 Sparse4D系列算法:邁向長時序稀疏化3D目標檢測的新實踐
Sparse4D系列算法:邁向長時序稀疏化3D目標檢測的新實踐
在自動駕駛視覺感知系統中,為了獲得環繞車輛范圍的感知結果,通常需要融合多攝像頭的感知結果。比較早期的感知架構中,通常采用后融合的范式,即先獲得每個攝像頭的感知結果,再進行結果層面的融合。后融合范式主要的問題在于難以處理跨攝像頭的目標(如大卡車),同時后處理的負擔也比較大。而目前更加主流的感知架構則是選擇在特征層面進行多攝像頭融合。其中比較有代表性的路線就是這兩年很火的BEV方法,繼Tesla Open AI Day公布其BEV感知算法之后,相關研究層出不窮,感知效果取得了顯著提升,BEV也幾乎成為了多傳感器特征融合的代名詞。但是,隨著大家對BEV研究和部署的深入,BEV范式也逐漸暴露出來了一些缺陷:
?感知范圍、感知精度、計算效率難平衡:從圖像空間到BEV空間的轉換,是稠密特征到稠密特征的重新排列組合,計算量比較大,與圖像尺寸以及BEV 特征圖尺寸成正相關。在大家常用的nuScenes 數據中,感知范圍通常是長寬 [-50m, +50m] 的方形區域,然而在實際場景中,我們通常需要達到單向100m,甚至200m的感知距離。若要保持BEV Grid 的分辨率不變,則需要大大增加BEV 特征圖的尺寸,從而使得端上計算負擔和帶寬負擔都過重;若保持BEV特征圖的尺寸不變,則需要使用更粗的BEV Grid,感知精度就會下降。因此,在車端有限的算力條件下,BEV 方案通常難以實現遠距離感知和高分辨率特征的平衡;
?無法直接完成圖像域的2D感知任務:BEV 空間可以看作是壓縮了高度信息的3D空間,這使得BEV范式的方法難以直接完成2D相關的任務,如標志牌和紅綠燈檢測等,感知系統中仍然要保留圖像域的感知模型。
實際上,我們感興趣的目標(如動態目標和車道線)在空間中的分布通常很稀疏,BEV范式中有大量的計算都被浪費了。因此,基于BEV的稠密融合算法或許并不是最優的多攝融合感知框架。同時特征級的多攝融合也并不等價于BEV。這兩年,PETR系列(PETR, PETR-v2, StreamPETR) 也取得了卓越的性能,并且其輸出空間是稀疏的。在PETR系列方法中,對于每個instance feature,采用global cross attention來實現多視角的特征融合。由于融合模塊計算復雜度仍與特征圖尺寸相關,因此其仍然屬于稠密算法的范疇,對高分辨率的圖像特征輸入不夠友好。
因此,我們希望實現一個高性能高效率的長時序純稀疏融合感知算法,一方面能加速2D->3D 的轉換效率,另外一方面在圖像空間直接捕獲目標跨攝像頭的關聯關系更加容易,因為在2D->BEV的環節不可避免存在大量信息丟失。這條技術路線代表性的方法是基于deformable attention 的DETR3D算法。然而從開源數據集指標來看,DETR3D的性能距離其他稠密類型的算法存在較大差距。