") DPU 技術(shù)發(fā)展概況系列(三) DPU的發(fā)展背景
DPU 技術(shù)發(fā)展概況系列(三) DPU的發(fā)展背景
DPU的出現(xiàn)是異構(gòu)計算的又一個階段性標(biāo)志。摩爾定律放緩使得通用CPU性能增長的邊際成本迅速上升,數(shù)據(jù)表明現(xiàn)在CPU的性能年化增長(面積歸一化之后)僅有3%左右,但計算需求卻是爆發(fā)性增長,這幾乎是所有專用計算芯片得以發(fā)展的重要背景因素。以AI芯片為例,最新的GPT-3等千億級參數(shù)的超大型模型的出現(xiàn),將算力需求推向了一個新的高度。DPU也不例外。隨著2019年我國以信息網(wǎng)絡(luò)等新型基礎(chǔ)設(shè)施為代表的“新基建”戰(zhàn)略帷幕的拉開,5G、千兆光纖網(wǎng)絡(luò)建設(shè)發(fā)展迅速,移動互聯(lián)網(wǎng)、工業(yè)互聯(lián)網(wǎng)、車聯(lián)網(wǎng)等領(lǐng)域發(fā)展日新月異。云計算、數(shù)據(jù)中心、智算中心等基礎(chǔ)設(shè)施快速擴容。網(wǎng)絡(luò)帶寬從主流10G朝著25G、40G、100G、200G甚至400G發(fā)展。網(wǎng)絡(luò)帶寬和連接數(shù)的劇增使得數(shù)據(jù)的通路更寬、更密,直接將處于端、邊、云各處的計算節(jié)點暴露在了劇增的數(shù)據(jù)量下,而CPU的性能增長率與數(shù)據(jù)量增長率出現(xiàn)了顯著的“剪刀差”現(xiàn)象。所以,尋求效率更高的計算芯片就成為了業(yè)界的共識。DPU芯片就是在這樣的趨勢下提出的。
一、帶寬性能增速比(RBP)失調(diào)
摩爾定律的放緩與全球數(shù)據(jù)量的爆發(fā)這個正在迅速激化的矛盾通常被作為處理器專用化的大背景,正所謂硅的摩爾定律雖然已經(jīng)明顯放緩,但“數(shù)據(jù)摩爾定律”已然到來。IDC的數(shù)據(jù)顯示,全球數(shù)據(jù)量在過去10年年均復(fù)合增長率接近50%,并進一步預(yù)測每四個月對于算力的需求就會翻一倍。因此必須要找到新的可以比通用處理器帶來更快算力增長的計算芯片,DPU于是應(yīng)運而生。這個大背景雖然有一定的合理性,但是還是過于模糊,并沒有回答DPU之所以新的原因是什么,是什么“量變”導(dǎo)致了“質(zhì)變”?
從現(xiàn)在已經(jīng)公布的各個廠商的DPU架構(gòu)來看,雖然結(jié)構(gòu)有所差異,但都不約而同強調(diào)網(wǎng)絡(luò)處理能力。從這個角度看,DPU是一個強IO型的芯片,這也是DPU與CPU最大的區(qū)別。CPU的IO性能主要體現(xiàn)在高速前端總線(在Intel的體系里稱之為FSB,F(xiàn)ront Side Bus),CPU通過FSB連接北橋芯片組,然后連接到主存系統(tǒng)和其他高速外設(shè)(主要是PCIe設(shè)備)。