 ChatGPT熱潮席卷全球ChatGPT將帶動哪些芯片的需求?ChatGPT帶來的啟示
ChatGPT熱潮席卷全球ChatGPT將帶動哪些芯片的需求?ChatGPT帶來的啟示
最近,ChatGPT熱潮席卷全球。
ChatGPT(Chat Generative Pre-trained Transformer)是由OpenAI于2022年12月推出的對話AI模型,僅發布2個月便實現月活突破1億,成為歷史上用戶增長最快的消費級應用之一。
ChatGPT火出圈背后是“人類反饋強化模型”的應用。在問答模式的基礎上,ChatGPT可以進行推理、編寫代碼、文本創作等等,這樣的特殊優勢和用戶體驗使得應用場景流量大幅增加。
隨著ChatGPT用戶數快速增長,需求量火爆引發宕機。在龐大用戶群涌入的情況下,ChatGPT服務器2天宕機5次,火爆程度引人注目的同時也催生了對算力基礎設施建設更高的要求,特別是底層芯片。那么,ChatGPT將帶動哪些芯片的需求?
AI服務器需求激增
當前,ChatGPT在問答模式的基礎上進行推理、編寫代碼、文本創作等,用戶人數及使用次數均提升,同時在一些新應用場景也產生了較大的流量,比如智能音箱、內容生產、游戲NPC、陪伴機器人等。隨著終端用戶使用頻率提高,數據流量暴漲,對服務器的數據處理能力、可靠性及安全性等要求相應提升。
從技術原理來看,ChatGPT基于Transformer技術,隨著模型不斷迭代,層數也越來越多,對算力的需求也就越來越大。從運行條件來看,ChatGPT完美運行的三個條件:訓練數據+模型算法+算力,需要在基礎模型上進行大規模預訓練,存儲知識的能力來源于1750億參數,需要大量算力。
資料顯示,ChatGPT是基于GPT-3.5優化的一個模型,GPT-3.5是GPT-3.0的微調版本。OpenAI的GPT-3.0模型存儲知識的能力來源于1750億參數,單次訓練費用約460萬美元,GPT-3.5在微軟AzureAI超算基礎設施上進行訓練,總算力消耗約3640PF-days(即假如每秒計算一千萬億次,需要計算3640天)。
可以說,ChatGPT拉動了芯片產業量價齊升,即不僅對人工智能底層芯片數量產生了更大的需求,而且對底層芯片算力也提出了更高的要求,即拉動了高端芯片的需求。據悉,采購一片英偉達頂級GPU成本為8萬元,GPU服務器成本通常超過40萬元。支撐ChatGPT的算力基礎設施至少需要上萬顆英偉達GPU A100,高端芯片需求的快速增加會進一步拉高芯片均價。
隨著ChatGPT流量激增,作為算力載體的AI服務器將迎來重要發展機遇。預計,全球AI服務器市場將從2020年的122億美元成長到2025年288億美元,年復合增長率達到18.8%。
這些芯片將受益
從芯片構成來看,AI服務器主要是CPU+加速芯片,通常搭載GPU、FPGA、ASIC等加速芯片,利用CPU與加速芯片的組合可以滿足高吞吐量互聯的需求。
1.CPU
作為計算機系統的運算和控制核心,是信息處理、程序運行的最終執行單元。其優勢在于有大量的緩存和復雜的邏輯控制單元,擅長邏輯控制、串行的運算;劣勢在于計算量較小,且不擅長復雜算法運算和處理并行重復的操作。因此,CPU在深度學習中可用于推理/預測。