為了Make 純稀疏感知 Great Again,我們提出了Sparse4D及其進化版本Sparse4D v2,從Query構建方式、特征采樣方式、特征融合方式、時序融合方式等多個方面提升了模型的效果。當前,Sparse4D v2 在nuScenes detection 3D排行榜來看,達到了SOTA的效果,超越了包括SOLOFusion、BEVFormer v2和StreamPETR在內的一眾最新方法,并且在推理效率上也具備顯著優勢。本文主要介紹了Sparse4D 和 Sparse4D v2 方案的細節實踐。
Sparse4D:純稀疏感知方案的全面改進
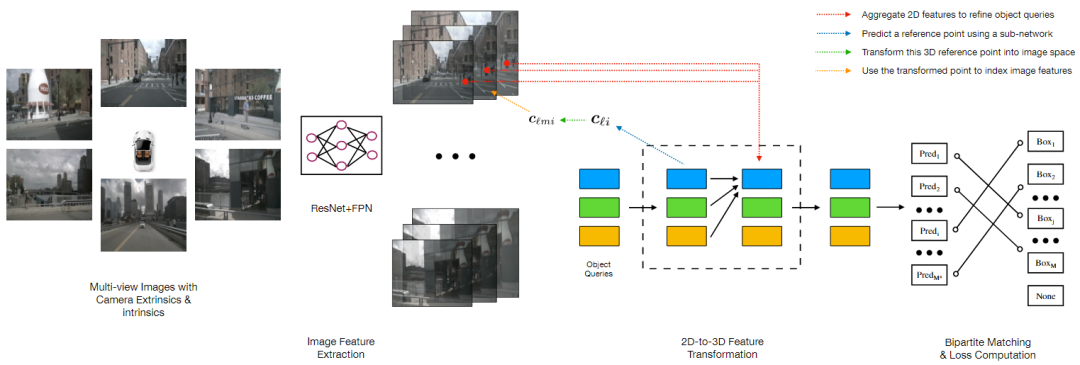
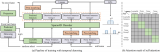
圖1DETR3D 算法框架圖
首先,我們先簡單回顧一下DETR3D算法(圖1)。DETR3D 算法可以概括為如下幾個步驟:
1. 多尺度特征提取:對于多攝像頭圖像,采用ResNet + FPN 提取圖像的多尺度特征
2. Query 初始化:初始化若干Object Queries(以特征編碼的形式)
3.Query 特征更新:基于Query 特征,采用一個MLP Decoder 獲得其對應的3D 空間參考點坐標,將這個點通過相機內外參投影到圖像平面上,并采樣多尺度特征,最后融合這些采樣特征來更新Query 特征
4. 預測與loss:基于多輪更新后的Query 特征,預測每個Query 對應的bounding box,并通過Bipartite 匹配的方式與真值進行匹配并計算損失函數
DETR3D 搭建了純稀疏感知的基本框架,即稀疏Query + 稀疏特征采樣的范式,但存在一些不足:
? 每個Query 僅對應一個Reference Point,不能夠有效采樣目標的特征,特別對于較大的目標
?從Learnable Query 來decode 獲得Reference Point 的方式,并不能非常有效的定位roi 區域,且會存在退化解,多模式等諸多的問題。這個問題在Anchor-DETR和 DAB-DETR等方法中都有過討論
?不支持對于時序信息的融合
由于上述的這些原因,DETR3D 網絡整體的學習能力偏弱,指標在當前顯著弱于BEV 范式的方法。在Sparse4D-v1 中,我們主要通過instance 構建方式,特征采樣、特征融合和時序融合等方面改進了現有的框架。
Sparse4D 算法框架
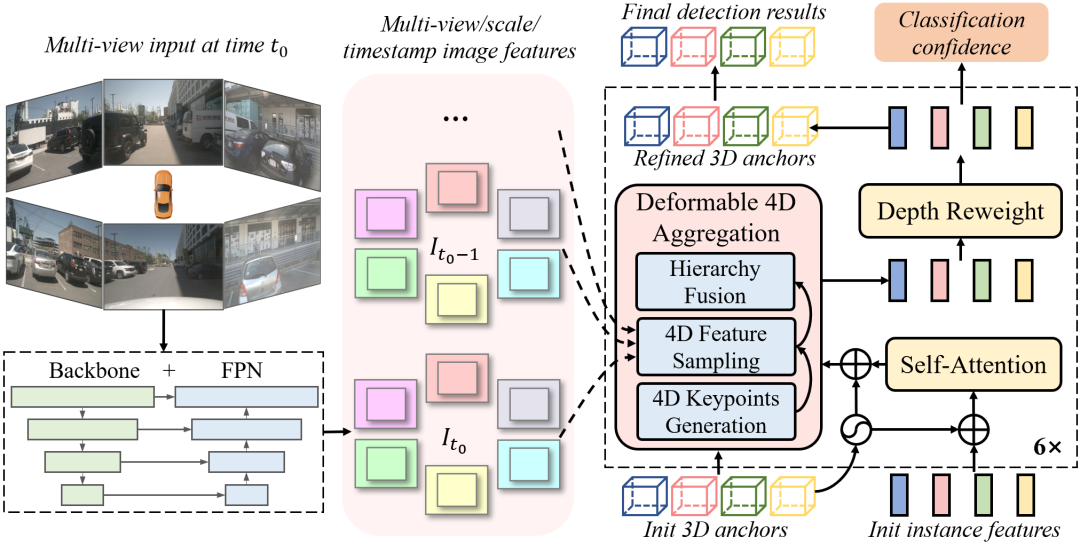
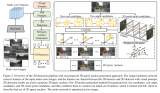
圖2 Sparse4D算法框架
如圖2所示,Sparse4D 也采用了Encoder-Decoder 結構。其中Encoder包括image backbone和neck,用于對多視角圖像進行特征提取,得到多視角多尺度特征圖。同時,我們會cache 多歷史幀的圖像特征,用于在decoder 中提取時序特征;Decoder為多層級聯形式,輸入時序多尺度圖像特征圖和初始化instance,輸出精細化后的instance,每層decoder包含self-attention、deformable aggregation和refine module三個主要部分。
