 使用PyMC進行時間序列分層建模
使用PyMC進行時間序列分層建模
在統計建模領域,理解總體趨勢的同時解釋群體差異的一個強大方法是分層(或多層)建模。這種方法允許參數隨組而變化,并捕獲組內和組間的變化。在時間序列數據中,這些特定于組的參數可以表示不同組隨時間的不同模式。
今天,我們將深入探討如何使用PyMC(用于概率編程的Python庫)構建分層時間序列模型。
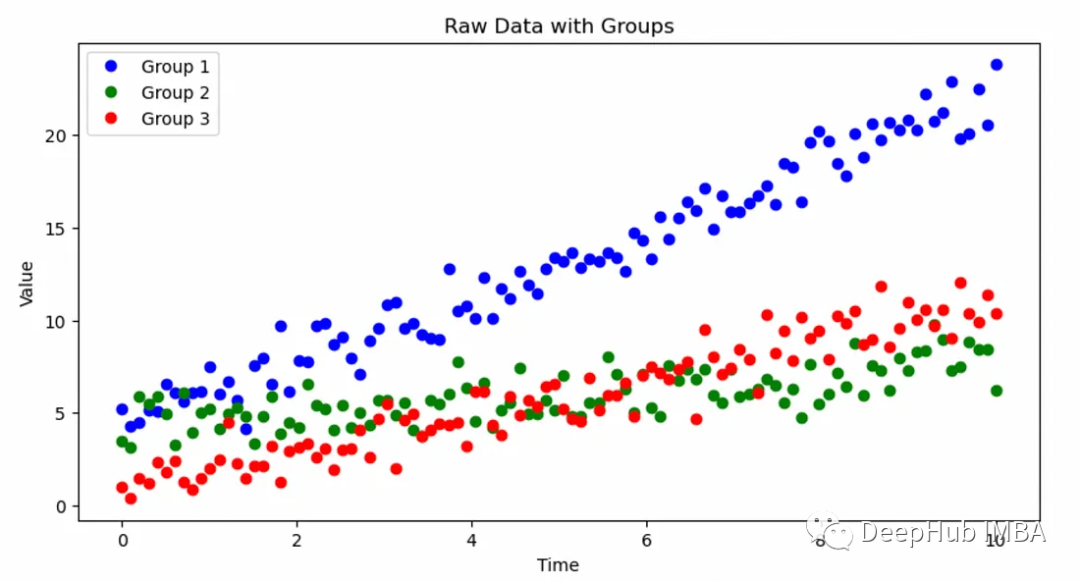
讓我們從為多個組生成一些人工時間序列數據開始,每個組都有自己的截距和斜率。
import numpy as np
import matplotlib.pyplot as plt
import pymc as pm
# Simulating some data
np.random.seed(0)
n_groups = 3 # number of groups
n_data_points = 100 # number of data points per group
x = np.tile(np.linspace(0, 10, n_data_points), n_groups)
group_indicator = np.repeat(np.arange(n_groups), n_data_points)
slope_true = np.random.normal(0, 1, size=n_groups)
intercept_true = np.random.normal(2, 1, size=n_groups)
y = slope_true[group_indicator]*x + intercept_true[group_indicator] + np.random.normal(0, 1, size=n_groups*n_data_points)
我們生成了三個不同組的時間序列數據。每組都有自己的時間趨勢,由唯一的截距和斜率定義。
colors = ['b', 'g', 'r'] # Define different colors for each group
plt.figure(figsize=(10, 5))
# Plot raw data for each group
for i in range(n_groups):
plt.plot(x[group_indicator == i], y[group_indicator == i], 'o', color=colors[i], label=f'Group {i+1}')
plt.title('Raw Data with Groups')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
下一步是構建層次模型。我們的模型將具有組特定的截距(alpha)和斜率(beta)。截距和斜率是從具有超參數mu_alpha、sigma_alpha、mu_beta和sigma_beta的正態分布中繪制的。這些超參數分別表示截距和斜率的組水平均值和標準差。
with pm.Model() as hierarchical_model:
# Hyperpriors
mu_alpha = pm.Normal('mu_alpha', mu=0, sigma=10)
sigma_alpha = pm.HalfNormal('sigma_alpha', sigma=10)
mu_beta = pm.Normal('mu_beta', mu=0, sigma=10)
sigma_beta = pm.HalfNormal('sigma_beta', sigma=10)
# Priors
alpha = pm.Normal('alpha', mu=mu_alpha, sigma=sigma_alpha, shape=n_groups) # group-specific intercepts
