") 主流的機(jī)器視覺技術(shù)有哪些呢
主流的機(jī)器視覺技術(shù)有哪些呢
視覺是人類最敏感、最直接的感知方式,在不進(jìn)行實(shí)際接觸的情況下,視覺感知可以使得我們獲取周圍環(huán)境的諸多信息。由于生物視覺系統(tǒng)非常復(fù)雜,目前還不能使得某一機(jī)器系統(tǒng)完全具備這一強(qiáng)大的視覺感知能力。
當(dāng)下,機(jī)器視覺的目標(biāo),即構(gòu)建一個(gè)在可控環(huán)境中處理特定任務(wù)的機(jī)器視覺系統(tǒng)。由于工業(yè)中的視覺環(huán)境可控,并且處理任務(wù)特定,所以現(xiàn)如今大部分的機(jī)器視覺被應(yīng)用在工業(yè)當(dāng)中。 人類視覺感知是通過眼睛視網(wǎng)膜的椎體和桿狀細(xì)胞對(duì)光源進(jìn)行捕捉,而后由神經(jīng)纖維將信號(hào)傳遞至大腦視覺皮層,形成我們所看到的圖像,而機(jī)器視覺卻不然。 機(jī)器視覺系統(tǒng)的輸入是圖像,輸出是對(duì)這些圖像的感知描述。這組描述與這些圖像中的物體或場(chǎng)景息息相關(guān),并且這些描述可以幫助機(jī)器來完成特定的后續(xù)任務(wù),指導(dǎo)機(jī)器人系統(tǒng)與周圍的環(huán)境進(jìn)行交互。 那么,迄今為止,主流的機(jī)器視覺技術(shù)又有哪些呢?
01中流砥柱:卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)是目前計(jì)算機(jī)視覺中使用最普遍的模型結(jié)構(gòu)。 引入卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行特征提取,既能提取到相鄰像素點(diǎn)之間的特征模式,又能保證參數(shù)的個(gè)數(shù)不隨圖片尺寸變化。上圖是一個(gè)典型的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),多層卷積和池化層組合作用在輸入圖片上,在網(wǎng)絡(luò)的最后通常會(huì)加入一系列全連接層,ReLU激活函數(shù)一般加在卷積或者全連接層的輸出上,網(wǎng)絡(luò)中通常還會(huì)加入Dropout來防止過擬合。 自2012年AlexNet在ImageNet比賽上獲得冠軍,卷積神經(jīng)網(wǎng)絡(luò)逐漸取代傳統(tǒng)算法成為了處理計(jì)算機(jī)視覺任務(wù)的核心。 在這幾年,研究人員從提升特征提取能力,改進(jìn)回傳梯度更新效果,縮短訓(xùn)練時(shí)間,可視化內(nèi)部結(jié)構(gòu),減少網(wǎng)絡(luò)參數(shù)量,模型輕量化, 自動(dòng)設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu)等這些方面,對(duì)卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)有了較大的改進(jìn),逐漸研究出了AlexNet、ZFNet、VGG、NIN、GoogLeNet和Inception系列、ResNet、WRN和DenseNet等一系列經(jīng)典模型,MobileNet系列、ShuffleNet系列、SqueezeNet和Xception等輕量化模型。 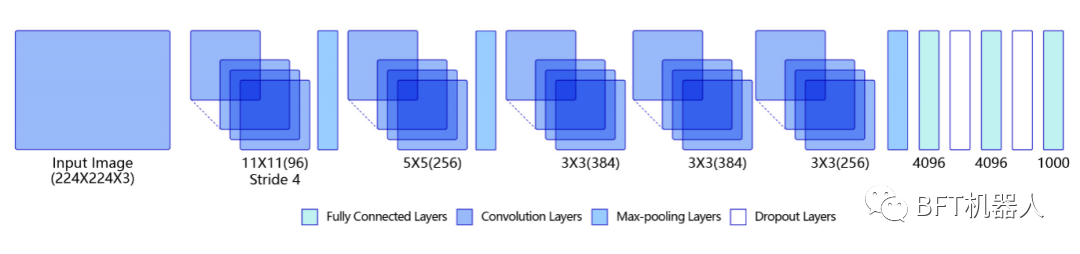
