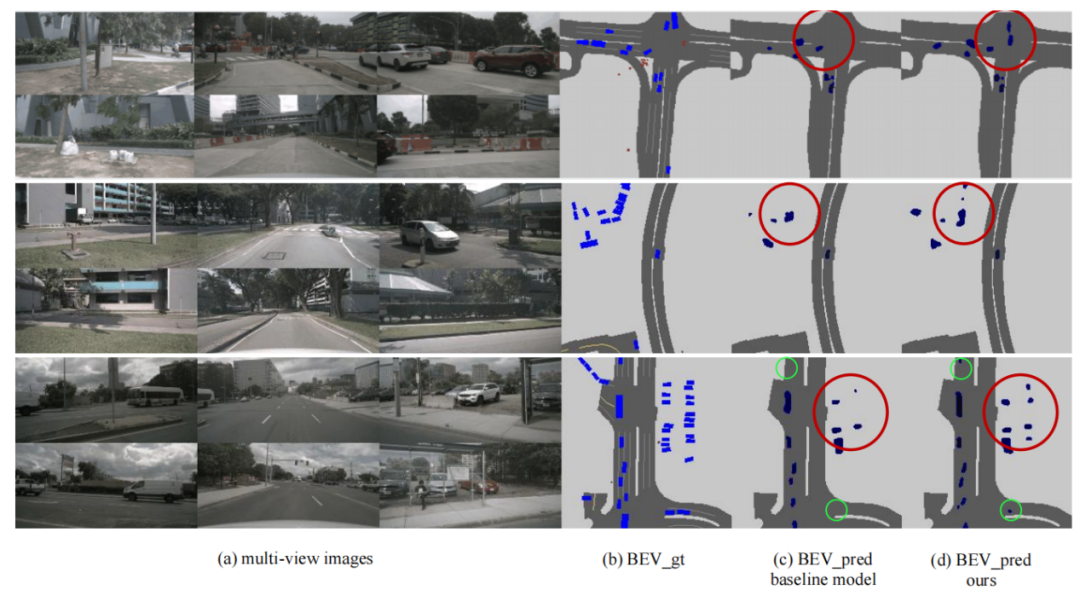
圖4:不同模型的可視化結果對比 結論 在本文中,我們提出了一種稱為BAEFormer的BEV語義分割新框架,采用雙向交叉注意力機制,通過對圖像特征空間和 BEV 特征空間中的信息流施加雙向約束來建立改進的跨空間對齊,同時利用前置交互方法來合并跨尺度信息,并實現更精細的語義表示。實驗結果表明,BAEFormer在保持實時推理速度的同時能夠提高BEV語義分割的性能。 點擊“閱讀原文”,下載論文獲取更多信息。
責任編輯:彭菁
-
相機
+關注
關注
4文章
1359瀏覽量
53764 -
視覺
+關注
關注
1文章
147瀏覽量
23991 -
感知
+關注
關注
1文章
66瀏覽量
12148
原文標題:CVPR 2023|BAEFormer:基于雙向前置交互Transformer的BEV語義分割方法
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
人類視覺感知方式對VR的挑戰
智能感知方案怎么幫助實現安全的自動駕駛?

一種基于智能終端的環境與接近度感知方法
基于信道歷史狀態信息的頻譜感知方法
激光雷達vs純計算機視覺 自動駕駛的兩大流派
新的工業應用智能感知方案
黑芝麻智能在BEV感知方面的研發進展
4分鐘了解吸頂燈具智能感知方案測試方法


自動駕駛中激光雷達和視覺感知的區別






 工商網監
工商網監
評論