 AI大模型網絡如何搭建
AI大模型網絡如何搭建
2023年,以ChatGPT為代表的AIGC大模型全面崛起,成為了整個社會關注的焦點。 大模型表現出了強悍的自然語言理解能力,刷新了人們對AI的認知,也掀起了新一輪的“算力軍備競賽”。 大家都知道,AIGC大模型的入局門檻是很高的。玩AI的三大必備要素——算力、算法和數據,每一個都意味著巨大的投入。 以算力為例。ChatGPT的技術底座,是基于微調后的GPT3.5大模型,參數量多達1750億個。為了完成這個大模型的訓練,微軟專門建設了一個AI超算系統,投入了1萬個V100 GPU,總算力消耗約3640 PF-days(即假如每秒計算一千萬億次,需要計算3640天)。 業內頭部廠商近期推出的大模型,參數量規模更是達到萬億級別,需要的GPU更多,消耗的算力更大。 這些數量龐大的GPU,一定需要通過算力集群的方式,協同完成計算任務。這就意味著,需要一張超高性能、超強可靠的網絡,才能把海量GPU聯接起來,形成超級計算集群。 那么,問題來了,這張網絡,到底該如何搭建呢?
高性能網絡的挑戰 想要建設一張承載AIGC大模型的網絡,需要考慮的因素非常多。 首先,是網絡規模。 剛才我們也提到,AI訓練都是10000個GPU起步,也有的達到十萬級。從架構上,目標網絡就必須hold得住這么多的計算節點。而且,在節點增加的同時,集群算力盡量線性提升,不能引入過高的通信開銷,損失算力。 其次,是網絡帶寬。 超高性能的GPU,加上千億、萬億參數的訓練規模,使得計算節點之間的通信量,達到了百GB量級。再加上各種并行模式、加速框架的引入,節點之間的通道帶寬需求會更高。 傳統數據中心通用的100Gbps帶寬接入,根本滿足不了這個需求。我們的目標網絡,接入帶寬必須升級到800Gbps、1.6Tbps,甚至更高。 第三,流量調控。 傳統的網絡架構,在應對AI大模型訓練產生的數據流時,存在缺陷。所以,目標網絡需要在架構上做文章,更好地控制數據流路徑,讓節點和通道的流量更均衡,避免發生擁塞。 第四,協議升級。 網絡協議是網絡工作的行為準則。它的好壞,直接決定了網絡的性能、效率和延遲。 傳統數據中心的TCP/IP協議,早已已無法滿足高性能網絡的大帶寬、低時延需求。