學習2D檢測領域DETR改進的經驗,我們也重新引入了Anchor的使用,并將待感知的目標定義為instance,每個instance主要由兩個部分構成:
1. Instance feature:目標的高維特征,在decoder 中不斷由來自于圖像特征的采樣特征所更新;
2. 3D Anchor:目標結構化的狀態信息,比如3D檢測中的目標3D框(x, y, z, w, l, h, yaw, vx, vy);我們通過kmeans 算法來對anchor 的中心點分布進行初始化;同時,在網絡中我們會基于一個MLP網絡來對anchor的結構化狀態進行高維空間映射得到 Anchor Embed ,并與instance feature 相融合。
基于以上定義,我們可以初始化一系列instance,經過每一層decoder都會對instance 進行調整,包括instance feature的更新,和anchor的refine。基于每個instance 最終預測的bounding box,Sparse4D 中同樣通過Bipartite 匹配的方式與真值進行匹配并計算損失函數。
Deformable 4D Aggregation 模塊
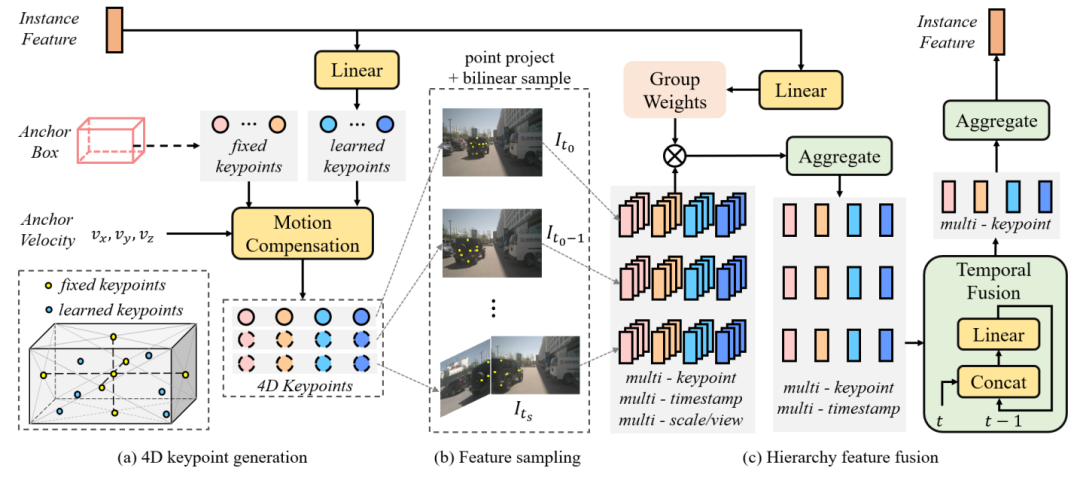
圖3 deformable aggregation結構圖
在Sparse4D 的decoder 中,最重要的是Deformable 4D Aggreagation 模塊。這個模塊主要負責instance 與時序圖像特征之間的交互,如圖3所示,主要包括三個步驟:
1. 4D 關鍵點生成
首先,基于每個instance 的3D anchor信息, 我們可以生成一系列3D關鍵點,分為固定關鍵點和可學習關鍵點。我們將固定關鍵點設置為anchor box的各面中心點及其立體中心點,可學習關鍵點坐標通過instance feature接一層全連接網絡得到。在Sparse4D 中,我們采用了7個固定關鍵點 + 6個可學習關鍵點的配置。
然后,我們結合instance 自身的速度信息以及自車的速度信息,對這些3D關鍵點進行運動補償,獲得其在歷史時刻中的位置。結合當前幀和歷史幀的3D關鍵點,我們獲得了每個instance 的4D 關鍵點。
2. 4D 特征采樣
在獲得每個instance 在當前幀和歷史幀的3D關鍵點后,我們根據相機的內外參將其投影到對應的多視角多尺度特征圖上進行雙線性插值采樣。從而得到Multi-Keypoint,Multi-Timestamp, Multi-Scale, Multi-View 的特征表示。
3. 層級化特征融合
在采樣得到多層級的特征表示后,需要進行層級化的特征融合,我們分為了三層:
?Fuse Multi-Scale/View:對于一個關鍵點在不同特征尺度和視角上的投影,我們采用了加權求和的方式,權重系數通過將instance feature和anchor embed輸入至全連接網絡中得到
?Fuse Multi-Timestamp:對于時序特征,我們采用了簡單的recurrent策略(concat + linear)來融合
?Fuse Multi-Keypoint:最后,我們采用求和的方式融合同一個instance 不同keypoint 的特征
實驗驗證
我們在nuScenes 數據集上對Sparse4D 方法展開了很多實驗驗證,這里列舉幾個主要的實驗。
1. 運動補償:Sparse4D針對自車運動和instance運動都進行了補償。目前,大多數算法僅顯式考慮了自車運動。我們通過實驗分析了運動補償的作用,如表1所示。對于NDS指標來說,自車運動和他車運動分別帶來了6.4%和0.7%的提升,他車運動補償對檢測精度無提升,但是對速度估計精度的提升非常顯著(mAVE從0.398降低至0.329)。
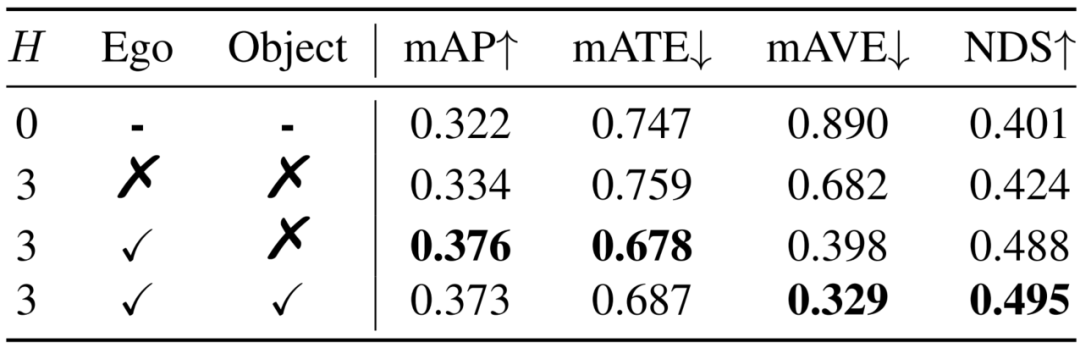
表1 運動補償的影響
2. 多層次特征融合:在deformable aggregation中,我們需要對多尺度、多視角和多關鍵點的特征進行融合。為了分析各個層級融合的重要程度,我們分別將各層的加權方式改為直接求和,可以看到多尺度的影響小于多視角,而多關鍵點的融合最為重要。此外,將三個層級的融合全部改為求和的形式,模型將難以收斂,指標也會顯著降低。
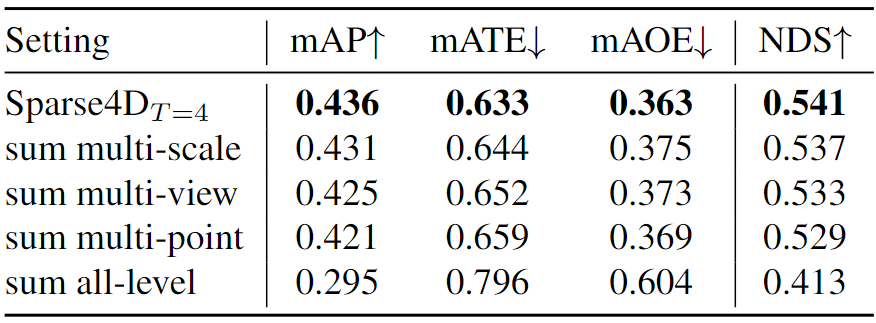
表2 多層級融合的影響
3. 采樣時序融合幀數:Spase4D v1中,采用多幀采樣的方式實現時序融合,其中采樣幀數對感知性能的影響顯著。我們將幀數從0逐步增加至10,感知性能一直在穩步提升,說明長時序融合對檢測性能有很大幫助。但是由于顯存限制,我們僅驗證到了10幀。
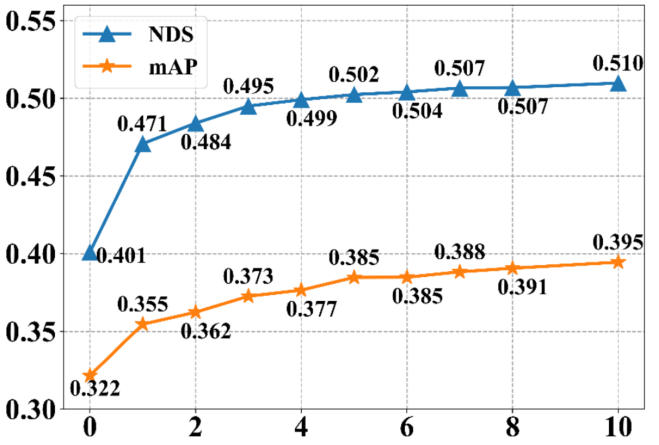
表3采樣時序融合幀數影響
4. 效率與指標分析:如下表所示,在單幀配置下,我們的方法速度與DETR3D持平,且指標顯著優于DETR3D。但在時序配置下,Sparse4D的效率出現了顯著的下降。這是因為對于每一幀的檢測,我們都需要進行當前幀和歷史多幀的特征采樣和特征融合。這里包含了很多冗余的計算,使得多幀效率顯著低于單幀效率。針對這個問題,我們在最近對時序策略進行了優化,提出了Sparse4D-v2 方案,使得其時序推理效率和單幀推理基本一致。
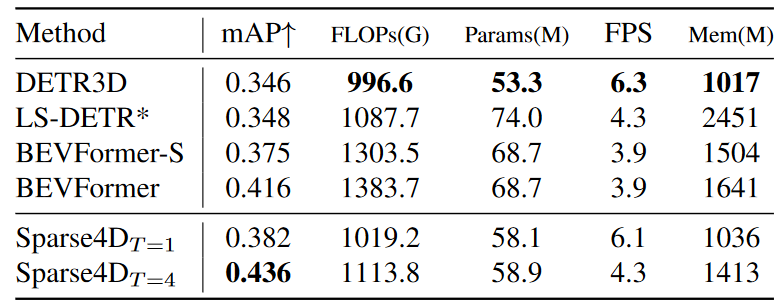
表4在Resnet101 backbone + 900x1600 輸入分辨率配置下的效率對比
Sparse4D-v2:Recurrent 時序方案 & 進一步效率優化
