 650億參數,8塊GPU就能全參數微調!邱錫鵬團隊把大模型門檻打下來了!
650億參數,8塊GPU就能全參數微調!邱錫鵬團隊把大模型門檻打下來了!
全參數微調的顯存使用量和推理一樣多,大模型不再只是大型科技公司的玩具了。
在大模型方向上,科技巨頭在訓更大的模型,學界則在想辦法搞優化。最近,優化算力的方法又上升到了新的高度。
大型語言模型(LLM)徹底改變了自然語言處理(NLP)領域,展示了涌現、頓悟等非凡能力。然而,若想構建出具備一定通用能力的模型,就需要數十億參數,這大幅提高了 NLP 研究的門檻。在 LLM 模型調優過程中通常又需要昂貴的 GPU 資源,例如 8×80GB 的 GPU 設備,這使得小型實驗室和公司很難參與這一領域的研究。
最近,人們正在研究參數高效的微調技術(PEFT),例如 LoRA 和 Prefix-tuning,為利用有限資源對 LLM 進行調優提供了解決方案。然而,這些方法并沒有為全參數微調提供實用的解決方案,而全參數微調已被公認為是比參數高效微調更強大的方法。
在上周復旦大學邱錫鵬團隊提交的論文《Full Parameter Fine-tuning for Large Language Models with Limited Resources》中,研究人員提出了一種新的優化器 LOw-Memory Optimization(LOMO)。
通過將 LOMO 與現有的內存節省技術集成,與標準方法(DeepSpeed 解決方案)相比,新方法將內存使用量減少到了之前的 10.8%。因此,新方法能夠在一臺具有 8×RTX 3090 的機器上對 65B 模型進行全參數微調,每個 RTX 3090 具有 24GB 內存。

論文鏈接:https://arxiv.org/abs/2306.09782
在該工作中,作者分析了 LLM 中內存使用的四個方面:激活、優化器狀態、梯度張量和參數,并對訓練過程進行了三方面的優化:
從算法的角度重新思考了優化器的功能,發現 SGD 在微調 LLM 完整參數方面是一種很好的替代品。這使得作者可以刪除優化器狀態的整個部分,因為 SGD 不存儲任何中間狀態。
新提出的優化器 LOMO 將梯度張量的內存使用量減少到 O (1),相當于最大梯度張量的內存使用量。
為了使用 LOMO 穩定混合精度訓練,作者集成了梯度歸一化、損失縮放,并在訓練期間將某些計算轉換為全精度。
新技術讓內存的使用等于參數使用加上激活和最大梯度張量。全參數微調的內存使用被推向了極致,其僅等同于推理的使用。這是因為 forward+backward 過程的內存占用應該不會比單獨的 forward 過程少。值得注意的是,在使用 LOMO 節省內存時,新方法確保了微調過程不受影響,因為參數更新過程仍然等同于 SGD。
該研究評估了 LOMO 的內存和吞吐量性能,表明借助 LOMO,研究者在 8 個 RTX 3090 GPU 上就可以訓練 65B 參數的模型。此外,為了驗證 LOMO 在下游任務上的性能,他們應用 LOMO 來調優 SuperGLUE 數據集集合上 LLM 的全部參數。結果表明了 LOMO 對具有數十億參數的 LLM 進行優化的有效性。
方法介紹
在方法部分,本文詳細介紹了 LOMO(LOW-MEMORY OPTIMIZATION)。一般而言,梯度張量表示一個參數張量的梯度,其大小與參數相同,這樣一來內存開銷較大。而現有的深度學習框架如 PyTorch 會為所有參數存儲梯度張量。現階段,存儲梯度張量有兩方面原因:計算優化器狀態以及歸一化梯度。
由于該研究采用 SGD 作為優化器,因此沒有依賴于梯度的優化器狀態,并且他們有一些梯度歸一化的替代方案。
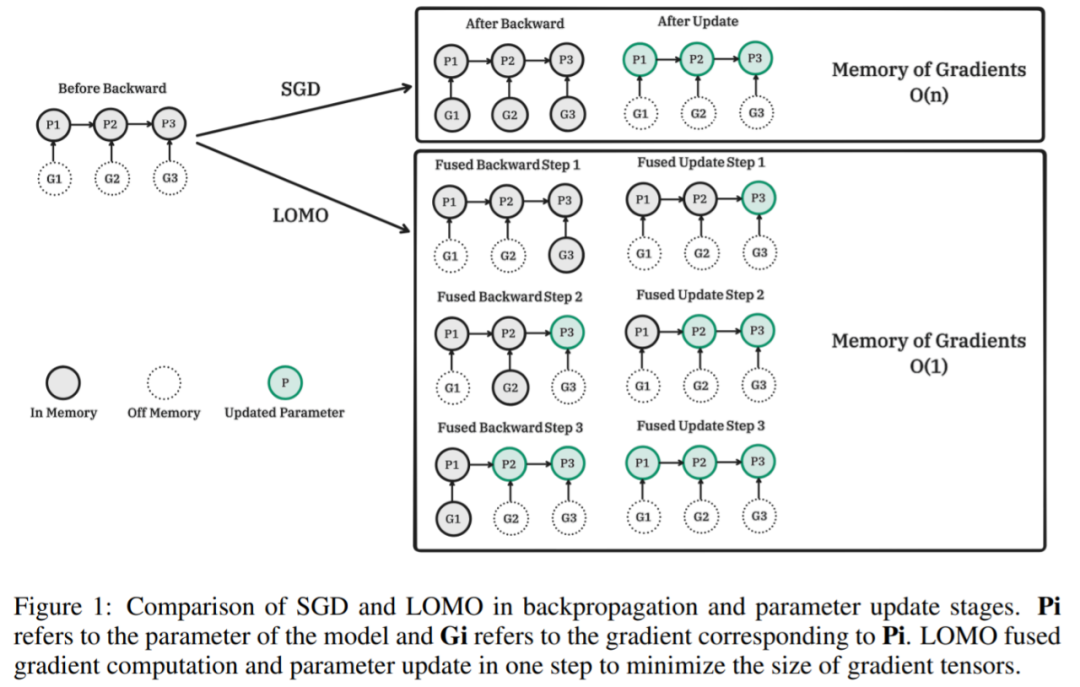
他們提出了 LOMO,如算法 1 所示,LOMO 將梯度計算與參數更新融合在一個步驟中,從而避免了梯度張量的存儲。
下圖為 SGD 和 LOMO 在反向傳播和參數更新階段的比較。Pi 為模型參數,Gi 為 Pi 對應的梯度。LOMO 將梯度計算和參數更新融合到一個步驟中,使梯度張量最小。
