 從Arm的TCS23參考設計,看明年的手機性能提升
從Arm的TCS23參考設計,看明年的手機性能提升
其實Arm前一陣已經正式發布了TCS23(Total Compute Solutions 23)平臺,以及對應的IP產品,包括Cortex-X4、A720、A520這些Armv9架構的CPU IP,最新的Immortalis-G720——也就是基于Arm第五代GPU微架構的新IP,以及更新后的DSU。毫無疑問的,這些IP會成為接下來1-2年手機AP SoC的焦點。
最近Arm特別在中國的媒體技術日上,花較多篇幅去談這些IP及TCS23平臺的組成細節。Arm從解決方案、CPU/GPU及相關IP、軟件、安全四個方面做了比較大篇幅的分享。
幾個核心IP應該是普羅大眾最關心的,包括全面徹底遷往AArch64的CPU IP,新一代的Immortalis GPU,以及新版DSU-120(DynamIQ Shared Unit)。這幾個組成部分,我們將另外撰文詳述。
實際上Arm推的TCS23解決方案也已經是第3代了。大部分人對于“解決方案”于Arm IP這套生態的理解,應該就是將IP打包發售。但實際上,TCS是從設計角度,更綜合、整體的范圍去提升性能和效率的存在。
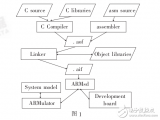
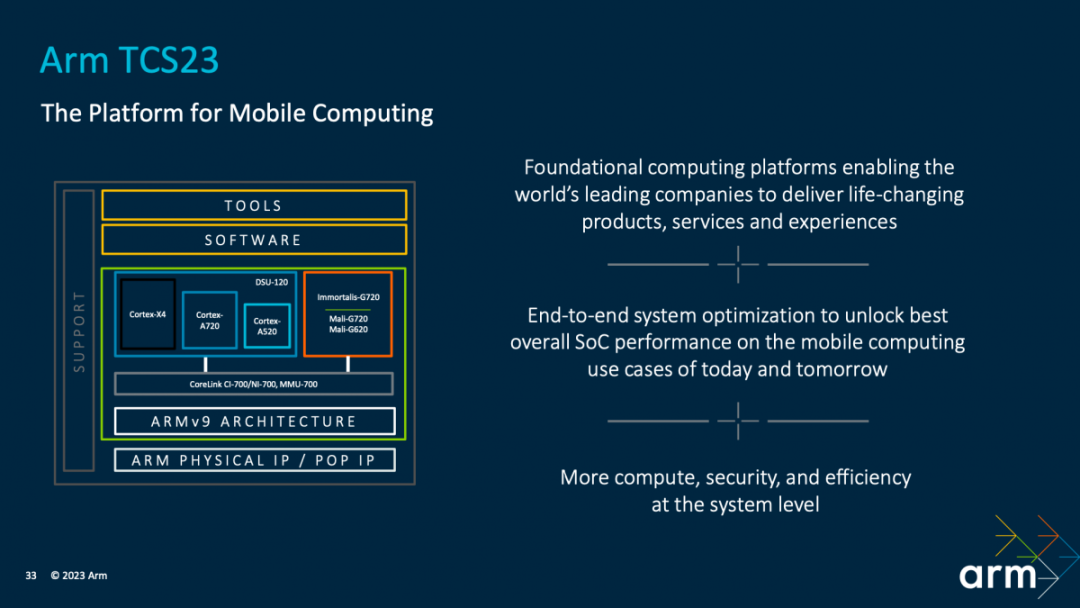 ?具體如上圖所示,大部分人關心的是處在中間的環節,即Armv9架構及其上的存儲與互聯一致性、各種核心IP。實際TCS還包括圖中的軟件、開發工具,以及以先進工藝做Arm IP實施的物理IP。
Arm終端事業部產品管理高級總監Kinjal Dave說:“談到解決方案,為什么 Arm 要采取這樣一種全局的方法論來開發解決方案,不斷推高性能、提高效率,本身變得越來越難且成本高昂。其實這對 Arm 來說,意味著我們每年推出的 TCS 在性能跟效率方面,都必須實現進步。所以,我們要采取一種平衡。”
Kinjal說Arm這些年來始終努力在benchmark和真實使用場景之間做平衡:“一方面,單獨的 IP 要不斷把它做強,另外一方面把這些單獨的 IP 集合在一起時,總體的系統級別也要實現性能效率的雙提升。” “為我們的合作伙伴提供融合了這些單獨IP的系統級解決方案所帶來的完整性能提升。”
隨著摩爾定律的放緩,以及設計層面各種經典技術的全面上線,這兩年單獨IP微架構層面帶來的性能和效率提升也遠不及此前那么大了,從更系統的角度來做考量也是半導體鏈條上各個玩家的共識。
所以這篇文章我們就從TCS23整體的角度來看看這一代平臺的改進,其中會涉及到上述IP,但不會過多深入。另外很難得的是,Arm特別用一個主題演講的章節去談了軟件改進,包括編譯器、SVE2指令、Android動態性能框架等,本文也會略有涉及。
TCS23參考設計
本文就不過多提單獨IP的性能與效率變化了,包括Cortex-X4相比X3性能提升15%,Cortex-A720相比A715能效提升20%,Cortex-A520相比A510能效提升22%,DSU提升動態功耗表現、針對閑置與低負載場景的新功耗模式,Immortalis-G720性能提升15%、帶寬用量降低40%等等。
?具體如上圖所示,大部分人關心的是處在中間的環節,即Armv9架構及其上的存儲與互聯一致性、各種核心IP。實際TCS還包括圖中的軟件、開發工具,以及以先進工藝做Arm IP實施的物理IP。
Arm終端事業部產品管理高級總監Kinjal Dave說:“談到解決方案,為什么 Arm 要采取這樣一種全局的方法論來開發解決方案,不斷推高性能、提高效率,本身變得越來越難且成本高昂。其實這對 Arm 來說,意味著我們每年推出的 TCS 在性能跟效率方面,都必須實現進步。所以,我們要采取一種平衡。”
Kinjal說Arm這些年來始終努力在benchmark和真實使用場景之間做平衡:“一方面,單獨的 IP 要不斷把它做強,另外一方面把這些單獨的 IP 集合在一起時,總體的系統級別也要實現性能效率的雙提升。” “為我們的合作伙伴提供融合了這些單獨IP的系統級解決方案所帶來的完整性能提升。”
隨著摩爾定律的放緩,以及設計層面各種經典技術的全面上線,這兩年單獨IP微架構層面帶來的性能和效率提升也遠不及此前那么大了,從更系統的角度來做考量也是半導體鏈條上各個玩家的共識。
所以這篇文章我們就從TCS23整體的角度來看看這一代平臺的改進,其中會涉及到上述IP,但不會過多深入。另外很難得的是,Arm特別用一個主題演講的章節去談了軟件改進,包括編譯器、SVE2指令、Android動態性能框架等,本文也會略有涉及。
TCS23參考設計
本文就不過多提單獨IP的性能與效率變化了,包括Cortex-X4相比X3性能提升15%,Cortex-A720相比A715能效提升20%,Cortex-A520相比A510能效提升22%,DSU提升動態功耗表現、針對閑置與低負載場景的新功耗模式,Immortalis-G720性能提升15%、帶寬用量降低40%等等。
 ?不過Arm針對TCS23就FPGA級別做了參考設計,“代表真實的芯片設備”。Arm做參考設計的原因,一是IP越來越復雜,其次是系統中的許多特性是需要跨系統的,比如說這次Arm一直在談的MTE(Memory Tagging Extention)安全特性;
另外還包括“越來越多樣化終端使用場景的出現”,以及“對這些芯片設計工作來說,在設計選擇以及平衡方面的取舍難度也提高了。”
?不過Arm針對TCS23就FPGA級別做了參考設計,“代表真實的芯片設備”。Arm做參考設計的原因,一是IP越來越復雜,其次是系統中的許多特性是需要跨系統的,比如說這次Arm一直在談的MTE(Memory Tagging Extention)安全特性;
另外還包括“越來越多樣化終端使用場景的出現”,以及“對這些芯片設計工作來說,在設計選擇以及平衡方面的取舍難度也提高了。”
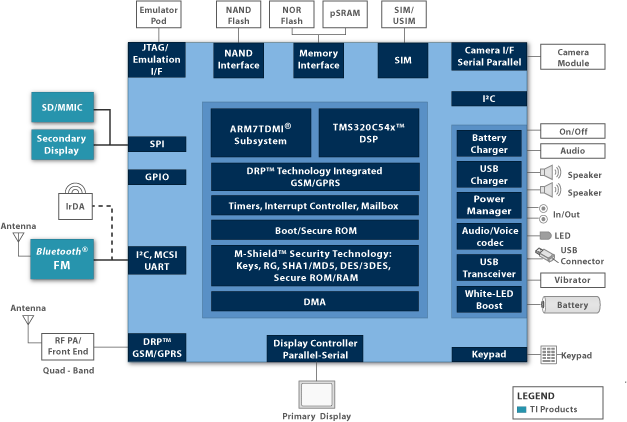
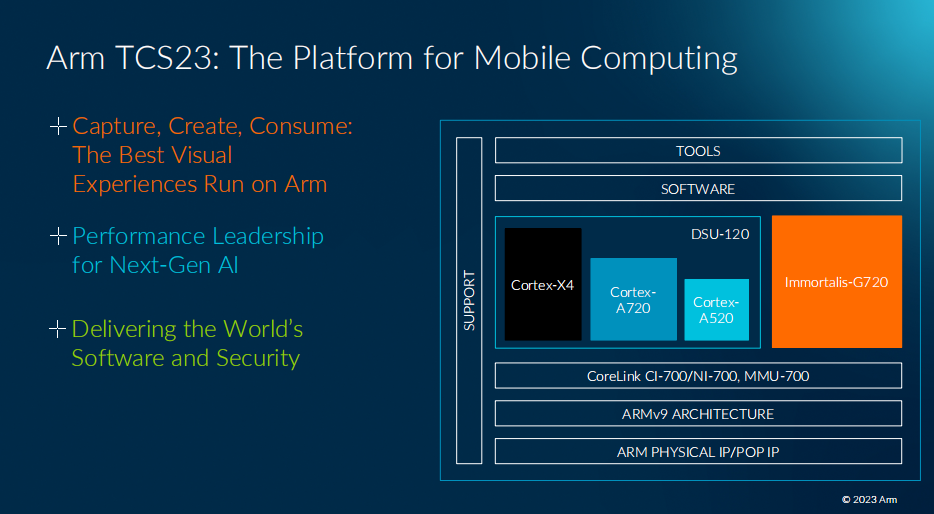
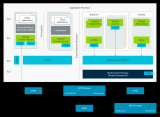
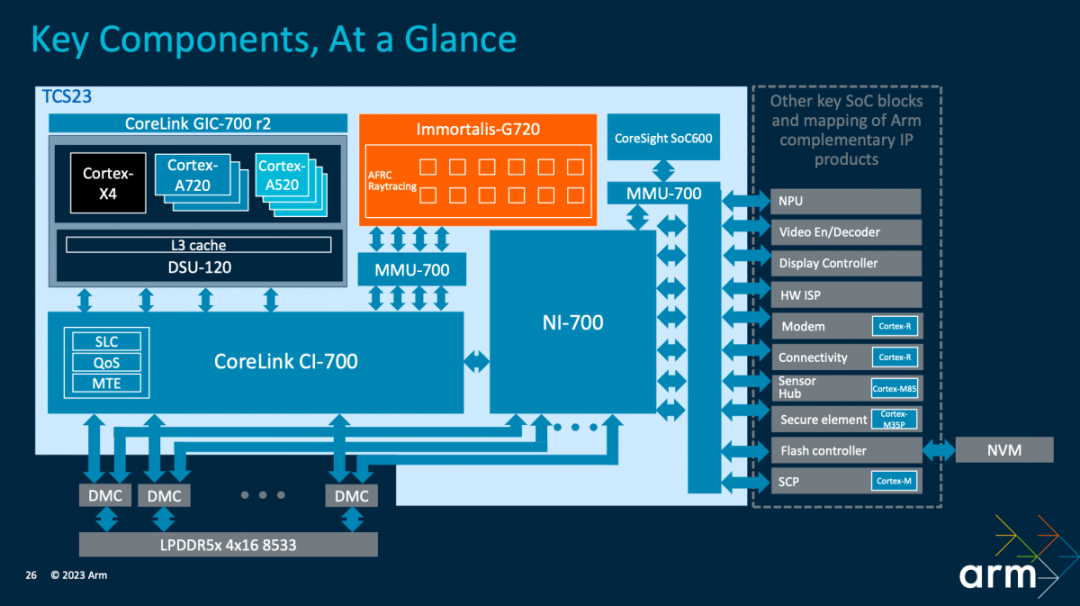 ?上面這張圖就是Arm TCS23參考設計。大框架上CPU、GPU都用了這一代最新IP。不同核心組成的CPU集群,“與DSU-120共同連接到共享系統的背板(backplane)”;借助system cache(SLC)所在的CoreLink CI-700,一邊連接到Immortalis-G720 GPU。
