 如何設計一個高效的分布式日志服務平臺
如何設計一個高效的分布式日志服務平臺
GEEK TALK
01
分布式服務下日志服務挑戰
分布式服務系統中,每個服務有大量的服務器,而每臺服務器每天都會產生大量的日志。我們面臨的主要挑戰有:
1、日志量巨大:在分布式服務環境中,日志分散在多個節點上,每個服務都會產生大量的日志,因此需要一種可靠的機制來收集和聚合日志數據。
2、多樣化的日志格式:不同的服務可能使用不同的日志格式,例如日志輸出的字段、順序和級別等,這會增加日志服務的開發和維護難度。
3、日志服務的可擴展性和可靠性:隨著分布式服務數量的增加和規模的擴大,日志服務需要能夠進行橫向擴展和縱向擴展,以保證其性能和可靠性。
所以我們該如何提供分布式系統下高效、低延遲、高性能的日志服務呢?
GEEK TALK
02
業內ELK通用解決方案
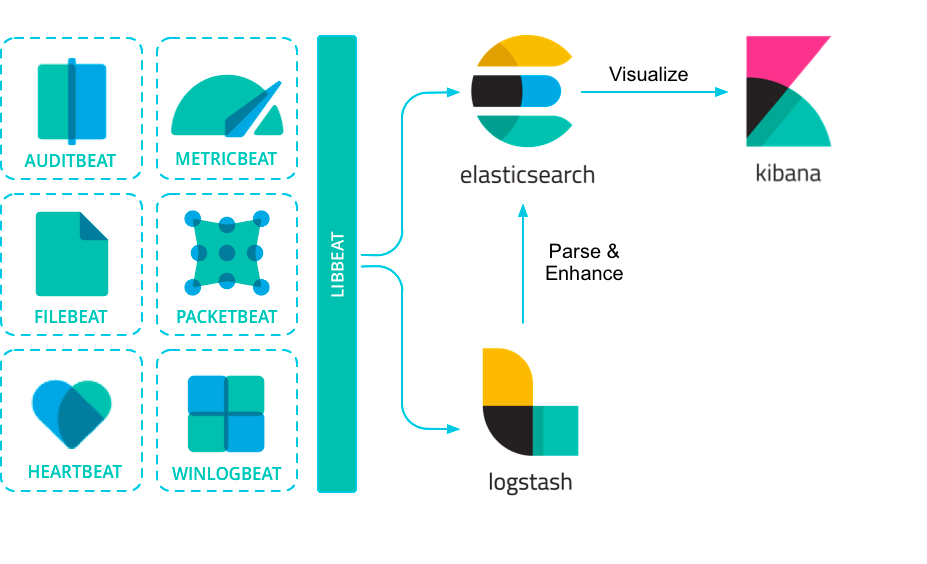
2.2 Elastic Stack組件架構圖
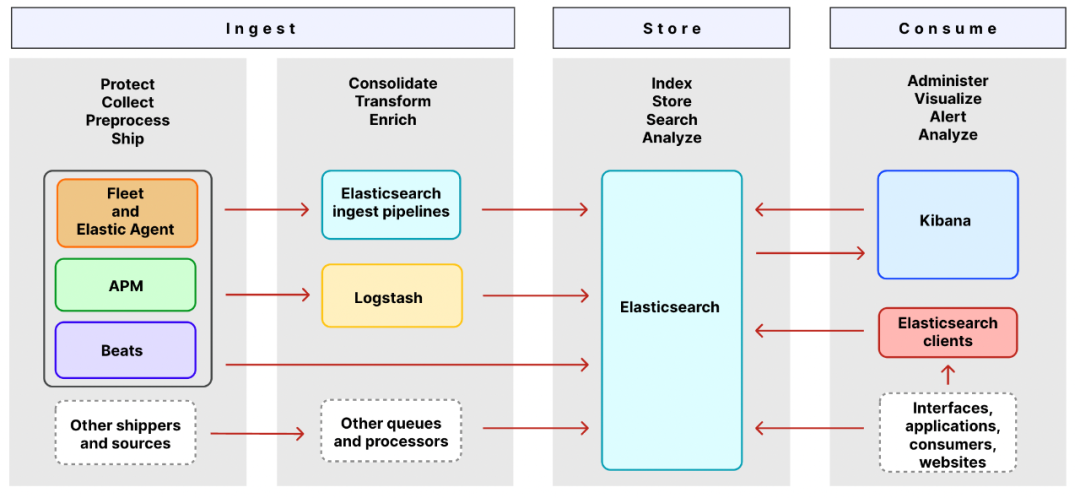
2.2.1 Ingest組件
Ingest是獲取日志數據的相關組件。
shippers和sources是收集的原始日志組件,承接著原始日志(log文件日志、系統日志、網絡日志等)采集和發送,其中Elastic Agent、APM、Beats 收集和發送日志、指標和性能數據。
queues和processors是原始日志數據的處理管道,使用這些組件可以定制化的對原始日志數據進行處理和轉換,在存儲之前可以模板化數據格式,方便elasticsearch更好的承接存儲和檢索功能。
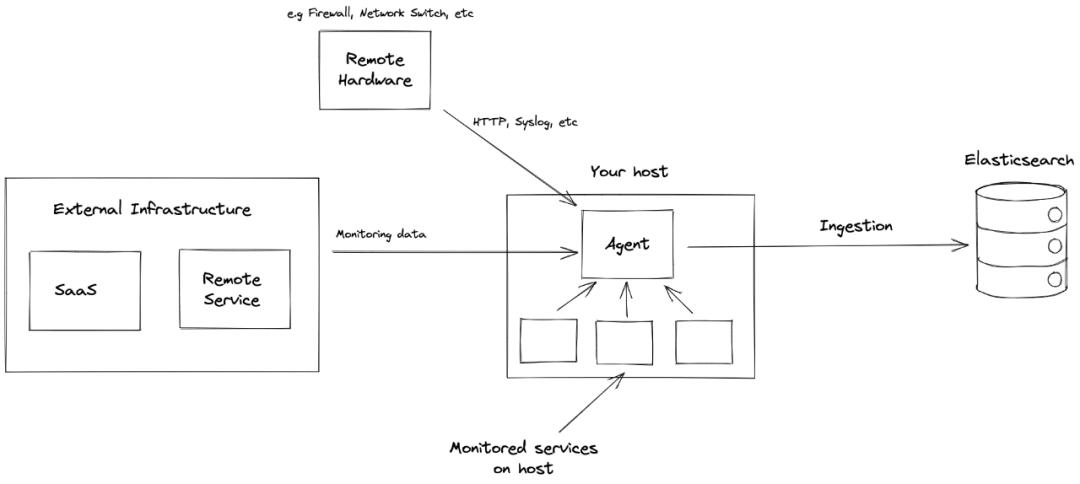
Elastic Agent是一種使用單一、統一的方式,為主機添加對日志、指標和其他類型數據的監控。它還可以保護主機免受安全威脅、從操作系統查詢數據、從遠程服務或硬件轉發數據等等。每個代理都有一個策略,可以向其中添加新數據源、安全保護等的集成。
Fleet能夠集中管理Elastic Agent及其策略。使用 Fleet 可以監控所有 Elastic Agent 的狀態、管理agent策略以及升級 Elastic Agent 二進制文件或集成。
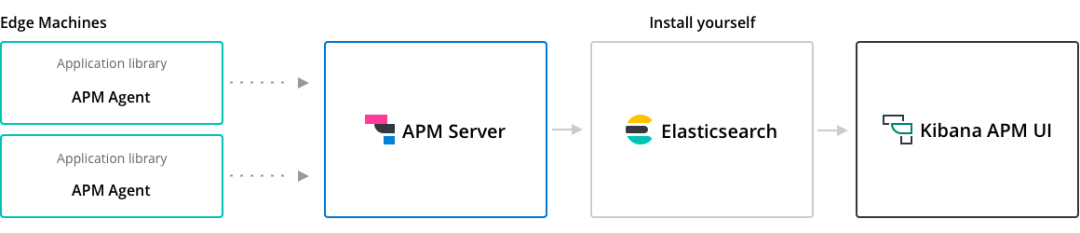
Elastic APM是一個基于 Elastic Stack 構建的應用程序性能監控系統。通過收集有關傳入請求、數據庫查詢、緩存調用、外部 HTTP 請求等響應時間的詳細性能信息,實時監控軟件服務和應用程序。
Beats是在服務器上作為代理安裝的數據發送器,用于將操作數據發送到 Elasticsearch。Beats 可用于許多標準的可觀察性數據場景,包括審計數據、日志文件和日志、云數據、可用性、指標、網絡流量和 Windows 事件日志。
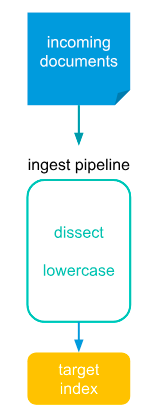
Elasticsearch Ingest Pipelines可以在將數據存儲到 Elasticsearch 之前對數據執行常見的轉換。將一個或多個“處理器”任務配置為按順序運行,在將文檔存儲到 Elasticsearch 之前對文檔進行特定更改。
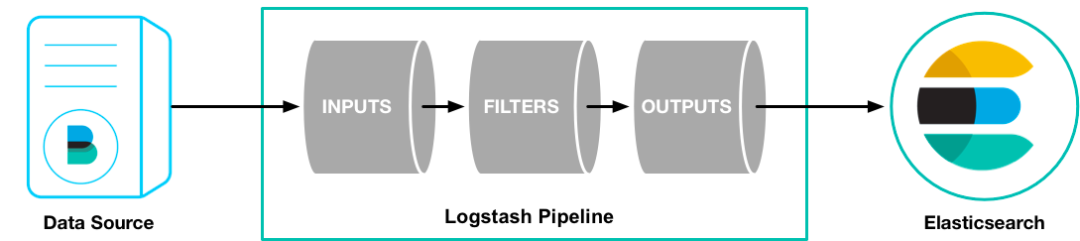
 Logstash是一個具有實時數據收集引擎。它可以動態地統一來自不同來源的數據,并將數據規范化到目的地。Logstash 支持豐富的輸入、過濾器和輸出插件。
Logstash是一個具有實時數據收集引擎。它可以動態地統一來自不同來源的數據,并將數據規范化到目的地。Logstash 支持豐富的輸入、過濾器和輸出插件。
2.2.2 Store組件