LOMO 對應的算法偽代碼:

具體而言,該研究將 vanilla 梯度下降表示為
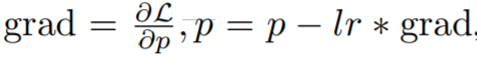
,這是一個兩步過程,首先是計算梯度,然后更新參數。融合版本為
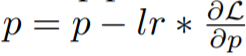
。 該研究的關鍵思想是在計算梯度時立即更新參數,這樣就不會在內存中存儲梯度張量。這一步可以通過在向反向傳播中注入 hook 函數來實現。PyTorch 提供了注入 hook 函數的相關 API,但卻無法用當前的 API 實現精確的即時更新。相反,該研究在內存中最多存儲一個參數的梯度,并隨著反向傳播逐一更新每個參數。本文方法減少了梯度的內存使用,從存儲所有參數的梯度到只存儲一個參數的梯度。
大部分 LOMO 內存使用與參數高效微調方法的內存使用一致,這表明 LOMO 與這些方法相結合只會導致梯度占用內存的輕微增加。這樣就可以為 PEFT 方法調優更多的參數。
實驗結果
在實驗部分,研究者從三個方面評估了他們提出的方法,即內存使用情況、吞吐量和下游性能。如果不作進一步解釋,所有的實驗都是用 7B 到 65B 的 LLaMA 模型進行的。
內存使用情況
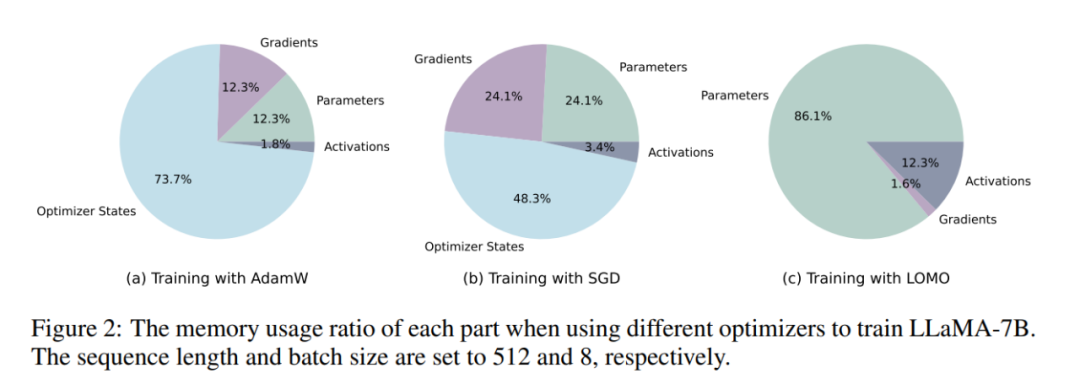
研究者首先剖析了,在不同設置下,訓練期間的模型狀態和激活的內存使用情況。如表 1 所示,與 AdamW 優化器相比,LOMO 優化器的使用導致內存占用大幅減少,從 102.20GB 減少到 14.58GB;與 SGD 相比,在訓練 LLaMA-7B 模型時,內存占用從 51.99GB 減少到 14.58GB。內存用量的大幅減少主要歸因于梯度和優化器狀態的內存需求減少。因此,在訓練過程中,內存大部分被參數占據,與推理過程中的內存用量相當。
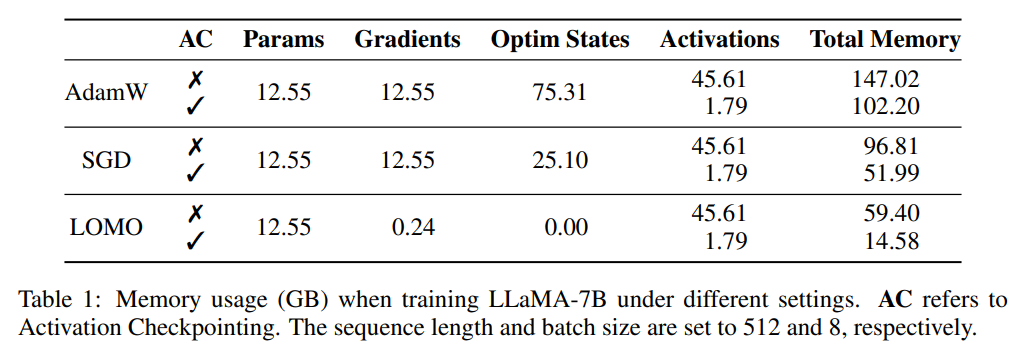