目前更新的CPU雖然通過集成存儲控制器等手段弱化了北橋芯片的作用,但本質(zhì)是不變的。CPU對于處理網(wǎng)絡(luò)處理的能力體現(xiàn)在網(wǎng)卡接入鏈路層數(shù)據(jù)幀,然后通過操作系統(tǒng)(OS)內(nèi)核態(tài),發(fā)起DMA中斷響應(yīng),調(diào)用相應(yīng)的協(xié)議解析程序,獲得網(wǎng)絡(luò)傳輸?shù)臄?shù)據(jù)(雖然也有不通過內(nèi)核態(tài)中斷,直接在用戶態(tài)通過輪詢獲得網(wǎng)絡(luò)數(shù)據(jù)的技術(shù),如Intel的DPDK,Xilinx的Onload等,但目的是降低中斷的開銷,降低內(nèi)核態(tài)到用戶態(tài)的切換開銷,并沒有從根本上增強IO性能)。可見,CPU是通過非常間接的手段來支持網(wǎng)絡(luò)IO,CPU的前端總線帶寬也主要是要匹配主存(特別是DDR)的帶寬,而不是網(wǎng)絡(luò)IO的帶寬。
相較而言,DPU的IO帶寬幾乎可以與網(wǎng)絡(luò)帶寬等同,例如,網(wǎng)絡(luò)支持25G,那么DPU就要支持25G。從這個意義上看,DPU繼承了網(wǎng)卡芯片的一些特征,但是不同于網(wǎng)卡芯片,DPU不僅僅是為了解析鏈路層的數(shù)據(jù)幀,而是要做直接的數(shù)據(jù)內(nèi)容的處理,進行復(fù)雜的計算。所以,DPU是在支持強IO基礎(chǔ)上的具備強算力的芯片。簡言之,DPU是一個IO密集型的芯片;相較而言,GPU還是一個計算密集型芯片。
進一步地,通過比較網(wǎng)絡(luò)帶寬的增長趨勢和通用CPU性能增長趨勢,能發(fā)現(xiàn)一個有趣的現(xiàn)象:帶寬性能增速比(RBP,Ratioof Bandwidth and Performance growth rate)失調(diào)。RBP定義為網(wǎng)絡(luò)帶寬的增速比上CPU性能增速,即RBP=BW GR/Perf. GR如下圖所示,以Mellanox的ConnectX系列網(wǎng)卡帶寬作為網(wǎng)絡(luò)IO的案例,以Intel的系列產(chǎn)品性能作為CPU的案例,定義一個新指標(biāo)“帶寬性能增速比”來反應(yīng)趨勢的變化。
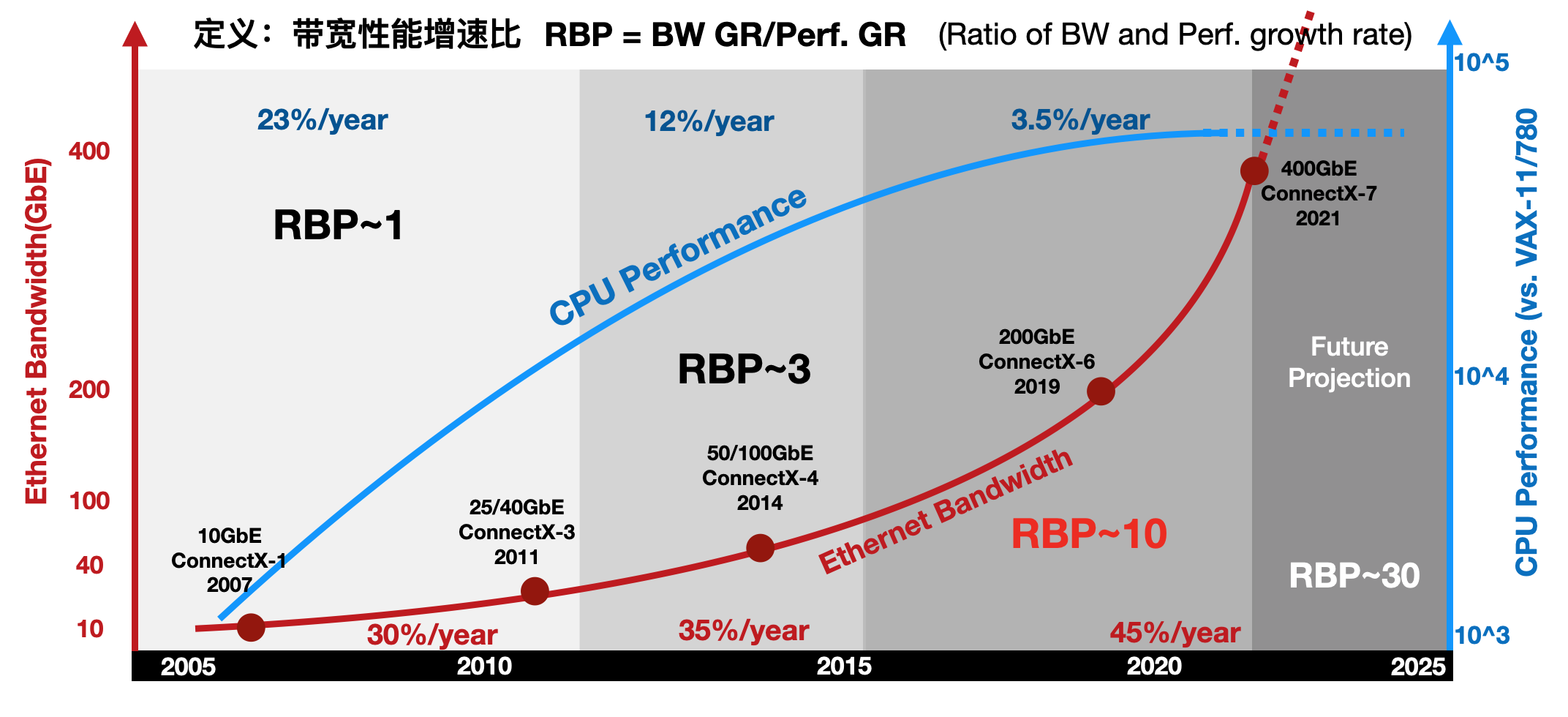
圖 帶寬性能增速比(RBP)失調(diào)
2010年前,網(wǎng)絡(luò)的帶寬年化增長大約是30%,到2015年微增到35%,然后在近年達到45%。相對應(yīng)的,CPU的性能增長從10年前的23%,下降到12%,并在近年直接降低到3%。在這三個時間段內(nèi),RBP指標(biāo)從1附近,上升到3,并在近年超過了10!如果在網(wǎng)絡(luò)帶寬增速與CPU性能增速近乎持平,RGR~1,IO壓力尚未顯現(xiàn)出來,那么當(dāng)目前RBP達到10倍的情形下,CPU幾乎已經(jīng)無法直接應(yīng)對網(wǎng)絡(luò)帶寬的增速。RBP指標(biāo)在近幾年劇增也許是DPU終于等到機會“橫空出世”的重要原因之一。
