 構建一個移動端友好的SAM方案MobileSAM
構建一個移動端友好的SAM方案MobileSAM
導讀
本文提出一種"解耦蒸餾"方案對SAM的ViT-H解碼器進行蒸餾,同時所得輕量級編碼器可與SAM的解碼器"無縫兼容"。在推理速度方面,MobileSAM處理一張圖像僅需10ms,比FastSAM的處理速度快4倍。
SAM(Segment Anything Model)是一種提示詞引導感興趣目標分割的視覺基礎模型。自提出之日起,SAM引爆了CV社區,也衍生出了大量相關的應用(如檢測萬物、摳取萬物等等),但是受限于計算量問題,這些應用難以用在移動端。
本文旨在將SAM的"重量級"解碼器替換為"輕量級"以使其可在移動端部署應用。為達成該目標,本文提出一種"解耦蒸餾"方案對SAM的ViT-H解碼器進行蒸餾,同時所得輕量級編碼器可與SAM的解碼器"無縫兼容" 。此外,所提方案,只需一個GPU不到一天時間即可完成訓練,比SAM小60倍且性能相當,所得模型稱之為MobileSAM。在推理速度方面,MobileSAM處理一張圖像僅需10ms(8ms@Encoder,2ms@Decoder),比FastSAM的處理速度快4倍,這就使得MobileSAM非常適合于移動應用。
SAM
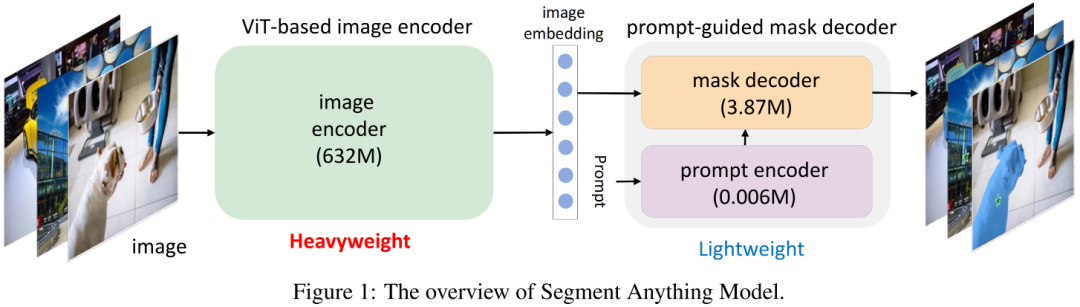
上圖給出了SAM架構示意圖,它包含一個"重量級"ViT編碼器與一個提示詞引導Mask解碼器。解碼器以圖像作為輸入,輸出將被送入Mask解碼器的隱特征(embedding);Mask解碼器將基于提示詞(如point、bbox)生成用于目標分割的Mask。此外,SAM可以對同一個提示詞生成多個Mask以緩解"模棱兩可"問題。更多關于SAM及衍生技術可參考文末推薦閱讀材料。