如圖 2 所示,如果采用 AdamW 優化器進行 LLaMA-7B 訓練,相當大比例的內存(73.7%)被分配給優化器狀態。用 SGD 優化器替換 AdamW 優化器可以有效減少優化器狀態占用內存的百分比,從而減輕 GPU 內存使用(從 102.20GB 減少到 51.99GB)。如果使用 LOMO,參數更新和 backward 會被融合到一個步驟中,進一步消除優化器狀態對內存的需求。
吞吐量
研究者比較了 LOMO、AdamW 和 SGD 的吞吐性能。實驗是在一臺配備了 8 個 RTX 3090 GPU 的服務器上進行的。
對于 7B 的模型,LOMO 的吞吐量呈現顯著優勢,超過 AdamW 和 SGD 約 11 倍。這一重大改進可歸功于 LOMO 在單個 GPU 上訓練 7B 模型的能力,這減少了 GPU 間的通信開銷。與 AdamW 相比,SGD 的吞吐量略高,這可歸因于 SGD 排除了動量和方差的計算。
至于 13B 模型,由于內存的限制,它無法在現有的 8 個 RTX 3090 GPU 上用 AdamW 訓練。在這種情況下,模型的并行性對 LOMO 來說是必要的,LOMO 在吞吐量方面仍然優于 SGD。這一優勢歸功于 LOMO 的內存高效特性,以及只需要兩個 GPU 以相同的設置來訓練模型,從而降低了通信成本,提高了吞吐量。此外,在訓練 30B 模型時,SGD 在 8 個 RTX 3090 GPU 上遇到了內存不足(OOM)的問題,而 LOMO 在只有 4 個 GPU 的情況下表現良好。
最后,研究者使用 8 個 RTX 3090 GPU 成功訓練了 65B 模型,實現了 4.93 TGS 的吞吐量。利用這樣的服務器配置和 LOMO,模型在 1000 個樣本上的訓練過程(每個樣本包含 512 個 token)大約需要 3.6 小時。
下游性能
