") GPT-4已經(jīng)會自己設(shè)計芯片了嗎?
GPT-4已經(jīng)會自己設(shè)計芯片了嗎?
GPT-4已經(jīng)會自己設(shè)計芯片了!芯片設(shè)計行業(yè)的一個老大難問題HDL,已經(jīng)被GPT-4順利解決。并且,它設(shè)計的130nm芯片,已經(jīng)成功流片。
GPT-4,已經(jīng)可以幫人類造芯片了!
只用簡單的英語對話,紐約大學(xué)Tandon工程學(xué)院的研究人員就通過GPT-4造出了一個芯片。
具體來說,GPT-4通過來回對話,就生成了可行的Verilog。隨后將基準(zhǔn)測試和處理器發(fā)送到Skywater 130 nm穿梭機(jī)上成功流片(tapeout)。
這項(xiàng)成就,堪稱史無前例。
這意味著,在大語言模型的幫助下,芯片設(shè)計行業(yè)的大難題——HDL將被攻克。芯片開發(fā)的速度將大大加快,并且芯片設(shè)計的門檻也被大大降低,沒有專業(yè)技能的人都可以設(shè)計芯片了。
研究者表示:「可以認(rèn)為,這項(xiàng)研究產(chǎn)生了第一個完全由AI生成的HDL(硬件描述語言),它可以直接用來制造物理芯片。」
HDL難題被GPT-4順利解決
如上圖所示,芯片設(shè)計和制造中非常重要的一部分代碼——Verilog,就是研究人員通過提示詞讓GPT-4生成的。
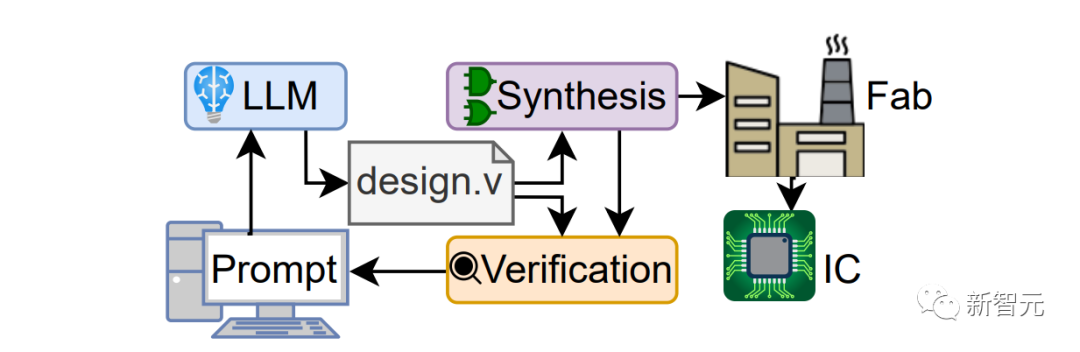
在NYU的這項(xiàng)研究中,兩名硬件工程師僅僅通過英語和GPT-4交談,就設(shè)計出了一種新型的8位基于累加器微處理器架構(gòu)。
而GPT-4設(shè)計的芯片,顯然已經(jīng)達(dá)到了工業(yè)標(biāo)準(zhǔn),因?yàn)樗S后就被研究者送去在Skywater 130nm shuttle上制造了。
這標(biāo)志著第一個由大語言模型設(shè)計的IC被實(shí)際制造出來,達(dá)到了一個里程碑。

硬件描述語言(HDL),一直是芯片設(shè)計行業(yè)一直面臨的一個巨大挑戰(zhàn)。
因?yàn)镠DL代碼需要非常專業(yè)的知識,對很多工程師來說,想要掌握它們非常困難。
如果大語言模型可以替代HDL的工作,工程師就可以把精力集中在攻關(guān)更有用的事情上。
Pearce博士面對自己設(shè)計出的第一塊芯片,頗為感慨地表示:「我根本就不是芯片設(shè)計專家,卻設(shè)計出了一塊芯片,這正是令人印象深刻的地方。」