這里CoreLink CI-700作為存儲系統的核心,為所有的IO流量提供一個匯聚點(也用于實現MTE)。同時,NI-700為所有其他流量提供一條通往DRAM獨立的路徑;“能進行QoS執行,允許不同的流量類型一起流動,而不會出現交叉流,或者互相阻塞的情況”。
系統級解決方案的奧義
參考設計的CPU部分,是1x Cortex-X4, 3x Cortex-A720, 4x Cortex-A520的配置;DSU-120配了8MB L3 cache。Arm認為1+3+4是性能和效率可達成均衡的配置方案。不過在多線程性能對比時,Arm也有基于1+5+2的搭配呈現。
?上面這張圖就是Arm TCS23參考設計。大框架上CPU、GPU都用了這一代最新IP。不同核心組成的CPU集群,“與DSU-120共同連接到共享系統的背板(backplane)”;借助system cache(SLC)所在的CoreLink CI-700,一邊連接到Immortalis-G720 GPU。
這里CoreLink CI-700作為存儲系統的核心,為所有的IO流量提供一個匯聚點(也用于實現MTE)。同時,NI-700為所有其他流量提供一條通往DRAM獨立的路徑;“能進行QoS執行,允許不同的流量類型一起流動,而不會出現交叉流,或者互相阻塞的情況”。
系統級解決方案的奧義
參考設計的CPU部分,是1x Cortex-X4, 3x Cortex-A720, 4x Cortex-A520的配置;DSU-120配了8MB L3 cache。Arm認為1+3+4是性能和效率可達成均衡的配置方案。不過在多線程性能對比時,Arm也有基于1+5+2的搭配呈現。
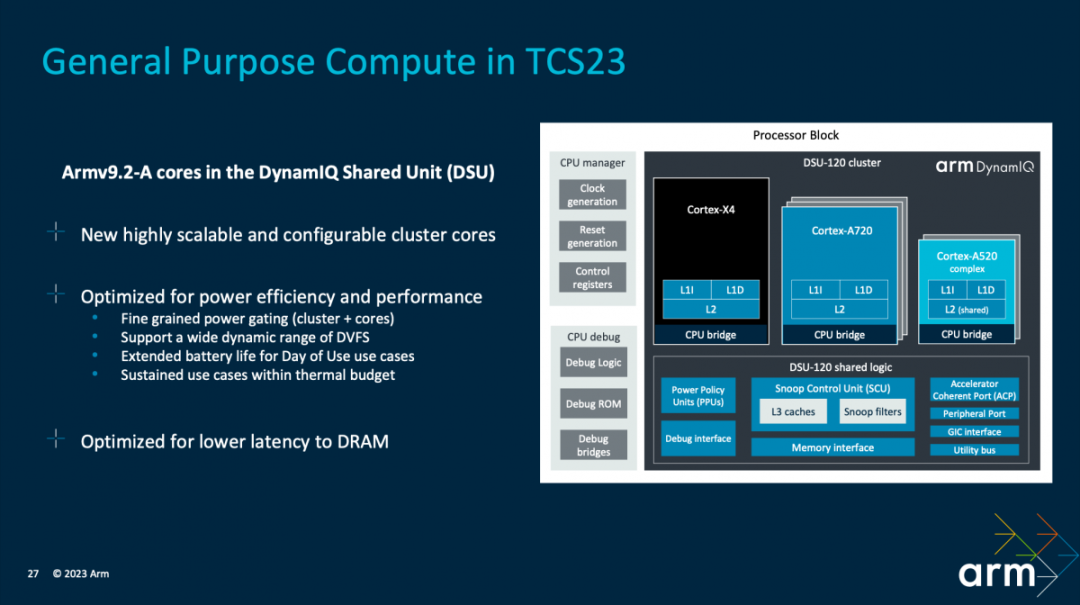 ?Kinjal沒有細談這部分的配置。不過這里主要看的還是系統級別的工作。他強調CPU集群的關鍵首先是如何利用CPU和行為架構實現跨越三個層級的性能動態范圍;其次影響CPU性能很重要的因素是DRAM延遲。
對于后者,一方面,“我們進行了DRAM結構性的靜態延遲優化”,“首先是DynamIQ共享單元內和通往內存的路徑中的時鐘配置的選擇,也就是在這個領域資源的競爭”——在這個過程里,需要進行DynamIQ時鐘配置優化,“同時要最小化數量的選擇”;
另一方面,還需要考慮“加載系統內存層面下的動態優先級別”,包括“GPU、攝像頭以及其他多媒體管道等”,“它們可能要同時訪問內存”。這些都要求在進行CPU集群配置時,做相應的考量。
?Kinjal沒有細談這部分的配置。不過這里主要看的還是系統級別的工作。他強調CPU集群的關鍵首先是如何利用CPU和行為架構實現跨越三個層級的性能動態范圍;其次影響CPU性能很重要的因素是DRAM延遲。
對于后者,一方面,“我們進行了DRAM結構性的靜態延遲優化”,“首先是DynamIQ共享單元內和通往內存的路徑中的時鐘配置的選擇,也就是在這個領域資源的競爭”——在這個過程里,需要進行DynamIQ時鐘配置優化,“同時要最小化數量的選擇”;
另一方面,還需要考慮“加載系統內存層面下的動態優先級別”,包括“GPU、攝像頭以及其他多媒體管道等”,“它們可能要同時訪問內存”。這些都要求在進行CPU集群配置時,做相應的考量。
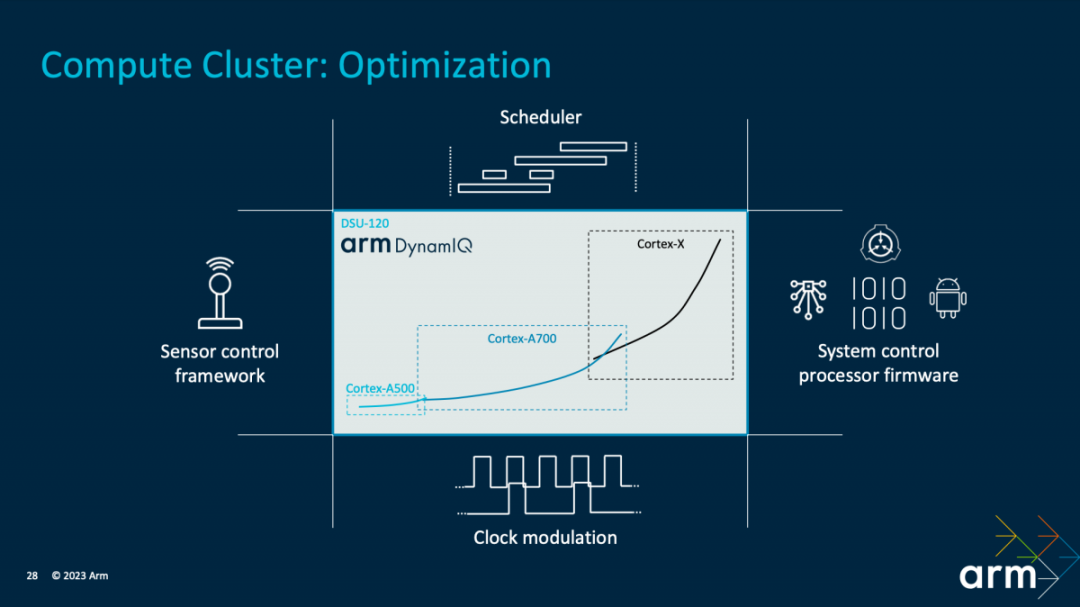 ?在CPU集群的優化上,首先是基于“CPU核心微架構”提供“最為廣泛的動態范圍”,“跨越三層(Cortex X4,Cortex A720和Cortex A520)”。其中包括DVFS動態調整,線程核心遷移等;適配各種負載場景、應對不同的性能目標。此間涵蓋以最優化的效率,針對不同的運行場景,包括了分配多少CPU資源,如頻率、響應、哪些核心參與等等。
“計算IP級的系統級解決方案,包括不同電源選擇的模式,不同時鐘選項的配置”,“在TCS23中我們添加了一個邏輯增強型降功耗的模式”。
“在解決方案層級,我們的電源控制固件的堆棧以及調度器一起工作,能實現基于不同的使用場景的選擇,這點很關鍵。”Kinjal說,“TCS23解決方案中還有一個系統控制處理器,它能夠協調傳感器控制框架,在各個CPU內核以及DSU-120工作點之間移動的時候充分考慮到散熱以及輸電的一些限制因素。”“跨整個CPU集群,我們還實施了積極的時鐘門控以及時空調節的機制,來節約動態功耗。”
?在CPU集群的優化上,首先是基于“CPU核心微架構”提供“最為廣泛的動態范圍”,“跨越三層(Cortex X4,Cortex A720和Cortex A520)”。其中包括DVFS動態調整,線程核心遷移等;適配各種負載場景、應對不同的性能目標。此間涵蓋以最優化的效率,針對不同的運行場景,包括了分配多少CPU資源,如頻率、響應、哪些核心參與等等。
“計算IP級的系統級解決方案,包括不同電源選擇的模式,不同時鐘選項的配置”,“在TCS23中我們添加了一個邏輯增強型降功耗的模式”。
“在解決方案層級,我們的電源控制固件的堆棧以及調度器一起工作,能實現基于不同的使用場景的選擇,這點很關鍵。”Kinjal說,“TCS23解決方案中還有一個系統控制處理器,它能夠協調傳感器控制框架,在各個CPU內核以及DSU-120工作點之間移動的時候充分考慮到散熱以及輸電的一些限制因素。”“跨整個CPU集群,我們還實施了積極的時鐘門控以及時空調節的機制,來節約動態功耗。”
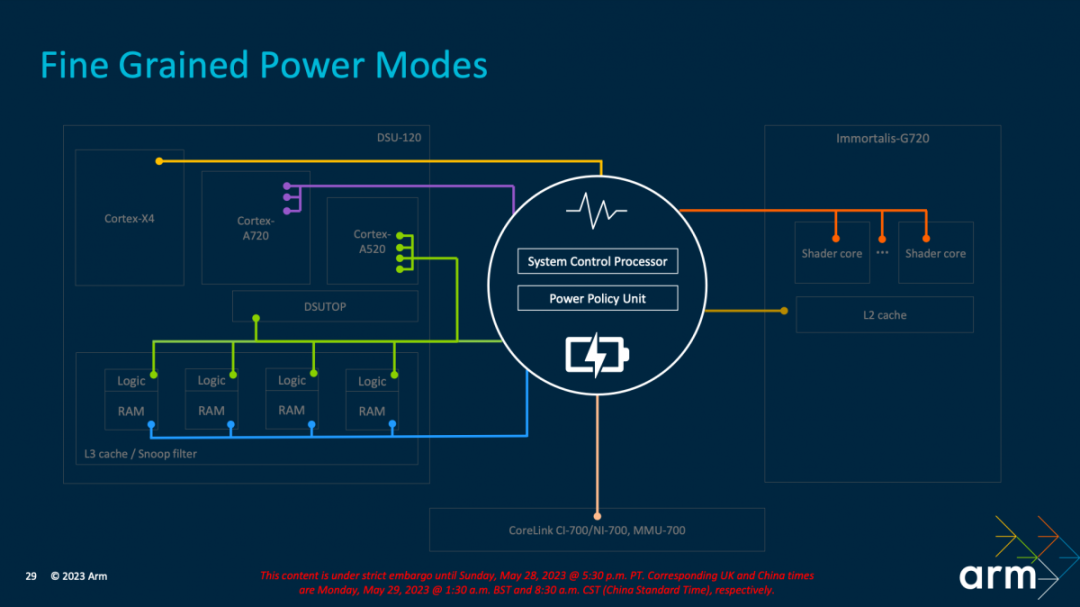 ?另一個關鍵是細粒度的電源模式——這也是當代低功耗設計的精髓所在。上面這張圖每種顏色代表“單獨的電源連接供電”。Arm在此的工作之一就是管理供電的復雜性,“我們有專門用于電壓供應的管理、電源傳輸、網絡控制電源控制部件。
“這里電源控制部件是與調度器,以及操作系統的電源管理軟件共同協調工作的。”
?另一個關鍵是細粒度的電源模式——這也是當代低功耗設計的精髓所在。上面這張圖每種顏色代表“單獨的電源連接供電”。Arm在此的工作之一就是管理供電的復雜性,“我們有專門用于電壓供應的管理、電源傳輸、網絡控制電源控制部件。
“這里電源控制部件是與調度器,以及操作系統的電源管理軟件共同協調工作的。”
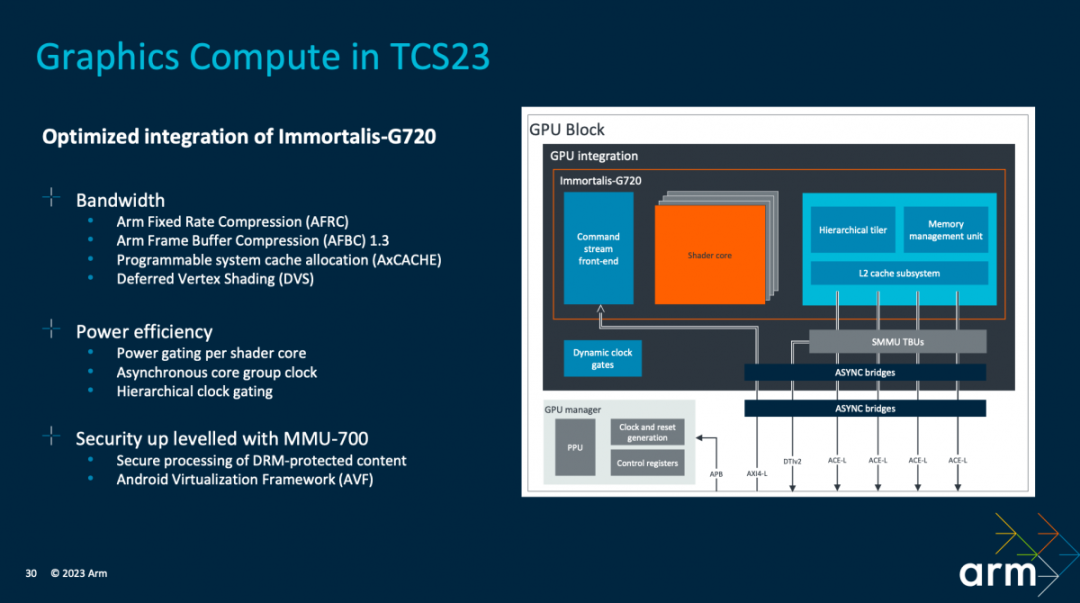 ?圖形計算相關的部分,Arm強調了3個解決方案層面的關注點,分別是帶寬、功耗,與安全性。“我們將Arm Immotalis-G720集成到TCS23解決方案中,配置了MMU-700,與GPU實現共同的優化”。其中的某些部分,也會在我們后續的IP文章GPU相關部分做更詳盡的介紹——比如節約帶寬的Deferred Vertex Shading延遲頂點著色。
