 ChatGPT也能用來造芯,說說英語就可以了?
ChatGPT也能用來造芯,說說英語就可以了?
ChatGPT 真的那么牛嗎?
來自紐約大學 Tandon 工程學院的研究人員發布了一篇《Chip-Chat: Challenges and Opportunities in Conversational Hardware Design》論文,用實驗回答道:是的,ChatGPT 確實比較厲害!
只用簡單的自然語言之英語和 ChatGPT 聊聊天,便制作出了一款微處理芯片。更值得注意的是,在 ChatGPT 的助力下,這款芯片組件不僅是設計了出來的,也是經過了基礎測試,可以制造出來。

紐約大學發文評價道,「這是一項史無前例的成就,可以加快芯片開發速度,并允許沒有專業技術技能的個人設計芯片。」
所以說,全民”造芯“的時代真的要來臨了嗎?在此,我們不妨先看看研究人員到底是怎么做的。
AI 大模型的應用,硬件領域落后于軟件
在論文中,研究人員指出,現代硬件設計始于自然語言提供的規范,如英文文檔需求,然后再由硬件工程師使用硬件描述語言(HDL)如 Verilog,將需求用代碼構建出來,完成芯片內部的設計,最終再合成為電路元件。
那么,在 AIGC 時代來臨之際,如 OpenAI 的 ChatGPT 和 Google 的 Bard 號稱可以生成代碼,也有不少開發者使用過它們創建了一個又一個網站,但是當前在其應用范圍主要聚焦在軟件領域的情況,這些 AIGC 工具能否將硬件工程師的”翻譯“(文檔需求轉換成代碼)工作給取而代之。
基于此,研究人員使用了 8 種具有代表性的基準,研究了在生成硬件描述語言本身的編寫時,最先進的 LLM 狀態的能力和局限性。
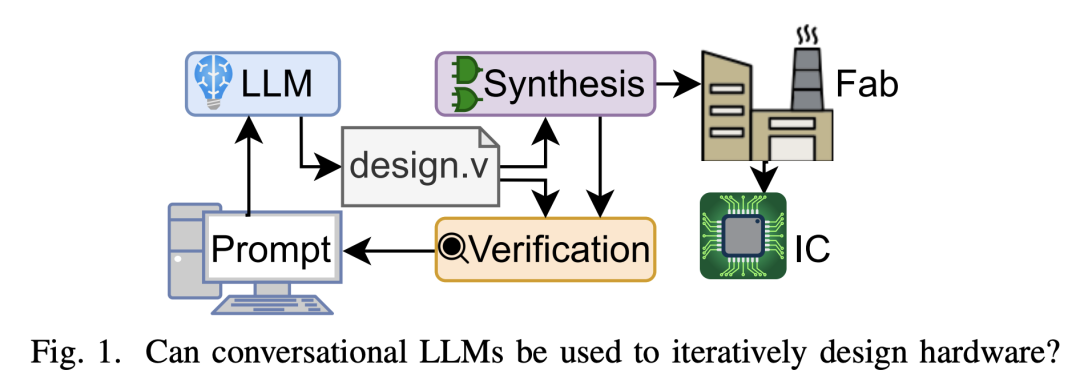
測試原理與規則
實驗環節,研究人員將 ChatGPT 作為一種模式識別器(充當人類的角色),可以在各種類型的語言(口頭語、書面語)中轉換自如,同時,ChatGPT 可以讓硬件工程師們跳過 HDL 階段。
整體驗證流程如下圖所示:
