 自壓縮神經網絡
自壓縮神經網絡
過去十年,人工智能研究主要集中在探索深度神經網絡的潛力。我們近年來看到的進步至少可以部分歸因于網絡規模的不斷擴大。從使用GPT-3 [1] 的文本生成到使用 Imagen [2] 的圖像生成,研究人員付出了相當大的努力來創建更大、更復雜的架構,以實現越來越令人印象深刻的壯舉。此外,現代神經網絡的成功使其在各種應用中部署。就在我寫這篇文章的時候,一個神經網絡正在施圖預測我即將寫的下一個單詞,盡管它不夠準確,不能很快取代我!
另一方面,性能優化在該領域受到的關注相對較少,這是神經網絡更廣泛部署的一個重大障礙。造成這種情況的一個可能原因是能夠同時在數千個GPU 或其他硬件上的數據中心中訓練大型神經網絡。這與計算機圖形領域形成鮮明對比,例如,必須在單臺計算機上實時運行的限制產生了在不犧牲質量的情況下優化算法的強大動力。
神經網絡容量的研究表明,發現高精度解決方案所需的網絡容量大于表示這些解決方案所需的容量。Frankle和Carbin [3]在他們的論文《彩票假設:尋找稀疏、可訓練的神經網絡》 [3] 中發現,只需要網絡中權重的一小部分即可代表一個好的解決方案,但直接訓練容量減少的網絡并不能達到相樣的精度。同樣,Hinton等人。[4] 發現,將“知識”從高精度網絡轉移到低容量網絡可以產生比使用、相同損失函數的高容量網絡更高精度的網絡。
在本篇博文中,我們查找是否可以在訓練時動態減少網絡參數。雖然這樣做具有挑戰性,但由于實現的復雜性( PyTorch不是為處理動態網絡架構而設計的,例如,在訓練期間移除整個通道),
我們希望實現以下優點。
減少最終網絡中的權重數量。
減少剩余權重的位寬。
減少最終網絡的運行時間。
減少訓練時間。
降低設計網絡架構時選擇層寬度的復雜性。
- 不需要特殊的硬件來優化(例如,不需要稀疏矩陣乘法)。
在這項工作中,我們通過引入一種新穎的量化感知訓練(QAT)方案來實現這些目標,該方案平衡了最大化網絡精度和最小化網絡規模的要求。我們同時最大限度地提高精度并最大限度地減少權重位深度,從而消除不太重要或不必要的通道,從而以現有硬件可以輕松利用的方式降低計算和帶寬需求。
可微量化這是通過可微量化實現的,正如我在之前的文章[5]中介紹的那樣。簡而言之,可微量化允許您同時學習數字格式的參數和權重。這允許以與網絡中的權重完全相同的方式學習量化,并啟用諸如自壓縮網絡之類的新技術——本文的主題。量化函數量化為可變比特率有符號定點格式:
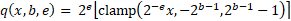
這可以描述為以下步驟順序:
- 使用指數縮放輸入值:
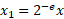
- 使用位深度鉗位值:
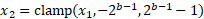
- 四舍五入到最接近的整數:
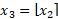
反轉步驟 1 中引入的縮放: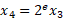
其中 b 是位深度,e 是指數,x 是被量化的值(或一組值) 。為了確保連續可微性,我們在訓練期間使用實值位深度參數。
上述函數使用舍入運算。通過它傳播可用梯度的常用方法是將四舍五入操作的梯度定義為1 而不是 0。這類似于“直通估計器” [6] 。要了解其工作原理,請考慮下圖:
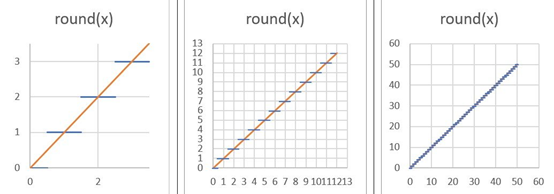
當我們從函數中“縮小”時,您可以看到它是如何實現的;舍入函數似乎接近y=x 線。我們將取整函數的后向傳遞(梯度)替換為函數 y=x 的梯度,即常數1。