beta = pm.Normal('beta', mu=mu_beta, sigma=sigma_beta, shape=n_groups) # group-specific slopes
sigma = pm.HalfNormal('sigma', sigma=1)
# Expected value
mu = alpha[group_indicator] + beta[group_indicator] * x
# Likelihood
y_obs = pm.Normal('y_obs', mu=mu, sigma=sigma, observed=y)
# Sampling
trace = pm.sample(2000, tune=1000)
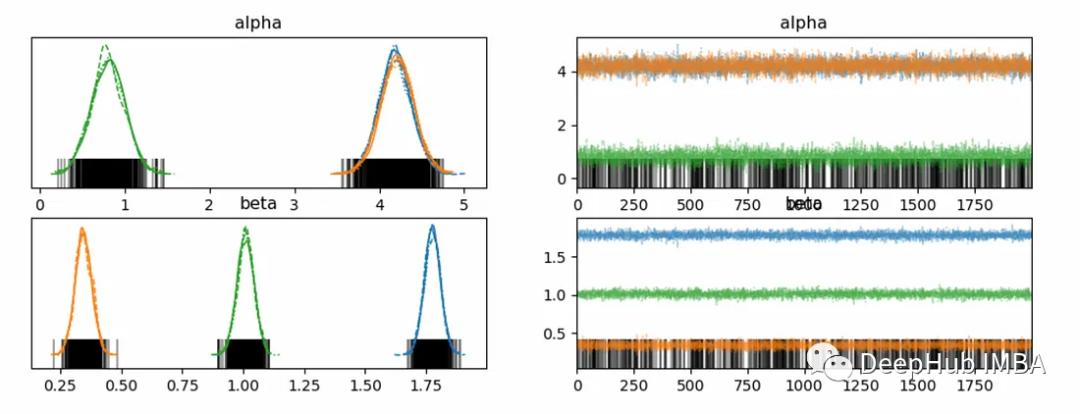
現在我們已經定義了模型并對其進行了采樣。讓我們檢查不同參數的模型估計:
# Checking the trace
pm.plot_trace(trace,var_names=['alpha','beta'])
plt.show()
最后一步是將原始數據和模型預測可視化:
# Posterior samples
alpha_samples = trace.posterior['alpha'].values
beta_samples = trace.posterior['beta'].values
# New x values for predictions
x_new = np.linspace(0, 10, 200)
plt.figure(figsize=(10, 5))
# Plot raw data and predictions for each group
for i in range(n_groups):
# Plot raw data
plt.plot(x[group_indicator == i], y[group_indicator == i], 'o', color=colors[i], label=f'Group {i+1} observed')
x_new = x[group_indicator == i]
# Generate and plot predictions
alpha = trace.posterior.sel(alpha_dim_0=i,beta_dim_0=i)['alpha'].values
beta = trace.posterior.sel(alpha_dim_0=i,beta_dim_0=i)['beta'].values
y_hat = alpha[..., None] + beta[..., None] * x_new[None,:]
y_hat_mean = y_hat.mean(axis=(0, 1))
y_hat_std = y_hat.std(axis=(0, 1))
plt.plot(x_new, y_hat_mean, color=colors[i], label=f'Group {i+1} predicted')
plt.fill_between(x_new, y_hat_mean - 2*y_hat_std, y_hat_mean + 2*y_hat_std, color=colors[i], alpha=0.3)
plt.title('Raw Data with Posterior Predictions by Group')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()

從圖中可以看出,分層時間序列模型很好地捕獲了每組中的單個趨勢,而陰影區域給出了預測的不確定性。