從大方向來看,節約帶寬方面的工作包括AFRC與AFBC無損壓縮——管線不同階段的數據壓縮始終是GPU不變的話題之一,它對于DRAM訪問需求的降低,提供更大的發熱空間都有價值;IO一致性,將緩存維護開銷降到最低,并由CoreLink CI-700與Immortalis-G720合作,來達成性能的提升;以及利用大型系統高速緩存(system cache),而且還有個“內存分配提示,優先考慮哪部分要存在高速緩存中”。
能效優化部分,一方面是利用針對每個shader核心的power gating,另外就是核心群組的節電模式等。“TCS23解決方案提供了一套完整的參考:Immortalis-G720驅動如何與我們的參考固件堆棧協同,實現電源控制、動態電壓與頻率的調節。”另外,“我們在GPU中也實施了積極的clock gating方案,用以管理動態功耗。”
安全性方面,MMU-700的集成對于支持DRAM保護內容的安全處理,以及支持Android虛擬化框架是至關重要的。
?圖形計算相關的部分,Arm強調了3個解決方案層面的關注點,分別是帶寬、功耗,與安全性。“我們將Arm Immotalis-G720集成到TCS23解決方案中,配置了MMU-700,與GPU實現共同的優化”。其中的某些部分,也會在我們后續的IP文章GPU相關部分做更詳盡的介紹——比如節約帶寬的Deferred Vertex Shading延遲頂點著色。
從大方向來看,節約帶寬方面的工作包括AFRC與AFBC無損壓縮——管線不同階段的數據壓縮始終是GPU不變的話題之一,它對于DRAM訪問需求的降低,提供更大的發熱空間都有價值;IO一致性,將緩存維護開銷降到最低,并由CoreLink CI-700與Immortalis-G720合作,來達成性能的提升;以及利用大型系統高速緩存(system cache),而且還有個“內存分配提示,優先考慮哪部分要存在高速緩存中”。
能效優化部分,一方面是利用針對每個shader核心的power gating,另外就是核心群組的節電模式等。“TCS23解決方案提供了一套完整的參考:Immortalis-G720驅動如何與我們的參考固件堆棧協同,實現電源控制、動態電壓與頻率的調節。”另外,“我們在GPU中也實施了積極的clock gating方案,用以管理動態功耗。”
安全性方面,MMU-700的集成對于支持DRAM保護內容的安全處理,以及支持Android虛擬化框架是至關重要的。
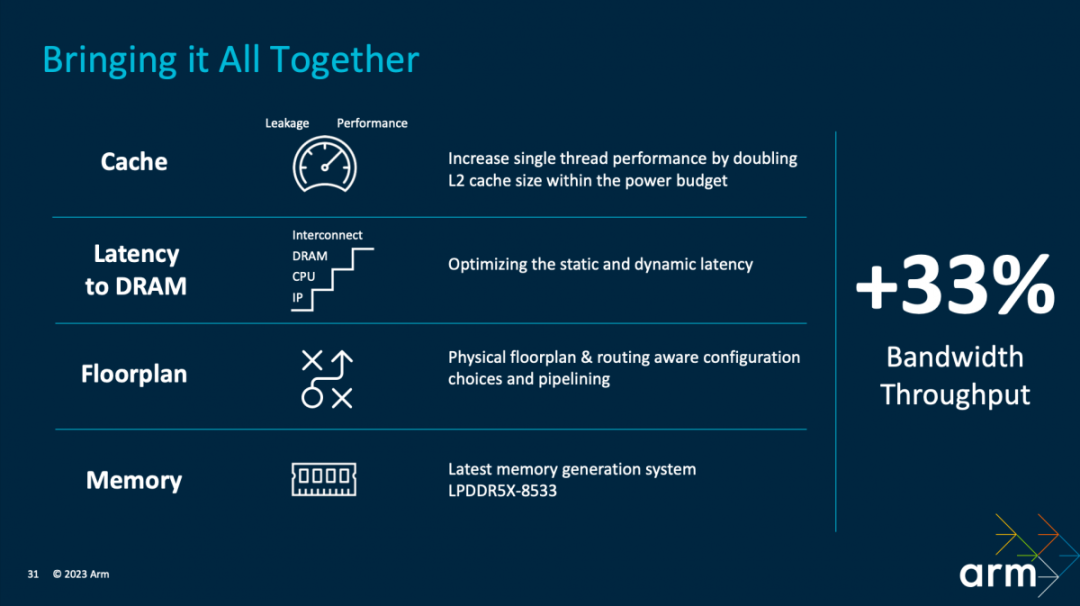 ?結合包括cache、連接至內存的延遲、floorplan以及內存支持方面的變化,參考設計達成綜合的帶寬吞吐,相比于前代提升了33%。
所以在總結性發言里,Kinjal再度強調的一點就是基于TCS全面計算解決方案,“Arm已經超越單個IP產品,為客戶實現端到端系統級的優化,從而釋放整個SoC系統全面性能”。這是TCS存在的核心價值。
軟件帶來的性能提升
除了這些比較多人關注的IP之外,如文首所述,TCS作為解決方案還涵蓋了工具、軟件、物理/POP IP等。這里我們再談一談工具和軟件,TCS23不僅升級了IP,也升級了軟件與工具。Arm終端事業部生態系統及工程高級總監Geraint North說Arm的工程師中,超過45%都是軟件工程師,底層部分涵蓋了驅動、Linux內核,往上則有軟件框架、性能分析工具、開發者教學、最佳實踐等。
?結合包括cache、連接至內存的延遲、floorplan以及內存支持方面的變化,參考設計達成綜合的帶寬吞吐,相比于前代提升了33%。
所以在總結性發言里,Kinjal再度強調的一點就是基于TCS全面計算解決方案,“Arm已經超越單個IP產品,為客戶實現端到端系統級的優化,從而釋放整個SoC系統全面性能”。這是TCS存在的核心價值。
軟件帶來的性能提升
除了這些比較多人關注的IP之外,如文首所述,TCS作為解決方案還涵蓋了工具、軟件、物理/POP IP等。這里我們再談一談工具和軟件,TCS23不僅升級了IP,也升級了軟件與工具。Arm終端事業部生態系統及工程高級總監Geraint North說Arm的工程師中,超過45%都是軟件工程師,底層部分涵蓋了驅動、Linux內核,往上則有軟件框架、性能分析工具、開發者教學、最佳實踐等。
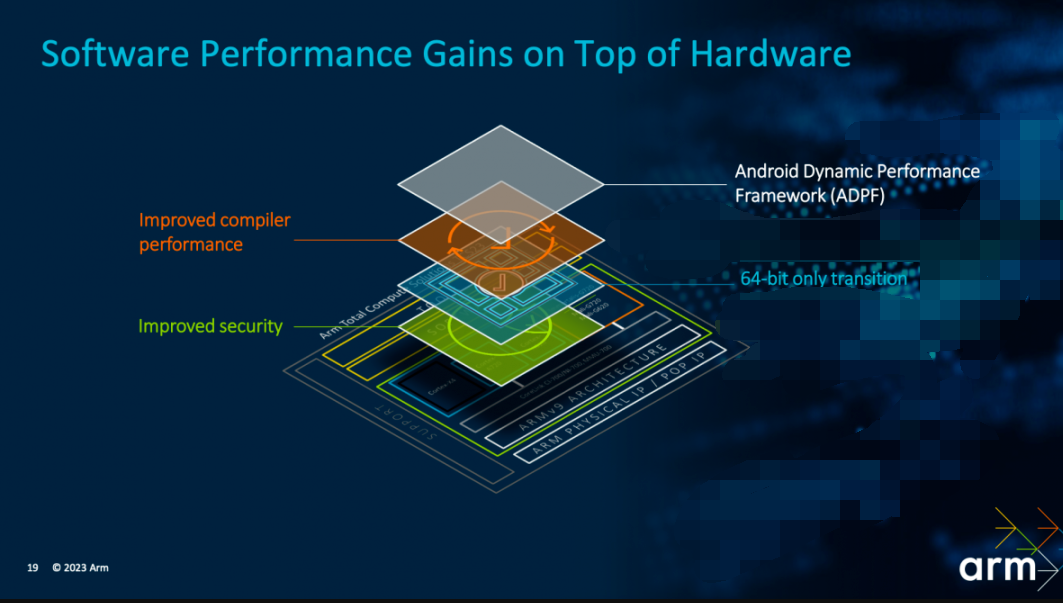 ?軟件自然是位于硬件之上的層級,這部分Geraint主要談了64bit完全遷移、compiler編譯器性能提升,以及ADPF(Android自適應性能框架)帶來的軟件層面的性能提升。
實際上就軟件相關的主題演講,Arm還特別花篇幅去談了安全,包括MTE、PAC/BTI技術及對應生態——談到與谷歌、Unity在安全特性上的合作,甚至在MTE(Memory Tagging Extension)技術上,還特別找來快手、聯發科、vivo這些合作伙伴站臺。不過這次我們不會把筆墨放在安全問題上,即便這個問題就當代移動技術而言正變得格外重要。
有關64位生態遷移的話題,桎梏并不在芯片和操作系統廠商身上,而在最上層的App開發者身上。自11年以前,CPU層面提供64位支持(Cortex-A57/A53),以及2年后Android操作系統跟進,一直到今年Pixel 7作為純64位Android配置的手機問世,這仍然是個相當漫長的過程。而TCS23是徹底構建起純64bit支持集群的一代。
?軟件自然是位于硬件之上的層級,這部分Geraint主要談了64bit完全遷移、compiler編譯器性能提升,以及ADPF(Android自適應性能框架)帶來的軟件層面的性能提升。
實際上就軟件相關的主題演講,Arm還特別花篇幅去談了安全,包括MTE、PAC/BTI技術及對應生態——談到與谷歌、Unity在安全特性上的合作,甚至在MTE(Memory Tagging Extension)技術上,還特別找來快手、聯發科、vivo這些合作伙伴站臺。不過這次我們不會把筆墨放在安全問題上,即便這個問題就當代移動技術而言正變得格外重要。
有關64位生態遷移的話題,桎梏并不在芯片和操作系統廠商身上,而在最上層的App開發者身上。自11年以前,CPU層面提供64位支持(Cortex-A57/A53),以及2年后Android操作系統跟進,一直到今年Pixel 7作為純64位Android配置的手機問世,這仍然是個相當漫長的過程。而TCS23是徹底構建起純64bit支持集群的一代。
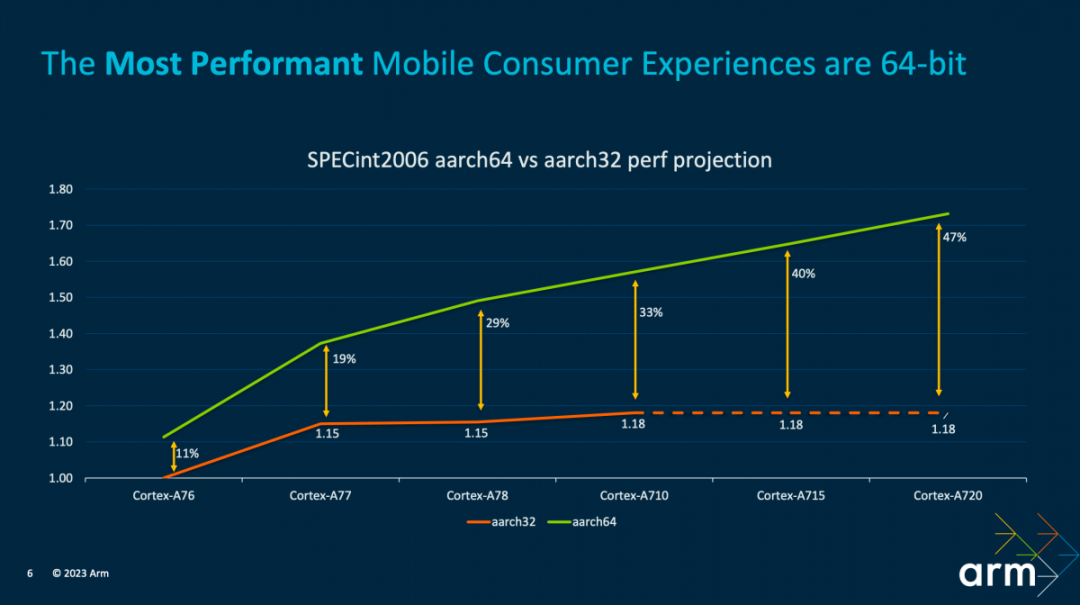 ?從安全和性能兩個角度來看,64位都顯然是個更好的選擇。安全方面,64bit提供更大的內存地址空間,在地址空間布局隨機化(ASLR)等特性實現上會更為有效;也為Arm多番提及的MTE和PAC(Pointer Authentication)提供了實現基礎。