為了避免多幀采樣,進而提升時序特征融合的效率,我們在Sparse4D v2中采用了recurrent的方式來實現時序信息的傳遞。具體而言,如下圖所示,Sparse4D v2中以instance作為時序信息傳遞的媒介。此外,我們還提出了更高效的Deformable Aggregation 模塊,并引入了輔助訓練loss。
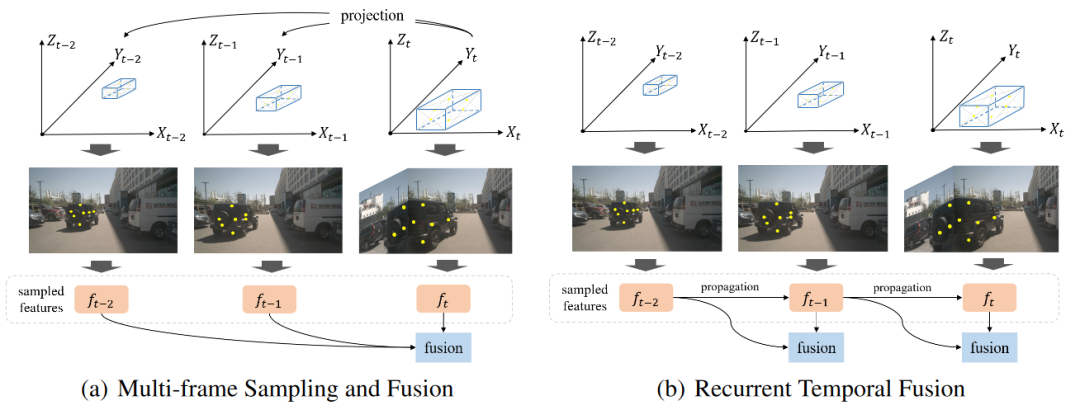
基于稀疏實例的Recurrent 時序方案
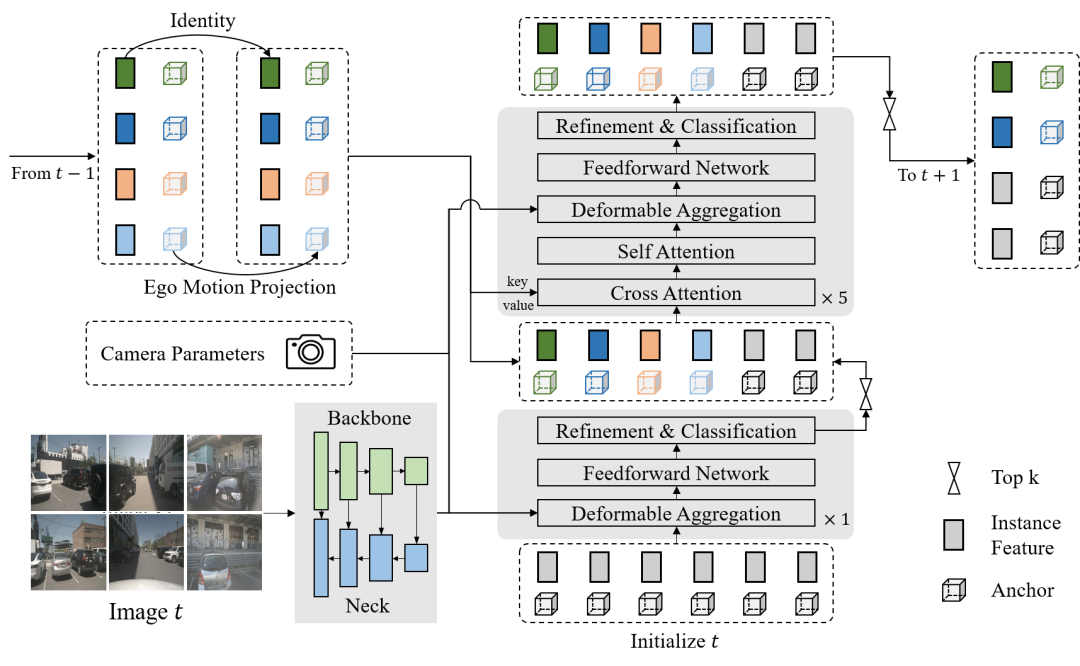
Sparse4D v2算法框架
在Sparse4D-v2中,我們將decoder分為單幀層和時序層。單幀層以新初始化的instance作為輸入,輸出一部分高置信度的instance至時序層;時序層的instance除了來自于單幀層的輸出以外,還來自于歷史幀(上一幀)。我們將歷史幀的instance投影至當前幀,其中,instance feature保持不變,anchor box通過自車運動和目標速度投影至當前幀,anchor embed通過對投影后的anchor進行編碼得到,如公式1。
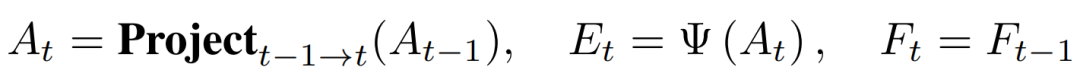
公式1 instance時序轉換
其中投影公式與anchor定義相關,對于3D 檢測任務,我們使用的投影公式如公式2。
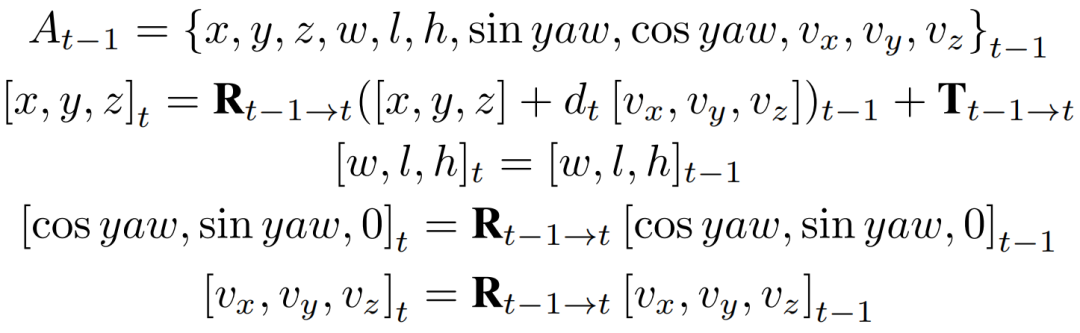
公式2 anchor 3D box時序投影
近期效果很好的方法StreamPETR也采用了稀疏的Recurrent 時序框架,Sparse4D v2與其的區別主要在于:
? Instance 表示方式:PETR系列中,query instance 采用的是 “Anchor Point -> Query 特征”的方式。即將均勻分布在3D 空間中的anchor point(learnable)用MLP編碼成Query 特征。比起Sparse4D instance 中顯式分離feature (紋理語義信息) 和3D anchor(幾何運動信息) 的方式,PETR的instance 表示方式更加隱式一些。我們認為feature + anchor box的顯式instance表示方式,在稀疏3D檢測任務中更加簡潔有效,也更易于訓練;
? 時序轉換方式:與instance 表示方法相對應的是稀疏Reccurent 的方式。StreamPETR 中,采用了隱式的query時序轉換方式,即把velocity、ego pose、timestamp都編碼成特征,然后再和query feature做一些乘加操作;Sparse4d-V2 則采用了顯式的時序轉換方式,對于歷史幀的instance,直接將其3D anchor基于自車和instance 運動投影到當前幀,而保持其instance feature不變;
?歷史幀數量:StreamPETR 中 cache了歷史N幀的query,再與當前幀進行attention。Sparse4d-v2 則只cache了上一幀的query。當然,StreamPETR 也可以只cache 一幀,只是效果會略有下降。在實際的業務實踐中,較少的歷史幀cache 有助于減少端上的帶寬占用,進一步提升系統整體性能。