層次模型為捕獲時間序列數據中的組級變化提供了一個強大的框架。它們允許我們在組之間共享統計數據,提供部分信息池和對數據結構的細微理解。使用像PyMC這樣的庫,實現這些模型變得相當簡單,為健壯且可解釋的時間序列分析鋪平了道路。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
python
+關注
關注
56文章
4797瀏覽量
84689 -
Alpha
+關注
關注
0文章
45瀏覽量
25620
發布評論請先 登錄
相關推薦
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
的,書籍封面如下。下面對全書概覽并對第一章時間序列概述進行細度。
一. 全書概覽
全書分為8章,每章的簡介如下:
●第1章“時間序列概述
發表于 08-07 23:03
使用PyMC3包實現貝葉斯線性回歸
1、如何使用PyMC3包實現貝葉斯線性回歸 PyMC3(現在簡稱為PyMC)是一個貝葉斯建模包,它使數據科學家能夠輕松地進行貝葉斯推斷。
發表于 10-08 15:59
基于SAX的時間序列分類
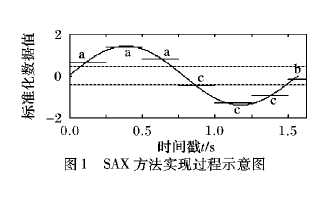
分類問題是數據挖掘中的基本問題之一,時間序列的特征表示及相似性度量是時間序列數據挖掘中分類、聚類及模式發現等任務的基礎。SAX方法是一種典型的時間
發表于 11-30 14:49
?2次下載
小波回聲狀態網絡的時間序列預測
為了更好的對具有多尺度特性的時間序列進行預測,運用小波分析方法與回聲狀態網絡模型相結合來創建小波回聲狀態網絡預測模型。利用小波方法對原始時間序列
發表于 01-13 11:40
?0次下載
基于系數矩陣弧微分的時間序列相似度量
的最小二乘思想,通過構建系數矩陣獲取時間序列形態屬性向量基,實現序列曲線的連續化。在此基礎上,應用連續函數的弧微分與曲率半徑的關系進行時間序列
發表于 03-29 09:45
?0次下載
如何基于Keras和Tensorflow用LSTM進行時間序列預測
為了做到這一點,我們需要先對CSV文件中的數據進行轉換,把處理后的數據加載到pandas的數據框架中。之后,它會輸出numpy數組,饋送進LSTM。Keras的LSTM一般輸入(N, W, F)三維numpy數組,其中N表示訓練數據中的序列數,W表示
如何使用頻繁模式發現進行時間序列異常檢測詳細方法概述
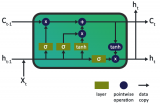
針對傳統異常片 段檢測方法在處理增量式時間序列時效率低的問題,提出一種基于頻繁模式發現的時間序列異常檢測(TSAD)方法。首先,將歷史輸入的時間
發表于 11-28 11:09
?5次下載
如何用Python進行時間序列分解和預測?
預測是一件復雜的事情,在這方面做得好的企業會在同行業中出類拔萃。時間序列預測的需求不僅存在于各類業務場景當中,而且通常需要對未來幾年甚至幾分鐘之后的時間序列

基于時間卷積網絡的通用日志序列異常檢測框架
基于循環神經網絡的日志序列異常檢測模型對短序列有較好的檢測能力,但對長序列的檢測準確性較差。為此,提出一種基于時間卷積網絡的通用日志序列異常
發表于 03-30 10:29
?8次下載

如何使用SBC ToolBox云平臺進行時間序列分析?
使用SBC ToolBox云平臺時間序列分析模塊探索基因集在不同時間點的表達趨勢,使用c-means算法對基因集進行聚類分群,尋找出表達趨勢一致的基因集。
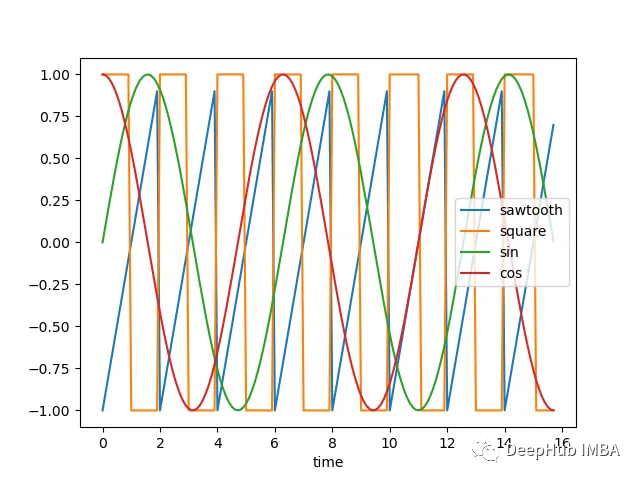
如何使用RNN進行時間序列預測
一種強大的替代方案,能夠學習數據中的復雜模式,并進行準確的預測。 RNN的基本原理 RNN是一種具有循環結構的神經網絡,它能夠處理序列數據。在RNN中,每個輸入序列的元素都會通過一個或多個循環層,這些循環層可以捕獲





 工商網監
工商網監
評論