 PowerBEV的高效新型端到端框架基于流變形的后處理方法
PowerBEV的高效新型端到端框架基于流變形的后處理方法
摘要
準確地感知物體實例并預測它們未來的運動是自動駕駛車輛的關鍵任務,使它們能夠在復雜的城市交通中安全導航。雖然鳥瞰圖(BEV)表示在自動駕駛感知中是常見的,但它們在運動預測中的潛力尚未得到充分探索。現有的從環繞攝像頭進行BEV實例預測的方法依賴于多任務自回歸設置以及復雜的后處理,以便以時空一致的方式預測未來的實例。在本文中,我們不同于這中范例,提出了一個名為PowerBEV的高效新型端到端框架,采用了幾種旨在減少先前方法中固有冗余的設計選擇。首先,與其按自回歸方式預測未來,PowerBEV采用了由輕量級2D卷積網絡構建的并行多尺度模塊。其次,我們證明,分割和向心反向流對于預測是足夠的,通過消除冗余輸出形式簡化了先前的多任務目標。基于此輸出表示,我們提出了一種簡單的基于流變形的后處理方法,可在時間上產生更穩定的實例關聯。通過這種輕量化但強大的設計,PowerBEV在NuScenes數據集上勝過了最先進的方法,并為BEV實例預測提供了一種替代范例。
主要貢獻
我們提出了PowerBEV,一個新穎而優雅的基于視覺的端到端框架,它只由2D卷積層組成,用于在BEV中執行多個對象的感知和預測。
我們證明,由于冗余表示引起的過度監督會影響模型的預測能力。相比之下,我們的方法通過簡單地預測分割和向心反向流來實現語義和實例級別的代理預測。
我們提出的基于向心反向流的提議分配優于以前的前向流結合傳統的匈牙利匹配算法。
主要方法
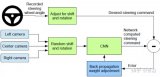
我們的方法的框架如圖1所示。它主要由三個部分組成:感知模塊、預測模塊和后處理階段。感知模塊將M個多視角相機圖像作為個時間戳的輸入,并將他們轉換為個BEV特征圖。然后,預測模塊融合提取的BEV特征中包含的時空信息,并同時預測一系列分割地圖和向心反向流,用于未來幀。最后,通過基于變形的后處理。從預測的分割和流中恢復未來的實例預測。
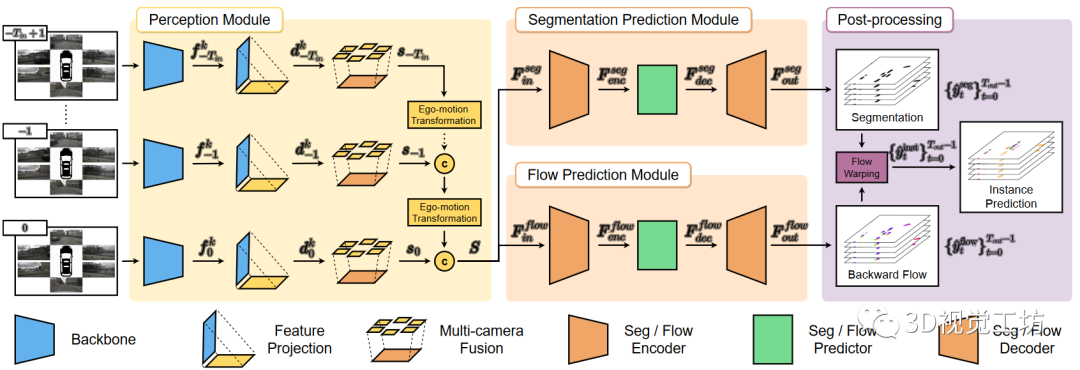 圖1:PowerBEV的框架
圖1:PowerBEV的框架
1、基于LSS的感知模塊
為了獲取用于預測的視覺特征,我們遵循之前的工作,并在LSS的基礎上建立起從環繞攝像機中提取BEV特征網格。對于每個時間t的每個相機圖像,我們應用共享的EfficientNet網絡來提取透視特征,其中我們將的前個通道指定為上下文特征,后面的個通道表示分類深度分布。通過外積構造一個三維特征張量。
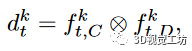
其中,根據估計的深度分布置信度將上下文特征提升到不同的深度中。然后,每個時間戳的每個相機特征分布映射基于對應相機的已知內部參數和外部參數被投影到以車輛為中心的坐標系中。隨后,它們沿著高度維度加權,以獲得時間戳t處的全局BEV狀態,其中是狀態通道數量,(H,W)是BEV狀態地圖的網格大小。最后,所有的BEV狀態合并到當前幀中,并像FIERY一樣堆疊,因此這追蹤表示是獨立于自車位置的當前全局動態。
2、多尺度預測模塊
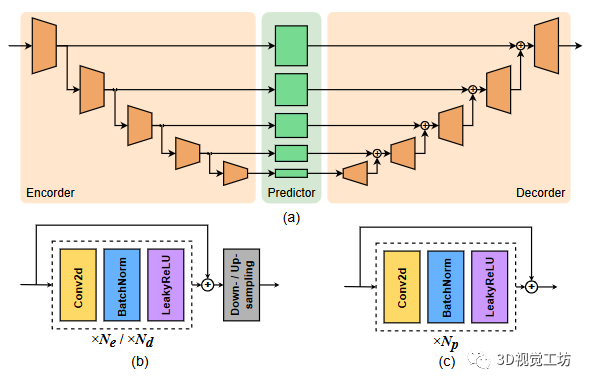 圖2:多尺度預測模塊的結構