Store 是承接日志存儲和檢索組件,這里是使用的Elasticsearch承接該功能。Elasticsearch 是 Elastic Stack 核心的分布式搜索和分析引擎。它為所有類型的數據提供近乎實時的搜索和分析。無論結構化或非結構化文本、數字數據還是地理空間數據,Elasticsearch 都可以以支持快速搜索的方式高效地存儲和索引這些數據。Elasticsearch 提供了一個 REST API,使您能夠在 Elasticsearch 中存儲和檢索數據。REST API 還提供對 Elasticsearch 的搜索和分析功能的訪問。2.2.3 Consumer組件
Consumer是消費store存儲數據的組件,這里組要有可視化的kibana和Elasticsearch Client。Kibana 是利用 Elasticsearch 數據和管理 Elastic Stack 的工具。使用它可以分析和可視化存儲在 Elasticsearch 中的數據。
Elasticsearch Client提供了一種方便的機制來管理來自語言(如 Java、Ruby、Go、Python 等)的 Elasticsearch 的 API 請求和響應。

2.3天眼對比ELK差異
1、接入便捷性
ELK:方案依賴完整流程部署準備,操作配置復雜,接入跑通耗時長。
天眼:只需簡單三步配置,頁面申請產品線接入、頁面獲取產品線appkey、依賴管理中增加天眼SDK依賴并配置appkey到系統配置中。
2、資源定制化
ELK:資源修改、配置每次都需要重啟才能生效,不支持多資源配置化選擇。
天眼:產品線接入時可以選擇使用業務自身傳輸、存儲資源或自動使用系統默認資源,資源切換只需頁面簡單配置并即時自動生效。
3、擴容成本與效率
ELK:方案僅支持單個業務產品線,其他業務產線接入需重新部署一套,資源無法共享,擴容需手動增加相應實例等。
天眼:資源集中管理,產品線動態接入,資源動態配置即時生效,大部分資源自動共享同時又支持資源獨享配置;擴容直接通過平臺頁面化操作,簡單便捷。
4、日志動態清理
ELK:依賴人工發現、手動清理和處理資源占用。
天眼:自動化監測ES集群概況,自動計算資源占用情況,當達到監控閾值時自動執行時間最早的索引資源清理。
5、自適應存儲
ELK:傳統方案受限于存儲資源空間和成本,存儲成本高、可保存的數據量有限。
天眼:實現了日志轉存文件及從文件自動化恢復,日志存儲成本低,存儲周期長。
天眼通過自建分布式日志平臺,有效的解決ELK日志方案下存在的缺陷問題;當前天眼日志量級:日均10TB日志量,并發QPS:10w+,接入產品線數:1000+。
GEEK TALK
03
天眼
3.1 天眼系統架構
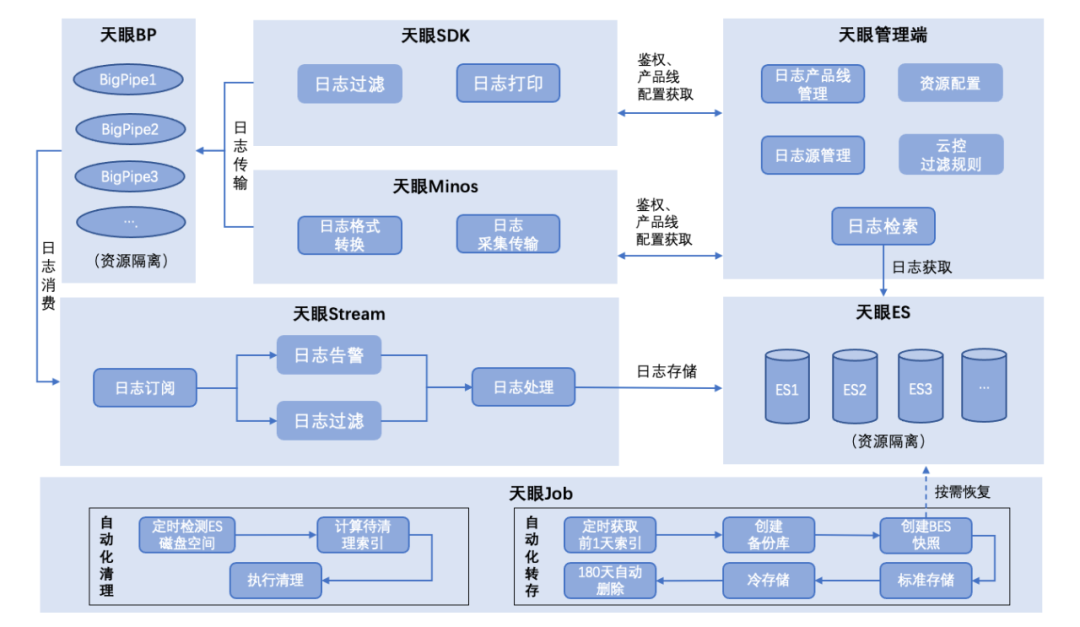
上圖為完整的天眼核心系統架構,概述如下:
1、天眼日志采集支持SDK及監聽日志文件兩種方式,其中SDK主要通過實現日志插件接口獲得完整日志結構信息,并傳輸至天眼日志傳輸管道;獲得的日志信息LogEvent結構完整,同時基于LogEvent增加了產品線標識等字段,為日志隔離和檢索提供核心依據;監聽日志文件方式實現業務方0開發成本接入,僅需簡單配置即可實現日志接入,支持產品線字段標識的同時,日志消息體解析也實現了正則匹配規則自動化匹配。
2、天眼日志傳輸采用高并發性能隊列Disruptor,并且二次采用高性能隊列Bigpipe實現日志傳輸異步解耦,解決了傳統隊列因加鎖和偽共享等問題帶來的性能缺陷;同時在傳輸過程中提供日志過濾和日志告警規則配置化自動化執行。
3、天眼日志存儲通過輪詢消費Bigpipe日志消息,最終寫入ES的BulkProcessor,由ES自動調度并發寫入ES進行存儲;在日志傳輸和存儲過程中實現了日志傳輸資源與存儲資源隔離,根據產品線配置自動化選擇傳輸與存儲資源。
4、天眼自動化清理實現在存儲資源有限的情況下自適應存儲,自動化轉存與恢復實現了在ES資源有限情況下低成本長時間存儲解決方案。
3.2 天眼日志采集
日志平臺核心目的是采集分布式場景下的業務日志進行集中處理和存儲,采集方式主要包含如下:
1、借助常見日志框架提供的插件接口,在生成日志事件的同時執行其他自定義處理邏輯,例如log4j2提供的Appender等。