而在性能方面,Arm給出了上面這張圖。Cortex-A7x系列核心,從A76到A720的SPECint2006性能變化情況:32位與64位應用的性能差別是在逐步擴大的。至Cortex-A710這一代性能差距擴大至33%,且后續的IP上32位應用不再能獲得性能紅利。Geraint說:“這種差距的拉大,一部分是由于 IP 實施的決策,我們會把更加寶貴的時間以及硅面積集中在 64 位路徑的優化之上。”
“軟件方面也是如此,我們的編譯器和庫優化團隊,都把工作重點聚焦在 64 位上。如果現在你還是在做 32 位的開發,那么我們做的這些工作可能就不能為你提供賦能。”即便目前歷史遺留問題多少都還在,TCS23應當也意味著移動平臺的64位攻堅戰進入了尾聲。
?從安全和性能兩個角度來看,64位都顯然是個更好的選擇。安全方面,64bit提供更大的內存地址空間,在地址空間布局隨機化(ASLR)等特性實現上會更為有效;也為Arm多番提及的MTE和PAC(Pointer Authentication)提供了實現基礎。
而在性能方面,Arm給出了上面這張圖。Cortex-A7x系列核心,從A76到A720的SPECint2006性能變化情況:32位與64位應用的性能差別是在逐步擴大的。至Cortex-A710這一代性能差距擴大至33%,且后續的IP上32位應用不再能獲得性能紅利。Geraint說:“這種差距的拉大,一部分是由于 IP 實施的決策,我們會把更加寶貴的時間以及硅面積集中在 64 位路徑的優化之上。”
“軟件方面也是如此,我們的編譯器和庫優化團隊,都把工作重點聚焦在 64 位上。如果現在你還是在做 32 位的開發,那么我們做的這些工作可能就不能為你提供賦能。”即便目前歷史遺留問題多少都還在,TCS23應當也意味著移動平臺的64位攻堅戰進入了尾聲。
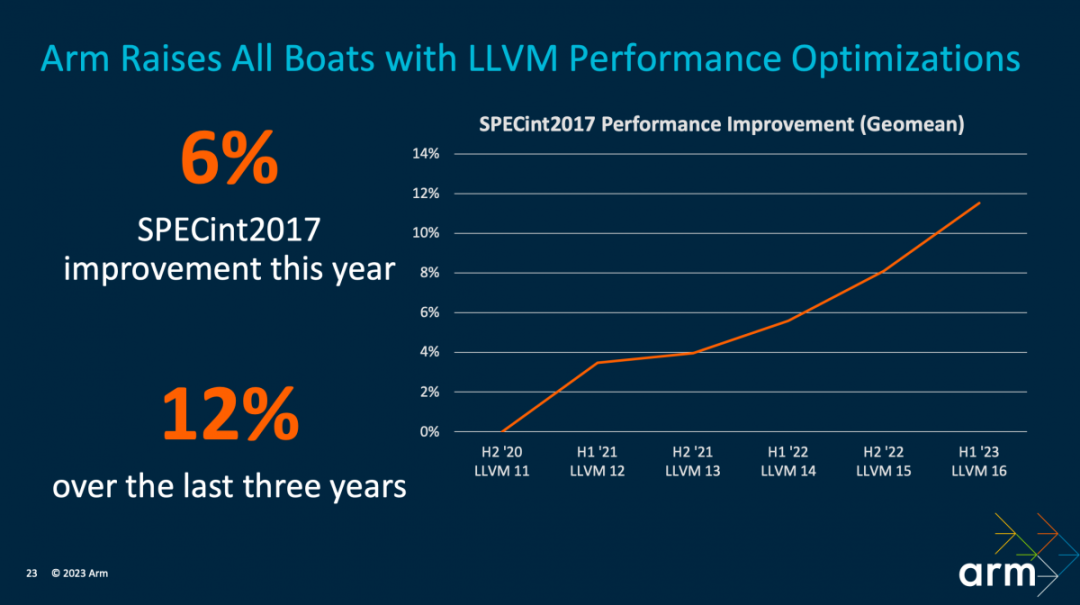 ?編譯器方面,Geraint說過去3年時間里,LLVM實現了12%的性能提升。所以“這種工作是非常有價值的,因為它不僅提高了最新一代的 CPU 性能,不管這個設備是基于 Armv8 還是 Armv9,當它搭載最新的工具鏈重新編譯的時候,會普遍獲得性能的提升”。
Geraint強調,Arm在LLVM上的投入有很大一部分是集中在了SVE2指令的性能提升的——也就是Armv9架構引入的矢量擴展。
?編譯器方面,Geraint說過去3年時間里,LLVM實現了12%的性能提升。所以“這種工作是非常有價值的,因為它不僅提高了最新一代的 CPU 性能,不管這個設備是基于 Armv8 還是 Armv9,當它搭載最新的工具鏈重新編譯的時候,會普遍獲得性能的提升”。
Geraint強調,Arm在LLVM上的投入有很大一部分是集中在了SVE2指令的性能提升的——也就是Armv9架構引入的矢量擴展。
 ?Arm對于SVE2真正產生價值的目標是,“第一我們要確保 SVE2 的代碼生成盡可能做好,這就意味著我們要保證 LLVM 能做矢量化的工作,同時又能確保 LLVM 能夠矢量化目前它不能做到的事情。”也就是在LLVM可實現矢量化工作的基礎上,做得比NEON更好,比如scatter/gather指令和predicted指令。
另一方面LLVM 16版本引入了Function Multi-Versioning,“所以開發者能夠更加容易確保其函數的利用和 SVE2版本都能夠生成,并且在運行的時候自動選擇正確的版本”。“作為一個開發者你不必同時做兩個二進位文件,或者每一次都進行 CPU 的檢測。”這是為兼容性所做的考量。
不過我們知道,現階段SVE2面臨的一個實際問題還是在于利用率,和移動平臺是否真正需要SVE2。所以Geraint特別提到SVE2對于圖像處理非常適用。
?Arm對于SVE2真正產生價值的目標是,“第一我們要確保 SVE2 的代碼生成盡可能做好,這就意味著我們要保證 LLVM 能做矢量化的工作,同時又能確保 LLVM 能夠矢量化目前它不能做到的事情。”也就是在LLVM可實現矢量化工作的基礎上,做得比NEON更好,比如scatter/gather指令和predicted指令。
另一方面LLVM 16版本引入了Function Multi-Versioning,“所以開發者能夠更加容易確保其函數的利用和 SVE2版本都能夠生成,并且在運行的時候自動選擇正確的版本”。“作為一個開發者你不必同時做兩個二進位文件,或者每一次都進行 CPU 的檢測。”這是為兼容性所做的考量。
不過我們知道,現階段SVE2面臨的一個實際問題還是在于利用率,和移動平臺是否真正需要SVE2。所以Geraint特別提到SVE2對于圖像處理非常適用。
 ?他舉了iToF(indirect Time-of-Flight)的例子,即用基于相位差的ToF方法來構建深度圖。基于的Halide圖像處理算法,都用Cortex-A720分別在FP32和FP16精度下跑,則SVE2相比NEON,分別有10%和23%的性能領先。這和SVE2的scatter/gather指令有很大的關系,也就是“從內存不連續部分檢索數據”的效率。
軟件相關的提升,還有個有趣的部分是Android Adaptability Framework動態性能自適應框架(ADPF)。ADPF為開發者提供了一些API,包括ADPF Hint API,Thermal API,Game State API等。比如其中的Hint API,可讓操作系統以更快的速度來進行CPU頻率、資源的調節,達成性能需求或者節能;而Thermal API顯然是溫控相關的。
?他舉了iToF(indirect Time-of-Flight)的例子,即用基于相位差的ToF方法來構建深度圖。基于的Halide圖像處理算法,都用Cortex-A720分別在FP32和FP16精度下跑,則SVE2相比NEON,分別有10%和23%的性能領先。這和SVE2的scatter/gather指令有很大的關系,也就是“從內存不連續部分檢索數據”的效率。
軟件相關的提升,還有個有趣的部分是Android Adaptability Framework動態性能自適應框架(ADPF)。ADPF為開發者提供了一些API,包括ADPF Hint API,Thermal API,Game State API等。比如其中的Hint API,可讓操作系統以更快的速度來進行CPU頻率、資源的調節,達成性能需求或者節能;而Thermal API顯然是溫控相關的。
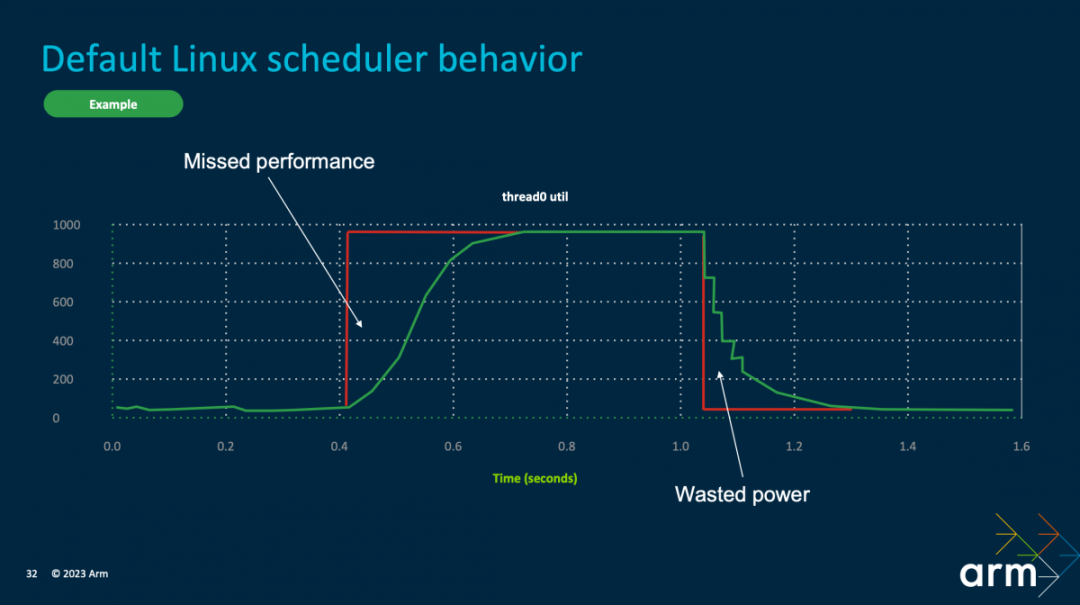 ?比如具體到PerformanceHint API,這個API存在的價值在于,它能為操作系統提供應用或游戲目標負載的更多信息,那么CPU可以更精準地調控資源——它比Linux內核的scheduler行為更高效。比如governor需要200ms從空閑狀態拉升到最高頻率,而在該工作完成后,頻率還有個緩慢回落的過程。這些行為不夠高效。