Efficient Deformable Aggregation
此外,在Sparse4D v2中,我們還對deformable aggregation模塊進行了底層的分析和優化,讓其并行計算效率顯著提升,顯存占用大幅降低。基于pytorch op組合的Basic Deformable Aggregation 計算邏輯實現如下圖所示:

Basic Deformable Aggregation
可以發現其會生成多個中間變量,需要對顯存進行多次訪問和存儲,降低了推理速度,且中間變量尺寸較大,從而導致顯存占用量顯著增加,并且反向傳播過程中的顯存消耗會進一步提升。
為了提升該op的計算效率,降低顯存占用,我們將上述實現中的雙線性特征插值和加權求和融合為一個op,如下圖所示,我們稱之為Efficient Deformable Aggregation(EDA)。EDA的關鍵在于將“先采樣所有特征再融合”的方式變成了“并行地邊采樣邊融合”,其允許在關鍵點維度和特征維度上實現完全的并行化,每個線程的計算復雜度僅與相機數量和特征尺度數量相關:。此外,在某些場景中,3D空間中的一個點最多被投影到兩個視圖,使得計算復雜度可以進一步降低至。EDA可以作為一種基礎性的算子操作,可以適用于需要多圖像和多尺度融合的各種應用。
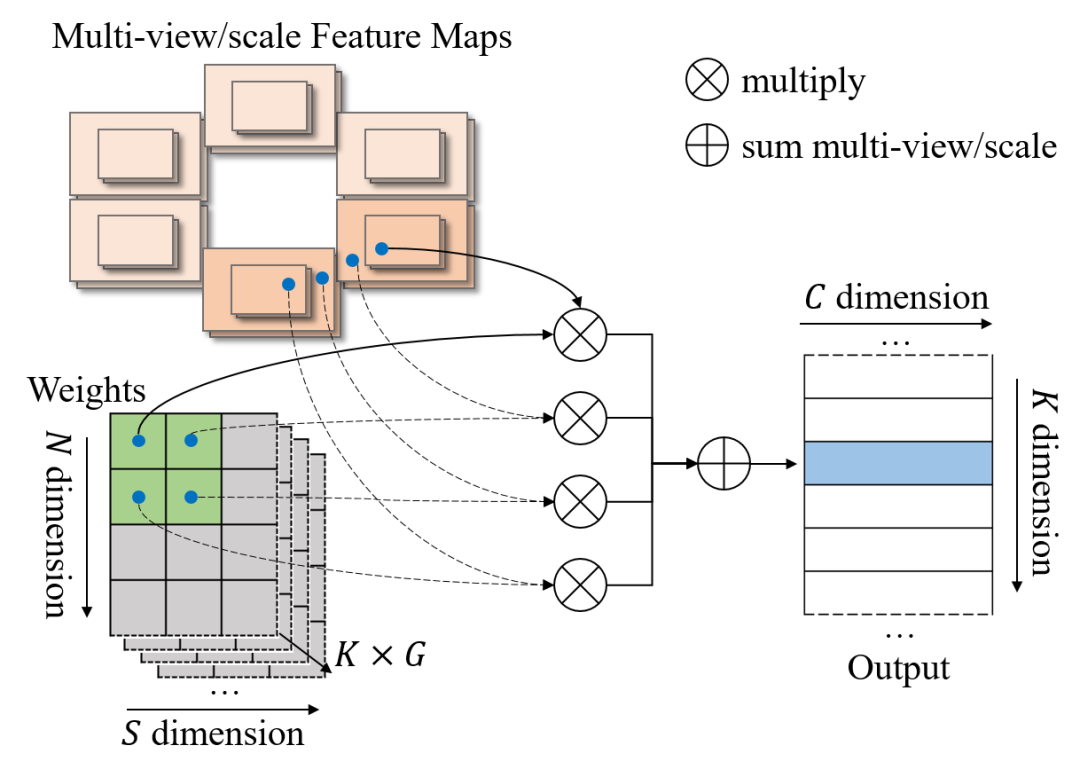
Efficient Deformable Aggregation
我們在3090上對EDA模塊進行了性能測試。EDA對顯存占用和推理速度都有很大的優化效果。加上EDA之后,Sparse4Dv2在nuScenes單次實驗訓練時間只需要14.5小時(8 GPUs),推理速度可達20.3FPS,且batch size=1時訓練顯存僅為3100M。

EDA性能分析,image size為256X704,backbone為resnet50,訓練epoch數為100
相機編碼的加入 & 輔助訓練任務
為了提高模型對相機內外參泛化性,我們在Sparse4D v2中加入了內外參的編碼,將相機投影矩陣通過全連接網絡映射到高維特征空間得到camera embed。在計算deformable aggregation中的attention weights 時,我們不僅考慮instance feature和anchor embed,還加上了camera embed。
在實驗中,我們發現基于稀疏的方法在早期訓練階段缺乏足夠的收斂能力和速度。為了緩解這一問題,我們還引入了以點云為監督的多尺度密集深度估計方法作為輔助訓練任務。而在推理過程中,這個分支網絡將不會被激活,不影響推理效率。
實驗驗證
1. Ablation Study
我們首先基于Resnet50 + 256x704 分辨率的配置展開了消融實驗。如下表所示:
?對比Exp1 和Exp5可以看出,采用recurrent instance的形式來實現長時序融合,相比單幀提升非常大;
?對比Exp4 和Exp5可以看出,深度監督模塊,有效降低了Sparse4D-V2的收斂難度,如果去掉該模塊,模型訓練過程會出現梯度崩潰的現象,從而使得mAP降低了8.5%。(在不具備深度監督條件的情況下,也可以考慮使用2D 的檢測head 作為輔助loss,如FCOS Head,YoloX等);
?對比Exp2 和Exp3可以看出,單幀層 + 時序層的組合方式比起只使用時序層的效果要好很多;
?對比Exp3 和Exp5可以看出,相機參數編碼也帶來了可觀的提升,mAP和NDSf分別提升了2.0%和1.5%。
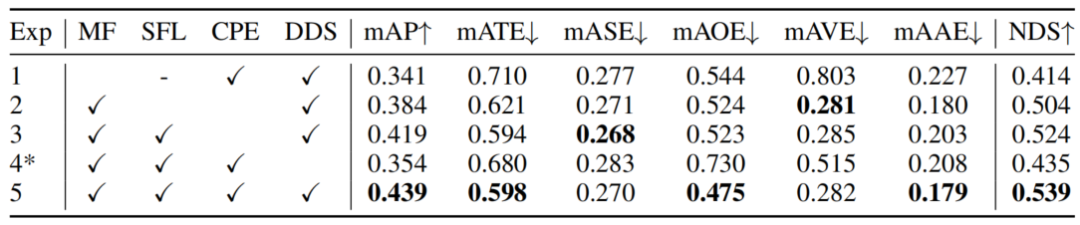
Sparse4D v2消融實驗:MF(Multi-Frame), SFL(Single-Frame Layer), CPE(Camera Parameter Encoding), DDS(Dense Depth Supervision)
此外,Exp1 (單幀)在3090 上的推理速度為21.0 FPS,Exp5(時序)的推理速度則為20.3 FPS。可以看出,在recurrent 時序融合框架下,其推理速度和單幀推理基本一致,增加了少量歷史instance 映射的耗時。
2. Compare with SOTA
我們先在nuScenes validation數據集上進行了對比,可以無論是在低分辨率+ResNet50還是高分辨率+ResNet101的配置下,Sparse4D v2都取得了SOTA的指標,超過了SOLOFusion、VideoBEV和StreamPETR等算法。
從推理速度來看,在256X704的圖像分辨率下,Sparse4Dv2超過了LSS-Based算法BEVPoolv2,但是低于StreamPETR。但是當圖像分辨率提升至512X1408,Sparse4Dv2的推理速度會反超StreamPETR。這主要是因為在低分辨率下直接做global attention的代價較低,但隨著特征圖尺寸的上升其效率顯著下降。而Sparse4D head理論計算量則和特征圖尺寸無關,這也展示了純稀疏范式算法在效率上的優勢。實際測定中,當圖像分辨率從256x704 提升到512x1408時,Sparse4Dv2 的decoder 部分耗時僅增加15%(從高分辨率特征上進行grid sample,會比從低分辨率特征上進行grid sample 略慢一點)。
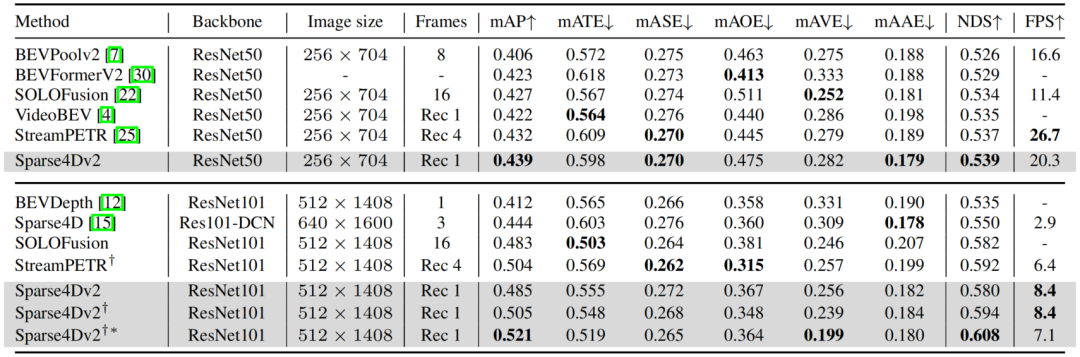
nuScenes validtion dataset指標對比,“Rec N”表示recurrent融合算法中cache時序特征幀數為“N”,倒數第二行和第四行的上標表示采用了nuImage Pretrain 的backbone
在nuScenes test數據集上,Sparse4Dv2同樣獲得了SOTA的指標,超過了所有BEV-based算法,同時也比目前SOTA的StreamPETR高0.2NDS。