圖2:多尺度預測模塊的結構
獲得過去環境的簡潔表示S后,我們使用一個多尺度U-Net類編碼器解碼器架構,將觀察到的BEV特征圖作為輸入,并預測未來的分割地圖和向心反向流場,如圖2所示。為了僅使用2D卷積進行時空特征處理,我們將時間和特征維度折疊成一個單一的維度,從而得到輸入張量。編碼器首先逐步在空間上對進行下采樣,生成多尺度BEV特征,其中。在一個中間的預測器階段,將特征從映射到,獲取。最后,解碼器鏡像編碼器,在原始尺度上重建出未來的BEV特征。每個分支分別被監督以預測未來的分割地圖或向心反向流場。考慮到任務和監督的差異,我們為每個分支使用相同的架構但不共享權重。與以前基于空間LSTM或空間GRU的工作相比,我們的架構只利用2D卷積,在解決長程時間依賴性方面大大緩解了空間RNN的限制。
3、多任務的設置
現有的方法遵循自下而上的原則,為每個幀生成實例分割,然后根據前向流使用匈牙利匹配算法在幀之間關聯實例。因此,需要四個不同的頭部:語義分割、中心性、未來前向流和BEV中的每像素向心偏移。這導致由于多任務訓練而產生模型冗余和不穩定性。相比之下,我們首先發現,流和向心偏移都是實例掩模內的回歸任務,并且流可以理解為運動偏移量。此外,這兩個量與中心性在兩個階段中組合:(1)向心偏移將像素分組到每個幀中預測的實例中心,以將像素分配給實例ID;(2)流用于匹配兩個連續幀中的中心以進行實例ID關聯。基于以上分析,使用統一表示形式直觀地解決這兩個任務。為此,我們提出了向心反向流場,它是從時間t處的每個前景像素到時間t?1處關聯實例標識的對象中心的位移向量。這將像素到像素的反向流向量和向心偏移向量統一為單一表示形式。使用我們提出的流,可以直接將每個占用的像素關聯到上一幀中的實例ID。這消除了將像素分配給實例的額外聚類步驟,將先前工作中使用的兩階段后處理簡化為單階段關聯任務。此外,我們發現語義分割地圖和中心性的預測非常相似,因為中心基本對應于語義實例的中心位置。因此,我們建議直接從預測的分割地圖中提取局部最大值來推斷對象中心。這消除了分別預測中心的需要,如圖3所示。
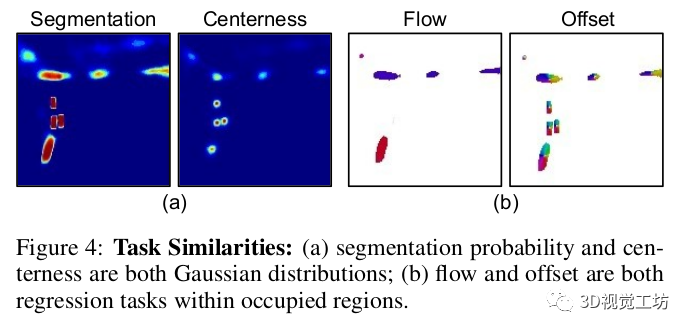
圖3:多任務設置
總的來說,我們的網絡僅僅產生兩個輸出,語義分割和向心反向流。我們使用top-k,k=25%的交叉熵作為語義分割損失函數,平滑的L1距離作為流動損失函數。總的損失函數為。
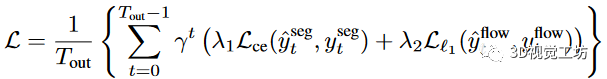
,和使用不確定性權重自動的更新。
4、實例關聯
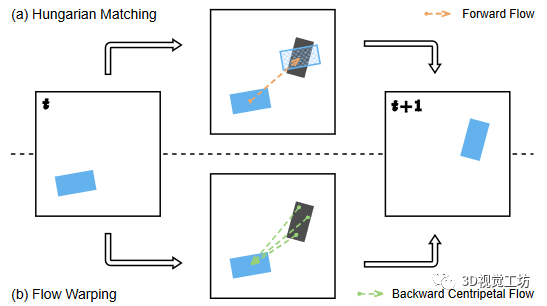 圖4:實例關聯
圖4:實例關聯
對于實例預測,我們需要隨著時間推移將未來的實例相互關聯。現有的方法使用前向流將實例中心投影到下一幀,然后使用匈牙利匹配將最近的代理中心進行匹配,如圖4.a所示。這種方法執行實例級別的關聯,其中實例身份由其中心表示。因此,僅使用位于對象中心上的流向量用于運動預測。這有兩個缺點:首先,沒有考慮對象旋轉;其次,單個位移向量比覆蓋整個實例的多個位移向量更容易出錯。在實踐中,這可能導致重疊的預測實例,導致錯誤的ID分配。這在長期預測范圍內的近距離物體上尤為明顯。利用我們提出的向心反向流,我們進一步提出了基于變形的像素級關聯來解決上述問題。