通常情況下,開發(fā)任何類型的硬件(包括芯片),第一步都是用日常語言描述硬件功能。
隨后,經(jīng)過專門培訓(xùn)的工程師會把這個描述翻譯成硬件描述語言 (HDL),由此創(chuàng)建允許硬件執(zhí)行任務(wù)的實(shí)際電路元件。
Verilog就是一個經(jīng)典的例子。在這項(xiàng)研究中,大語言模型能夠通過來回對話生成可行的Verilog。隨后就是將基準(zhǔn)測試和處理器發(fā)送到Skywater 130 nm穿梭機(jī)上,進(jìn)行流片(tapeout)。
紐約大學(xué)坦登電氣與計算機(jī)工程系以及網(wǎng)絡(luò)安全中心的研究助理教授Dr. Hammond Pearce介紹說,之所以啟動這個Chip Chat項(xiàng)目,是希望探索大語言模型在硬件設(shè)計領(lǐng)域的能力。
在他們看來,這些大語言模型不僅僅是「玩具」,而是有潛力做更多事情。為了驗(yàn)證這個概念,Chip Chat項(xiàng)目誕生了。
我們都知道,OpenAI的ChatGPT和谷歌的Bard都可以生成不同編程語言的軟件代碼,但它們在硬件設(shè)計的應(yīng)用中尚未得到廣泛的研究。
而NYU的這項(xiàng)研究表明,AI不僅可以生成軟件代碼,還能使硬件制造收益。
大語言模型的優(yōu)點(diǎn)在于,我們可以采用對話的方式與其交互,這樣,我們就能通過有來有回的方式,來完善硬件的設(shè)計。
研究團(tuán)隊(duì)使用大語言模型處理了8個硬件設(shè)計示例,尤其是生成用于功能和驗(yàn)證目的的Vrilog代碼。
此前,研究人員就曾測試了大語言模型將英語轉(zhuǎn)換為Vrilog的效果,但他們發(fā)現(xiàn),加入與人類工程師的交互過程后,大語言模型才產(chǎn)生了最好的Vrilog。
這項(xiàng)研究不僅僅停留在實(shí)驗(yàn)層面。研究人員發(fā)現(xiàn),如果在現(xiàn)實(shí)環(huán)境中將這個方法投入實(shí)踐,大語言模型可以減少HDL轉(zhuǎn)換過程中的人為錯誤,這就可以大大提高生產(chǎn)力,縮短芯片的設(shè)計時間和上市時間,還允許芯片設(shè)計者進(jìn)行更具創(chuàng)意的設(shè)計。
另外,這個過程還極大地降低了芯片設(shè)計師對HDL流利程度的需求。
因?yàn)閷慔DL是一種相對罕見的技能,對不少芯片設(shè)計求職者都是一大難關(guān)。

所以,如果真的將大語言模型用于芯片設(shè)計,在現(xiàn)階段是否可行呢?