從應用或游戲直接把負載預期持續時間、目標發給操作系統,調度策略就會高效許多,可以減少掉幀、提升能效。Geraint說,PerformanceHint API的應用可確保正確的工作放在正確的核心上,“而不是用以前的工具如setAffinity進行猜測”。
Pixel手機將ADPF應用到了SurfaceFlinger(Android負責繪制應用UI的服務),減少了50%的掉幀、節電6%。PerformanceHint API在 Android 14成為必選項;Unity游戲引擎中,它也作為Adaptability Plugin插件存在。
?比如具體到PerformanceHint API,這個API存在的價值在于,它能為操作系統提供應用或游戲目標負載的更多信息,那么CPU可以更精準地調控資源——它比Linux內核的scheduler行為更高效。比如governor需要200ms從空閑狀態拉升到最高頻率,而在該工作完成后,頻率還有個緩慢回落的過程。這些行為不夠高效。
從應用或游戲直接把負載預期持續時間、目標發給操作系統,調度策略就會高效許多,可以減少掉幀、提升能效。Geraint說,PerformanceHint API的應用可確保正確的工作放在正確的核心上,“而不是用以前的工具如setAffinity進行猜測”。
Pixel手機將ADPF應用到了SurfaceFlinger(Android負責繪制應用UI的服務),減少了50%的掉幀、節電6%。PerformanceHint API在 Android 14成為必選項;Unity游戲引擎中,它也作為Adaptability Plugin插件存在。
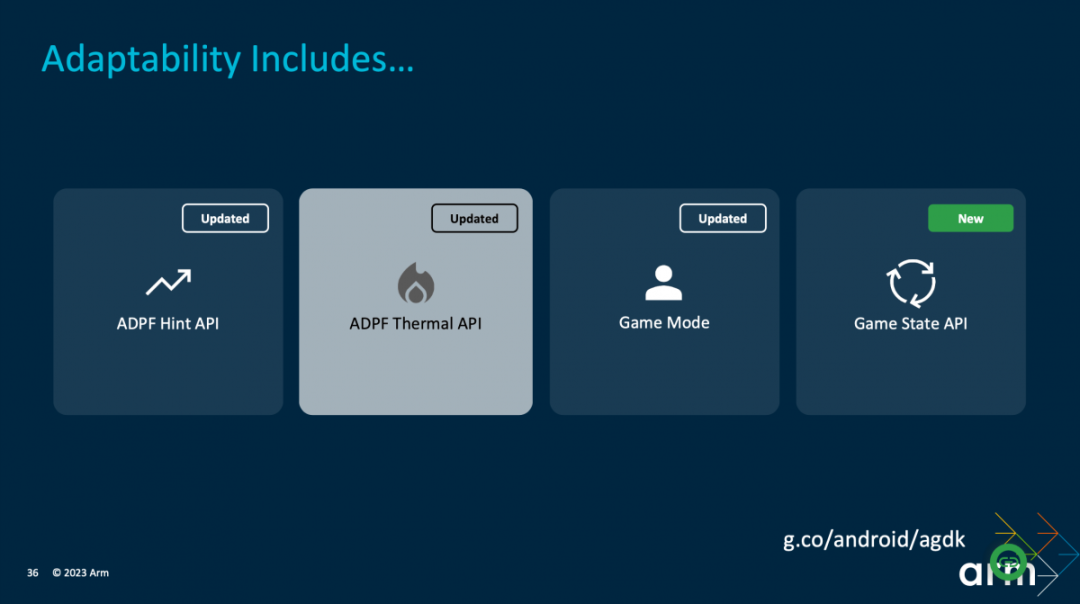 ?還有個ADPF Thermal API,Geraint也做了分享,包括在游戲《Candy Clash》里的測試結果。其本質都在為達成更好的游戲體驗,基于設備的熱狀態(thermal state),動態適配游戲畫面渲染質量(包括幀率、分辨率、LOD、貼圖),則即便是老手機也不會發生過熱,而且可穩幀、降低功耗,測試結果是平均幀提高25%,CPU功耗降低最多18%。
ADPF以及Unity的自適應性能特性顯然是需要和Arm IP配合的。當然了另一方面這也需要開發者去使用對應的API。這類API理所應當的,不僅成為軟件層面性能提升的組成部分,也是Arm加強生態粘性的關鍵。
?還有個ADPF Thermal API,Geraint也做了分享,包括在游戲《Candy Clash》里的測試結果。其本質都在為達成更好的游戲體驗,基于設備的熱狀態(thermal state),動態適配游戲畫面渲染質量(包括幀率、分辨率、LOD、貼圖),則即便是老手機也不會發生過熱,而且可穩幀、降低功耗,測試結果是平均幀提高25%,CPU功耗降低最多18%。
ADPF以及Unity的自適應性能特性顯然是需要和Arm IP配合的。當然了另一方面這也需要開發者去使用對應的API。這類API理所應當的,不僅成為軟件層面性能提升的組成部分,也是Arm加強生態粘性的關鍵。
 ?就軟件和工具,Kinjal聊到了當前市場需求熱點之一的AI,機器學習。Arm在這方面的中間件和庫主要是Arm NN與Arm Compute Library。
Kinjal說:“開發者每個季度都可以從Arm發布的最新軟件庫優化上實現更高的機器學習應用開發。”今年1月份,Android NN和ACL已經可以在谷歌應用商店下載;到2024年,兩者都可以直接在GMS(Google Mobile Services)上直接訪問——在更廣的范圍內,成為Android的NN標準。
?就軟件和工具,Kinjal聊到了當前市場需求熱點之一的AI,機器學習。Arm在這方面的中間件和庫主要是Arm NN與Arm Compute Library。
Kinjal說:“開發者每個季度都可以從Arm發布的最新軟件庫優化上實現更高的機器學習應用開發。”今年1月份,Android NN和ACL已經可以在谷歌應用商店下載;到2024年,兩者都可以直接在GMS(Google Mobile Services)上直接訪問——在更廣的范圍內,成為Android的NN標準。
 ?開發工具相關的,有個促成軟件優化的改進,Profile Guided Optimization的性能提升。開發者借助PGO能夠“收集應用執行需要的各類數據、信息,基于它進行優化,信息的收集能幫助大家了解到執行這個應用的瓶頸,從而有指導的進行調整,獲得最大收益”。
Armv9架構通過名為ETE(Embedded Trace Extention)和TRBE(TRace Buffer Extention)的擴展,來捕捉這些數據,做“基于硬件的追蹤”。最終在程序的binary size、追蹤捕獲數據對性能方面都達成了影響最低。
明年手機性能提升的一些數字參考
最后來談談可能更多人關心的性能提升數字,其中的絕大部分應該都是上述參考設計的表現提升,也要考慮進軟件層面的提升。既然是系統層面的,那就是高層級的系統測試了,對于反映未來手機性能變化應該相比IP層面的性能和能效提升數字更有價值。
?開發工具相關的,有個促成軟件優化的改進,Profile Guided Optimization的性能提升。開發者借助PGO能夠“收集應用執行需要的各類數據、信息,基于它進行優化,信息的收集能幫助大家了解到執行這個應用的瓶頸,從而有指導的進行調整,獲得最大收益”。
Armv9架構通過名為ETE(Embedded Trace Extention)和TRBE(TRace Buffer Extention)的擴展,來捕捉這些數據,做“基于硬件的追蹤”。最終在程序的binary size、追蹤捕獲數據對性能方面都達成了影響最低。
明年手機性能提升的一些數字參考
最后來談談可能更多人關心的性能提升數字,其中的絕大部分應該都是上述參考設計的表現提升,也要考慮進軟件層面的提升。既然是系統層面的,那就是高層級的系統測試了,對于反映未來手機性能變化應該相比IP層面的性能和能效提升數字更有價值。
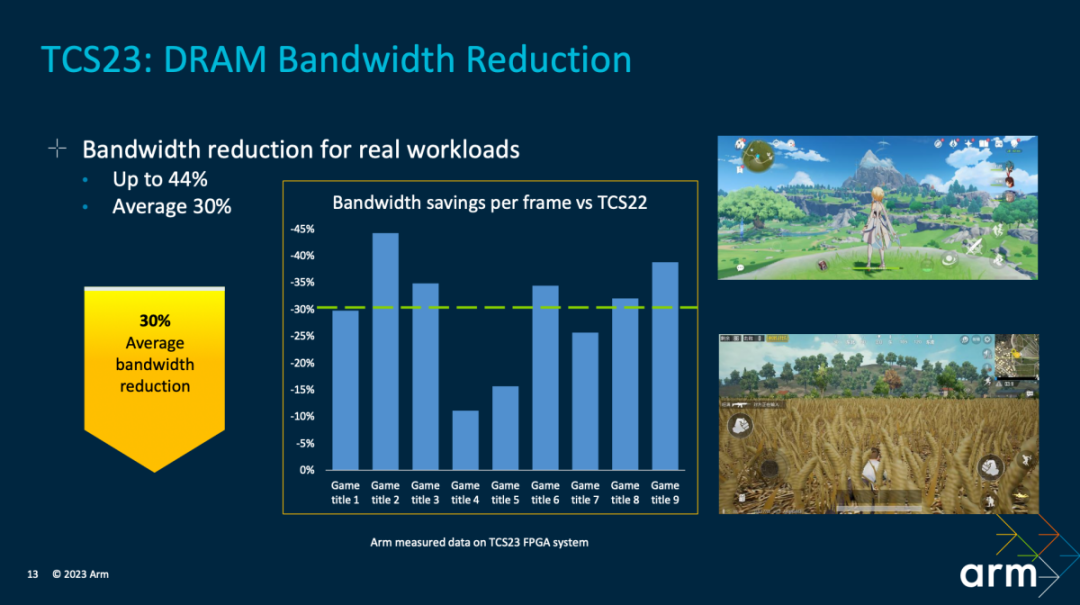 ?首先上述對比是不同游戲,每一幀的DRAM帶寬需求縮減。Arm測試了不少游戲。相比TCS22,最高可達成44%的帶寬縮減,平均縮減幅度30%。換句話說就是片外主內存的依賴更低了,這對提升游戲能效表現是很有價值的。
這也對應地帶來了20%的功耗節省(測試這些游戲在60fps下持續性能發揮)。“決定,這些節約下來的能耗,它們或被用于 SoC 功率的計算中,來實現性能進一步提升,或者又可以把它們存起來,從而實現更長電池續航的時間,讓用戶能夠玩更長時間的游戲。”Kinjal說。
