 使用Vitis AI在Zynq MP上實現手勢識別
使用Vitis AI在Zynq MP上實現手勢識別
FPGA得益于其高可編程性以及低延遲,低功耗的特點,在機器學習的推理領域已獲得了廣泛的關注。在過去,FPGA對于軟件開發人員來說有較高的開發門檻,把一部分開發者擋在了門外。如今越來越完善的高階工具以及軟件堆棧使得開發者可以充分利用FPGA優點對關鍵應用進行加速,同時不需花費時間去了解FPGA的底層實現。
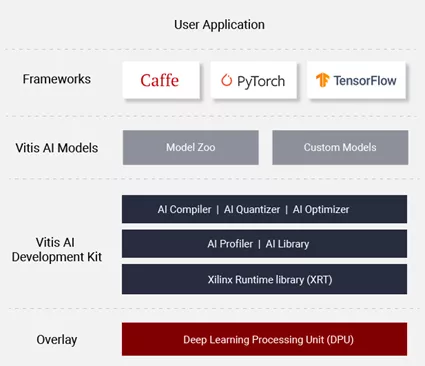
Xilinx Vitis AI 是用于 Xilinx 硬件平臺上的 AI 推理的開發堆棧。它由優化的 IP(DPU)、工具、庫、模型和示例設計組成,使用Xilinx ZynqMP SOC或者Versal ACAP器件并借助強大的Vitis AI堆棧,已大大降低了FPGA上部署機器學習應用的門檻。
本文將使用Tensorflow 2.0從零搭建并訓練一個簡單的CNN模型來進行數字手勢識別,并部署運行在ZynqMP開發板上,來熟悉Vitis AI的工作流程。
我們首先用Tensorflow 2.0創建模型并針對目標數據集進行訓練,然后使用Vitis AI 工具對模型進行量化/編譯等處理,獲得運行DPU所需要的xmodel文件。最后需要編寫調用Vitis AI runtime的主機應用,該應用運行在CPU上,進行必要的預處理/后處理以及對DPU進行調度。
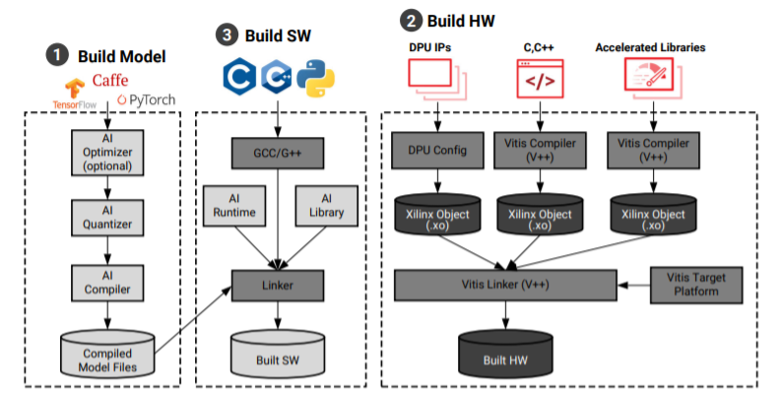
1Vitis AI環境配置
Vitis AI支持業界通用的Pytorch/Tensorflow/Caffe訓練框架。模型創建和訓練工作完全在通用框架下進行開發。開始工作之前需要先在Host機器上配置好Vitis-AI Docker環境,這部分完全參考https://github.com/Xilinx/Vitis-AI Guide即可。以下所有在Host機器上完成的步驟(訓練/量化/編譯)都是在Vitis AI docker 及vitis-ai-tensorflow2 conda env環境下完成。
2數據集
本實例使用的數字手勢數據集:
https://github.com/ardamavi/Sign-Language-Digits-Dataset (感謝開源數據集作者Arda Mavi )
3源碼說明
本項目的工程文件保存在 Github目錄:
https://github.com/lobster1989/Handsign-digits-classification-on-KV260
有4個主要文件夾:
1. code:
此處包含所有源代碼,包括用于訓練/量化/編譯任務的腳本,以及在 ARM 內核上運行的主機應用程序。
2. output:
生成的模型文件。
3. Sign-Language-Digits-Dataset:
數據集應該下載并放在這里。
4. target_zcu102_zcu104_kv260:
準備復制到目標板運行的文件。
4創建/訓練模型
Host機器上運行 "train.py" 腳本,train.py腳本中包含了模型的創建和訓練過程。模型的創建主要代碼如下,使用Keras的function式 API(注意sequential 式API目前Vitis AI不支持)。創建的模型包含4個連續的Conv2D+Maxpolling層,然后跟隨一個flatten layer,一個dropout layer,以及兩個全連接層。
這個模型僅僅作為示例,各位也可以嘗試使用其它的CNN模型或進行優化。
# Function: create a custom CNN model
def customcnn():
inputs = keras.Input(shape=image_shape)
x = layers.Conv2D(32, (3,3), activation='relu', input_shape=image_shape)(inputs)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Conv2D(64, (3,3), activation='relu')(x)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Conv2D(128, (3,3), activation='relu')(x)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Conv2D(128, (3,3), activation='relu')(x)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(512, activation='relu')(x)