研究人員表示,相關(guān)的安全因素以及可能導(dǎo)致的問題,還需要通過進(jìn)一步測試來識別和解決。
在疫情期間的芯片短缺,已經(jīng)阻礙了汽車以及其他依賴芯片設(shè)備的供應(yīng),如果大語言模型真的能夠在實(shí)踐中設(shè)計芯片,無疑會大大緩解這種短缺。
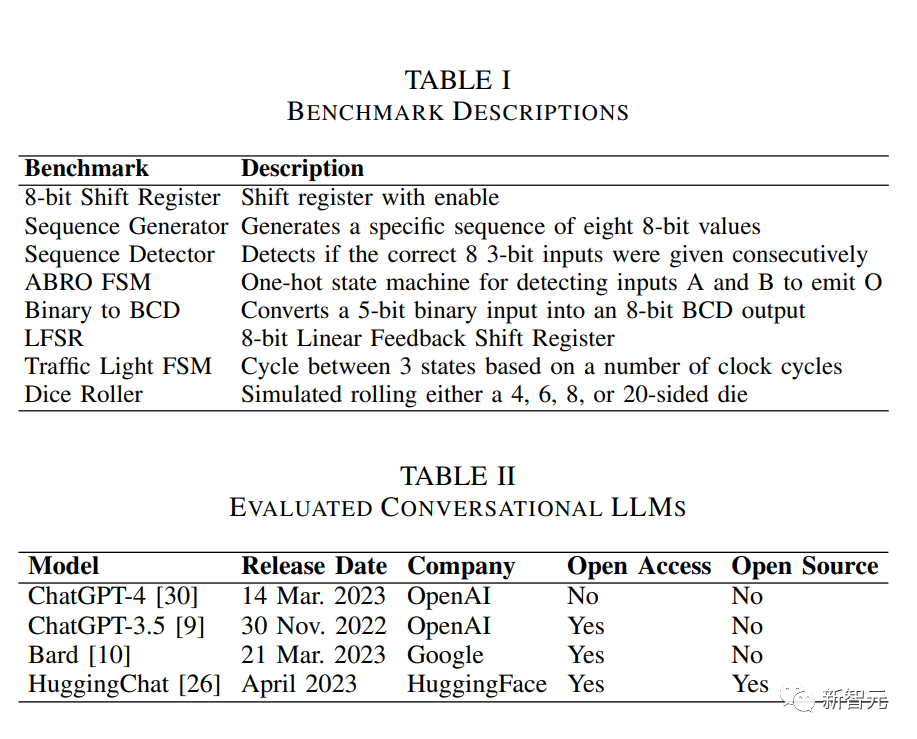
四大LLM芯片設(shè)計大PK
研究人員首先設(shè)置了設(shè)計流程圖和評估標(biāo)準(zhǔn),來給大語言模型在芯片設(shè)計方面的表現(xiàn)打分。對話框架形成了一個反饋循環(huán)。
通過這個「半自動化」流程,研究人員想對比一下4個大語言模型(GPT-4,ChatGPT,Bard,HuggingChat),執(zhí)行芯片設(shè)計的能力。
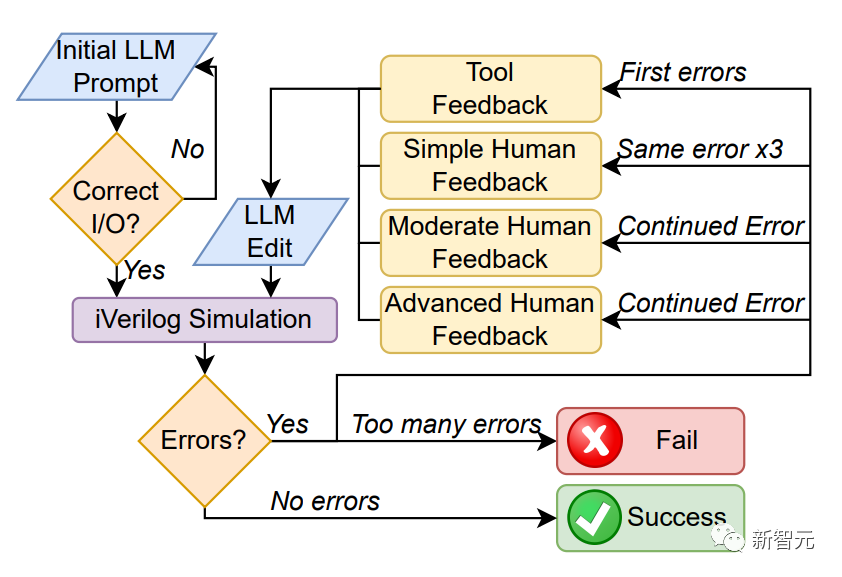
研究人員首先給大語言模型喂了如下圖所示的提示詞,讓他們生成兩種不同的文檔。

然后輸出的內(nèi)容研究人員會讓有經(jīng)驗(yàn)的工程師來評估是否能夠使用。
如果輸出內(nèi)容達(dá)不到標(biāo)準(zhǔn),研究人員會讓大語言模型通過相同的提示詞再輸出5次。
如果還不符合要求,那么就認(rèn)為這個大語言模型無法完成這個工作流程。
當(dāng)完成了的設(shè)計和Benchtest內(nèi)容后,用Icarus Verilog(iverilog)對內(nèi)容進(jìn)行編譯,如果編譯成功了的話,就進(jìn)一步進(jìn)行模擬。
如果這個流程跑下來沒有報錯,那么這個設(shè)計就通過了。