前文也部分提到了圖形計算目標之一的帶寬縮減,主要是DVS延遲頂點著色技術的加入,以及system cache分配策略優化。
?首先上述對比是不同游戲,每一幀的DRAM帶寬需求縮減。Arm測試了不少游戲。相比TCS22,最高可達成44%的帶寬縮減,平均縮減幅度30%。換句話說就是片外主內存的依賴更低了,這對提升游戲能效表現是很有價值的。
這也對應地帶來了20%的功耗節省(測試這些游戲在60fps下持續性能發揮)。“決定,這些節約下來的能耗,它們或被用于 SoC 功率的計算中,來實現性能進一步提升,或者又可以把它們存起來,從而實現更長電池續航的時間,讓用戶能夠玩更長時間的游戲。”Kinjal說。
前文也部分提到了圖形計算目標之一的帶寬縮減,主要是DVS延遲頂點著色技術的加入,以及system cache分配策略優化。
 ?在GFXBench系統性能測試里,兩個比較知名的測試項Manhattan 3.0和Aztec Ruins High中,TCS23分別有21%和20%的性能提升。這是更高的頻率、更多的shader核心,外加系統級優化帶來的。未來的游戲手機又可以期待以下了。
CPU方面,Arm主要給的是Geekbench 6多線程測試,和Speedometer 2.1網頁瀏覽測試。需要注意的是,GB6的這個測試,TCS23這邊的CPU搭配方法是1+5+2,多線程性能提升27%。
Kinjal解釋說之所以這樣搭配,是因為“越來越多的人們開始比較多線程指標,并且它也成為我們合作伙伴進行優化的一個目標。我們看到許多 AAA 級的游戲會產生高性能線程,而且數量正在不斷增加,因此就對CPU集群持續的多線程性能提出了要求。我們通過這個基準測試來展示全新 IP 效率的提升以及制程技術的改進,可以滿足持續多線程性能方面的要求。”
Speedometer這邊是1+3+4,其中還加入了軟件優化——即Arm與谷歌就Chromium的合作,開啟PAC/BTI安全特性。軟件優化達成的更高性能提升。
?在GFXBench系統性能測試里,兩個比較知名的測試項Manhattan 3.0和Aztec Ruins High中,TCS23分別有21%和20%的性能提升。這是更高的頻率、更多的shader核心,外加系統級優化帶來的。未來的游戲手機又可以期待以下了。
CPU方面,Arm主要給的是Geekbench 6多線程測試,和Speedometer 2.1網頁瀏覽測試。需要注意的是,GB6的這個測試,TCS23這邊的CPU搭配方法是1+5+2,多線程性能提升27%。
Kinjal解釋說之所以這樣搭配,是因為“越來越多的人們開始比較多線程指標,并且它也成為我們合作伙伴進行優化的一個目標。我們看到許多 AAA 級的游戲會產生高性能線程,而且數量正在不斷增加,因此就對CPU集群持續的多線程性能提出了要求。我們通過這個基準測試來展示全新 IP 效率的提升以及制程技術的改進,可以滿足持續多線程性能方面的要求。”
Speedometer這邊是1+3+4,其中還加入了軟件優化——即Arm與谷歌就Chromium的合作,開啟PAC/BTI安全特性。軟件優化達成的更高性能提升。
 ?還有個CPU的對比,是比較CPU的機器學習性能,具體到對象識別、分類、人體姿勢追蹤等;比的主要就是Int8推理。不同核心的性能提升幅度,相比TCS22如上圖所示。
圖中右邊是GPU的AI超分性能提升達成了4倍。這里面除了CPU、GPU算力加強,也在于Arm NN和Arm Compute Library的進化。
?還有個CPU的對比,是比較CPU的機器學習性能,具體到對象識別、分類、人體姿勢追蹤等;比的主要就是Int8推理。不同核心的性能提升幅度,相比TCS22如上圖所示。
圖中右邊是GPU的AI超分性能提升達成了4倍。這里面除了CPU、GPU算力加強,也在于Arm NN和Arm Compute Library的進化。
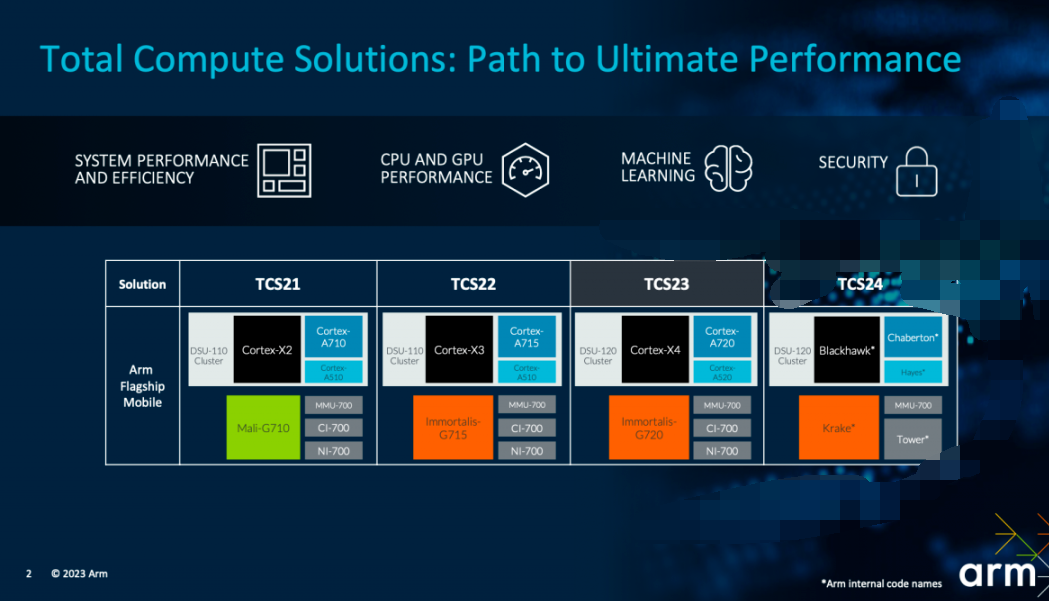 ?以上就是從解決方案層面Arm闡釋的TCS23了。不過Kinjal提到,TCS23是個可伸縮的平臺,面向廣闊的客戶端設備,不只是高端手機設備。比如說Immortalis-G720彈性縮放有下設Mali-G720/G620可選配;而在CPU集群方面,Cortex-A720核心有著對應的可伸縮選項。
“我們最新發布的產品也將推動下一代的旗艦智能手機。”Arm產品營銷副總裁Ian Smythe說。實際上他在開篇還展望了未來的TCS設計,如上圖,包括Blackhawk CPU以及Krake GPU等關鍵IP,“我們還著眼于未來。我們對 CPU 和 GPU 產品路線圖的承諾更勝以往,在接下來的幾年里,我們將在包括 Krake GPU 和 Blackhawk CPU 等關鍵 IP 上加大投入,以滿足合作伙伴對于計算和圖形性能的要求。”
?以上就是從解決方案層面Arm闡釋的TCS23了。不過Kinjal提到,TCS23是個可伸縮的平臺,面向廣闊的客戶端設備,不只是高端手機設備。比如說Immortalis-G720彈性縮放有下設Mali-G720/G620可選配;而在CPU集群方面,Cortex-A720核心有著對應的可伸縮選項。
“我們最新發布的產品也將推動下一代的旗艦智能手機。”Arm產品營銷副總裁Ian Smythe說。實際上他在開篇還展望了未來的TCS設計,如上圖,包括Blackhawk CPU以及Krake GPU等關鍵IP,“我們還著眼于未來。我們對 CPU 和 GPU 產品路線圖的承諾更勝以往,在接下來的幾年里,我們將在包括 Krake GPU 和 Blackhawk CPU 等關鍵 IP 上加大投入,以滿足合作伙伴對于計算和圖形性能的要求。”
?具體如上圖所示,大部分人關心的是處在中間的環節,即Armv9架構及其上的存儲與互聯一致性、各種核心IP。實際TCS還包括圖中的軟件、開發工具,以及以先進工藝做Arm IP實施的物理IP。
Arm終端事業部產品管理高級總監Kinjal Dave說:“談到解決方案,為什么 Arm 要采取這樣一種全局的方法論來開發解決方案,不斷推高性能、提高效率,本身變得越來越難且成本高昂。其實這對 Arm 來說,意味著我們每年推出的 TCS 在性能跟效率方面,都必須實現進步。所以,我們要采取一種平衡。”
Kinjal說Arm這些年來始終努力在benchmark和真實使用場景之間做平衡:“一方面,單獨的 IP 要不斷把它做強,另外一方面把這些單獨的 IP 集合在一起時,總體的系統級別也要實現性能效率的雙提升。” “為我們的合作伙伴提供融合了這些單獨IP的系統級解決方案所帶來的完整性能提升。”
隨著摩爾定律的放緩,以及設計層面各種經典技術的全面上線,這兩年單獨IP微架構層面帶來的性能和效率提升也遠不及此前那么大了,從更系統的角度來做考量也是半導體鏈條上各個玩家的共識。