2、通過各種攔截器插件在固定位置攔截并主動生成和打印業務日志,將這類日志信息主動發送至日志消息傳輸隊列中供消費使用,常見的如http、rpc調用鏈請求與返回信息打印,以及mybatis執行過程SQL明細打印等。
3、監聽日志文件寫入,從文件系統上的一個文件進行讀取,工作原理有些類似UNIX的tail -0F命令,當日志寫入本地文件時捕獲寫入行內容并進行其他自定義處理,例如將日志行信息發送至消息隊列供下游使用。
4、syslog:監聽來自514端口的syslog消息,并將其轉換為RFC3164格式。
更多可用的日志采集實現方式,可以參考:Input Plugins
下面以天眼日志采集為例詳細介紹日志采集實現過程:
天眼平臺供支持兩類日志采集實現方式,一類是SDK、一類是minos(百度自研的新一代的流式日志傳輸系統)。
3.2.1 天眼SDK日志采集
天眼SDK日志采集方式為通過Java SDK方式向業務方提供日志采集組件實現,達到自動收集業務日志并自動傳輸的目的;核心分為message日志流和trace日志流兩大塊:
1、message日志流主要通過日志框架提供的Appender接口實現,共支持log4j、logback、log4j2等主流日志框架。
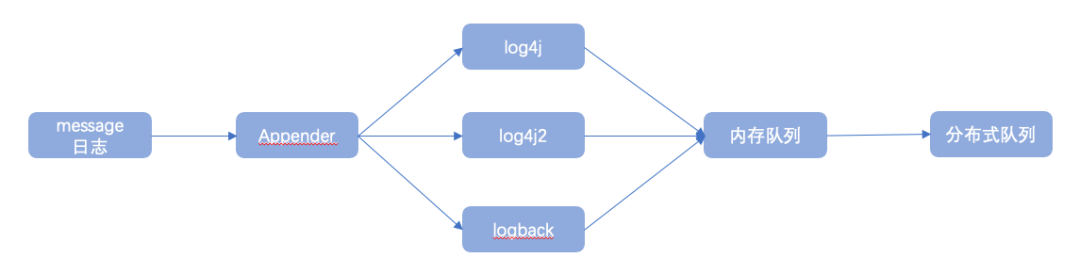
以logback為例,通過繼承并實現AppenderBase抽象類提供的append方法,在logback日志框架生成LogEvent后獲取日志事件對象并提交給LogbackTask執行任務處理,在LogbackTask中可以對日志事件內容進行進一步包裝完善,并執行一些日志過濾策略等,最終得到的日志事件信息將直接發送至日志傳輸隊列進行傳輸處理;
public class LogClientAppender<E> extends AppenderBase<E> {
private static final Logger LOGGER = LoggerFactory.getLogger(LogClientAppender.class);
protected void append(E eventObject) {
ILoggingEvent event = filter(eventObject);
if (event != null) {
MessageLogSender.getExecutor().submit(new LogbackTask(event, LogNodeFactory.getLogNodeSyncDto()));
}
}
}
2、trace日志流主要通過各類攔截器攔截業務請求調用鏈及業務執行鏈路,通過獲取調用鏈詳細信息主動生成調用鏈日志事件,并發送至日志傳輸隊列進行消費使用,常見的調用鏈日志包含http與rpc請求及響應日志、mybatis組件SQL執行日志等;
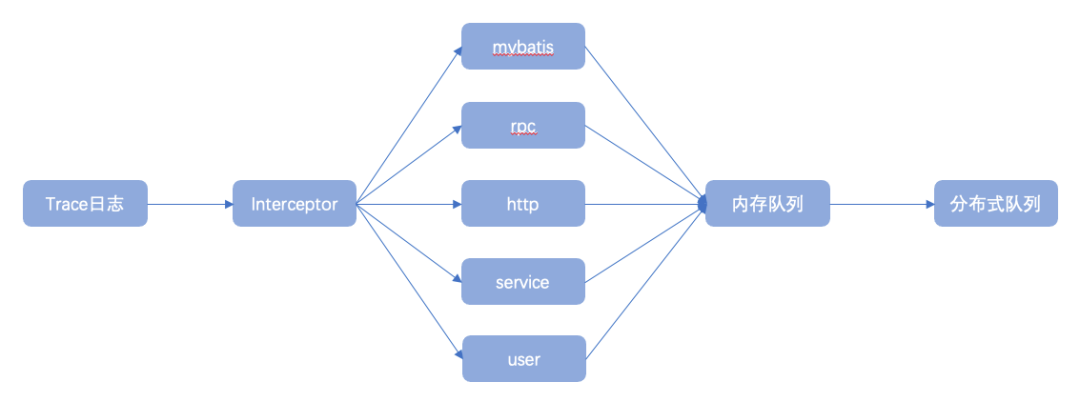
下圖為trace日志流實現類圖,描述了trace日志流抽象實現過程:
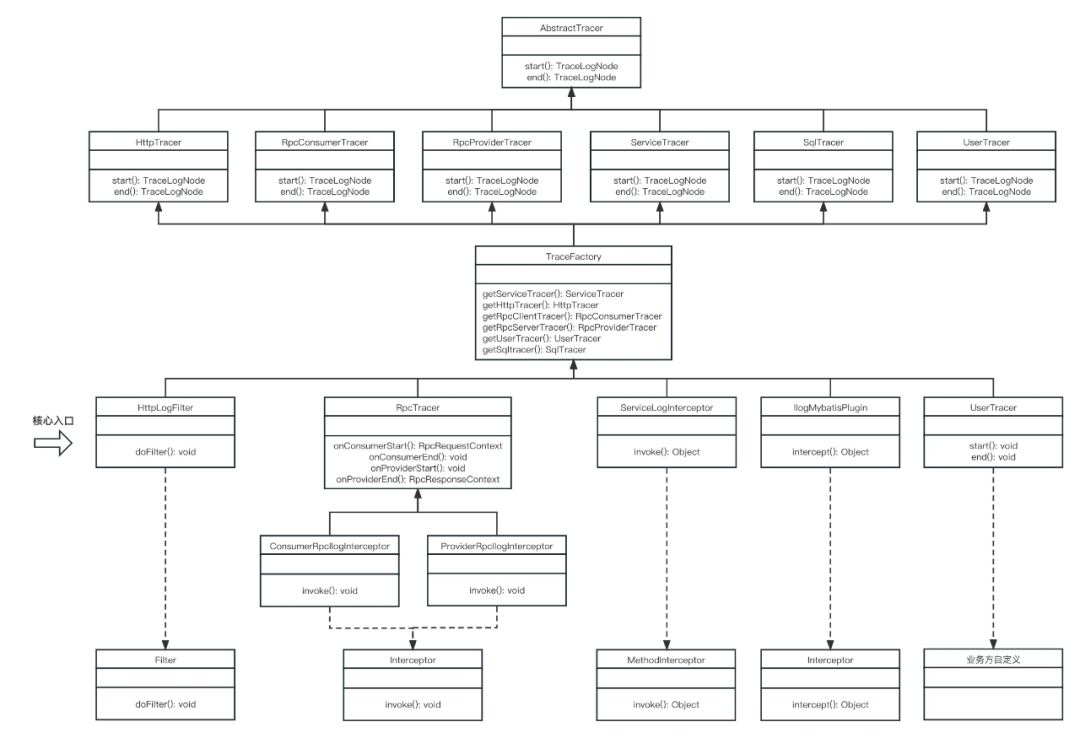
以mybatis為例,trace日志流核心攔截器實現類為IlogMybatisPlugin,實現ibatis Interceptor接口
核心代碼:
TraceFactory.getSqltracer().end(returnObj, className, methodName, realParams, dbType, sqlType, sql, sqlUrl)
在end方法中將SQL執行過程中產生的各類信息通過參數傳入,并組裝成SqlLogNode(繼承至通用日志節點LogNode)發布到隊列。
使用時需要業務方手動將插件注冊到SqlSessionFactory,以生效插件:
sqlSessionFactory.getConfiguration().addInterceptor(new IlogMybatisPlugin());
3.2.2 天眼minos日志采集