延續SAM架構體系:采用輕量級ViT解碼器生成隱特征,然后采用提示詞引導解碼器生成期望的Mask。本文目標:構建一個移動端友好的SAM方案MobileSAM,即比原生SAM更快且具有令人滿意的性能。考慮到SAM不同模塊之間的參數量問題,本文主要聚焦于采用更輕量型的Encoder替換SAM的重量級Encoder。
實現方案
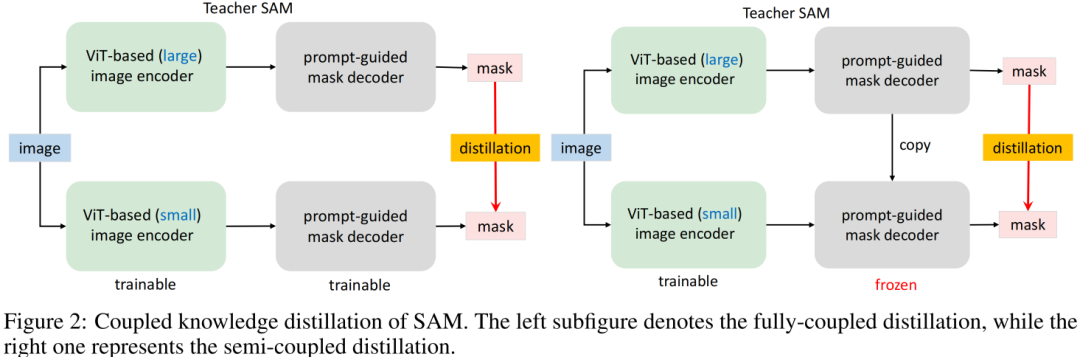
Coupled Distillation 一種最直接的方式是參考SAM方案重新訓練一個具有更小Encoder的SAM,見Figure2左圖。如SAM一文所提到:SAM-ViT-H的訓練需要256個A100,且訓練時間達68小時;哪怕Encoder為ViT-B也需要128個GPU。這樣多的資源消耗無疑阻礙了研究人員進行復現或改進。此外,需要注意的是SAM所提供數據集的Mask是有預訓練SAM所生成,本質上講,重訓練過程也是一種知識蒸餾過程,即講ViT-H學習到的知識遷移到輕量級Encoder中。
Semi-coupled Distillation 當對原生SAM進行知識蒸餾時,主要困難在于: Encoder與Decoder的耦合優化,兩者存在互依賴。有鑒于此,作者將整個知識蒸餾過程拆解為Encoder蒸餾+Decoder微調,該方案稱之為半耦合蒸餾(Semi-coupled Distillation),見Figure2右圖。也就是說,我們首先對Encoder進行知識蒸餾,然后再與Decoder進行協同微調。
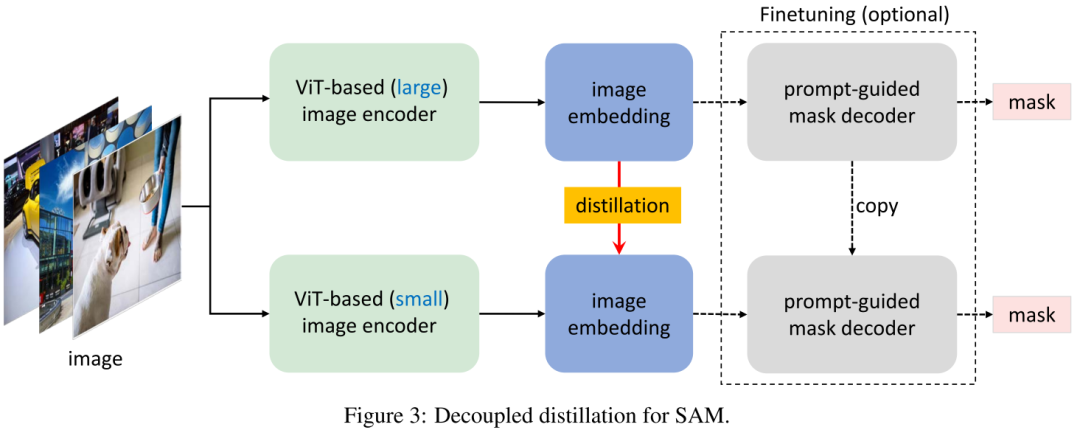
Decoupled Distillation 根據經驗,我們發現這種半耦合蒸餾方案仍然極具挑戰性,這是因為提示詞的選擇具有隨機性,使得Decoder可變,進而導致優化變難。有鑒于此,作者提出直接對原生SAM的編碼器進行蒸餾且無需與Decoder組合,該方案稱之為解耦合蒸餾。該方案的一個優勢在于:僅需使用MSE損失即可,而無需用于Mask預測的Focal與Dice組合損失。
Necessity of Mask Decoder Finetuning 不同于半耦合蒸餾,經解耦合蒸餾訓練得到的輕量級Encoder可能與凍結的Decoder存在不對齊問題。根據經驗,我們發現:該現象并不存在。這是因為學生Encoder生成的隱特征非常接近于原始老師Encoder生成的隱特征,因此并不需要與Decoder進行組合微調。當然,進一步的組合微調可能有助于進一步提升性能。
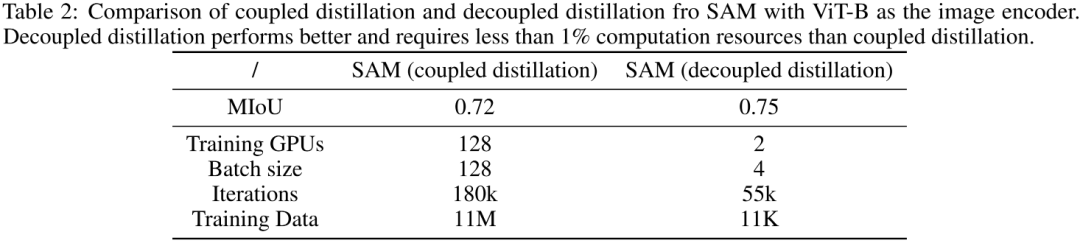
Preliminary Evaluation 上表對比了耦合蒸餾與解耦合蒸餾的初步對比。可以看到:
從指標方面,解耦合蒸餾方案指標稍高,0.75mIoU vs 0.72mIoU;
從訓練GPU方面,解耦合蒸餾方案僅需兩個GPU,遠小于耦合蒸餾方案的128卡,大幅降低了對GPU的依賴;
從迭代次數方面,解耦合蒸餾方案僅需55k次迭代,遠小于耦合蒸餾方案的180K,大幅降低了訓練消耗;
從訓練數據方面,解耦合蒸餾方案僅需11K數據量,遠小于耦合蒸餾方案的11M,大幅降低了數據依賴。
盡管如此,但ViT-B對于移動端部署仍然非常困難。因此,后續實驗主要基于TinyViT進行。
本文實驗