性能更強的IB(InfiniBand)協議、RDMA協議,已然成為主流。有實力的廠家,還會基于自家硬件設備,自研更高效的協議。 第五,運維簡化。 這就不用多說了。超大規模的網絡,如果還是采用傳統運維,不僅效率跟不上,還會導致更長的故障恢復周期,損失算力,損失資金。 目前,行業里的“大模頭”們,都會根據自己技術和資金實力,選擇商用網絡組網,或者自研網絡協議。 大家心里很清楚,想要贏得這場比賽,除了算力芯片足夠強之外,網絡的性能表現是至關重要的。網絡越強,集群的算力提升就越大,完成模型訓練的時間就越短,成本也就越低。
星脈網絡,鵝廠的算力集群殺手锏 對于AI大模型這場熱潮,騰訊當然不會缺席。他們推出了業界領先的高性能計算網絡架構——星脈。 騰訊深耕互聯網行業20多年,從QQ到微信,他們的超大規模業務承載能力,可以說是行業頂尖的。在網絡技術的理解和駕馭能力上,也是世界領先水平。而星脈,則是他們多年技術研究的精髓,是真正的殺手锏。 根據實測,星脈實現了AI大模型通信性能的10倍提升、GPU利用率提升40%、通信時延降低40%。 基于全自研的網絡硬件平臺,星脈可以實現網絡建設成本降低30%,模型訓練成本節省30%~60%。 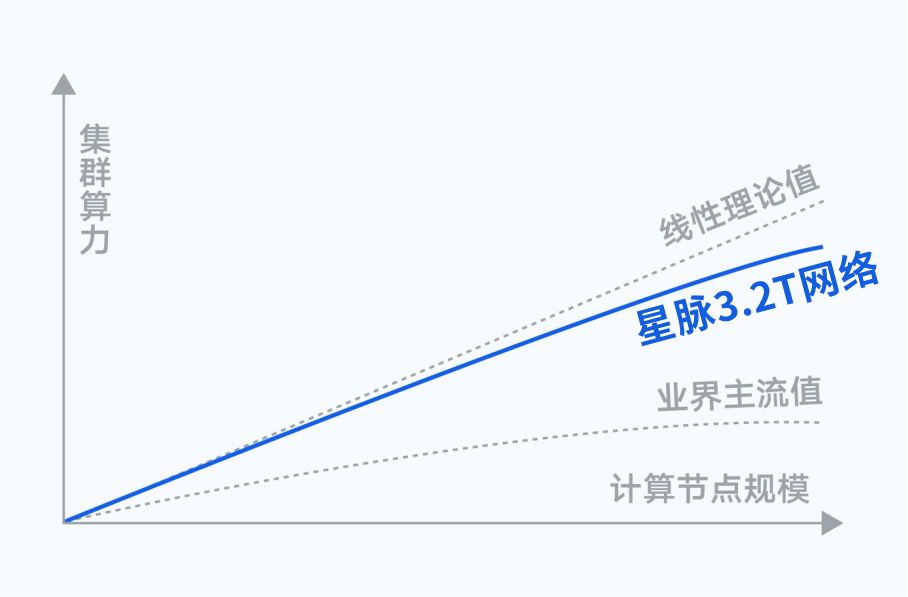 星脈網絡的算力效率,遠高于業界主流值 ? 接下來,我們不妨深入解讀一下,星脈到底采用了哪些黑科技。在前面所提到的幾項挑戰上,騰訊團隊又是如何應對的。 ?
星脈網絡的算力效率,遠高于業界主流值 ? 接下來,我們不妨深入解讀一下,星脈到底采用了哪些黑科技。在前面所提到的幾項挑戰上,騰訊團隊又是如何應對的。 ?
網絡規模
在組網架構上,星脈網絡采用無阻塞胖樹(Fat-Tree)拓撲,分為Block-Pod-Cluster三級。 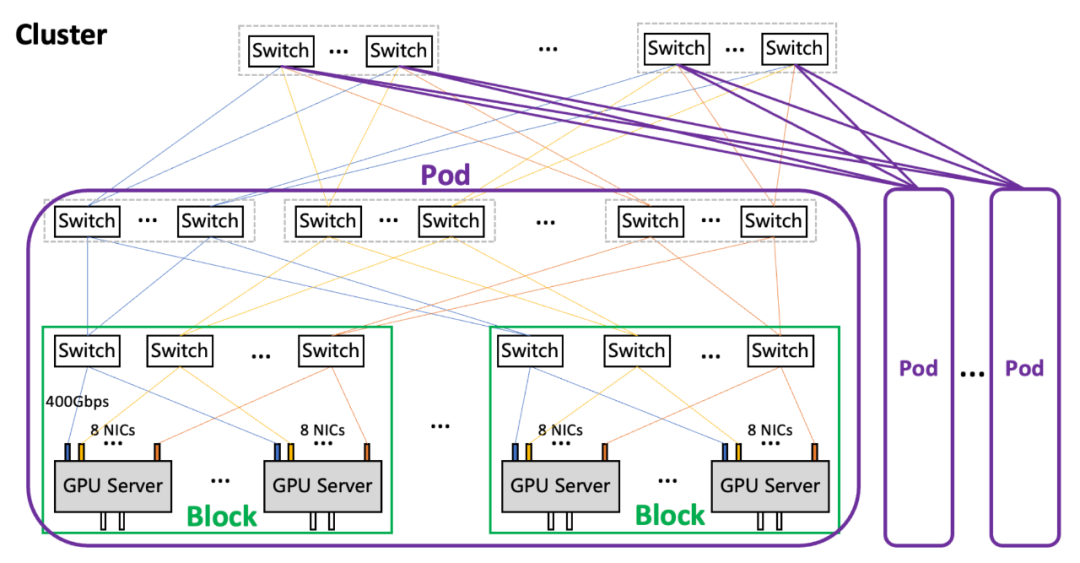 星脈網絡的架構 ? Block是最小單元,包括256個GPU。 ? Pod是典型集群規模,包括16~64個Block,也就是4096~16384個GPU。 ? 多個Block可以組成Cluster。1個Cluster最大支持16個Pod,也就是65536~262144個GPU。 ? 26萬個GPU,這個規模完全能夠滿足目前的訓練需求。 ?