minos日志采集主要是借助百度自研的minos數據傳輸平臺,實現機器實例上的日志文件信息實時傳輸至目的地,常見傳輸目的地有Bigpipe、HDFS、AFS等;目前天眼主要是通過將minos采集到的日志發送到Bigpipe實現,并由后續的Bigpipe消費者統一消費和處理;同時針對日志來源為minos的日志在消費過程中增加了日志解析與轉換策略,確保采集到的日志格式和SDK方式生成的日志格式基本一致;
在日志采集過程中,天眼如何解決平臺化標識:
1、在產品線接入天眼時,天眼給對應產品線生成產品線唯一標識;
2、SDK接入方式下,產品線服務端通過系統變量配置產品線標識,SDK在運行過程中會自動讀取該變量值并設置到LogNode屬性中;
3、LogNode作為日志完整信息對象,在傳輸過程中最終存儲到ES,同時ES在建索引時為產品線唯一標識分配字段屬性;
4、產品線唯一標識貫穿整個分布式日志鏈路并和日志內容強綁定。
3.3 高并發數據傳輸和存儲
在ELK方案中,生成的日志信息直接發送給logstash進行傳輸,并寫入到es,整個過程基本為同步操作,并發性能完全依賴logstash服務端及ES服務端性能;
天眼則是通過異步方式解耦日志傳輸過程,以及在日志入口處引入Disruptor高性能隊列,并發性能直奔千萬級別;同時在Disruptor本地隊列之后再設計Bigpipe離線隊列,用來長效存儲和傳輸日志消息;以及引入兜底文件隊列BigQueue解決方案,處理在極少數異常情況下寫本地隊列或離線隊列失敗時的兜底保障,如下圖所示:
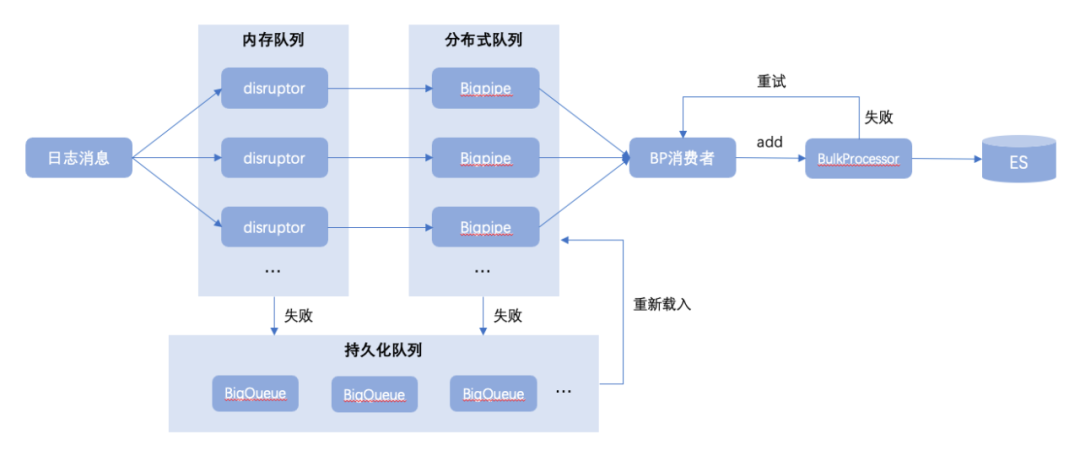 Disruptor是一個高性能的用于線程間消息處理的開源框架。Disruptor內部使用了RingBuffer,它是Disruptor的核心的數據結構。Disruptor隊列設計特性:固定大小數組:由于數組占用一塊連續的內存空間,可以利用CPU的緩存策略,預先讀取數組元素附近的元素;數組預填充:避免了垃圾回收代來的系統開銷;緩存行填充:解決偽共享問題;位操作:加快系統的計算速度;使用數組+系列號的這種方法最大限度的提高了速度。因為如果使用傳統的隊列的話,在多線程環境下對隊列頭和隊列尾的鎖競爭是一種很大的系統開銷。
Bigpipe是一個分布式中間件系統,支持Topic和Queue模型,不僅可以完成傳統消息隊列可以實現的諸如消息、命令的實時傳輸,也可以用于日志數據的實時傳輸。Bigpipe能夠幫助模塊間的通信實現解耦,并能保證消息的不丟不重;BigQueue是基于內存映射文件的大型、快速和持久隊列;
Disruptor是一個高性能的用于線程間消息處理的開源框架。Disruptor內部使用了RingBuffer,它是Disruptor的核心的數據結構。Disruptor隊列設計特性:固定大小數組:由于數組占用一塊連續的內存空間,可以利用CPU的緩存策略,預先讀取數組元素附近的元素;數組預填充:避免了垃圾回收代來的系統開銷;緩存行填充:解決偽共享問題;位操作:加快系統的計算速度;使用數組+系列號的這種方法最大限度的提高了速度。因為如果使用傳統的隊列的話,在多線程環境下對隊列頭和隊列尾的鎖競爭是一種很大的系統開銷。
Bigpipe是一個分布式中間件系統,支持Topic和Queue模型,不僅可以完成傳統消息隊列可以實現的諸如消息、命令的實時傳輸,也可以用于日志數據的實時傳輸。Bigpipe能夠幫助模塊間的通信實現解耦,并能保證消息的不丟不重;BigQueue是基于內存映射文件的大型、快速和持久隊列;1、快: 接近直接內存訪問的速度,enqueue和dequeue都接近于O(1)內存訪問。
2、大:隊列的總大小僅受可用磁盤空間的限制。
3、持久:隊列中的所有數據都持久保存在磁盤上,并且是抗崩潰的。
4、可靠:即使您的進程崩潰,操作系統也將負責保留生成的消息。
5、實時:生產者線程產生的消息將立即對消費者線程可見。
6、內存高效:自動分頁和交換算法,只有最近訪問的數據保留在內存中。
7、線程安全:多個線程可以同時入隊和出隊而不會損壞數據。