目前,服務器CPU向多核心發展,滿足處理能力和速度提升需要,比如AMD EPYC 9004核心數量最多可達96個。不過,系統性能優劣不能只考慮CPU核心數量,還要考慮操作系統、調度算法、應用和驅動程序等。
2.GPU
GPU高度適配AI模型構建,由于具備并行計算能力,可兼容訓練和推理,目前GPU被廣泛應用于加速芯片。以英偉達A100為例,在訓練過程中,GPU幫助高速解決問題:2048個A100 GPU可在一分鐘內成規模地處理 BERT之類的訓練工作負載。在推理過程中,多實例GPU (MIG)技術允許多個網絡同時基于單個A100運行,從而優化計算資源的利用率。在A100其他推理性能增益的基礎之上,僅結構稀疏支持一項就能帶來高達兩倍的性能提升。在BERT等先進的對話式AI模型上,A100可將推理吞吐量提升到高達CPU的249倍。
目前,ChatGPT引發了GPU應用熱潮。其中,百度即將推出文心一言(ERNIE Bot)。蘋果則引入AI加速器設計的M2系列芯片(M2 pro和M2 max)將被搭載于新款電腦。隨著ChatGPT的使用量激增,OpenAI需要更強的計算能力來響應百萬級別的用戶需求,因此增加了對英偉達GPU的需求。
AMD計劃推出與蘋果M2系列芯片競爭的臺積電4nm工藝“Phoenix”系列芯片,以及使用Chiplet工藝設計的“Alveo V70”AI芯片。這兩款芯片均計劃在今年推向市場,分別面向消費電子市場以及AI推理領域。
3.FPGA
FPGA具有可編程靈活性高、開發周期短、現場可重編功能、低延時、方便并行計算等特點,可通過深度學習+分布集群數據傳輸賦能大模型。
4.ASIC
ASIC在批量生產時與通用集成電路相比具有體積更小、功耗更低、可靠性提高、性能提高、保密性增強、成本降低等優點,可進一步優化性能與功耗。隨著機器學習、邊緣計算、自動駕駛的發展,大量數據處理任務的產生,對于芯片計算效率、計算能力和計能耗比的要求也越來越高,ASIC通過與CPU結合的方式被廣泛關注,國內外龍頭廠商紛紛布局迎戰AI時代的到來。
其中,谷歌最新的TPU v4集群被稱為Pod,包含4096個v4芯片,可提供超過1 exaflops的浮點性能。英偉達GPU+CUDA主要面向大型數據密集型HPC和AI應用;基于Grace的系統與NVIDIAGPU緊密結合,性能比NVIDIADGX系統高出10倍。百度昆侖2代AI芯片采用全球領先的7nm 制程,搭載自研的第二代 XPU 架構,相比一代性能提升2-3倍;昆侖芯3代將于2024年初量產。
5.光模塊
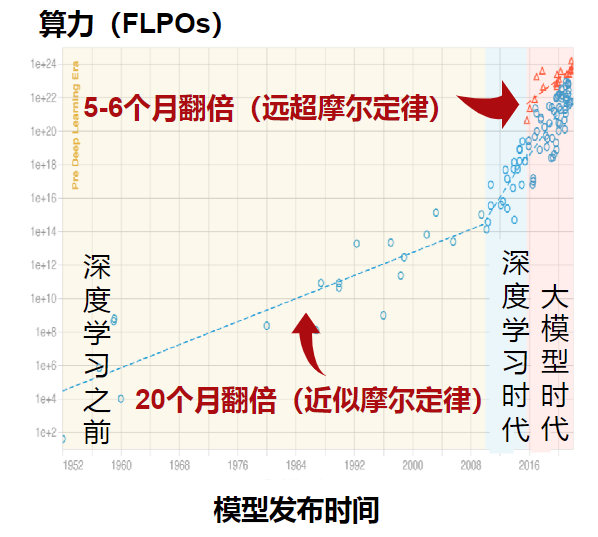
當前,AI時代模型算力需求已經遠超摩爾定律的速度增長,特別是在深度學習、大模型時代之后,預計5-6個月翻倍。然而,數據傳輸速率成為容易被忽略的算力瓶頸。伴隨數據傳輸量的增長,光模塊作為數據中心內設備互聯的載體,需求量隨之增長。
來源:Google Scholar
未來算力升級路徑