可微量化進行自壓縮
在這項工作中,我們使用可微量化(1)來減少訓練期間網絡參數的位寬(即壓縮),以及(2)發現哪些參數可以用 0 位表示。當神經網絡中的參數可以用 0 位表示而不影響網絡的精度時,就沒必要使用該參數。當發現權重張量中的通道可以用0 位表示時,在訓練期間將其從網絡中刪除。這樣做的一個附加好處是訓練會隨著時間的推移而加速(見圖2)。
該過程可以描述如下:
- 將網絡的參數拆分為通道。
- 用位寬和指數的單個量化參數對每個通道進行量化。
- 為原始任務訓練網絡,同時最小化所有位寬參數。
當位寬參數達到 0 時,從網絡中移除該參數編碼的網絡權重通道。由于消除了整個輸出通道,這減少了相應卷積的大小以及消耗輸出張量的任何后續操作,而不會更改網絡輸出。
通過在訓練期間從網絡中移除空(即0 位)通道,我們可以顯著加速訓練而不改變訓練結果:訓練結果與我們在最后只移除空通道時得到的網絡相同。
盡管本文中描述的方法學習壓縮和消除通道,但它可以推廣到其他硬件可利用的學習稀疏模式。
網絡架構
選擇的網絡架構是David Page 的CIFAR-10[7]的DAWNbench條目,這是一個可以快速訓練的淺ResNet 。
使用快速訓練網絡有幾個優點,包括:
- 使算法設計迭代更快,
- 縮短調試周期,
- 使在合理的時間內在單個 GPU 上執行實驗變得容易,
幫助重現這項工作的結果。
該網絡由兩種主要類型的塊組成:卷積塊(卷積→批量歸一化→激活→池化)和殘差塊(殘差分支由兩個卷積塊組成)。
以下部分描述了如何對這些模塊應用可微量化以使其可壓縮。
優化目標
這項工作的目標是減少神經網絡的推理和訓練時間。為了實現這一點,應該在損失函數中體現推理時間,以便將其最小化,從而產生更快的網絡。在這種情況下使用的指標是網絡規模,定義為用于表示網絡中權重的總位數。作為網絡性能的體現,計算層輸出所需的激活張量大小或操作數也可以最小化。單個權重張量的大小可以用四個張量維度的乘積表示:輸出通道、輸入通道、濾波器高度和濾波器寬度(0、I、H、W)。由于我們使用一個單獨的數字格式量化每個輸出通道,并為層提供一個可學習的位數,因此用于表示張量的總位數由下式給出:
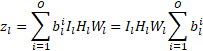
當 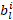 為 0 時,ith通道變得不必要,減少了權重張量中的輸出通道總數,以及下一個卷積的權重張量中相應的輸入通道數。因此最小化通過
為 0 時,ith通道變得不必要,減少了權重張量中的輸出通道總數,以及下一個卷積的權重張量中相應的輸入通道數。因此最小化通過 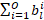 最小化輸出通道的數量,可以最小化權重張量中的元素數量。這有效地最小化了權重張量的輸出維度。認識到一層的輸入通道數等于前一層的輸出通道數,可以使壓縮損失更好地反映網絡的大小。這樣一個權重張量的輸入維度也可以最小化:
最小化輸出通道的數量,可以最小化權重張量中的元素數量。這有效地最小化了權重張量的輸出維度。認識到一層的輸入通道數等于前一層的輸出通道數,可以使壓縮損失更好地反映網絡的大小。這樣一個權重張量的輸入維度也可以最小化:
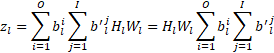
一旦通道可以被壓縮到0 位,它就可能在訓練期間被刪除。然而,需要克服的實際問題是,從卷積層中移除一個輸出通道并不一定意味著可以從下一層的輸入中安全地移除相應的輸入通道,因為可以將偏差添加到層的輸出0中,在這種情況下刪除它可能會顯著改變網絡的輸出。為了處理這個問題,識別達到 0 位的加權通道(過濾器),并對其輸出應用L1 損耗,以將其推至 0 位。只有當偏差減少到0 時,這些過濾器才會被移除,因為此時移除這樣的通道不會改變網絡的輸出。