8、簡單輕量:目前源文件個數12個,庫jar不到30K。
在采集到日志事件后,進入傳輸過程中,天眼SDK中支持日志過濾規則策略匹配,針對命中策略的日志進行過濾,實現過程如下圖所示: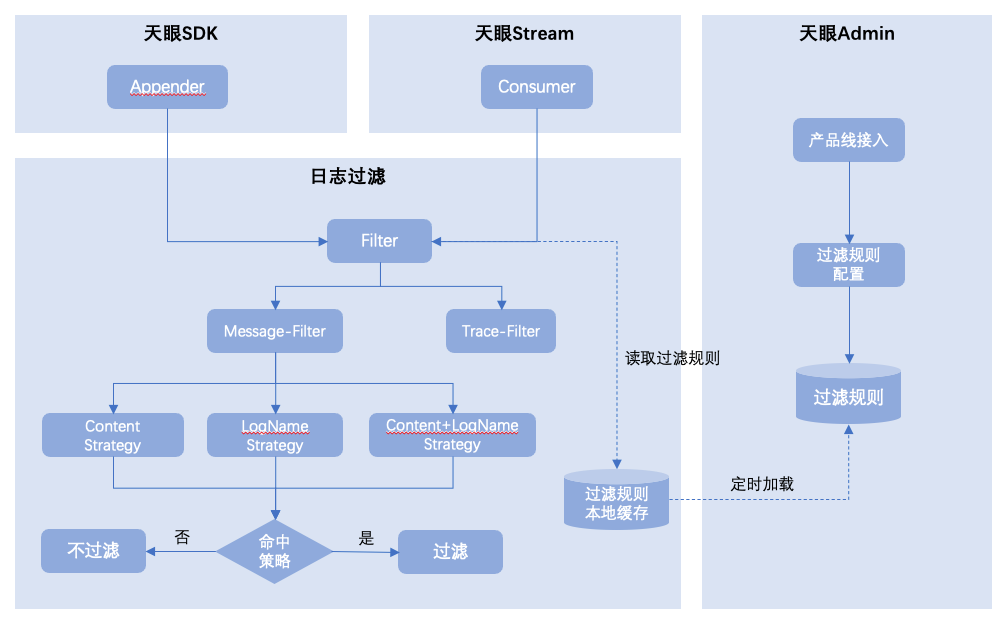
未命中過濾規則的日志消息事件將繼續發送至Bigpipe,至此日志生產階段即完成,后續通過天眼消費者模塊訂閱Bigpipe消費并批量推送至ES。
3.4天眼日志檢索
基于天眼鏈路最終存儲到ES的日志數據,天眼平臺提供了可視化日志檢索頁面,能夠根據產品線唯一標識(日志源ID)指定業務范圍進行檢索,同時支持各種檢索條件,效果如下圖所示:
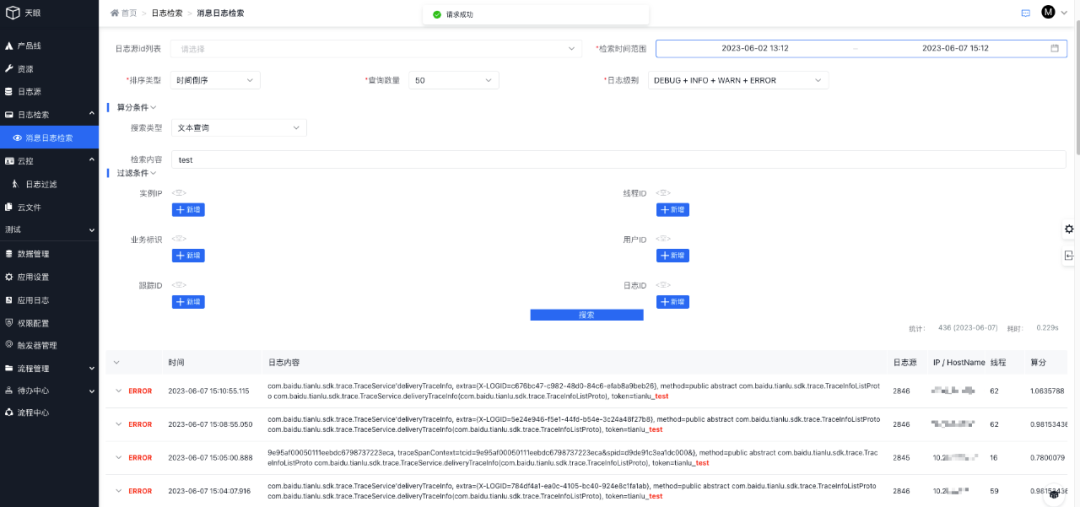
3.4.1 檢索條件詳解
日志源id列表:獲取日志源對應的日志
檢索時間范圍:日志的時間范圍
排序類型:日志的存入時間/日志存入的算分
查詢數量:查詢出多少數量的日志
日志級別:查詢什么級別的日志,如:DEBUG / INFO / WARN / ERROR
算分條件:支持五種算分查詢,文本查詢、等值查詢、短語查詢、前綴查詢、邏輯查詢;五選一

過濾條件:?只顯示符合過濾條件信息的日志

3.4.2 算分條件檢索詳細說明
支持五種算分查詢:文本查詢、等值查詢、短語查詢、前綴查詢、邏輯查詢。五選一
搜索內容字段:message、exception
"message": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 15000
}
},
"analyzer": "my_ik_max_word",
"search_analyzer": "my_ik_smart"
},
"exception": {
"type": "text",
"analyzer": "my_ik_max_word",
"search_analyzer": "my_ik_smart"
}
說明:
-
"analyzer": "my_ik_max_word":底層使用ik_max_word,message和exception信息在存儲是會以最細粒度拆詞進行存儲;
-
"search_analyzer": "my_ik_smart":底層使用ik_smart,在查詢內容是,會將查詢內容以最粗粒度拆分進行查詢。
3.4.2.1 文本查詢
底層實現原理
{
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "best_fields"
}
}]
}
}
}
天眼管理端對應圖
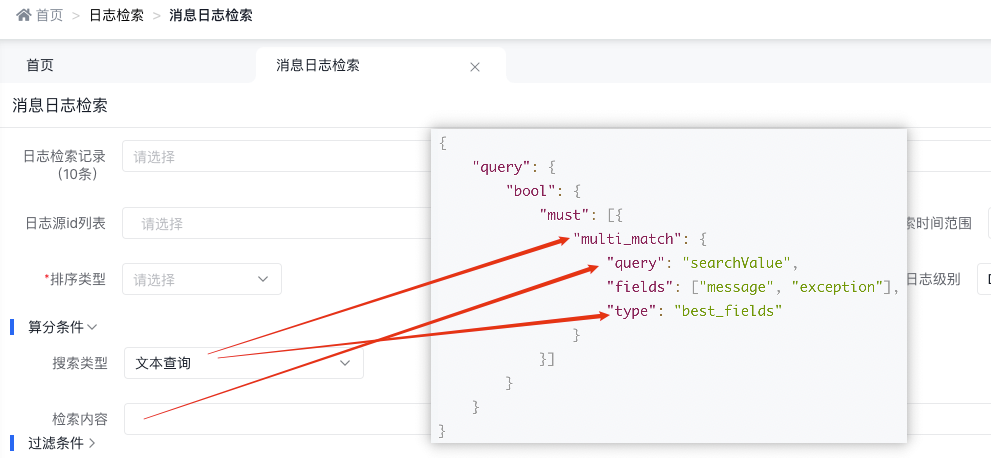
使用說明:
-
multi_match中的best_fields會將任何與查詢匹配的文檔作為結果返回,但是只使用最佳字段的 _score 評分作為評分結果返回
3.4.2.2 等值查詢
底層實現原理
{
"query": {
"bool": {
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "best_fields",
"analyzer": "keyword"
}
}]
}
}
}
天眼管理端對應圖
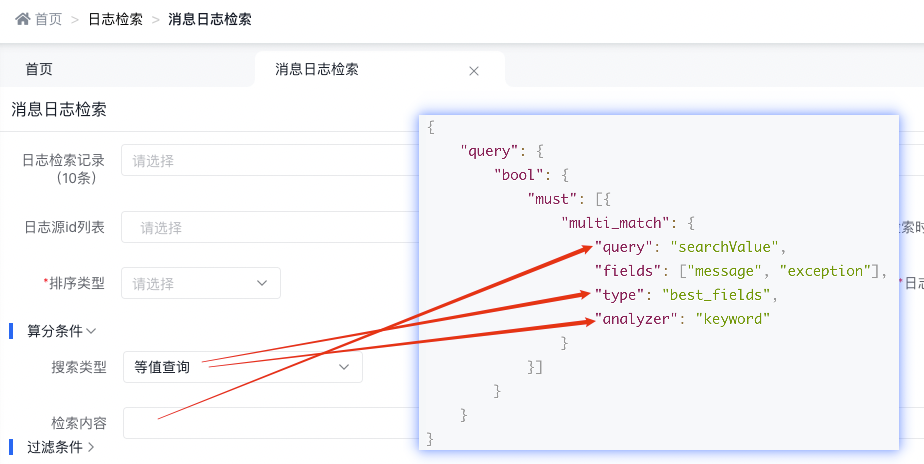
使用說明:
-
multi_match中的best_fields會將任何與查詢匹配的文檔作為結果返回,但是只使用最佳字段的 _score 評分作為評分結果返回
-
設置 analyzer 參數來定義查詢語句時對其中詞條執行的分析過程
-
KeywordAnalyzer - 不分詞,直接將輸入當做輸出
3.4.2.3 短語查詢
底層實現原理
{
"query": {
"bool": {
// 短語查詢
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "phrase",
"slop": 2
}
}]