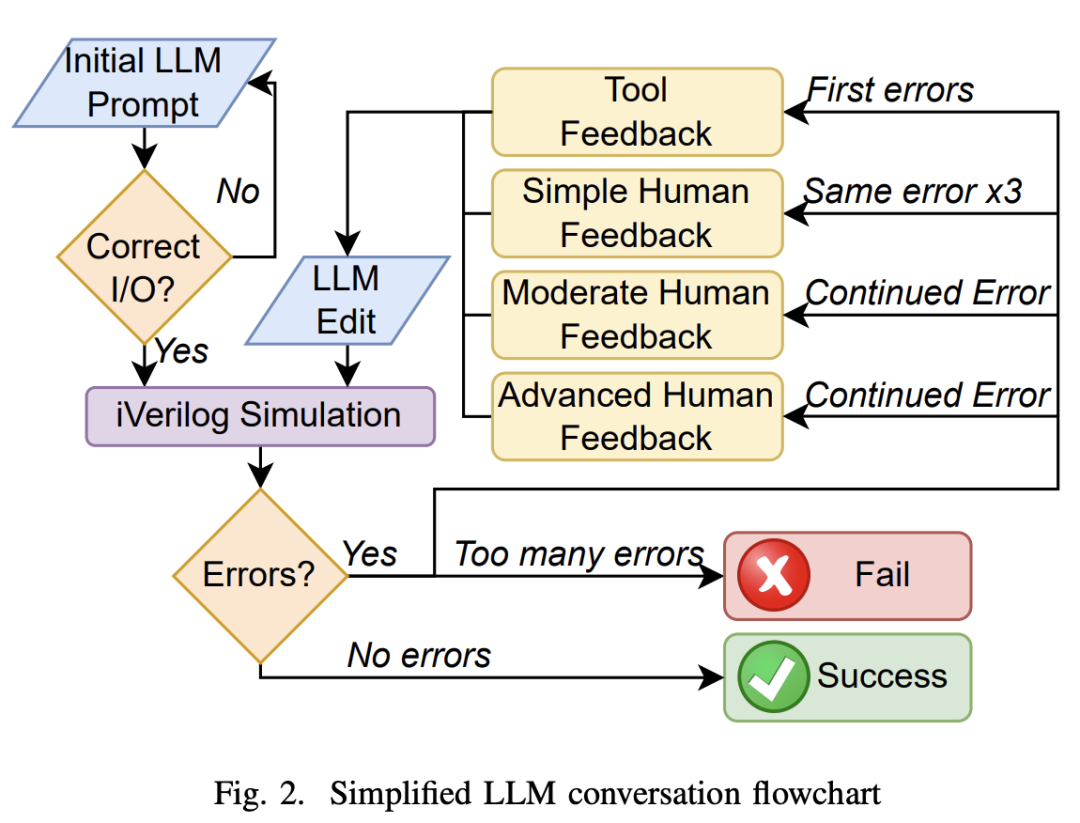
詳細來看,首先,硬件工程師對大模型提供初始提示,讓它創建一個 Verilog 模型,然后提供輸入、輸出的具體信息。最終硬件工程師對輸出設計進行可視化評估,以確定其是否符合基本設計規范。
如果一個設計不符合規范,它會在相同的提示下再生成五次。倘若它仍然不符合規范,那么它就會失敗。
一旦設計和測試用例已經寫好了,它們就會被用 Icarus Verilog (iverilog,Verilog 硬件描述語言的實現工具之一) 編譯。如果編譯成功,則進行模擬。如果沒有報告錯誤,則設計通過,不需要反饋 (NFN)。
如果這些操作中的任何一個報告了錯誤,它們就會被反饋到模型中,并被要求“請提供修正”,這被稱為工具反饋 (TF)。如果相同的錯誤或錯誤類型出現三次,那么簡單的人類反饋 (SHF) 是由用戶給出的,通常通過說明 Verilog 中什么類型的問題會導致這個錯誤 (例如:聲明中出現語法錯誤)。
如果錯誤持續存在,則會給出適度的人類反饋 (Moderate Human Feedback,MHF) ,并提供稍微更直接的信息給工具,以識別特定的錯誤。
如果錯誤持續存在,則會給出高級人類反饋 (Advanced HumanFeedback,AHF),它依賴于精確地指出錯誤所在和修復它的方法。
一旦設計編譯和模擬,沒有失敗的測試用例,它就被認為是成功的。
但是如果高級反饋不能修復錯誤,或者用戶需要編寫任何 Verilog 代碼來解決錯誤,則測試被認為是失敗的。如果會話超過 25 條消息,符合每 3 小時 ChatGPT-4 消息的 OpenAI 速率限制,則該測試也被視為失敗。
Bard和HuggingChat在首輪測試中折戟
具體實驗環節,研究人員針對 8 位移位寄存器進行了基準測試。
他們要求大模型嘗試為一個「測試名稱」創建一個 Verilog 模型,然后提供規范,定義輸入和輸出端口以及任何需要的進一步細節,并進一步詢問大模型“我將如何寫一個設計,以滿足這些規格?”