最近,ChatGPT的興起推動著人工智能在應用端的蓬勃發展,這也對計算設備的運算能力提出了前所未有的需求。雖然AI芯片、GPU、CPU+FPGA等芯片已經對現有模型構成底層算力支撐,但面對未來潛在的算力指數增長,短期使用Chiplet異構技術加速各類應用算法落地,長期來看打造存算一體芯片(減少芯片內外的數據搬運),或將成為未來算力升級的潛在方式。
1. Chiplet
Chiplet是布局先進制程、加速算力升級的關鍵技術。Chiplet異構技術不僅可以突破先進制程的封鎖,并且可以大幅提升大型芯片的良率、降低設計的復雜程度和設計成本、降低芯片制造成本。不過,雖然Chiplet技術加速了算力升級,但需要犧牲一定的體積和功耗,因此將率先在基站、服務器、智能電車等領域廣泛使用。
目前,Chiplet已廣泛應用于服務器芯片。AMD是Chiplet服務器芯片的引領者,其基于Chiplet的第一代AMDEPYC處理器中,裝載8個“Zen”CPU核,2個DDR4內存通道和32個PCIe通道。2022年AMD正式發布第四代EPYC處理器,擁有高達96顆5nm的Zen4核心,并使用新一代的Chiplet工藝,結合5nm和6nm工藝來降低成本。
英特爾第14代酷睿Meteor Lake首次采用intel 4工藝,首次引入Chiplet小芯片設計,預計將于2023年下半年推出,至少性能功耗比的目標要達到13代 Raptor Lake的1.5倍水平。
2.存算一體
正如上文提到的,AI時代模型算力需求遠超摩爾定律的速度增長,單純靠縮微化制程已經無法滿足需求而且成本急速攀升。實際上,從現有芯片架構來看,超過60%時間是花在數據搬運上,超過90%的功耗也損失在數據搬運上,能效非常低。因此,存儲墻”成為了數據計算應用的一大障礙。而存算一體是算力需求上升的主要解決技術路線之一。
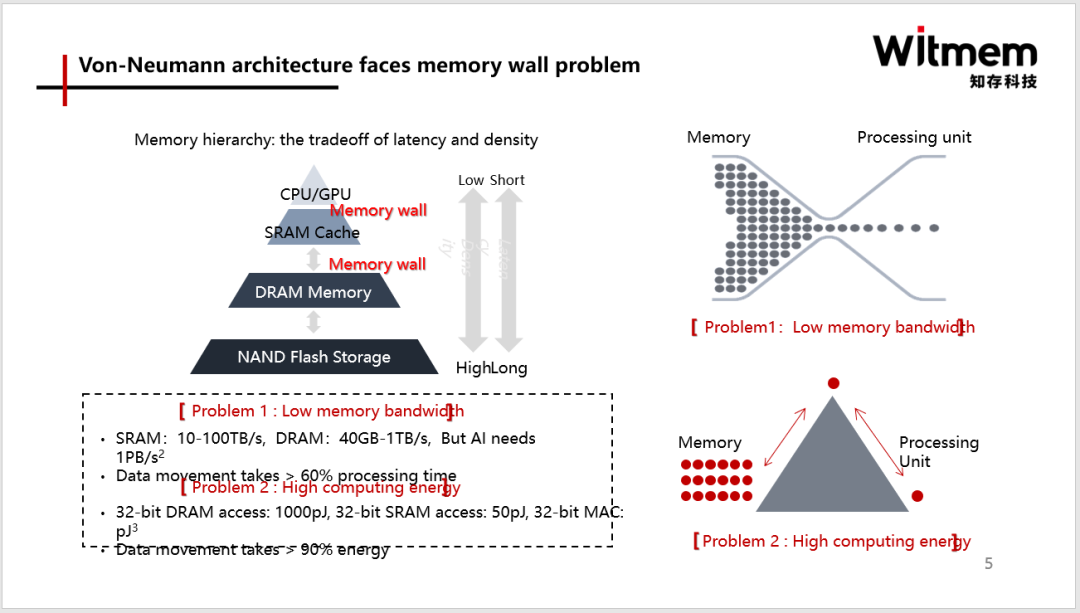
存內計算的計算原理可以理解成是用存儲器做計算,其計算單元不再是邏輯器件、CPU、GPU或者NPU,與這些架構是完全不一樣的。存內計算直接運算單元是存儲單元本身。存算一體技術通過在存儲器中疊加計算能力,以新的高效運算架構進行二維和三維矩陣運算。
以上信息由英利檢測(Teslab)原創發布,歡迎一起討論,我們一直在關注這方面的發展,如有引用也請注明出處。
國家高新技術企業;唯一覆蓋中國和歐美運營商認證服務機構;業內最為優秀第三方認證服務商之一;專業的人做專業的事;
入庫:┆移動┆聯通┆電信┆中國廣電┆
歐美:┆GCF┆PTCRB┆VzW┆ATT┆TMO┆FCC┆
中國:┆CCC┆SRRC┆CTA┆
號碼:┆IMEI┆MAC┆MEID┆EAN┆
-
芯片
+關注
關注
455文章
50816瀏覽量
423625 -
AI
+關注
關注
87文章
30896瀏覽量
269087 -
ChatGPT
+關注
關注
29文章
1561瀏覽量
7671
發布評論請先 登錄
相關推薦
ChatGPT新增實時搜索與高級語音功能
OpenAI推出ChatGPT搜索功能
ChatGPT:怎樣打造智能客服體驗的重要工具?





 工商網監
工商網監
評論