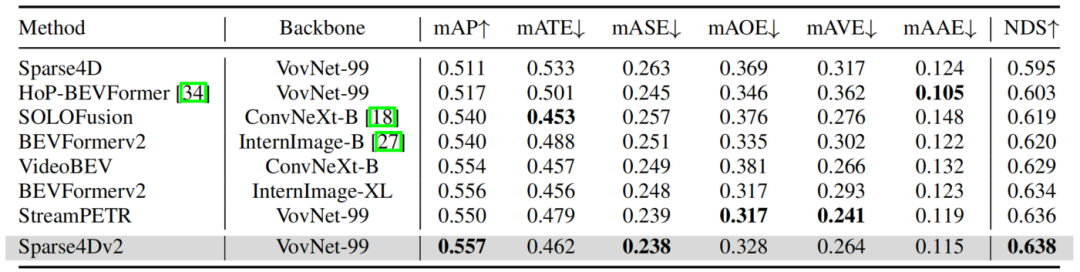
nuScenes test dataset指標對比
總結與展望
總的來說,在長時序稀疏化3D 目標檢測的一路探索中,我們主要有如下的收獲:
1. 顯式的稀疏實例表示方式:將待檢測的instance 表示為3D anchor 和 instance feature,并不斷進行迭代更新來獲得檢測結果是一種簡潔、有效的方式。同時,這種方式也更容易進行時序的運動補償;
2. 高效的Deformable Aggregation 算子:我們提出了針對多視角/多尺度圖像特征 + 多關鍵點的層級化特征采樣與融合策略,并進行了大幅的效率優化,使我們能高效獲得高質量的特征表示。同時在稀疏化的形式下,decoder 部分的計算量和計算延時受輸入圖像分辨率的影響不大,能更好處理高分辨率輸入;
3. Recurrent 的時序稀疏融合框架:基于稀疏實例的時序recurrent 融合框架,使得時序模型基本上具備與單幀模型相同的推理速度,同時在幀間只需要占用少量的帶寬(比起bev 的時序方案)。這樣輕量且有效的時序方案很適合在真實的車端場景處理多攝視頻流數據。
基于稀疏范式的感知算法仍然有很多未解決的問題,也具有很大的發展空間。首先,如何將Sparse的框架應用到更廣泛的感知任務上是下一步需要探索的,例如道路元素的感知任務(HD map construction、 topology等)、預測規控任務(trajectory prediction、end-to-end planning等);其次,我們需要對稀疏感知算法進行更充足的驗證,保證其具備量產能力,例如遠距離檢測效果、相機內外參泛化能力及多模態融合感知性能等。我們希望Sparse4D(v2)可以作為稀疏感知方向新的baseline,推動該領域的進步。
審核編輯:湯梓紅
-
算法
+關注
關注
23文章
4622瀏覽量
93077 -
目標檢測
+關注
關注
0文章
209瀏覽量
15638 -
自動駕駛
+關注
關注
784文章
13877瀏覽量
166631
原文標題:開發者說 | Sparse4D系列算法:邁向長時序稀疏化3D目標檢測的新實踐
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
芯片的3D化歷程
基于ToF的3D活體檢測算法研究
浩辰3D的「3D打印」你會用嗎?3D打印教程
3D分組密碼算法
大疆、港科大聯手!雙目3D目標檢測實驗效果大放送

谷歌開發pipeline,在移動設備上可實時計算3D目標檢測
3D的感知技術及實踐


CCV 2023 | SparseBEV:高性能、全稀疏的純視覺3D目標檢測器

如何搞定自動駕駛3D目標檢測!

地平線正式開源Sparse4D算法
Sparse4D-v3:稀疏感知的性能優化及端到端拓展
Nullmax提出多相機3D目標檢測新方法QAF2D





 工商網監
工商網監
評論