星脈網絡的架構 ? Block是最小單元,包括256個GPU。 ? Pod是典型集群規模,包括16~64個Block,也就是4096~16384個GPU。 ? 多個Block可以組成Cluster。1個Cluster最大支持16個Pod,也就是65536~262144個GPU。 ? 26萬個GPU,這個規模完全能夠滿足目前的訓練需求。 ?
網絡帶寬
騰訊星脈網絡為每個計算節點提供了3.2T的超高通信帶寬。 單個服務器(帶有8個GPU)就是一個計算節點。每個服務器有8塊RoCE網卡。每塊網卡的接口速率是400Gbps。 RoCE,是RDMA over Converged Ethernet(基于聚合以太網的RDMA)。RDMA(遠程直接GPU通信訪問)我們以前介紹過很多次。它允許計算節點之間直接通過內存進行數據傳輸,無需操作系統內核和CPU的參與,能夠大幅減小CPU負荷,降低延遲,提高吞吐量。 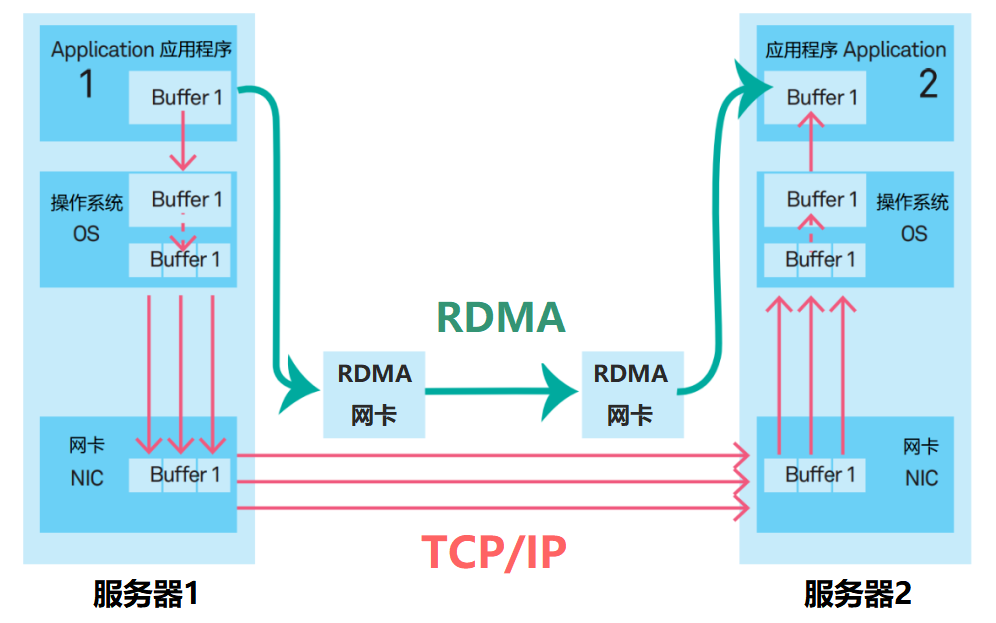 ? 大帶寬帶來的優勢是非常顯著的。對于AllReduce和All-to-All這兩種典型通信模式,在不同集群規模下,1.6Tbps超帶寬都會帶來10倍以上的通信性能提升(相比100Gbps帶寬)。 ? 以AllReduce模式、64 GPU規模為例,采用1.6Tbps超帶寬網絡,將使得AllReduce的耗時大幅縮短14倍,通信占比從35%減少到3.7%,最終使得單次迭代的訓練耗時減少32%。從集群算力的角度來看,相當于用同樣的計算資源,系統算力卻提升48%。 ?
? 大帶寬帶來的優勢是非常顯著的。對于AllReduce和All-to-All這兩種典型通信模式,在不同集群規模下,1.6Tbps超帶寬都會帶來10倍以上的通信性能提升(相比100Gbps帶寬)。 ? 以AllReduce模式、64 GPU規模為例,采用1.6Tbps超帶寬網絡,將使得AllReduce的耗時大幅縮短14倍,通信占比從35%減少到3.7%,最終使得單次迭代的訓練耗時減少32%。從集群算力的角度來看,相當于用同樣的計算資源,系統算力卻提升48%。 ?