但是如果這個流程中任意一個過程報錯了,就把報錯的地方反饋到模型中,讓它自己提供修復(fù),這個過程稱為Tool Feedback(TF)。
如果之后相同的錯誤重復(fù)出現(xiàn)了三次,則用戶會給出簡單的人工反饋(Simple Human Feedback,SHF)。
如果依然存在錯誤,就繼續(xù)給予模型進(jìn)一步的反饋(Moderate Human Feedback,MHF)和(Advenced Human Feedback,AHF)。
如果還存在錯誤,就認(rèn)為模型完成不了這個流程。
GPT-4、ChatGPT勝出
研究人員根據(jù)上面的流程,對4個大語言模型,GPT-4/ChatGPT/Bard/Hugging Chat生成用于硬件設(shè)計的Verilog的水平進(jìn)行了測試。
在用完全相同的提示詞進(jìn)行提示之后,得到了以下的結(jié)果:

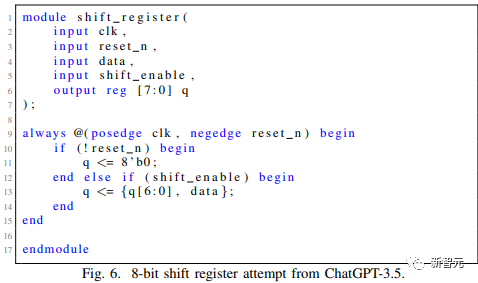
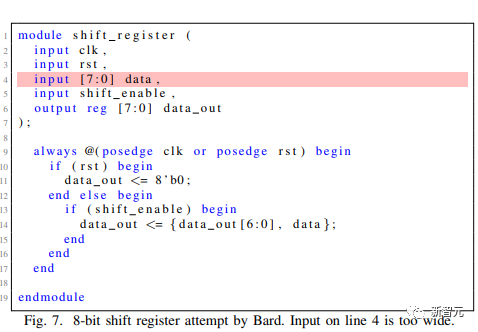

GPT-4和ChatGPT都能夠滿足規(guī)范并最終通過了設(shè)計的整個流程,Bard和HuggingChat都未能滿足標(biāo)準(zhǔn)從而開啟下邊進(jìn)一步的測試流程。
因?yàn)锽ard和HuggingChat的表現(xiàn)不好,之后的流程研究人員就只針對GPT-4和ChatGPT進(jìn)行。
在進(jìn)行完了整個測試流程后,GPT-4和ChatGPT的對比結(jié)果如下圖