整個網絡的大小是所有層大小的總和:
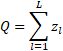
為了平衡網絡的準確性和規模,我們簡單地使用兩項的線性組合:
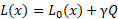
其中L0是網絡的原始損失,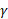 是壓縮因子。較大的 會生成較小但不太準確的網絡。
是壓縮因子。較大的 會生成較小但不太準確的網絡。
處理分支
壓縮網絡時出現的另一個問題是網絡分支的處理,例如,在殘差塊中。解決這個問題最簡單的方法是分別考慮這兩個分支。
更新優化器
實現細節涉及使優化器隨著網絡的變化而更新的問題。優化器跟蹤網絡中每個參數的信息(元參數),當網絡參數被動態刪除時,相應的元參數也必須從優化器中刪除。
結果
自壓縮網絡允許在規模和精度之間進行權衡,可以在規模準確度圖中可視化(參見圖1)。該圖中的每個點都表示一個神經網絡的大小和精度,該神經網絡經過隨機壓縮率,從覆蓋范圍的對數均勻分布中采樣  。圖1 顯示了在使用隨機壓縮率訓練網絡時,用于表示網絡權重的位數與32 位每權重基線(對應于 32 位浮點)之間的關系。這是通過保留權重的百分比乘以剩余權重的平均位寬來計算的。網絡的基線精度(未壓縮精度)為95.69 ± 0.22。
。圖1 顯示了在使用隨機壓縮率訓練網絡時,用于表示網絡權重的位數與32 位每權重基線(對應于 32 位浮點)之間的關系。這是通過保留權重的百分比乘以剩余權重的平均位寬來計算的。網絡的基線精度(未壓縮精度)為95.69 ± 0.22。
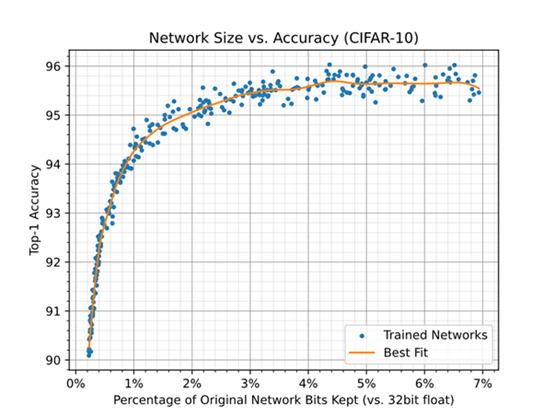
圖 1:當使用隨機壓縮率訓練網絡時,用于表示網絡權重的位數與32位/權重基線之間的關系。
圖 2 僅顯示了網絡中使用的權重數量的減少。在不影響精度的情況下,可以移除大約 75% 的權重。
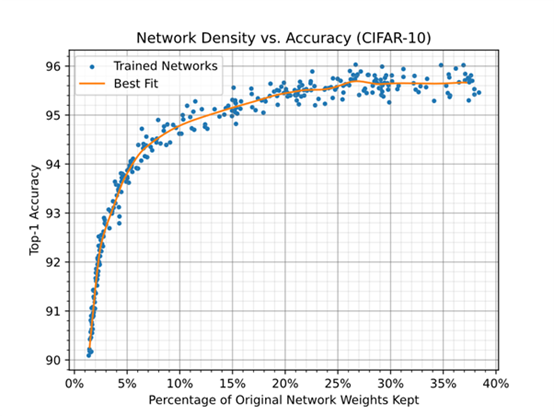
圖 2 顯示了使用隨機壓縮率訓練網絡時,網絡中保留的權重百分比與精度之間的關系。
圖 3 顯示了通過在訓練期間移除權重對訓練時間的影響。一個世代的訓練時間不僅取決于網絡的大小,還取決于系統的其他部分,例如輸入數據通道。為了確定基線訓練開銷,對于同一網絡進行訓練,每個層僅使用一個通道。每個訓練世代大約需要7.5 秒。
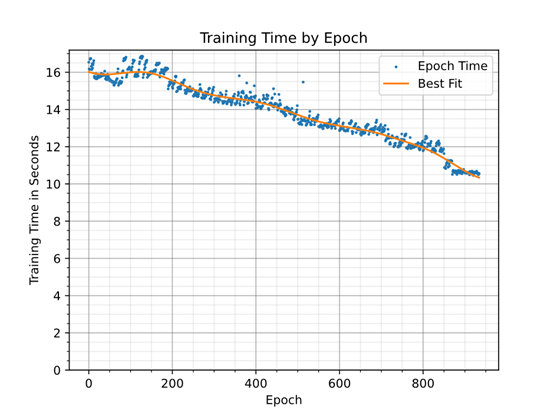 圖 3:隨著參數從網絡中移除,神經網絡訓練時間加快。訓練結束時移除了 86% 的權重。圖 4 顯示了
圖 3:隨著參數從網絡中移除,神經網絡訓練時間加快。訓練結束時移除了 86% 的權重。圖 4 顯示了  時使用壓縮率訓練的網絡架構。訓練將移除除殘差層中的快捷分支。其余九個通道在訓練結束時已經達到 0 位,并且正在消除它們的偏差。預計它們會隨著更長的訓練而消失。第二個殘差層中的快捷分支與它相關的損失非常低(由于它對網絡規模的貢獻最小),因此它的減少速度太慢,無法在訓練結束時消失。
時使用壓縮率訓練的網絡架構。訓練將移除除殘差層中的快捷分支。其余九個通道在訓練結束時已經達到 0 位,并且正在消除它們的偏差。預計它們會隨著更長的訓練而消失。第二個殘差層中的快捷分支與它相關的損失非常低(由于它對網絡規模的貢獻最小),因此它的減少速度太慢,無法在訓練結束時消失。