}
}
}
天眼管理端對應圖
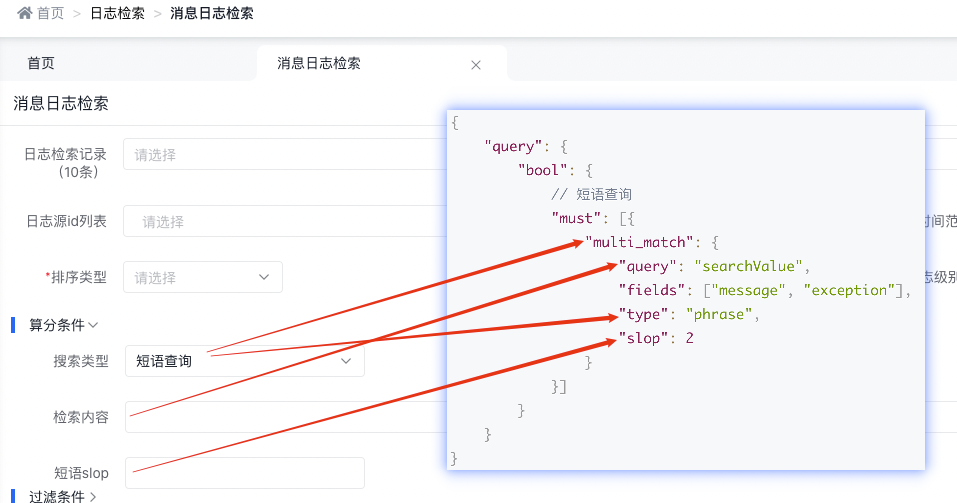
使用說明:
-
phrase在fields中的每個字段上均執行match_phrase查詢,并將最佳字段的 _score 作為結果返回
-
默認使用match_phrase時會精確匹配查詢的短語,需要全部單詞和順序要完全一樣,標點符號除外
-
slop指查詢詞條相隔多遠時仍然能將文檔視為匹配 什么是相隔多遠?意思是說為了讓查詢和文檔匹配你需要移動詞條多少次?以 "I like swimming and riding!" 的文檔為例,想匹配 "I like riding",只需要將 "riding" 詞條向前移動兩次,因此設置 slop 參數值為 2, 就可以匹配到。
3.4.2.4 前綴查詢
底層實現原理
{
"size": 50,
"query": {
"bool": {
// 前綴查詢
"must": [{
"multi_match": {
"query": "searchValue",
"fields": ["message", "exception"],
"type": "phrase_prefix",
"max_expansions": 2
}
}]
}
}
}
天眼管理端對應圖
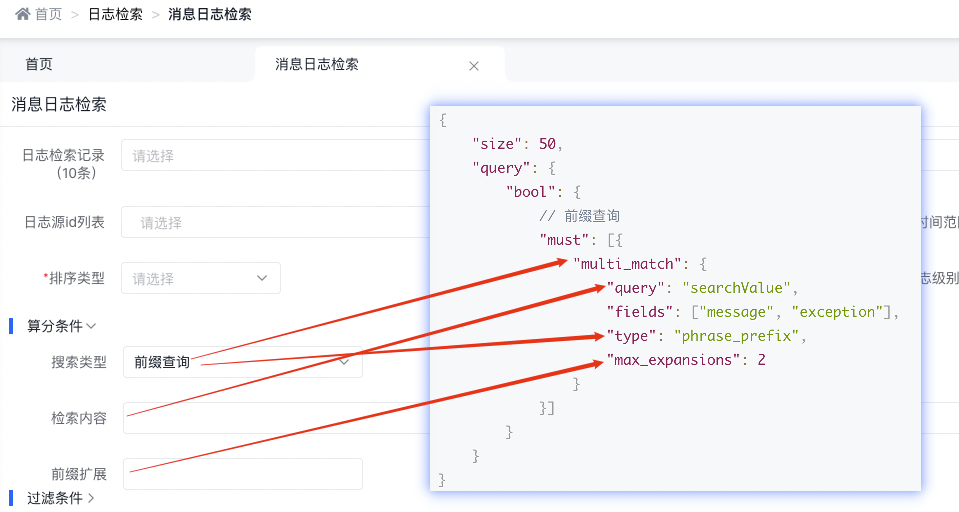
使用說明:
-
phrase_prefix在fields中的字段上均執行match_phrase_prefix查詢,并將每個字段的分數進行合并
-
match_phrase_prefix 和 match_phrase 用法是一樣的,區別就在于它允許對最后一個詞條前綴匹配,例如:查詢 I like sw 就能匹配到I like swimming and riding。
-
max_expansions 說的是參數 max_expansions 控制著可以與前綴匹配的詞的數量,默認值是 50。以 I like swi 查詢為例,它會先查找第一個與前綴 swi 匹配的詞,然后依次查找搜集與之匹配的詞(按字母順序),直到沒有更多可匹配的詞或當數量超過 max_expansions 時結束。
-
match_phrase_prefix 用起來非常方便,能夠實現輸入即搜索的效果,但是也會出現問題。假如說查詢 I like s 并且想要匹配 I like swimming ,結果是默認情況下它會搜索出前 50 個組合,如果前 50 個沒有 swimming ,那就不會顯示出結果。只能是用戶繼續輸入后面的字母才可能匹配出結果。
3.4.2.5 邏輯查詢
底層實現原理
{
"query": {
"bool": {
// 邏輯查詢
"must": [{
"simple_query_string": {
"query": "searchValue",
"fields": ["message", "exception"]
}
}]
}
}
}
天眼管理端對應圖:
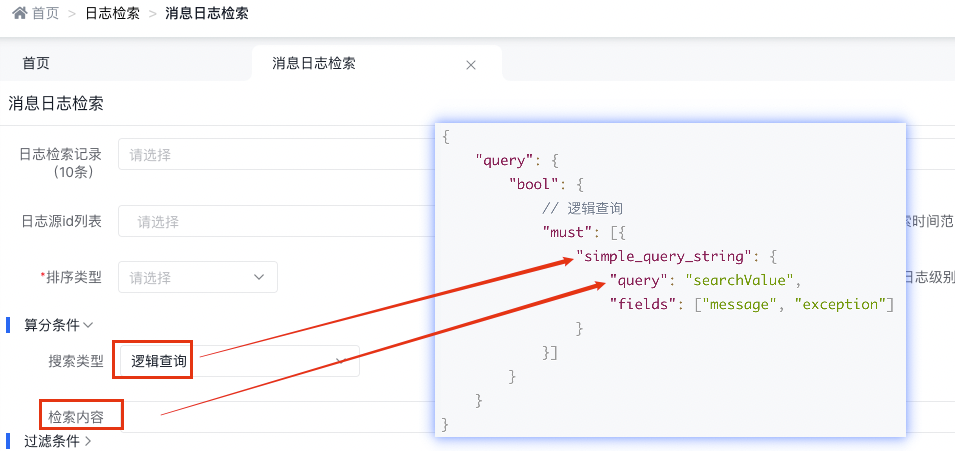
simple_query_string查詢支持以下操作符(默認是OR),用于解釋查詢字符串中的文本:
-
+AND
-
|OR
-
-非
-
"包裝許多標記以表示要搜索的短語
-
*在術語的末尾表示前綴查詢
-
(and)表示優先級
-
~N在一個單詞之后表示編輯距離(模糊)
-
~N在短語后面表示溢出量
官方使用文檔:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-simple-query-string-query.html
使用示例解釋:
GET/_search
{
"query": {
"simple_query_string": {
"fields": [ "content" ],
"query": "foo bar -baz"
}
}