我們的關聯方法的說明如圖4.b所示。對于每個前景網格單元,該操作將實例ID直接從前一個幀中流向量目標處的像素傳播到當前幀。使用此方法,每個像素的實例ID都被單獨分配,從而產生像素級關聯。與實例級別關聯相比,我們的方法對嚴重的流預測錯誤更具有容忍度,因為真實中心周圍的相鄰網格單元傾向于共享相同的身份,而錯誤往往發生在單個外圍像素上。此外,通過使用向后流變形,可以將多個未來位置與前一幀中的一個像素關聯起來。這對于多模式未來預測是有益的。正如所述,向后關聯需要在前一幀中的實例ID。特殊情況是第一個幀(t = 0)的實例分割生成,其沒有其前一幀(t = -1)的實例信息可用。因此,僅針對時間戳t = 0,我們通過將像素分組到過去實例中心來分配實例ID。
主要結果
我們首先將我們的方法與其他baseline相比較,結果如表1所示。我們的方法在感知范圍設置下的評估指標IoU(Intersection-over-Union)和VPQ(video panoptic quality)均取得了顯著的改進。在長距離設置中,PowerBEV的表現優于重新生成的FIERY,在IoU方面提高了1.1%,在VPQ方面提高了2.9%。此外,盡管使用較低的輸入圖像分辨率和更少的參數,PowerBEV在所有指標上的表現都優于BEVerse。與其他引入模型隨機過程的方法相比,PowerBEV是一種確定性方法,能夠實現準確的預測。這也展示了反向流在捕捉多模態未來方面的能力。
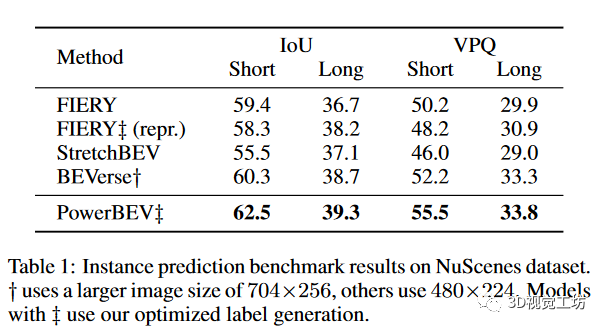 圖5:定量評估解決
圖5:定量評估解決
下圖展示了我們方法的定性結果。我們展示了在三種典型駕駛場景中(城市道路上交通密集的情況、停車場中靜態車輛眾多的情況和雨天駕駛場景)與FIERY的比較。我們的方法為最常見的交通密集場景提供了更精確、更可靠的軌跡預測,這在第一個例子中變得特別明顯,其中車輛轉向自車左側的側街。而FIERY只對車輛位置作出了一些模糊的猜測,并且難以處理它們的動態特征,與之相反,我們的方法提供了更好地匹配真實車輛形狀以及未來可能軌跡的清晰物體邊界。此外,從第二個例子的比較中可以看出,我們的框架可以檢測到位于較遠距離的車輛,而FIERY則失敗了。此外,我們的方法還可以檢測到在雨天場景中被墻壁遮擋的卡車,即使對于人眼來說也很難發現。
 圖6:可視化對比結果
圖6:可視化對比結果
責任編輯:彭菁
-
模塊
+關注
關注
7文章
2707瀏覽量
47476 -
框架
+關注
關注
0文章
403瀏覽量
17489 -
自動駕駛
+關注
關注
784文章
13812瀏覽量
166461
原文標題:IJCAI2023|PowerBEV:一個強大且輕量的環視圖像BEV實例預測框架
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TCP端到端等效噪聲模型及擁塞控制方法研究
SDN中的端到端時延
端到端的自動駕駛研發系統介紹

基于幀級特征的端到端說話人識別方法

采用帶有transformer的端到端框架獲取對應集合結果

使用FastDeploy在英特爾CPU和獨立顯卡上端到端高效部署AI模型
新型的端到端弱監督篇幅級手寫中文文本識別方法PageNet

PVT++:通用的端對端預測性跟蹤框架






 工商網監
工商網監
評論