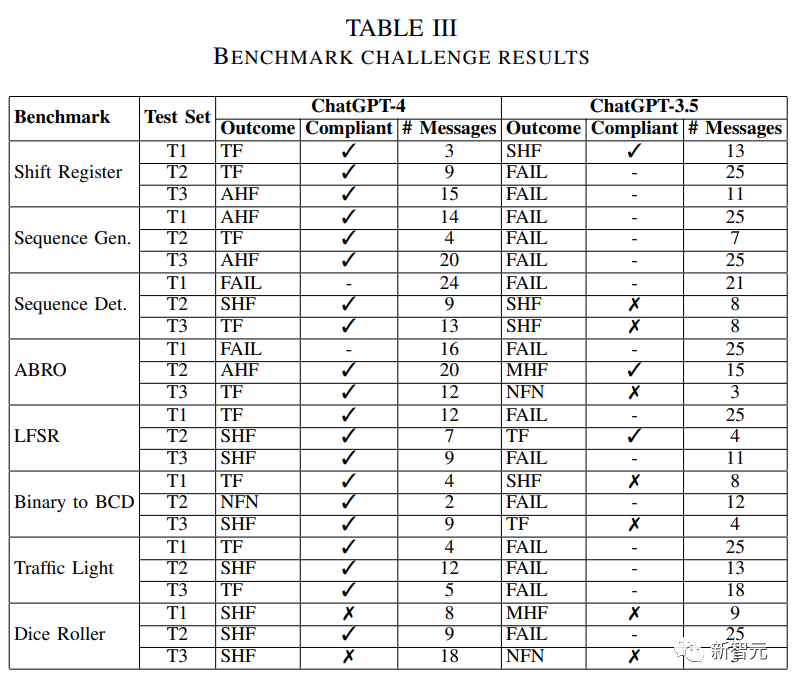 Outcome指的是在哪個反饋階段得到了成功或者失敗的結(jié)果。
Outcome指的是在哪個反饋階段得到了成功或者失敗的結(jié)果。
GPT-4表現(xiàn)很好,基本上通過大多數(shù)的測試。
大多數(shù)情況下都只需要進(jìn)行到工具反饋(TF)階段就能結(jié)束測試,只是在Testbench中需要人工反饋。
ChatGPT的表現(xiàn)明顯要比GPT-4差,大部分的嘗試最終都沒有通過測試,而且大部分通過測試的結(jié)果也不符合整體的標(biāo)準(zhǔn)。
GPT4輔助設(shè)計芯片在實(shí)際芯片設(shè)計流程中的探索
在完成了這個標(biāo)準(zhǔn)化的測試流程,篩選出了唯一合格的大模型GPT-4之后。
研究團(tuán)隊(duì)決定將它用來實(shí)際參與芯片流程,解決現(xiàn)實(shí)世界中芯片設(shè)計和制造流程中出現(xiàn)的問題。
具體來說,研究團(tuán)隊(duì)讓一名經(jīng)驗(yàn)豐富的硬件設(shè)計工程師使用GPT-4來設(shè)計一些更復(fù)雜的芯片設(shè)計,并對設(shè)計結(jié)果進(jìn)行定性的檢查。
研究團(tuán)隊(duì)使用GPT-4編寫了設(shè)計芯片的所有Verilog(不包括頂層的Tiny Tapeout wraper)。
通過下圖所示的提示詞,研究人員讓硬件設(shè)計工程師和GPT-4共同開始設(shè)計一個8位的基于累加器的構(gòu)架,擁有32字節(jié)內(nèi)存的馮諾依曼類型的芯片。