這個搜索的目的是只返回包含foo或bar但不包含baz的文檔。然而,由于使用了OR的default_operator,這個搜索實際上返回了包含foo或bar的文檔以及不包含baz的文檔。要按預期返回文檔,將查詢字符串更改為foo bar +-baz。
3.5日志資源隔離
在龐大的企業級軟件生產環境下,業務系統會產生海量日志數據。一方面,隨著業務方的不斷增加,日志系統有限的資源會被耗盡,導致服務不穩定甚至宕機。另一方面,不同業務的日志量級、QPS 存在差異,極端情況下不同業務方會對共享資源進行競爭,導致部分業務的日志查詢延時變高。這對日志系統的資源管理帶來了挑戰。
天眼平臺采用資源隔離的方式解決此問題,來為業務提供實時、高效、安全的存儲與查詢服務。
資源隔離主要圍繞著日志的傳輸資源與日志的存儲資源進行。業務方在接入天眼系統時,可以根據業務需要在平臺交互界面,進行傳輸資源與存儲資源的隔離配置,這種隔離資源的配置方式避免了共享資源競爭導致的日志延遲增加與潛在的日志丟失問題。
具體的隔離實現方案如圖 3.5.1 所示,主要包括以下步驟:
1、業務方生產日志:如 3.2 介紹到的,業務方運行時產生的日志可以通過 SDK 或 minos 的方式將日志傳輸至分布式隊列 BP 中;
2、天眼平臺訂閱日志:在業務方通過天眼平臺進行 ES、BP 資源的配置之后,配置監聽器會監測到變更內容,再根據配置的變更類型管理日志訂閱器、分發器的生命周期,包括ES 客戶端、BP 客戶端的創建與銷毀;
3、平臺內部日志處理:日志訂閱器通過 BP 客戶端收到業務方的日志后,首先會采用 3.3 中提到的業務方過濾規則進行過濾攔截,再將日志轉換為事件放入綁定的內存通道中;
4、天眼平臺分發日志:日志分發器會不斷從綁定的內存通道中拉取日志事件,并通過 ES 客戶端對日志進行存儲,如果存儲失敗則會觸發相應 backoff 策略,例如異常行為記錄;
5、業務方日志查詢:日志存儲至 ES 集群之后,業務方可以通過平臺界面便捷地進行日志查詢。
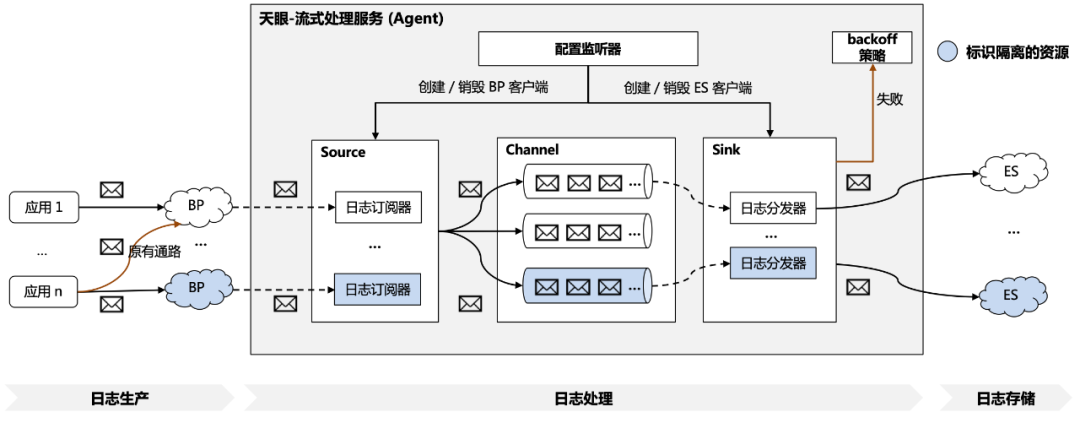
△3.5.1 天眼-資源隔離方案
可見在復雜的多應用場景下,隔離資源機制是一種高效管理日志系統資源的方式。天眼日志系統提供了靈活的資源配置來避免資源浪費,提供了共享資源的隔離來降低業務方日志查詢的延遲、提升日志查詢的安全性,進而推動業務的增長和運營效率。
3.6日志動態清理與存儲降級
隨著業務的長期運行與發展,日志量級也在不斷增加。一方面,針對近期產生的日志,業務方有迫切的查詢需求。針對產生較久的日志,迫于監管與審計要求也有低頻率訪問的訴求。如何在成本可控并且保證平臺穩定的前提下,維護這些海量日志并提供查詢服務對日志系統而言也是一個挑戰。
天眼平臺通過資源清理機制和日志存儲降級機制來解決這個問題。
資源清理機制主要用作 ES 集群的索引清理。隨著日志量的增加,集群的資源占用率也在增加,在極端情況下,過高的磁盤與內存占用率會導致 ES 服務的性能下降,甚至服務的宕機。資源清理機制會定期查詢 ES 集群的資源占用情況,一旦集群的磁盤資源超過業務方設定的閾值,會優先清理最舊的日志,直到資源占用率恢復正常水平。
存儲降級機制主要用作 ES 集群的索引備份與恢復。將日志長期存儲在昂貴的 ES 集群中是一種資源浪費,也為日志系統增加了額外的開銷。存儲降級機制會定期對 ES 集群進行快照,然后將快照轉存到更低開銷的大對象存儲服務(BOS)中,轉存之后的快照有 180 天的有效期以應對審查與監管。當業務方需要查詢降級存儲后的日志時,只需要從大對象存儲服務中拉取快照,再恢復到 ES 集群以提供查詢能力。
具體的資源清理機制與存儲降級機制如圖 3.6.1 所示,主要包括以下步驟:
1、集群狀態查詢:資源清理任務通過定期查詢集群信息的方式監測資源占用率,當資源占用率超過業務方設定的閾值時會觸發資源清理;
2、集群索引清理:通過查詢索引信息并進行資源占用情況計算,再根據時間倒序刪除依次最舊的索引,直到滿足設定的閾值;
3、集群索引備份:存儲降級任務會定期對集群進行快照請求,然后將快照文件轉存到低開銷的大文件存儲服務中完成存儲的降級;