與此同時,研究人員還直接讓大模型生成測試臺的設計:
你能為這個設計編寫一個 Verilog 測試臺嗎?測試臺應該具備自檢功能,并且能夠與 iverilog 一起用于仿真和驗證。如果測試用例失敗,測試臺應該能夠提供足夠的信息,以便找到并解決錯誤。

進而,研究人員基于 ChatGPT-4、ChatGPT-3.5、Bard、HuggingChat 四款大模型得到了輸出內容:

最終結果顯示,兩個 ChatGPT 模型都能夠滿足規格,并開始進行設計流程。不過,Bard 和 HuggingChat 未能滿足規格的初始標準。

雖然按照上文提到的測試流程,研究人員基于 Bard 和 HuggingChat 的初始提示,又讓大模型重新生成了五次回答,但是多輪之后,這兩個模型還是都失敗了。其中,Bard 始終無法滿足給定的設計規范,HuggingChat 的 Verilog 輸出是在模塊定義之后就開始不正確了。
鑒于 Bard 和 HuggingChat 在初始挑戰基準提示符上的性能較差,研究人員決定后續只針對 ChatGPT-4 和 ChatGPT-3.5 進行完整的測試。
ChatGPT-4 和ChatGPT-3.5 的角逐
下圖顯示了 ChatGPT-4 和 ChatGPT-3.5 的基準測試結果,明顯可以看出,ChatGPT-3.5 的性能要比 ChatGPT-4 差一些,大多數對話導致基準測試失敗,而大多數通過自己測試臺的對話都是不兼容的。
反觀 ChatGPT-4 的表現更勝一籌,大多數的基準測試都通過了,其中大部分只需要工具反饋。不過,在測試臺設計中,仍然需要人類的反饋。

ChatGPT-4 與硬件工程師配對,共同開發芯片
為了探索 LLM 的潛力,研究人員還讓硬件設計工程師和 ChatGPT-4 配對,共同設計一種基于 8 位的累加器的微處理器。
對 ChatGPT-4 的初始提示如下所示:
讓我們一起做一個全新的微處理器設計......我認為我們需要限制自己的累加器8位架構,沒有多字節指令。既然如此,你覺得我們該怎么開始?