所以這篇文章我們就從TCS23整體的角度來看看這一代平臺的改進,其中會涉及到上述IP,但不會過多深入。另外很難得的是,Arm特別用一個主題演講的章節去談了軟件改進,包括編譯器、SVE2指令、Android動態性能框架等,本文也會略有涉及。
TCS23參考設計
本文就不過多提單獨IP的性能與效率變化了,包括Cortex-X4相比X3性能提升15%,Cortex-A720相比A715能效提升20%,Cortex-A520相比A510能效提升22%,DSU提升動態功耗表現、針對閑置與低負載場景的新功耗模式,Immortalis-G720性能提升15%、帶寬用量降低40%等等。
?不過Arm針對TCS23就FPGA級別做了參考設計,“代表真實的芯片設備”。Arm做參考設計的原因,一是IP越來越復雜,其次是系統中的許多特性是需要跨系統的,比如說這次Arm一直在談的MTE(Memory Tagging Extention)安全特性;
另外還包括“越來越多樣化終端使用場景的出現”,以及“對這些芯片設計工作來說,在設計選擇以及平衡方面的取舍難度也提高了。”
?上面這張圖就是Arm TCS23參考設計。大框架上CPU、GPU都用了這一代最新IP。不同核心組成的CPU集群,“與DSU-120共同連接到共享系統的背板(backplane)”;借助system cache(SLC)所在的CoreLink CI-700,一邊連接到Immortalis-G720 GPU。
這里CoreLink CI-700作為存儲系統的核心,為所有的IO流量提供一個匯聚點(也用于實現MTE)。同時,NI-700為所有其他流量提供一條通往DRAM獨立的路徑;“能進行QoS執行,允許不同的流量類型一起流動,而不會出現交叉流,或者互相阻塞的情況”。
系統級解決方案的奧義
參考設計的CPU部分,是1x Cortex-X4, 3x Cortex-A720, 4x Cortex-A520的配置;DSU-120配了8MB L3 cache。Arm認為1+3+4是性能和效率可達成均衡的配置方案。不過在多線程性能對比時,Arm也有基于1+5+2的搭配呈現。
?Kinjal沒有細談這部分的配置。不過這里主要看的還是系統級別的工作。他強調CPU集群的關鍵首先是如何利用CPU和行為架構實現跨越三個層級的性能動態范圍;其次影響CPU性能很重要的因素是DRAM延遲。
對于后者,一方面,“我們進行了DRAM結構性的靜態延遲優化”,“首先是DynamIQ共享單元內和通往內存的路徑中的時鐘配置的選擇,也就是在這個領域資源的競爭”——在這個過程里,需要進行DynamIQ時鐘配置優化,“同時要最小化數量的選擇”;
另一方面,還需要考慮“加載系統內存層面下的動態優先級別”,包括“GPU、攝像頭以及其他多媒體管道等”,“它們可能要同時訪問內存”。這些都要求在進行CPU集群配置時,做相應的考量。
?在CPU集群的優化上,首先是基于“CPU核心微架構”提供“最為廣泛的動態范圍”,“跨越三層(Cortex X4,Cortex A720和Cortex A520)”。其中包括DVFS動態調整,線程核心遷移等;適配各種負載場景、應對不同的性能目標。此間涵蓋以最優化的效率,針對不同的運行場景,包括了分配多少CPU資源,如頻率、響應、哪些核心參與等等。
“計算IP級的系統級解決方案,包括不同電源選擇的模式,不同時鐘選項的配置”,“在TCS23中我們添加了一個邏輯增強型降功耗的模式”。
“在解決方案層級,我們的電源控制固件的堆棧以及調度器一起工作,能實現基于不同的使用場景的選擇,這點很關鍵。”Kinjal說,“TCS23解決方案中還有一個系統控制處理器,它能夠協調傳感器控制框架,在各個CPU內核以及DSU-120工作點之間移動的時候充分考慮到散熱以及輸電的一些限制因素。”“跨整個CPU集群,我們還實施了積極的時鐘門控以及時空調節的機制,來節約動態功耗。”
?另一個關鍵是細粒度的電源模式——這也是當代低功耗設計的精髓所在。上面這張圖每種顏色代表“單獨的電源連接供電”。Arm在此的工作之一就是管理供電的復雜性,“我們有專門用于電壓供應的管理、電源傳輸、網絡控制電源控制部件。
“這里電源控制部件是與調度器,以及操作系統的電源管理軟件共同協調工作的。”
?圖形計算相關的部分,Arm強調了3個解決方案層面的關注點,分別是帶寬、功耗,與安全性。“我們將Arm Immotalis-G720集成到TCS23解決方案中,配置了MMU-700,與GPU實現共同的優化”。其中的某些部分,也會在我們后續的IP文章GPU相關部分做更詳盡的介紹——比如節約帶寬的Deferred Vertex Shading延遲頂點著色。
從大方向來看,節約帶寬方面的工作包括AFRC與AFBC無損壓縮——管線不同階段的數據壓縮始終是GPU不變的話題之一,它對于DRAM訪問需求的降低,提供更大的發熱空間都有價值;IO一致性,將緩存維護開銷降到最低,并由CoreLink CI-700與Immortalis-G720合作,來達成性能的提升;以及利用大型系統高速緩存(system cache),而且還有個“內存分配提示,優先考慮哪部分要存在高速緩存中”。
能效優化部分,一方面是利用針對每個shader核心的power gating,另外就是核心群組的節電模式等。“TCS23解決方案提供了一套完整的參考:Immortalis-G720驅動如何與我們的參考固件堆棧協同,實現電源控制、動態電壓與頻率的調節。”另外,“我們在GPU中也實施了積極的clock gating方案,用以管理動態功耗。”
安全性方面,MMU-700的集成對于支持DRAM保護內容的安全處理,以及支持Android虛擬化框架是至關重要的。
?結合包括cache、連接至內存的延遲、floorplan以及內存支持方面的變化,參考設計達成綜合的帶寬吞吐,相比于前代提升了33%。
所以在總結性發言里,Kinjal再度強調的一點就是基于TCS全面計算解決方案,“Arm已經超越單個IP產品,為客戶實現端到端系統級的優化,從而釋放整個SoC系統全面性能”。這是TCS存在的核心價值。
軟件帶來的性能提升
除了這些比較多人關注的IP之外,如文首所述,TCS作為解決方案還涵蓋了工具、軟件、物理/POP IP等。這里我們再談一談工具和軟件,TCS23不僅升級了IP,也升級了軟件與工具。Arm終端事業部生態系統及工程高級總監Geraint North說Arm的工程師中,超過45%都是軟件工程師,底層部分涵蓋了驅動、Linux內核,往上則有軟件框架、性能分析工具、開發者教學、最佳實踐等。
?軟件自然是位于硬件之上的層級,這部分Geraint主要談了64bit完全遷移、compiler編譯器性能提升,以及ADPF(Android自適應性能框架)帶來的軟件層面的性能提升。