01
經(jīng)典模型(AlexNet)
AlexNet是第一個(gè)深度神經(jīng)網(wǎng)絡(luò),其主要特點(diǎn)包括:
使用ReLU作為激活函數(shù);
提出在全連接層使用Dropout避免過擬合。注:當(dāng)BN提出后,Dropout就被BN替代了;
由于GPU顯存太小,使用了兩個(gè)GPU,做法是在通道上分組;。
使用局部響應(yīng)歸一化(Local Response Normalization --LRN),在生物中存在側(cè)抑制現(xiàn)象,即被激活的神經(jīng)元會(huì)抑制周圍的神經(jīng)元。在這里的目的是讓局部響應(yīng)值大的變得相對(duì)更大,并抑制其它響應(yīng)值相對(duì)比較小的卷積核。例如,某特征在這一個(gè)卷積核中響應(yīng)值比較大,則在其它相鄰卷積核中響應(yīng)值會(huì)被抑制,這樣一來卷積核之間的相關(guān)性會(huì)變小。LRN結(jié)合ReLU,使得模型提高了一點(diǎn)多個(gè)百分點(diǎn);
使用重疊池化。作者認(rèn)為使用重疊池化會(huì)提升特征的豐富性,且相對(duì)來說會(huì)更難過擬合。
02
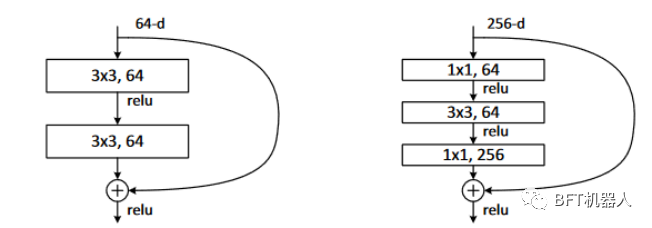
集大成之作(ResNet)
一般而言,網(wǎng)絡(luò)越深越寬會(huì)有更好的特征提取能力,但當(dāng)網(wǎng)絡(luò)達(dá)到一定層數(shù)后,隨著層數(shù)的增加反而導(dǎo)致準(zhǔn)確率下降,網(wǎng)絡(luò)收斂速度更慢。 傳統(tǒng)的卷積網(wǎng)絡(luò)在一個(gè)前向過程中每層只有一個(gè)連接,ResNet增加了殘差連接從而增加了信息從一層到下一層的流動(dòng)。FractalNets重復(fù)組合幾個(gè)有不同卷積塊數(shù)量的并行層序列,增加名義上的深度,卻保持著網(wǎng)絡(luò)前向傳播短的路徑。 相類似的操作還有Stochastic depth和Highway Networks等。這些模型都顯示一個(gè)共有的特征,縮短前面層與后面層的路徑,其主要的目的都是為了增加不同層之間的信息流動(dòng)。
02 后起之秀:Transformers
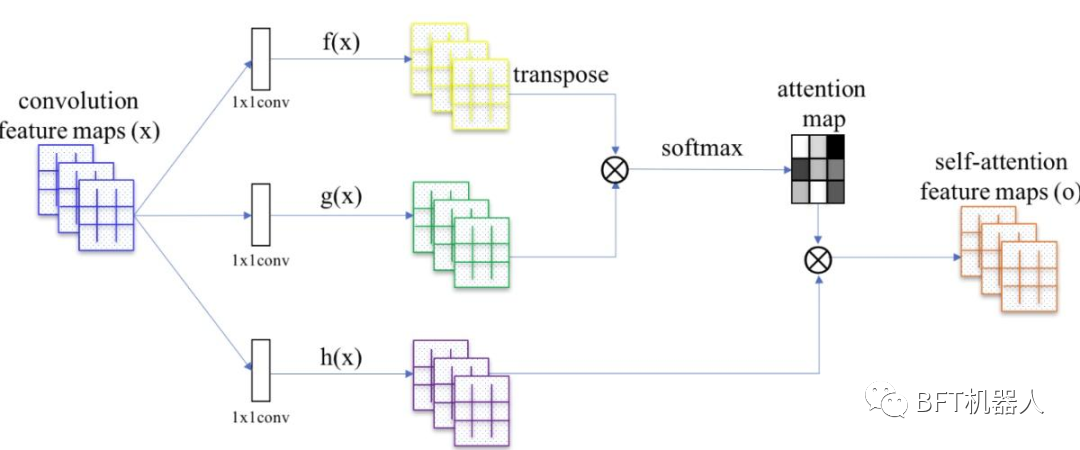 Transformer是一種self-attention(自注意力)模型架構(gòu)。 ? 2017年之后在NLP領(lǐng)域取得了很大的成功,尤其是序列到序列(seq2seq)任務(wù),如機(jī)器翻譯和文本生成。2020年,谷歌提出pure transformer結(jié)構(gòu)ViT ,在ImageNet分類任務(wù)上取得了和CNN可比的性能。之后大量ViT衍生的Transformer架構(gòu)在ImageNet上都取得了成功。 ? Transformer 與 CNN相比優(yōu)點(diǎn)是具有較少的歸納性與先驗(yàn)性,因此可以被認(rèn)為是不同學(xué)習(xí)任務(wù)的通用計(jì)算原語(yǔ),參數(shù)效率與性能增益與 CNN 相當(dāng)。不過缺點(diǎn)是在預(yù)訓(xùn)練期間,對(duì)大數(shù)據(jù)機(jī)制的依賴性更強(qiáng),因?yàn)?Transformer 沒有像 CNN 那樣定義明確的歸納先驗(yàn)。因此當(dāng)下出現(xiàn)了一個(gè)新趨勢(shì):當(dāng) self-attention 與 CNN 結(jié)合時(shí),它們會(huì)建立強(qiáng)大的基線?( BoTNet )。 ? Vision Transformer(ViT)將純Transformer架構(gòu)直接應(yīng)用到一系列圖像塊上進(jìn)行分類任務(wù),可以取得優(yōu)異的結(jié)果。它在許多圖像分類任務(wù)上也優(yōu)于最先進(jìn)的卷積網(wǎng)絡(luò),同時(shí)所需的預(yù)訓(xùn)練計(jì)算資源大大減少。 ?
Transformer是一種self-attention(自注意力)模型架構(gòu)。 ? 2017年之后在NLP領(lǐng)域取得了很大的成功,尤其是序列到序列(seq2seq)任務(wù),如機(jī)器翻譯和文本生成。2020年,谷歌提出pure transformer結(jié)構(gòu)ViT ,在ImageNet分類任務(wù)上取得了和CNN可比的性能。之后大量ViT衍生的Transformer架構(gòu)在ImageNet上都取得了成功。 ? Transformer 與 CNN相比優(yōu)點(diǎn)是具有較少的歸納性與先驗(yàn)性,因此可以被認(rèn)為是不同學(xué)習(xí)任務(wù)的通用計(jì)算原語(yǔ),參數(shù)效率與性能增益與 CNN 相當(dāng)。不過缺點(diǎn)是在預(yù)訓(xùn)練期間,對(duì)大數(shù)據(jù)機(jī)制的依賴性更強(qiáng),因?yàn)?Transformer 沒有像 CNN 那樣定義明確的歸納先驗(yàn)。因此當(dāng)下出現(xiàn)了一個(gè)新趨勢(shì):當(dāng) self-attention 與 CNN 結(jié)合時(shí),它們會(huì)建立強(qiáng)大的基線?( BoTNet )。 ? Vision Transformer(ViT)將純Transformer架構(gòu)直接應(yīng)用到一系列圖像塊上進(jìn)行分類任務(wù),可以取得優(yōu)異的結(jié)果。它在許多圖像分類任務(wù)上也優(yōu)于最先進(jìn)的卷積網(wǎng)絡(luò),同時(shí)所需的預(yù)訓(xùn)練計(jì)算資源大大減少。 ? 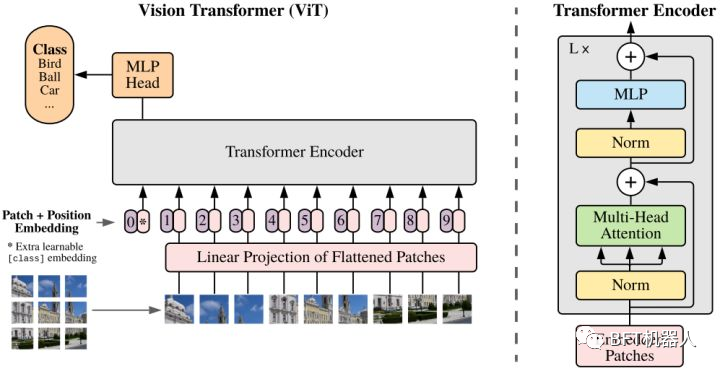 DETR是第一個(gè)成功地將Transformer作為pipeline中的主要構(gòu)建塊的目標(biāo)檢測(cè)框架。它與以前的SOTA方法(高度優(yōu)化的Faster R-CNN)的性能匹配,具有更簡(jiǎn)單和更靈活的pipeline。 ?