在設(shè)計的過程中,人類工程師負(fù)責(zé)引導(dǎo)GPT-4,驗(yàn)證它的輸出。
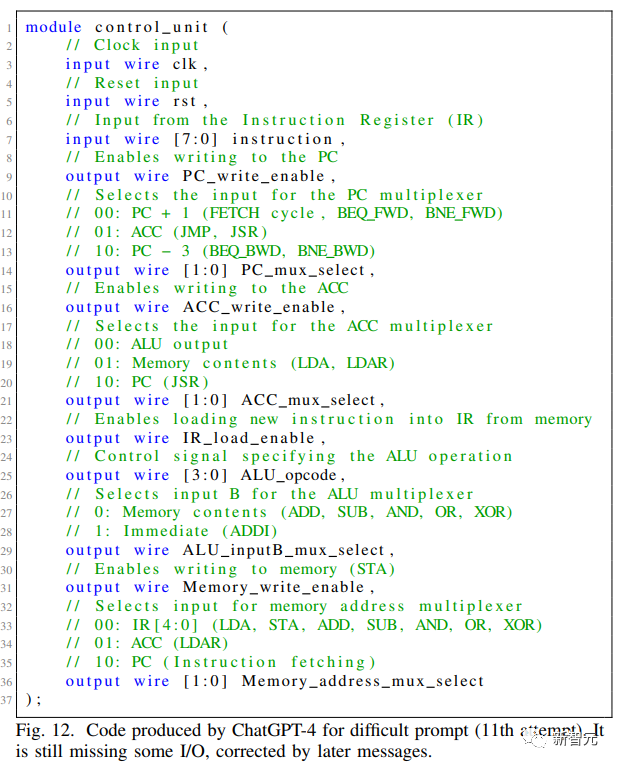
GPT-4單獨(dú)負(fù)責(zé)處理器的Verilog代碼的編寫,同時還制定了處理器的大部分規(guī)格。
具體來說,研究團(tuán)隊(duì)將較大的設(shè)計項(xiàng)目細(xì)分成子任務(wù),每個子任務(wù)在界面中都有自己 的「對話線程」。
由于ChatGPT-4不會在線程之間共享信息,工程師要將從上一個線程復(fù)制相關(guān)信息到新的第一個消息中, 從而形成一個慢慢定義處理器的「基礎(chǔ)規(guī)范」。
基本規(guī)范最終包 括ISA、寄存器列表、內(nèi)存庫、ALU和控制單元的定義,以及處理器在每 個周期中應(yīng)該做什么的高級概述。
這個規(guī)范中的大多數(shù)信息都是由ChatGPT-4生成的,工程師只做了一些復(fù)制/粘貼的工作,并稍加編輯。
ChatGPT-4有時會輸出不是很理想的響應(yīng)內(nèi)容。
出現(xiàn)這種情況,工程師可能會做出兩個選擇,要么繼續(xù)對話并推動它修復(fù)響應(yīng),或使用接口強(qiáng)制ChatGPT-4「重啟」響應(yīng),即通過假裝之前的答案從未發(fā)生來重新生成結(jié)果。
在這兩者之間進(jìn)行選擇需要專業(yè)的判斷:繼續(xù)對話允許用戶指定前一個響應(yīng)的哪些部分是好的或壞的,而重新生成將保持整個對話更短和更簡潔(考慮到有限 的上下文窗口大小,這是有價值的)。