流量調控
為了提升集群的通信效率,星脈網絡對通信流量路徑進行了優化,引入了“多軌道流量聚合架構”。 該架構將不同服務器上位于相同位置的網卡,都歸屬于同一個ToR switch(機柜頂部的匯聚交換機)。整個計算網絡平面,從物理上被劃分為8個獨立并行的軌道平面。 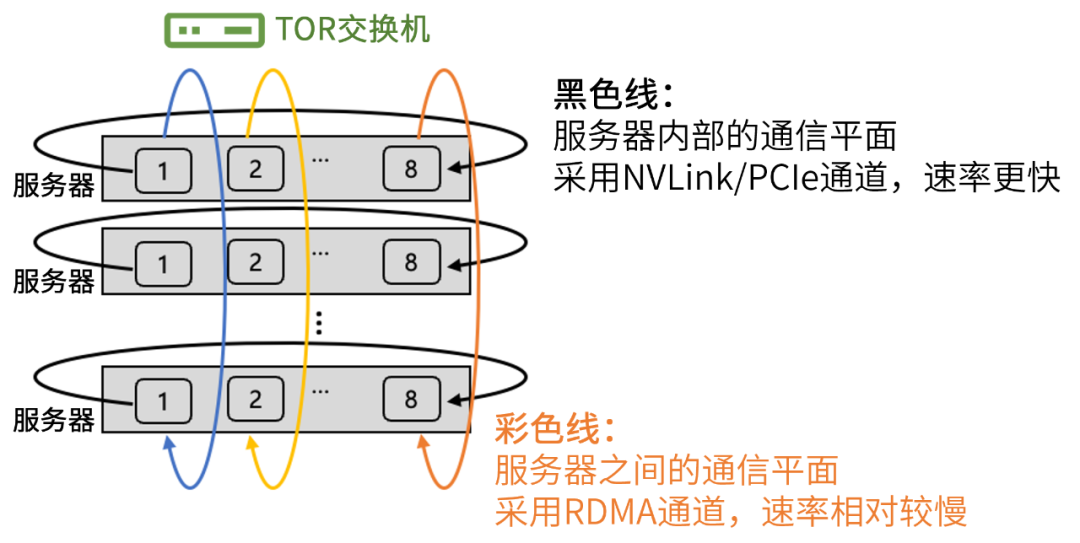 ? 在工作時,GPU之間的數據,可以用多個軌道并行傳輸加速。并且,大部分流量,都聚合在軌道平面內傳輸(只經過一級 ToR switch)。只有小部分流量,會跨軌道平面傳輸(需要經過二級 switch)。這大幅減輕了網絡壓力。 ? 星脈網絡還采用了“異構網絡自適應通信技術”。 在集群中,GPU之間的通信包括機間網絡(網卡+交換機)與機內網絡( NVLink/NVSwitch 網絡、PCIe 總線網絡)。 星脈網絡將機間、機內兩種網絡同時利用起來,實現了異構網絡之間的聯合通信優化。 例如,在All-to-All通信模式時,每個GPU都會和其它服務器的不同GPU通信。
? 在工作時,GPU之間的數據,可以用多個軌道并行傳輸加速。并且,大部分流量,都聚合在軌道平面內傳輸(只經過一級 ToR switch)。只有小部分流量,會跨軌道平面傳輸(需要經過二級 switch)。這大幅減輕了網絡壓力。 ? 星脈網絡還采用了“異構網絡自適應通信技術”。 在集群中,GPU之間的通信包括機間網絡(網卡+交換機)與機內網絡( NVLink/NVSwitch 網絡、PCIe 總線網絡)。 星脈網絡將機間、機內兩種網絡同時利用起來,實現了異構網絡之間的聯合通信優化。 例如,在All-to-All通信模式時,每個GPU都會和其它服務器的不同GPU通信。 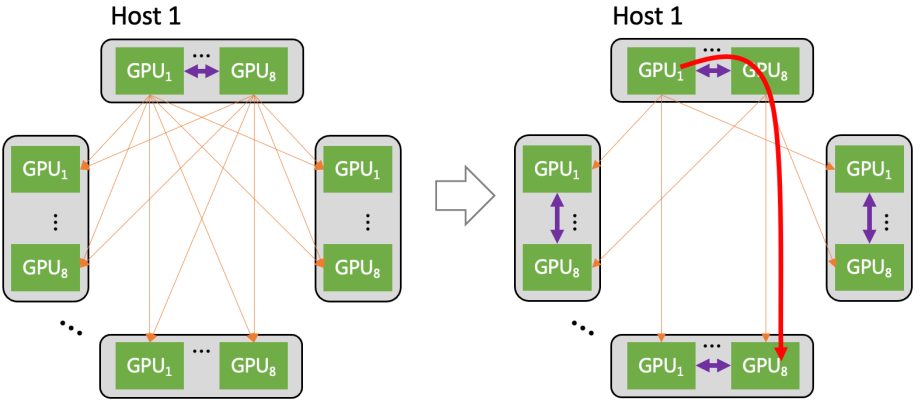 ? 基于異構網絡自適應通信技術,不同服務器上相同位置的GPU,在同一軌道平面,仍然走機間網絡通信。 ? 但是,要去往不同位置的GPU(比如host1上的GPU1,需要向其它host上的GPU8 送數據),則先通過機內網絡,轉發到host1上的GPU8上,然后通過機間網絡,來完成通信。 ? 這樣一來,機間網絡的流量,大部分都聚合在軌道內傳輸(只經過一級 ToR switch)。機間網絡的流量大幅減少,沖擊概率也明顯下降,從而提供了整網性能。 ? 根據實測,異構網絡通信在大規模All-to-All場景下,對中小數據包的傳輸性能提升在30%左右。 ?