 圖 4:訓練前后的層大小和每層平均位寬的示例。這里刪除了 86% 的權重和 97.6% 的位。每個方塊代表一個卷積。方塊中的值表示卷積的輸出或輸入(“in”)通道的總數,其中需要此類信息(在分支處)。
圖 4:訓練前后的層大小和每層平均位寬的示例。這里刪除了 86% 的權重和 97.6% 的位。每個方塊代表一個卷積。方塊中的值表示卷積的輸出或輸入(“in”)通道的總數,其中需要此類信息(在分支處)。
圖 5 顯示了整個訓練過程中的網絡規格。它在早期迅速收縮,然后逐漸減少。
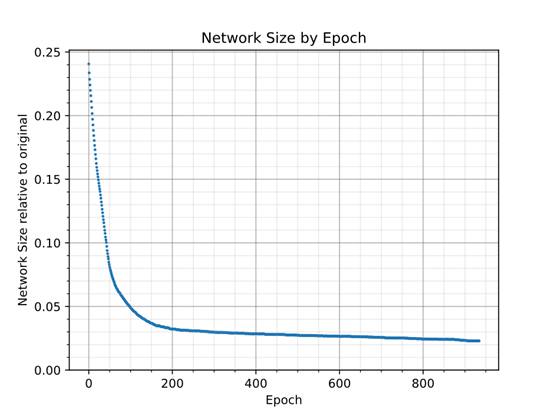
圖 5:網絡規模在訓練早期快速縮小,之后逐漸減小。
優化您的網絡
在本篇博文中,我們分享了一個通用框架,用于優化神經網絡的典型固定特征——通道數和位寬——以使網絡在訓練過程中學會自我壓縮。這樣做的主要優點是更快的執行時間和更快的生成網絡訓練。以前的許多工作都集中在通過創建稀疏層來減少網絡規模,這需要軟件和/或硬件的特殊支持才能更有效地運行。簡單地減少層的寬度不需要專門支持。通過減少 DRAM 帶寬,支持可變位寬可以提高多種架構的性能。
參考
[1] T. B. Brown and al, “Language Models are Few-Shot Learners,” 2020.
[2] C. Saharia and al, “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding,” 2022.
[3] J. Frankle and M. Carbin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,” 2018.
[4] G. Hinton, O. Vinyals and J. Dean, “Distilling the Knowledge in a Neural Network,” 2015.
[5] Cséfalvay, S, “High-Fidelity Conversion of Floating-Point Networks for Low-Precision Inference using Distillation,” 25 May 2021. [Online]. Available: https://blog.imaginationtech.com/low-precision-inference-using-distillation/.
[6] G. Hinton, “Lecture 9.3 — Using noise as a regularizer [Neural Networks for Machine Learning],” 2012. [Online]. Available: https://www.youtube.com/watch?v=LN0xtUuJsEI&list=PLoRl3Ht4JOcdU872GhiYWf6jwrk_SNhz9.
[7] Page, D, “How to Train Your ResNet 8: Bag of Tricks,” 19 Aug 2019. [Online]. Available: https://myrtle.ai/how-to-train-your-resnet-8-bag-of-tricks/.
本文作者:Szabolcs Cséfalvay
-
人工智能
+關注
關注
1791文章
47336瀏覽量
238696
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論