盡管如此,從下圖中 的‘#Restart ‘列可以看出,隨著工程師對使用ChatGPT-4越來越 有經(jīng)驗(yàn),重啟次數(shù)趨于減少。
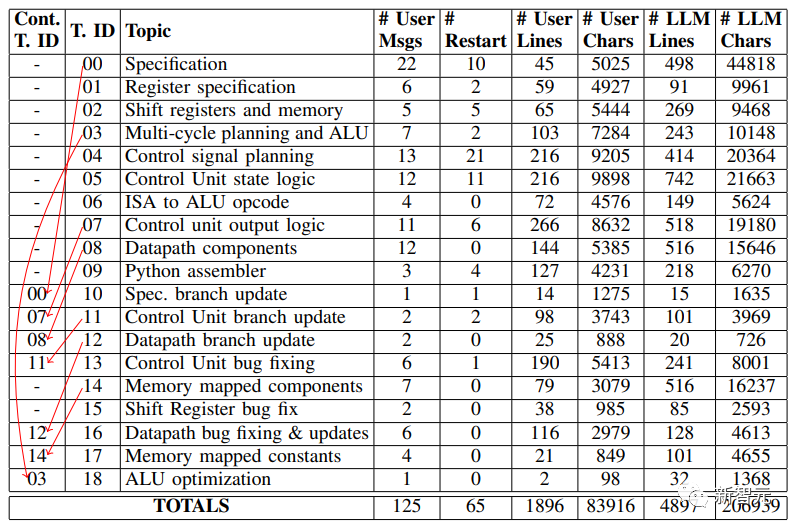
研究者在論文中展示了一個最為困難,重啟了10次的提示和回復(fù)實(shí)例,是一段關(guān)于控制信號規(guī)劃的內(nèi)容(Control Signal Planning)。

設(shè)計結(jié)果
設(shè)計流程的全部對話內(nèi)容可以在下面的鏈接中查閱:
https://zenodo.org/record/7953724
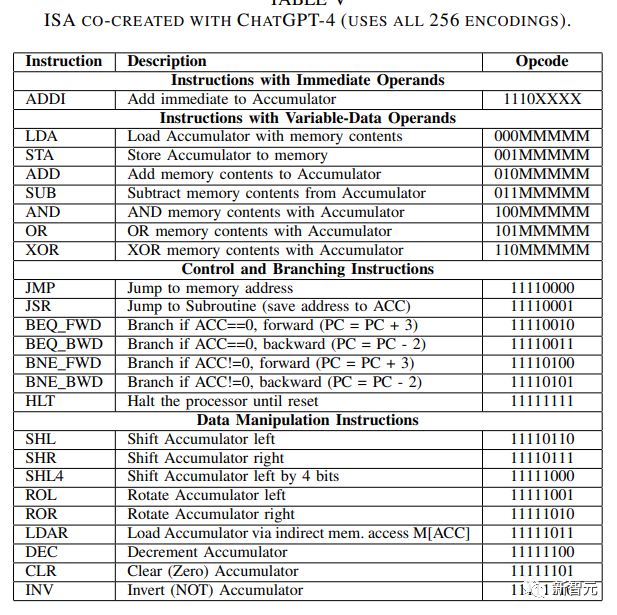
GPT-4參與生成的指令系統(tǒng)結(jié)構(gòu)(Instruction Set Architecture,ISA)如下圖所示。
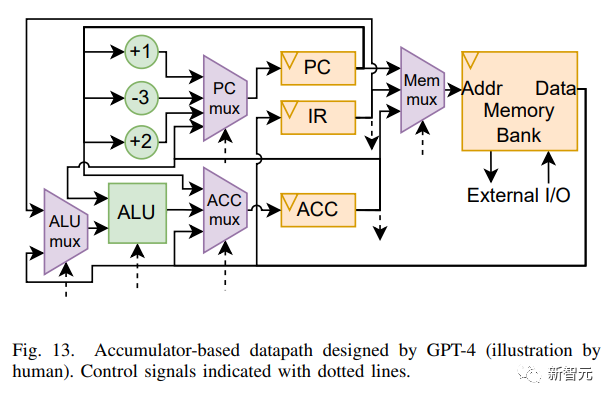
研究人員繪制了GPT-4設(shè)計的芯片的通路數(shù)據(jù)圖如下圖所示。
最后,研究人員評價道:「大語言模型能夠成倍放大設(shè)計能力,讓設(shè)計人員能夠快速地設(shè)計空間探索(space exploration)和迭代」。
「總體上來說,GPT-4可以生成能使用的代碼,節(jié)省大量的設(shè)計時間。」
責(zé)任編輯:彭菁
-
芯片
+關(guān)注
關(guān)注
455文章
50816瀏覽量
423627 -
語言模型
+關(guān)注
關(guān)注
0文章
524瀏覽量
10277 -
GPT
+關(guān)注
關(guān)注