為了評估 LOMO 在微調大型語言模型方面的有效性,研究者進行了一系列廣泛的實驗。他們將 LOMO 與其他兩種方法進行比較,一種是不需要微調的 Zero-shot,另一種是目前很流行的參數高效微調技術 LoRA。
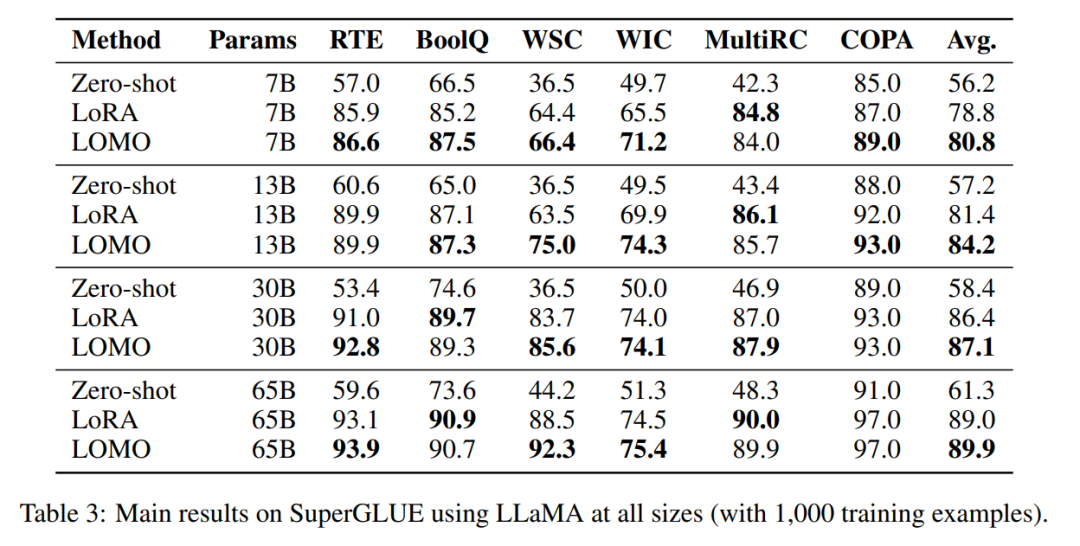
表 3 結果顯示:
LOMO 的表現明顯好于 Zero-shot;
在大多數實驗中,LOMO 普遍優于 LoRA;
LOMO 可以有效擴展至 650 億參數的模型。
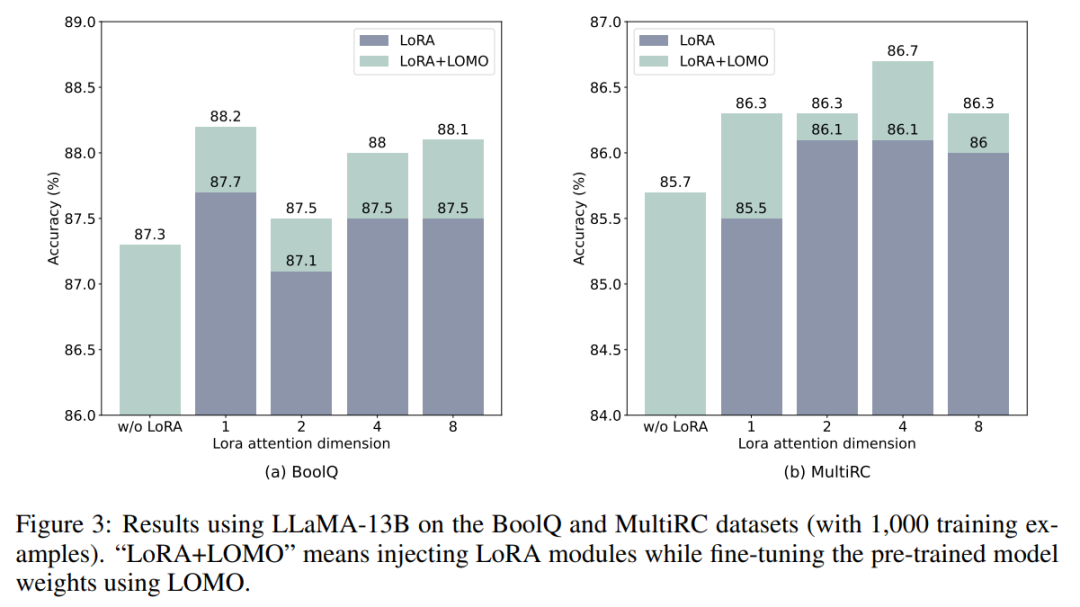
LOMO 和 LoRA 在本質上是相互獨立的。為了驗證這一說法,研究者使用 LLaMA-13B 在 BoolQ 和 MultiRC 數據集上進行了實驗。結果如圖 3 所示。
他們發現,LOMO 在持續增強 LoRA 的性能,不管 LoRA 取得的結果有多高。這表明,LOMO 和 LoRA 采用的不同微調方法是互補的。具體來說,LOMO 專注于微調預訓練模型的權重,而 LoRA 則調整其他模塊。因此,LOMO 不會影響到 LoRA 的性能;相反,它有助于對下游任務進行更好的模型調優。
-
gpu
+關注
關注
28文章
4742瀏覽量
128972 -
參數
+關注
關注
11文章
1838瀏覽量
32247 -
模型
+關注
關注
1文章
3248瀏覽量
48864
原文標題:650億參數,8塊GPU就能全參數微調!邱錫鵬團隊把大模型門檻打下來了!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
欲把AI計算成本打下來,谷歌高效益TPU正式開放
GPU上OpenVINO基準測試的推斷模型的默認參數與CPU上的參數不同是為什么?
消費者不著急出手?都在等蘋果加大供貨加個被“打下來”
一個GPU訓練一個130億參數的模型

我在iPhone上裝了70億參數大模型,來自陳天奇團隊最新成果
單張消費級顯卡微調多模態大模型
微軟宣布推出一個27億參數的語言模型Phi-2






 工商網監
工商網監
評論