DETR是第一個(gè)成功地將Transformer作為pipeline中的主要構(gòu)建塊的目標(biāo)檢測(cè)框架。它與以前的SOTA方法(高度優(yōu)化的Faster R-CNN)的性能匹配,具有更簡(jiǎn)單和更靈活的pipeline。 ? 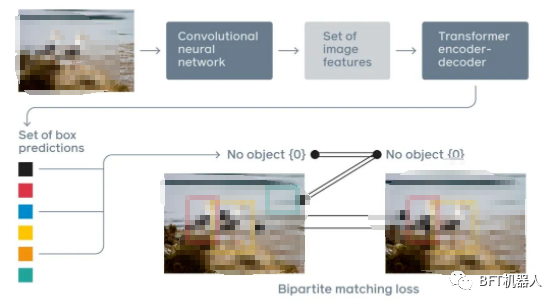 Transformer的變體模型是目前的研究熱點(diǎn),主要分為以下幾個(gè)類型: ?
Transformer的變體模型是目前的研究熱點(diǎn),主要分為以下幾個(gè)類型: ?
模型輕量化
加強(qiáng)跨模塊連接
自適應(yīng)的計(jì)算時(shí)間
引入分而治之的策略
循環(huán)Transformers
等級(jí)化的Transformer
03欺騙機(jī)器的眼睛——對(duì)抗性展示
最近引起研究界注意的一個(gè)問題是這些系統(tǒng)對(duì)對(duì)抗樣本的敏感性。 一個(gè)對(duì)抗性的例子是一個(gè)嘈雜的圖像,旨在欺騙系統(tǒng)做出錯(cuò)誤的預(yù)測(cè)。為了在現(xiàn)實(shí)世界中部署這些系統(tǒng),它們必須能夠檢測(cè)到這些示例。為此,最近的工作探索了通過在訓(xùn)練過程中包含對(duì)抗性示例來使這些系統(tǒng)更強(qiáng)對(duì)抗性攻擊的可能性。 現(xiàn)階段對(duì)模型攻擊的分類主要分為兩大類,即攻擊訓(xùn)練階段和推理階段。
01
訓(xùn)練階段的攻擊
訓(xùn)練階段的攻擊(Training in Adversarial Settings),主要的方法就是針對(duì)模型的參數(shù)進(jìn)行微小的擾動(dòng),從而達(dá)到讓模型的性能和預(yù)期產(chǎn)生偏差的目的。 例如直接通過對(duì)于訓(xùn)練數(shù)據(jù)的標(biāo)簽進(jìn)行替換,讓數(shù)據(jù)樣本和標(biāo)簽不對(duì)應(yīng),從而最后訓(xùn)練的結(jié)果也一定與預(yù)期的產(chǎn)生差異,或者通過在線的方式獲得訓(xùn)練數(shù)據(jù)的輸入權(quán),操縱惡意數(shù)據(jù)來對(duì)在線訓(xùn)練過程進(jìn)行擾動(dòng),最后的結(jié)果就是產(chǎn)出脫離預(yù)期。
02
推理階段的攻擊
推理階段的攻擊(Inference in Adversarial Settings),是當(dāng)一個(gè)模型被訓(xùn)練完成后,可以將該模型主觀的看作是一個(gè)盒子,如果該盒子對(duì)我們來說是透明的則可以將其看成“白盒”模型,若非如此則看成“黑盒”模型。 所謂的“白盒攻擊”,就是我們需要知道里面所有的模型參數(shù),但這在實(shí)際操作中并不現(xiàn)實(shí),卻有實(shí)現(xiàn)的可能,因此我們需要有這種前提假設(shè)。黑盒攻擊就比較符合現(xiàn)實(shí)生活中的場(chǎng)景:通過輸入和輸出猜測(cè)模型的內(nèi)部結(jié)構(gòu);加入稍大的擾動(dòng)來對(duì)模型進(jìn)行攻擊;構(gòu)建影子模型來進(jìn)行關(guān)系人攻擊;抽取模型訓(xùn)練的敏感數(shù)據(jù);模型逆向參數(shù)等等。 對(duì)抗攻擊的防御機(jī)制。抵御對(duì)抗樣本攻擊主要是基于附加信息引入輔助塊模型(AuxBlocks)進(jìn)行額外輸出來作為一種自集成的防御機(jī)制,尤其在針對(duì)攻擊者的黑盒攻擊和白盒攻擊時(shí),該機(jī)制效果良好。除此之外防御性蒸餾也可以起到一定的防御能力,防御性蒸餾是一種將訓(xùn)練好的模型遷移到結(jié)構(gòu)更為簡(jiǎn)單的網(wǎng)絡(luò)中,從而達(dá)到防御對(duì)抗攻擊的效果。 