? 基于異構網絡自適應通信技術,不同服務器上相同位置的GPU,在同一軌道平面,仍然走機間網絡通信。 ? 但是,要去往不同位置的GPU(比如host1上的GPU1,需要向其它host上的GPU8 送數據),則先通過機內網絡,轉發到host1上的GPU8上,然后通過機間網絡,來完成通信。 ? 這樣一來,機間網絡的流量,大部分都聚合在軌道內傳輸(只經過一級 ToR switch)。機間網絡的流量大幅減少,沖擊概率也明顯下降,從而提供了整網性能。 ? 根據實測,異構網絡通信在大規模All-to-All場景下,對中小數據包的傳輸性能提升在30%左右。 ?
協議升級
星脈網絡采用的“自研端網協同協議TiTa”,可以提供更高的網絡通信性能,非常適合大規模參數模型訓練。 TiTa協議內嵌擁塞控制算法,可以實時監控網絡狀態并進行通信優化。它就好比是一個智能交通管理系統,可以讓網絡上的數據傳輸更加通暢。 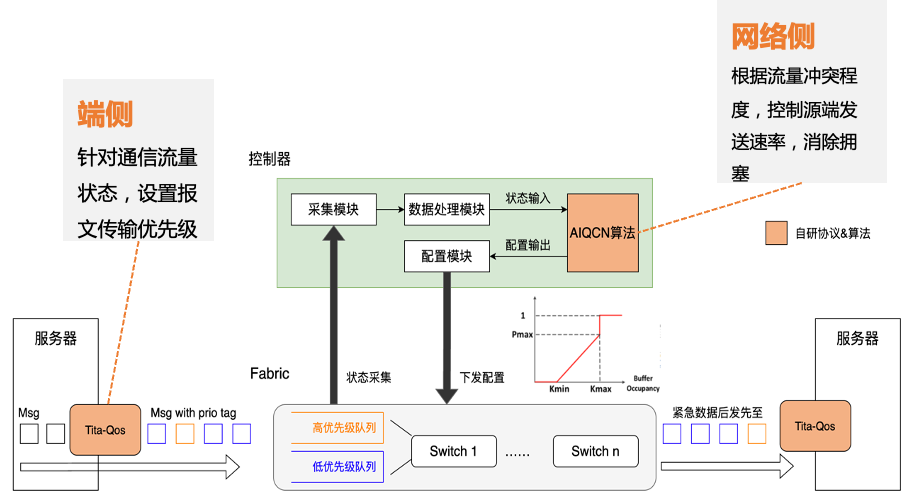 TiTa協議的處理方式 ? 面對定制設計的高性能組網架構,業界開源的GPU集合通信庫(例如NCCL)并不能將網絡的通信性能發揮到極致。為此,騰訊推出了“高性能集合通信庫TCCL(Tencent Collective Communication Library)”。 TCCL就像一個智能導航系統。它在網卡設備管理、全局網絡路由、拓撲感知親和性調度、網絡故障自動告警等方面進行了深度定制,對網絡了如指掌,讓流量路徑更加合理。 例如,從GPU A到GPU B,原來需要經過9個路口。有了TCCL導航之后,只需要走4個路口,提升了效率。 根據實測,在AllReduce/AllGather/ReduceScatter等常用通信模式下,TCCL能給星脈網絡帶來40%左右的通信性能提升。
TiTa協議的處理方式 ? 面對定制設計的高性能組網架構,業界開源的GPU集合通信庫(例如NCCL)并不能將網絡的通信性能發揮到極致。為此,騰訊推出了“高性能集合通信庫TCCL(Tencent Collective Communication Library)”。 TCCL就像一個智能導航系統。它在網卡設備管理、全局網絡路由、拓撲感知親和性調度、網絡故障自動告警等方面進行了深度定制,對網絡了如指掌,讓流量路徑更加合理。 例如,從GPU A到GPU B,原來需要經過9個路口。有了TCCL導航之后,只需要走4個路口,提升了效率。 根據實測,在AllReduce/AllGather/ReduceScatter等常用通信模式下,TCCL能給星脈網絡帶來40%左右的通信性能提升。
部署和運維簡化