outputs = layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs, name='customcnn_model')
model.summary()
# Compile the model
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=['acc']
)
return model
該模型在第 10 個epoch在驗證數據集上獲得了 0.7682 的精確度。
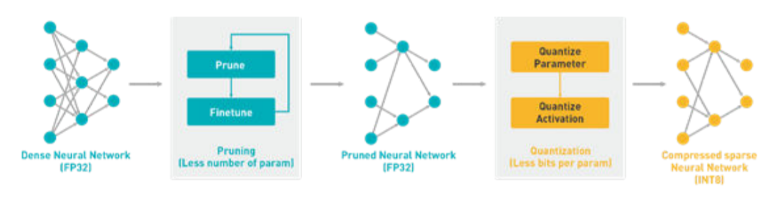
5模型量化
訓練完Tensorflow2.0模型后,下一步是使用Vitis AI quantizer工具對模型進行量化。量化過程將 32 位浮點權重轉換為 8 位整型 (INT8),定點模型需要更少的內存帶寬,從而提供更快的速度和更高的運行效率。如果需要進一步優化計算量級,還可以使用Vitis AI提供的剪枝(pruning)工具。
運行quantize.py腳本進行量化,運行結束后將生成量化后的模型''quantized_model.h5''。
進行quantize的代碼部分如下,調用VitisQuantizer,需要提供的輸入包括上個步驟生成的float模型,以及一部分圖片(推薦為100~1000張)作為calibration的輸入。Calibration操作使用提供的圖片進行正向運算,不需要提供label
# Run quantization
quantizer = vitis_quantize.VitisQuantizer(float_model)
quantized_model = quantizer.quantize_model(
calib_dataset=train_generator
)
6評估量化后模型
我們可以測試評估下量化后的模型是否有精度的損失。量化模型的評估可以直接在 python 腳本中利用TensorFlow框架完成。讀入模型,重新compile, 然后調用evaluation相關 API對模型進行評估。主要代碼部分如下
# Load the quantized model
path = os.path.join(MODEL_DIR, QAUNT_MODEL)
with vitis_quantize.quantize_scope():
model = models.load_model(path)
# Compile the model
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=['accuracy']
)
# Evaluate model with test data
loss, acc = model.evaluate(val_generator) # returns loss and metrics
運行“eval_quantize.py”腳本即可完成評估。通過評估發現,量化后的模型沒有發生精度損失。當然實際并不總是如此,有時候量化后的模型會有些許精度損失,這和不同的模型有關系。這時候我們可以使用Vitis AI提供finetuning來精調模型 。
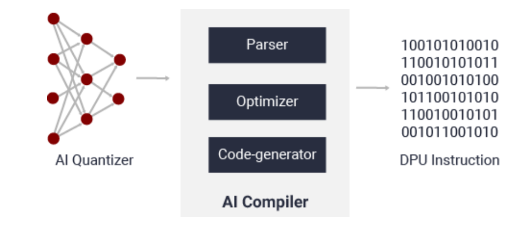
7編譯模型
模型的編譯需要用到Vitis AI compiler(VAI_C)。這個步驟實際上是把量化后的模型轉化為可以在DPU上運行的指令序列。VAI_C 框架的簡化流程如下圖所示,包含模型解析,優化和代碼生成三個階段。模型解析步驟對模型的拓撲進行解析,生成用Xilinx的中間表示層(Intermediate Representation)表示的計算圖(computation graph)。然后是執行一些優化操作,例如計算節點融合或者提高數據重用。最后的步驟是生成DPU架構上運行的指令序列。
運行compile.sh腳本即可完成編譯過程。主要代碼如下,使用vai_c_tensorflow2命令。注意需要提供目標DPU配置的arch.json文件作為輸入(--arch選項)。編譯步驟完成后會生成DPU推理用的xmodel文件。