對(duì)抗學(xué)習(xí)的應(yīng)用舉例:自動(dòng)駕駛 自動(dòng)駕駛是未來智能交通的發(fā)展方向,但在其安全性獲得完全檢驗(yàn)之前,人們還難以信任這種復(fù)雜的技術(shù)。雖然許多車企、科技公司已經(jīng)在這一領(lǐng)域進(jìn)行了許多實(shí)驗(yàn),但對(duì)抗樣本技術(shù)對(duì)于自動(dòng)駕駛?cè)匀皇且粋€(gè)巨大的挑戰(zhàn)。幾個(gè)攻擊實(shí)例:對(duì)抗攻擊下的圖片中的行人在模型的面前隱身,對(duì)抗樣本使得模型“無視”路障;利用 AI 對(duì)抗樣本生成特定圖像并進(jìn)行干擾時(shí),特斯拉的 Autopilot 系統(tǒng)輸出了「錯(cuò)誤」的識(shí)別結(jié)果,導(dǎo)致車輛雨刷啟動(dòng);在道路的特定位置貼上若干個(gè)對(duì)抗樣本貼紙,可以讓處在自動(dòng)駕駛模式的汽車并入反向車道;在Autopilot 系統(tǒng)中,通過游戲手柄對(duì)車輛行駛方向進(jìn)行控制;對(duì)抗樣本使得行人對(duì)于機(jī)器學(xué)習(xí)模型“隱身”。
04自學(xué)也能成才:自監(jiān)督學(xué)習(xí)
深度學(xué)習(xí)需要干凈的標(biāo)記數(shù)據(jù),這對(duì)于許多應(yīng)用程序來說很難獲得。 注釋大量數(shù)據(jù)需要大量的人力勞動(dòng),這是耗時(shí)且昂貴的。此外,數(shù)據(jù)分布在現(xiàn)實(shí)世界中一直在變化,這意味著模型必須不斷地根據(jù)不斷變化的數(shù)據(jù)進(jìn)行訓(xùn)練。自監(jiān)督方法通過使用大量原始未標(biāo)記數(shù)據(jù)來訓(xùn)練模型來解決其中的一些挑戰(zhàn)。在這種情況下,監(jiān)督是由數(shù)據(jù)本身(不是人工注釋)提供的,目標(biāo)是完成一個(gè)間接任務(wù)。間接任務(wù)通常是啟發(fā)式的(例如,旋轉(zhuǎn)預(yù)測(cè)),其中輸入和輸出都來自未標(biāo)記的數(shù)據(jù)。定義間接任務(wù)的目標(biāo)是使模型能夠?qū)W習(xí)相關(guān)特征,這些特征稍后可用于下游任務(wù)(通常有一些注釋可用)。 自監(jiān)督學(xué)習(xí)是一種數(shù)據(jù)高效的學(xué)習(xí)范式。 監(jiān)督學(xué)習(xí)方法教會(huì)模型擅長(zhǎng)特定任務(wù)。另一方面,自監(jiān)督學(xué)習(xí)允許學(xué)習(xí)不專門用于解決特定任務(wù)的一般表示,而是為各種下游任務(wù)封裝更豐富的統(tǒng)計(jì)數(shù)據(jù)。在所有自監(jiān)督方法中,使用對(duì)比學(xué)習(xí)進(jìn)一步提高了提取特征的質(zhì)量。自監(jiān)督學(xué)習(xí)的數(shù)據(jù)效率特性使其有利于遷移學(xué)習(xí)應(yīng)用。 目前的自監(jiān)督學(xué)習(xí)領(lǐng)域可大致分為兩個(gè)分支。 一個(gè)是用于解決特定任務(wù)的自監(jiān)督學(xué)習(xí),例如上次討論的場(chǎng)景去遮擋,以及自監(jiān)督的深度估計(jì)、光流估計(jì)、圖像關(guān)聯(lián)點(diǎn)匹配等。另一個(gè)分支則用于表征學(xué)習(xí)。有監(jiān)督的表征學(xué)習(xí),一個(gè)典型的例子是ImageNet分類。