算力集群網絡越龐大,它的部署和維護難度也就越大。 為了提升星脈網絡的可靠性,騰訊自研了一套全棧網絡運營系統,實現了“端網部署一體化”、“一鍵故障定位”、“業務無感秒級網絡自愈”,對網絡進行全方位保駕護航。 先看看“端網部署一體化”。 部署一直都是高性能網絡的痛點。在星脈網絡之前,根據統計,90%的高性能網絡故障問題,是因為配置錯誤導致。原因很簡單,網卡的配置套餐太多(取決于架構版本、業務類型和網卡類型),人為操作很難保證不出錯。 騰訊的解決方法,是將配置過程自動化。 他們通過API的方式,實現單臺/多臺交換機的并行部署能力。 在正式部署前,系統會自動對基礎網絡環境進行校驗,看看上級交換機的配置是否合理等。 然后,識別外部因素,自動選擇配置模板。 配置完成后,為了保證交付質量,運營平臺還會進行自動化驗收,包括一系列的性能和可靠性測試。  ? 所有工作完成后,系統才會進入交付狀態。 ? 根據數據統計,基于端網一體部署能力,大模型訓練系統的整體部署時間從19天縮減到4.5天,并保證了基礎配置100%準確。 ? 再看看運維階段的“一鍵故障定位”。 星脈網絡具有端網高度協同的特點,增加了端側的運營能力。運營平臺通過數據采集模塊,獲取端側服務器和網絡側交換機的數據,聯動網管拓撲信息,可以做到快速診斷與自動化檢查。 一鍵故障定位,可以快速定界問題方向,精準推送到對應團隊的運營人員(網絡or業務),減少溝通成本,劃分責任界限。而且,它還有利于快速定位問題根因,并給出解決方案。 最后,是“業務無感秒級網絡自愈”。 在網絡運行的過程中,故障是無法避免的。 為了將故障自愈時間縮短到極致,騰訊推出了秒級故障自愈產品——“HASH DODGING”。 這是一種基于Hash偏移算法的網絡相對路徑控制方法。即,終端僅需修改數據包頭特定字段(如IP頭TOS字段)的值,即可使得修改后的包傳輸路徑與修改前路徑無公共節點。 在網絡數據平面發生故障(如靜默丟包、路由黑洞)時,該方案可以幫助TCP快速繞過故障點,不會產生對標準拓撲及特定源端口號的依賴。
? 所有工作完成后,系統才會進入交付狀態。 ? 根據數據統計,基于端網一體部署能力,大模型訓練系統的整體部署時間從19天縮減到4.5天,并保證了基礎配置100%準確。 ? 再看看運維階段的“一鍵故障定位”。 星脈網絡具有端網高度協同的特點,增加了端側的運營能力。運營平臺通過數據采集模塊,獲取端側服務器和網絡側交換機的數據,聯動網管拓撲信息,可以做到快速診斷與自動化檢查。 一鍵故障定位,可以快速定界問題方向,精準推送到對應團隊的運營人員(網絡or業務),減少溝通成本,劃分責任界限。而且,它還有利于快速定位問題根因,并給出解決方案。 最后,是“業務無感秒級網絡自愈”。 在網絡運行的過程中,故障是無法避免的。 