二、異構(gòu)計算發(fā)展趨勢的助力
DPU首先作為計算卸載的引擎,直接效果是給CPU“減負(fù)”。DPU的部分功能可以在早期的TOE(TCP/IP Offloading Engine)中看到。正如其名,TOE就是將CPU的處理TCP協(xié)議的任務(wù)“卸載”到網(wǎng)卡上。傳統(tǒng)的TCP軟件處理方式雖然層次清晰,但也逐漸成為網(wǎng)絡(luò)帶寬和延遲的瓶頸。軟件處理方式對CPU的占用,也影響了CPU處理其他應(yīng)用的性能。TCP卸載引擎(TOE)技術(shù),通過將TCP協(xié)議和IP協(xié)議的處理進程交由網(wǎng)絡(luò)接口控制器進行處理,在利用硬件加速為網(wǎng)絡(luò)時延和帶寬帶來提升的同時,顯著降低了CPU處理協(xié)議的壓力。具體有三個方面的優(yōu)化:1)隔離網(wǎng)絡(luò)中斷,2)降低內(nèi)存數(shù)據(jù)拷貝量,3)協(xié)議解析硬件化。這三個技術(shù)點逐漸發(fā)展成為現(xiàn)在數(shù)據(jù)平面計算的三個技術(shù),也是DPU普遍需要支持的技術(shù)點。例如,NVMe協(xié)議,將中斷策略替換為輪詢策略,更充分的開發(fā)高速存儲介質(zhì)的帶寬優(yōu)勢;DPDK采用用戶態(tài)調(diào)用,開發(fā)“Kernel-bypassing”機制,實現(xiàn)零拷貝(Zeor-Copy);在DPU中的面向特定應(yīng)用的專用核,例如各種復(fù)雜的校驗和計算、數(shù)據(jù)包格式解析、查找表、IP安全(IPSec)的支持等,都可以視為協(xié)議處理的硬件化支持。所以,TOE基本可以被視為DPU的雛形。
延續(xù)TOE的思想,將更多的計算任務(wù)卸載至網(wǎng)卡側(cè)來處理,促進了智能網(wǎng)卡(SmartNIC)技術(shù)的發(fā)展。常見的智能網(wǎng)卡的基本結(jié)構(gòu)是以高速網(wǎng)卡為基本功能,外加一顆高性能的FPGA芯片作為計算的擴展,來實現(xiàn)用戶自定義的計算邏輯,達到計算加速的目的。然而,這種“網(wǎng)卡+FPGA”的模式并沒有將智能網(wǎng)卡變成一個絕對主流的計算設(shè)備,很多智能網(wǎng)卡產(chǎn)品被當(dāng)作單純的FPGA加速卡來使用,在利用FPGA優(yōu)勢的同時,也繼承了所有FPGA的局限性。DPU是對現(xiàn)有的SmartNIC的一個整合,能看到很多以往SmartNIC的影子,但明顯高于之前任何一個SmartNIC的定位。