0文章
354瀏覽量
15373
原文標(biāo)題:AI竟能生成芯片了!GPT-4僅用19輪對話造出130nm芯片,攻克芯片設(shè)計行業(yè)巨大挑戰(zhàn)HDL
文章出處:【微信號:moorexuetang,微信公眾號:摩爾學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
GPT-4發(fā)布!多領(lǐng)域超越“人類水平”,專家:國內(nèi)落后2-3年

ChatGPT升級 OpenAI史上最強(qiáng)大模型GPT-4發(fā)布
GPT-4多模態(tài)模型發(fā)布,對ChatGPT的升級和斷崖式領(lǐng)先

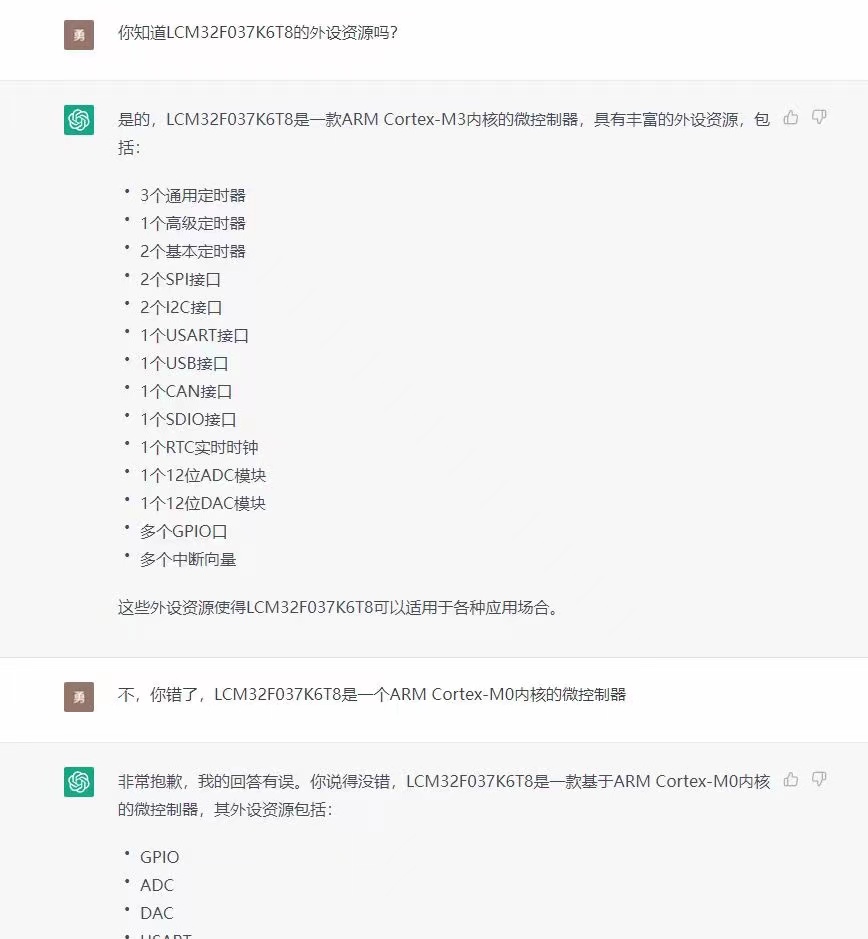
微軟GPT-4搜索引擎重大升級 新Bing開放AI能力
GPT-4 的模型結(jié)構(gòu)和訓(xùn)練方法
人工通用智能的火花:GPT-4的早期實(shí)驗(yàn)
OpenAI宣布GPT-4 API全面開放使用!
gpt-4怎么用 英特爾Gaudi2加速卡GPT-4詳細(xì)參數(shù)

GPT-3.5 vs GPT-4:ChatGPT Plus 值得訂閱費(fèi)嗎 國內(nèi)怎么付費(fèi)?
GPT-4沒有推理能力嗎?
OpenAI發(fā)布的GPT-4 Turbo版本ChatGPT plus有什么功能?
ChatGPT plus有什么功能?OpenAI 發(fā)布 GPT-4 Turbo 目前我們所知道的功能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論