為了將故障自愈時間縮短到極致,騰訊推出了秒級故障自愈產品——“HASH DODGING”。 這是一種基于Hash偏移算法的網絡相對路徑控制方法。即,終端僅需修改數據包頭特定字段(如IP頭TOS字段)的值,即可使得修改后的包傳輸路徑與修改前路徑無公共節點。 在網絡數據平面發生故障(如靜默丟包、路由黑洞)時,該方案可以幫助TCP快速繞過故障點,不會產生對標準拓撲及特定源端口號的依賴。 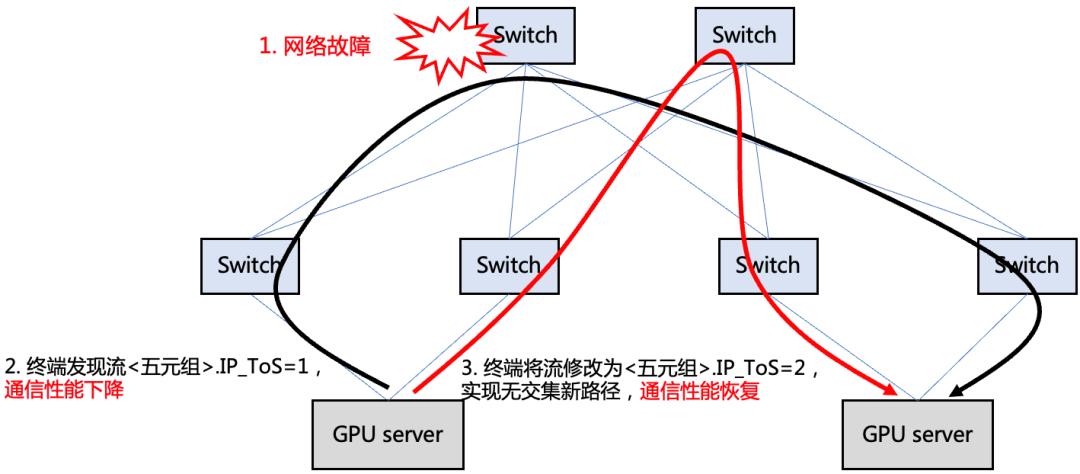 單路徑傳輸協議下,使用本方案,實現確定性換路 ? ? █ 結語 以上,就是對騰訊星脈高性能計算網絡的關鍵技術分析。 這些關鍵技術,揭示了高性能網絡的發展思路和演進方向。隨著AI大模型的深入發展,人類對AI算力的需求會不斷增加。 日前,騰訊云發布的新一代HCC高性能計算集群,正是基于星脈高性能網絡打造,算力性能較前代提升3倍,為AI大模型訓練構筑可靠的高性能網絡底座。 未來已來,這場圍繞算力和連接力的角逐已經開始。更多的精彩還在后面,讓我們拭目以待吧!
單路徑傳輸協議下,使用本方案,實現確定性換路 ? ? █ 結語 以上,就是對騰訊星脈高性能計算網絡的關鍵技術分析。 這些關鍵技術,揭示了高性能網絡的發展思路和演進方向。隨著AI大模型的深入發展,人類對AI算力的需求會不斷增加。 日前,騰訊云發布的新一代HCC高性能計算集群,正是基于星脈高性能網絡打造,算力性能較前代提升3倍,為AI大模型訓練構筑可靠的高性能網絡底座。 未來已來,這場圍繞算力和連接力的角逐已經開始。更多的精彩還在后面,讓我們拭目以待吧!
-
網絡
+關注
關注
14文章
7571瀏覽量
88897 -
AI
+關注
關注
87文章
30998瀏覽量
269329 -
TCP
+關注
關注
8文章
1362瀏覽量
79113
原文標題:死磕AI大模型網絡,鵝廠出招了!
文章出處:【微信號:鮮棗課堂,微信公眾號:鮮棗課堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
防止AI大模型被黑客病毒入侵控制(原創)聆思大模型AI開發套件評測4
用TINA如何搭建仿真模型?


Firefly支持AI引擎Tengine,性能提升,輕松搭建AI計算框架
【AI學習】第3篇--人工神經網絡
《AI概論:來來來,成為AI的良師益友》高煥堂老師帶你學AI
輕量化神經網絡的相關資料下載
介紹在STM32cubeIDE上部署AI模型的系列教程
simulink搭建的摩擦模型

卷積神經網絡模型搭建
虹科分享 | 谷歌Vertex AI平臺使用Redis搭建大語言模型





 工商網監
工商網監
評論