Amazon的AWS在2013研發(fā)了Nitro產(chǎn)品,將數(shù)據(jù)中心開銷(為虛機提供遠(yuǎn)程資源,加密解密,故障跟蹤,安全策略等服務(wù)程序)全部放到專用加速器上執(zhí)行。Nitro架構(gòu)采用輕量化Hypervisor配合定制化的硬件,將虛擬機的計算(主要是CPU和內(nèi)存)和I/O(主要是網(wǎng)絡(luò)和存儲)子系統(tǒng)分離開來,通過PCIe總線連接,節(jié)省了30%的CPU資源。阿里云提出的X-Dragon系統(tǒng)架構(gòu),核心是MOC卡,有比較豐富的對外接口,也包括了計算資源、存儲資源和網(wǎng)絡(luò)資源。MOC卡的核心X-Dragon SOC,統(tǒng)一支持網(wǎng)絡(luò),IO、存儲和外設(shè)的虛擬化,為虛擬機、裸金屬、容器云提供統(tǒng)一的資源池。
可見,DPU其實在行業(yè)內(nèi)已經(jīng)孕育已久,從早期的網(wǎng)絡(luò)協(xié)議處理卸載,到后續(xù)的網(wǎng)絡(luò)、存儲、虛擬化卸載,其帶來的作用還是非常顯著的,只不過在此之前DPU“有實無名”,現(xiàn)在是時候邁上一個新的臺階了。
來源:專用數(shù)據(jù)處理器(DPU)技術(shù)白皮書,中國科學(xué)院計算技術(shù)研究所,鄢貴海等
-
DPU
+關(guān)注
關(guān)注
0文章
358瀏覽量
24182
發(fā)布評論請先 登錄
相關(guān)推薦
直流高壓電源技術(shù)發(fā)展淺析
無線充電技術(shù)發(fā)展趨勢
中科馭數(shù)分析DPU在云原生網(wǎng)絡(luò)與智算網(wǎng)絡(luò)中的實際應(yīng)用
IaaS+on+DPU(IoD)+下一代高性能算力底座技術(shù)白皮書
中科馭數(shù)發(fā)布第三代DPU芯片K2 Pro,較上一代能耗降低30%
中科馭數(shù)CEO鄢貴海:從計算系統(tǒng)的三個視角重新審視DPU的核心價值

芯片軟件全上陣 DPU“全家桶”來了!中科馭數(shù)成功舉辦2024產(chǎn)品發(fā)布會

中科馭數(shù)發(fā)布高性能DPU芯片K2-Pro
芯啟源DPU賦能綠色數(shù)據(jù)中心,助力實現(xiàn)雙碳戰(zhàn)略
NVIDIA DPU編程入門開課儀式在澳門科技大學(xué)成功舉辦
DPU技術(shù)賦能下一代AI算力基礎(chǔ)設(shè)施
明天線上見!DPU構(gòu)建高性能云算力底座——DPU技術(shù)開放日最新議程公布!
中科馭數(shù)DPU技術(shù)開放日秀“肌肉”:云原生網(wǎng)絡(luò)、RDMA、安全加速、低延時網(wǎng)絡(luò)等方案組團亮相

FPGA-Based DPU網(wǎng)卡的發(fā)展和應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論