而無監(jiān)督的表征學(xué)習(xí)中,最主要的方法則是自監(jiān)督學(xué)習(xí)。 自監(jiān)督學(xué)習(xí)方法依賴于數(shù)據(jù)的空間和語(yǔ)義結(jié)構(gòu),對(duì)于圖像,空間結(jié)構(gòu)學(xué)習(xí)是極其重要的,因此在計(jì)算機(jī)視覺領(lǐng)域中的應(yīng)用廣泛。 一種是將旋轉(zhuǎn)、拼接和著色在內(nèi)的不同技術(shù)被用作從圖像中學(xué)習(xí)表征的前置任務(wù)。對(duì)于著色,將灰度照片作為輸入并生成照片的彩色版本。另一種廣泛用于計(jì)算機(jī)視覺自監(jiān)督學(xué)習(xí)的方法是放置圖像塊。一個(gè)例子包括 Doersch 等人的論文。在這項(xiàng)工作中,提供了一個(gè)大型未標(biāo)記的圖像數(shù)據(jù)集,并從中提取了隨機(jī)的圖像塊對(duì)。在初始步驟之后,卷積神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)第二個(gè)圖像塊相對(duì)于第一個(gè)圖像塊的位置。還有其他不同的方法用于自監(jiān)督學(xué)習(xí),包括修復(fù)和判斷分類錯(cuò)誤的圖像。 05結(jié)語(yǔ) 自2012年AlexNet問世這十年來,機(jī)器視覺領(lǐng)域的技術(shù)可以說是日新月異。機(jī)器視覺在諸多領(lǐng)域也逐漸接近甚至超越了我們?nèi)祟惖难劬ΑkS著技術(shù)的不斷進(jìn)步,機(jī)器視覺技術(shù)也一定會(huì)變得更加的強(qiáng)大,無論是安全防護(hù)、自動(dòng)駕駛、缺陷檢測(cè)還是目標(biāo)識(shí)別等領(lǐng)域,相信機(jī)器視覺會(huì)帶給我們更多的驚喜。
責(zé)任編輯:彭菁
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100766 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1698瀏覽量
45993 -
機(jī)器視覺技術(shù)
+關(guān)注
關(guān)注
0文章
35瀏覽量
7133
原文標(biāo)題:主流的機(jī)器視覺技術(shù)有哪些呢?
文章出處:【微信號(hào):機(jī)器視覺沙龍,微信公眾號(hào):機(jī)器視覺沙龍】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器視覺技術(shù)
機(jī)器視覺表面缺陷檢測(cè)技術(shù)
生活中“無處不在”的技術(shù)——機(jī)器視覺
機(jī)器視覺系統(tǒng)技術(shù)簡(jiǎn)介!(干貨分享建議收藏)
深圳機(jī)器視覺檢測(cè)項(xiàng)目包括哪些?
深圳機(jī)器視覺led光源有什么優(yōu)勢(shì)
深圳機(jī)器視覺技術(shù)在自動(dòng)化行業(yè)里有哪些應(yīng)用?
四元數(shù)數(shù)控:深圳機(jī)器視覺技術(shù)是圖像處理嗎?
機(jī)器視覺有哪些特點(diǎn)_機(jī)器視覺有哪些方向
機(jī)器視覺有前景嗎_如何入門機(jī)器視覺
機(jī)器人主流定位技術(shù):激光SLAM與視覺SLAM誰(shuí)更勝一籌
國(guó)內(nèi)十大機(jī)器視覺公司有哪些 主流的機(jī)器視覺軟件有哪些
主流的機(jī)器視覺技術(shù)盤點(diǎn)

什么是機(jī)器視覺?機(jī)器視覺與計(jì)算機(jī)有什么關(guān)系?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論