4、集群索引恢復:在業務方需要查詢降級存儲后的日志時,服務會將快照文件從大文件存儲服務中拉取目標快照,再通過快照恢復請求對快照進行恢復,以提供業務方查詢。
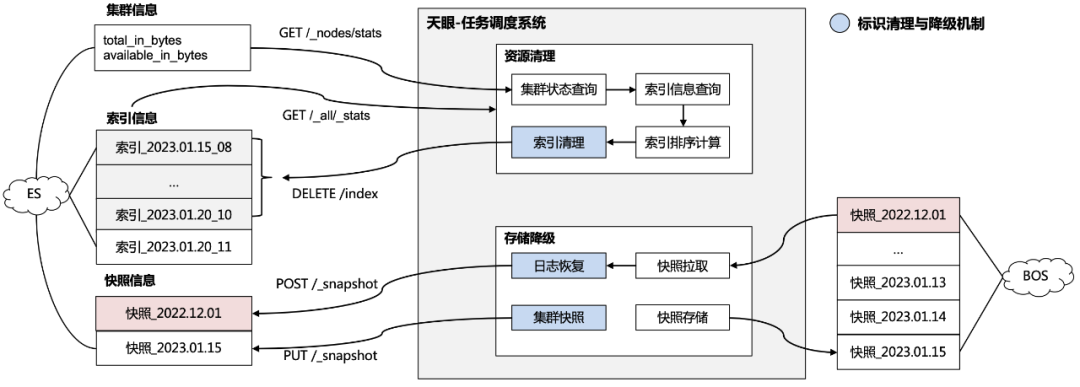
△3.6.1天眼-日志動態清理與存儲降級方案
可見在面對海量日志的存儲與查詢,通過資源清理機制可以防止集群資源過載同時提升日志檢索效率,通過存儲降級機制可以提升資源利用率同時確保審計的合規性,從而在業務高速增長使用的同時保證日志系統的健壯性。
3.7最佳實踐
基于前面提到的天眼平臺設計思想,結合其中部分能力展開介紹天眼在運維管理方面的實踐。
3.7.1 天眼平臺化實踐
天眼通過抽象產品線概念,針對不同的接入方提供產品線接入流程,為業務生成產品線唯一標識并與業務日志綁定;產品線相關流程如下:
1、產品線日志源申請流程
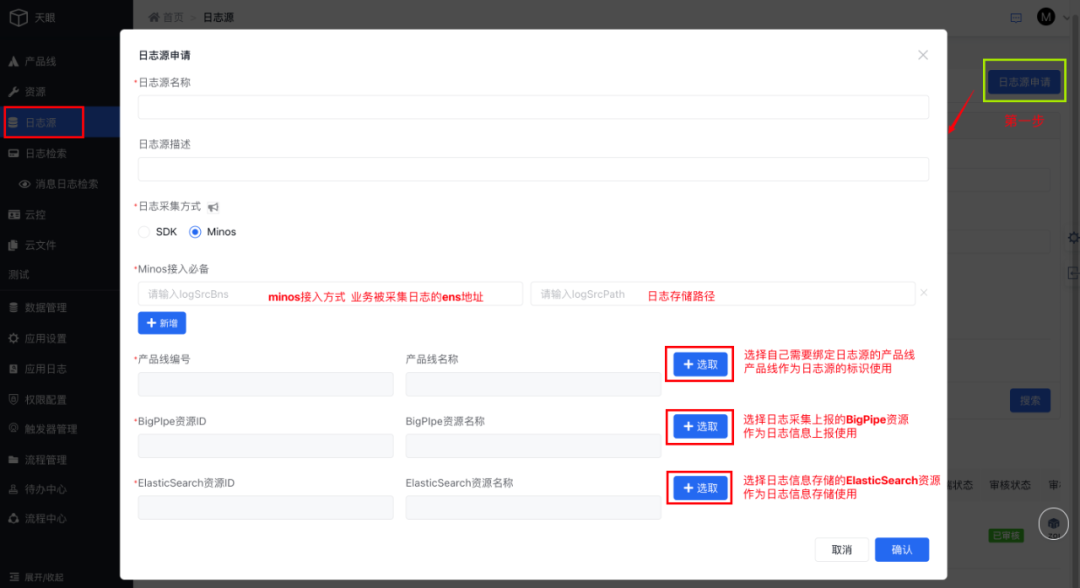
支持產品線選擇日志采集方式包含SDK、Minos兩種方式,選擇minos接入時,bns與日志存儲路徑必選,方便系統根據配置自動執行日志采集。
同時在Bigpipe資源與ES資源方面,平臺支持多種資源隔離獨立使用,不同的產品線可以配置各自獨有的傳輸和存儲資源,保障數據安全性和穩定性。
2、日志源申請后,需要管理員審核后才能進行使用(申請后無需操作,僅需等待管理員通過審核后,進行SDK接入)

access_key的值查看權限:僅日志源綁定產品線的經理及接口人可查,access_key將作為產品線接入天眼鑒權的關鍵依據。
3.7.2 日志過濾實踐
產品線接口人可以基于自身產品線新增日志過濾規則配置,配置的規則將自動生效于日志采集傳輸流程中:
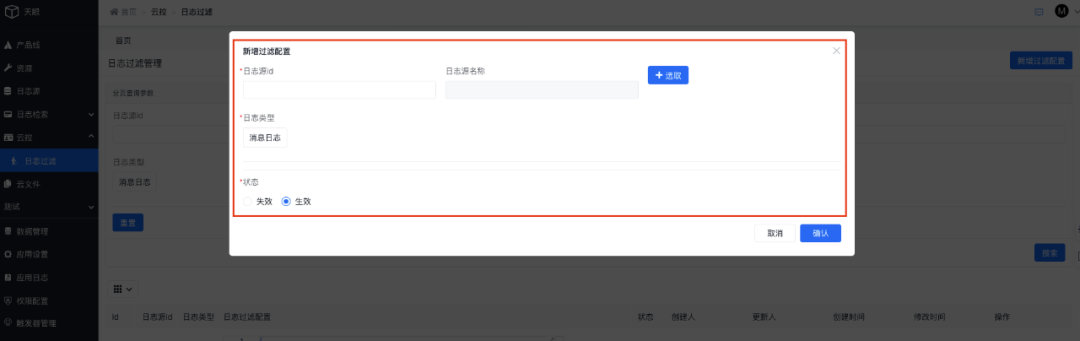
選擇消息日志后將彈出詳細過濾規則配置菜單,當前系統共支持三種過濾規則,分別是按日志內容、按日志名稱、按日志內容和日志名稱組合三種方式:
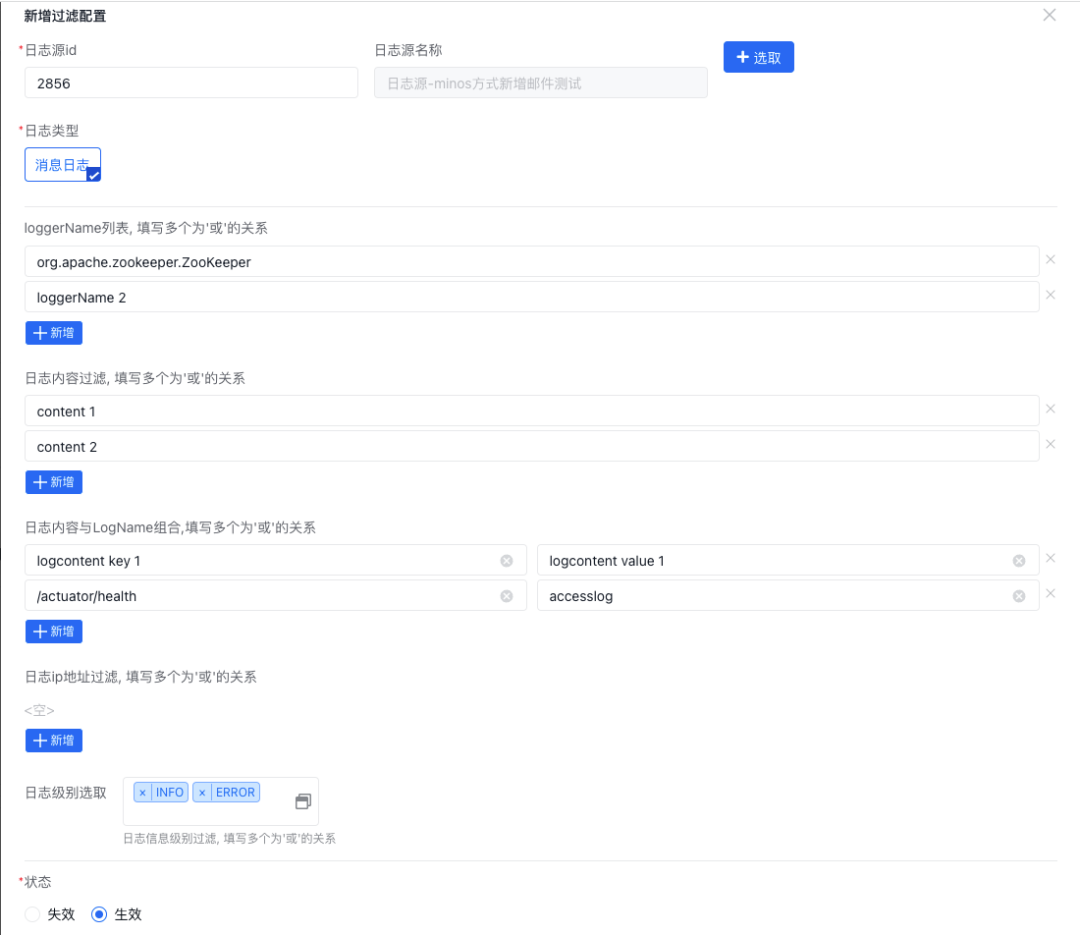
過濾規則配置完成后可以在列表管理每條規則:
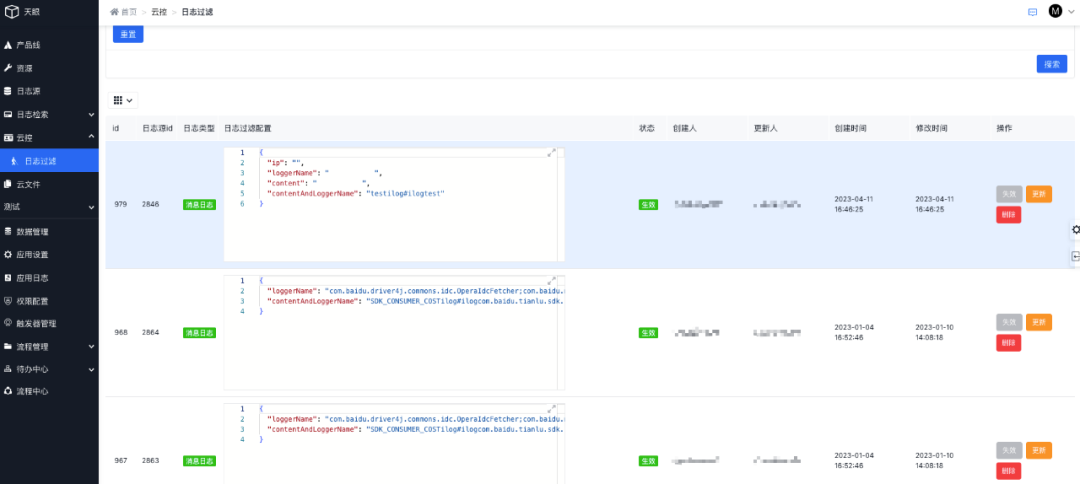
GEEK TALK
04
思考與總結
隨著分布式業務系統的日益復雜,為業務方提供高效、低延遲、高性能的日志服務系統顯得尤為重要。本文介紹了天眼平臺是如何進行日志采集、傳輸并支持檢索的,此外還通過支持日志的資源隔離,解耦各業務方的日志通路和存儲,從而實現業務日志的高效查詢和業務問題的高效定位。此外通過對日志進行監控可以主動發現系統問題,并通過告警日志的trace_id快速定位問題,從而提升問題發現導解決的效率。
隨著大模型技術的不斷發展,我們也通過大模型進行一些業務迭代,進而提升業務檢索和排查效率。例如:我們可以直接詢問,今天有幾筆異常核銷訂單;訂單7539661906核銷異常原因是什么等等。通過與大模型的結合,我們縮短了業務方問題排查定位的路徑,提升了業務運維效率和交互體驗。后續我們也將不斷與大模型進行深入打磨和持續深耕,持續沉淀和輸出相關的通用方案。
-
服務器
+關注
關注
12文章
9247瀏覽量
85731 -
大模型
+關注
關注
2文章
2499瀏覽量
2909
原文標題:如何設計一個高效的分布式日志服務平臺
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
開放分布式追蹤(OpenTracing)入門與 Jaeger 實現
一行代碼,保障分布式事務一致性—GTS:微服務架構下分布式事務解決方案
基于分布式調用鏈監控技術的全息排查功能
HDC2021技術分論壇:如何高效完成HarmonyOS分布式應用測試?
如何高效完成HarmonyOS分布式應用測試?
【學習打卡】OpenHarmony的分布式任務調度
網絡取證日志分布式安全管理
區塊鏈分布式身份證核驗服務平臺聯核云VIS介紹
分享一個有趣的鴻蒙分布式小游戲






 工商網監
工商網監
評論