考慮到空間限制,研究人員的目標是使用 32 字節內存(數據和指令相結合)的馮·諾依曼型設計。
最終,ChatGPT-4 與硬件工程師共同設計了一種新穎的基于 8 位累加器的微處理器架構。該處理器采用 Skywater 130nm 工藝,這意味著這些“Chip-Chat”實現了我們認為是世界上第一個完全由人工智能編寫的用于流片的 HDL。
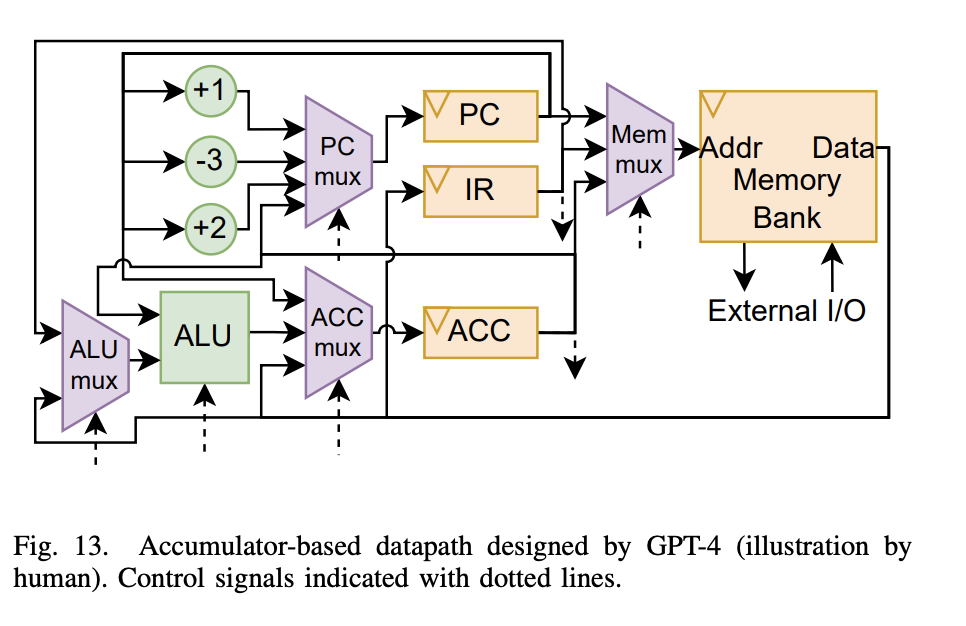
GPT-4 設計的基于累加器的數據路徑(由人類繪圖)
在論文中,研究人員總結道,ChatGPT-4 產生了相對高質量的代碼,這可以從短暫的驗證周轉中看出。考慮到 ChatGPT-4 每 3 小時 25 條消息的速率限制,此設計的總時間預算為 ChatGPT-4 的 22.8 小時(包括重新啟動)。每條消息的實際生成平均約為 30 秒:如果沒有速率限制,整個設計本可以在 <100 分鐘內完成,具體取決于人類工程師。盡管 ChatGPT-4 相對容易地生成了 Python 匯編程序,但它很難編寫為我們的設計編寫的程序,而且ChatGPT也沒有編寫任何重要的測試程序。
總體上,研究人員完成了在模擬和 FPGA 仿真中評估了一系列全面的人工編寫的匯編程序中的所有 24 條指令。
ChatGPT 能夠節省芯片開發周期
“這項研究產生了我們認為是第一個完全由 AI 生成的 HDL,用于制造物理芯片,”紐約大學 Tandon 的研究助理教授兼研究團隊成員 Hammond Pearce 博士說。“一些人工智能模型,如 OpenAI 的 ChatGPT 和谷歌的 Bard,可以生成不同編程語言的軟件代碼,但它們在硬件設計中的應用尚未得到廣泛研究。這項研究表明 AI 也可以使硬件制造受益,尤其是當它被用于對話時,你可以通過一種來回的方式來完善設計。”
然而,在這個過程中,研究人員也需要進一步測試和解決將 AI 用于芯片設計所涉及的安全考慮因素。
整體而言,雖然 ChatGPT 不是一款專門面向硬件領域的自動化軟件工具,但是它可以成為一款 EDA 輔助工具,而且幫助 EDA 設計師們大大降低了知識門檻。
研究人員也表示,如果在現實環境中實施,在芯片制造中使用 LLM 模型可以減少 HDL 轉換過程中的人為錯誤,有助于提高生產力,縮短設計時間和上市時間,并允許進行更具創意的設計。其實,僅是這一點,ChatGPT 便值得被硬件工程師們拿來在硬件領域參與更多的嘗試與探索。
-
FPGA
+關注
關注
1629文章
21736瀏覽量
603323 -
芯片
+關注
關注
455文章
50812瀏覽量
423583 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7666
原文標題:ChatGPT 也能用來造芯,說說英語就可以了?!
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
內存小的有福了,只要你的硬盤有多就可以當內存用
C語言基礎學習到什么程度就可以開始了?
科技大廠競逐AIGC,中國的ChatGPT在哪?
有了4G,是不是就可以砍掉固網了?
電池換換位置就可以增加里程并跑的更遠了嗎
百度將推出ChatGPT項目:文心一言 chatgpt國內能用嗎 可以用百度文心的






 工商網監
工商網監
評論