在具體實現方面,作者基于ViT-Tiny進行本文所提方案的有效性驗證,所得MobileSAM與原生SAM的參數+速度的對比可參考上表。在訓練方面,僅需SA-1B的1%數據量+單卡(RTX3090),合計訓練8個epoch,僅需不到一天即可完成訓練。


上述兩個圖給出了point與bbox提示詞下MobileSAM與原生SAM的結果對比,可以看到:MobileSAM可以取得令人滿意的Mask預測結果。
消融實驗
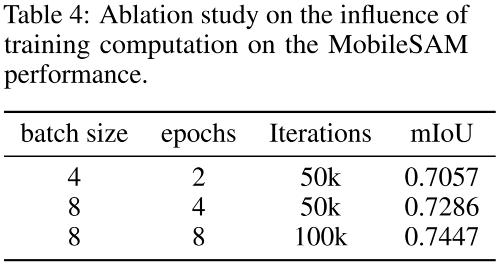
上表從訓練超參bs、epoch、iter等維度進行了對比分析,可以看到:
在同等迭代次數下,提升bs可以進一步提升模型性能;
在同等bs下,提升iter可以進一步提升模型性能。

上報對比了FastSAM與MobileSAM,可以看到:
從參數量方面,MobileSAM只有不到10M的參數量,遠小于FastSAM的68M;
從處理速度方面,MobileSAM僅需10ms,比FastSAM的40ms快4倍.

上圖從Segment everything角度對比了SAM、FastSAM以及MobileSAM三個模型,可以看到:
MobileSAM與原生SAM結果對齊驚人的好,而FastSAM會生成一些無法滿意的結果;
FastSAM通常生成非平滑的邊緣,而SAM與MobileSAM并沒有該問題。
最后,補充一下Segment Anything與Segment Everything之間的區別。
如SAM一文所提到,SAM通過提示詞進行物體分割,也就是說,提示詞的作用是指定想分割哪些物體。理論上講,當給定合適的提示詞后,任何目標都可以被分割,故稱之為Segment Anything。
相反,Segment Everything本質上是物體候選框生成過程,不需要提示詞。故它往往被用來驗證下游任務上的zero-shot遷移能力。
總而言之,Segment Anything解決了任意物體的提示分割基礎任務;Segment Everything則解決了所有物體面向下游任務的候選框生成問題。
-
編碼器
+關注
關注
45文章
3643瀏覽量
134525 -
模型
+關注
關注
1文章
3244瀏覽量
48842 -
SAM
+關注
關注
0文章
112瀏覽量
33524
原文標題:Faster Segment Anything
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【愛芯派 Pro 開發板試用體驗】+ 圖像分割和填充的Demo測試
基于SAM3S4C器件被動紅外參考設計
SMART SAM4C微控制器有哪些應用?
法國DREAM方案SAM5504B/SAM5704B音源芯片

中興聯手廣州移動實現構建端到端的5G地鐵切片
如何構建一個完整的物聯網解決方案
一個利用GT-SAM的緊耦合激光雷達慣導里程計的框架

如何構建一個演示移動端應用





 工商網監
工商網監
評論