compile() {
vai_c_tensorflow2
--model $MODEL
--arch $ARCH
--output_dir $OUTDIR
--net_name $NET_NAME
}
8主機程序
DPU作為神經網絡加速引擎,還需要CPU主機對其進行控制和調度,提供給DPU數據輸入/輸出。另外還需要對這部分運行在ARM或Host CPU上的應用而言, Vitis AI提供了Vitis AI Runtime (VART) 以及Vitis AI Library來方便應用開發。VART比較底層,提供更大的自由度。Vitis AI library屬于高層次API,構建于 VART 之上,通過封裝許多高效、高質量的神經網絡,提供更易于使用的統一接口。
VART具有C++和Python兩套API。多數機器學習開發者習慣用Python來開發和訓練模型,在部署階段甚至可以不用切換語言。本例子中提供了使用Python接口的host程序app_mt.py。使用Python API的簡化流程如下。
# Preprocess
dpu_runner = runner.Runner(subgraph,"run")
# Populate input/out tensors
jid = dpu_runner.execute_async(fpgaInput, fpgaOutput)
dpu_runner.wait(jid)
# Post process
9開發板上運行
如果使用的是 Xilinx zcu102/zcu104/KV260 官方 Vitis AI 啟動文件,則3 塊板上的 DPU 配置都相同。可以在 3 個平臺上運行相同的xmodel文件,主機上的所有步驟完成后,將以下文件復制到目標板上。共需要xmodel文件,主機程序,以及一些用來測試的圖片。
啟動開發板并運行 app_mt.py ,用 -d指定圖片路徑,-m指定xmodel文件,-t 指定CPU上運行的線程數。
很幸運,10張測試圖片的推理結果都是正確的。
root@xilinx-zcu102-2021_1:/home/petalinux/Target_zcu102_HandSignDigit#python3 app_mt.py -d Examples/ -m customcnn.xmodel
Pre-processing 10 images...
Starting 1 threads...
Throughput=1111.96 fps, total frames = 10, time=0.0090 seconds
Correct:10, Wrong:0, Accuracy:1.0000
審核編輯:湯梓紅
-
FPGA
+關注
關注
1630文章
21769瀏覽量
604628 -
手勢識別
+關注
關注
8文章
225瀏覽量
47809 -
AI
+關注
關注
87文章
31259瀏覽量
269615 -
Zynq
+關注
關注
10文章
610瀏覽量
47222 -
Vitis
+關注
關注
0文章
147瀏覽量
7464
原文標題:使用Vitis AI 在Zynq MP上實現手勢識別
文章出處:【微信號:HXSLH1010101010,微信公眾號:FPGA技術江湖】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何用10行代碼輕松在ZYNQ MP上實現圖像識別

閑談Vitis AI|DPU在UltraScale平臺下的軟硬件流程(1)
使用Vitis 在EBAZ4205(ZYNQ)礦機上實現"Hello World!"
【創龍TLZ7x-EasyEVM評估板試用連載】基于ZYNQ的動態手勢識別系統
【KV260視覺入門套件試用體驗】Vitis AI 初次體驗
【KV260視覺入門套件試用體驗】五、VITis AI (人臉檢測和人體檢測)
【KV260視覺入門套件試用體驗】六、VITis AI車牌檢測&車牌識別
【KV260視覺入門套件試用體驗】基于Vitis AI的ADAS目標識別
【KV260視覺入門套件試用體驗】Vitis AI 構建開發環境,并使用inspector檢查模型
【KV260視覺入門套件試用體驗】Vitis AI Library體驗之OCR識別
10行代碼輕松在ZYNQ MP上實現圖像識別
Zynq上使用Vitis的雙ARM Hello World

10行代碼輕松在ZYNQ MP上實現圖像識別的步驟





 工商網監
工商網監
評論