實際上就軟件相關的主題演講,Arm還特別花篇幅去談了安全,包括MTE、PAC/BTI技術及對應生態——談到與谷歌、Unity在安全特性上的合作,甚至在MTE(Memory Tagging Extension)技術上,還特別找來快手、聯發科、vivo這些合作伙伴站臺。不過這次我們不會把筆墨放在安全問題上,即便這個問題就當代移動技術而言正變得格外重要。
有關64位生態遷移的話題,桎梏并不在芯片和操作系統廠商身上,而在最上層的App開發者身上。自11年以前,CPU層面提供64位支持(Cortex-A57/A53),以及2年后Android操作系統跟進,一直到今年Pixel 7作為純64位Android配置的手機問世,這仍然是個相當漫長的過程。而TCS23是徹底構建起純64bit支持集群的一代。
?從安全和性能兩個角度來看,64位都顯然是個更好的選擇。安全方面,64bit提供更大的內存地址空間,在地址空間布局隨機化(ASLR)等特性實現上會更為有效;也為Arm多番提及的MTE和PAC(Pointer Authentication)提供了實現基礎。
而在性能方面,Arm給出了上面這張圖。Cortex-A7x系列核心,從A76到A720的SPECint2006性能變化情況:32位與64位應用的性能差別是在逐步擴大的。至Cortex-A710這一代性能差距擴大至33%,且后續的IP上32位應用不再能獲得性能紅利。Geraint說:“這種差距的拉大,一部分是由于 IP 實施的決策,我們會把更加寶貴的時間以及硅面積集中在 64 位路徑的優化之上。”
“軟件方面也是如此,我們的編譯器和庫優化團隊,都把工作重點聚焦在 64 位上。如果現在你還是在做 32 位的開發,那么我們做的這些工作可能就不能為你提供賦能。”即便目前歷史遺留問題多少都還在,TCS23應當也意味著移動平臺的64位攻堅戰進入了尾聲。
?編譯器方面,Geraint說過去3年時間里,LLVM實現了12%的性能提升。所以“這種工作是非常有價值的,因為它不僅提高了最新一代的 CPU 性能,不管這個設備是基于 Armv8 還是 Armv9,當它搭載最新的工具鏈重新編譯的時候,會普遍獲得性能的提升”。
Geraint強調,Arm在LLVM上的投入有很大一部分是集中在了SVE2指令的性能提升的——也就是Armv9架構引入的矢量擴展。
?Arm對于SVE2真正產生價值的目標是,“第一我們要確保 SVE2 的代碼生成盡可能做好,這就意味著我們要保證 LLVM 能做矢量化的工作,同時又能確保 LLVM 能夠矢量化目前它不能做到的事情。”也就是在LLVM可實現矢量化工作的基礎上,做得比NEON更好,比如scatter/gather指令和predicted指令。
另一方面LLVM 16版本引入了Function Multi-Versioning,“所以開發者能夠更加容易確保其函數的利用和 SVE2版本都能夠生成,并且在運行的時候自動選擇正確的版本”。“作為一個開發者你不必同時做兩個二進位文件,或者每一次都進行 CPU 的檢測。”這是為兼容性所做的考量。
不過我們知道,現階段SVE2面臨的一個實際問題還是在于利用率,和移動平臺是否真正需要SVE2。所以Geraint特別提到SVE2對于圖像處理非常適用。
?他舉了iToF(indirect Time-of-Flight)的例子,即用基于相位差的ToF方法來構建深度圖。基于的Halide圖像處理算法,都用Cortex-A720分別在FP32和FP16精度下跑,則SVE2相比NEON,分別有10%和23%的性能領先。這和SVE2的scatter/gather指令有很大的關系,也就是“從內存不連續部分檢索數據”的效率。
軟件相關的提升,還有個有趣的部分是Android Adaptability Framework動態性能自適應框架(ADPF)。ADPF為開發者提供了一些API,包括ADPF Hint API,Thermal API,Game State API等。比如其中的Hint API,可讓操作系統以更快的速度來進行CPU頻率、資源的調節,達成性能需求或者節能;而Thermal API顯然是溫控相關的。
?比如具體到PerformanceHint API,這個API存在的價值在于,它能為操作系統提供應用或游戲目標負載的更多信息,那么CPU可以更精準地調控資源——它比Linux內核的scheduler行為更高效。比如governor需要200ms從空閑狀態拉升到最高頻率,而在該工作完成后,頻率還有個緩慢回落的過程。這些行為不夠高效。
從應用或游戲直接把負載預期持續時間、目標發給操作系統,調度策略就會高效許多,可以減少掉幀、提升能效。Geraint說,PerformanceHint API的應用可確保正確的工作放在正確的核心上,“而不是用以前的工具如setAffinity進行猜測”。
Pixel手機將ADPF應用到了SurfaceFlinger(Android負責繪制應用UI的服務),減少了50%的掉幀、節電6%。PerformanceHint API在 Android 14成為必選項;Unity游戲引擎中,它也作為Adaptability Plugin插件存在。
?還有個ADPF Thermal API,Geraint也做了分享,包括在游戲《Candy Clash》里的測試結果。其本質都在為達成更好的游戲體驗,基于設備的熱狀態(thermal state),動態適配游戲畫面渲染質量(包括幀率、分辨率、LOD、貼圖),則即便是老手機也不會發生過熱,而且可穩幀、降低功耗,測試結果是平均幀提高25%,CPU功耗降低最多18%。
ADPF以及Unity的自適應性能特性顯然是需要和Arm IP配合的。當然了另一方面這也需要開發者去使用對應的API。這類API理所應當的,不僅成為軟件層面性能提升的組成部分,也是Arm加強生態粘性的關鍵。
?就軟件和工具,Kinjal聊到了當前市場需求熱點之一的AI,機器學習。Arm在這方面的中間件和庫主要是Arm NN與Arm Compute Library。
Kinjal說:“開發者每個季度都可以從Arm發布的最新軟件庫優化上實現更高的機器學習應用開發。”今年1月份,Android NN和ACL已經可以在谷歌應用商店下載;到2024年,兩者都可以直接在GMS(Google Mobile Services)上直接訪問——在更廣的范圍內,成為Android的NN標準。
?開發工具相關的,有個促成軟件優化的改進,Profile Guided Optimization的性能提升。開發者借助PGO能夠“收集應用執行需要的各類數據、信息,基于它進行優化,信息的收集能幫助大家了解到執行這個應用的瓶頸,從而有指導的進行調整,獲得最大收益”。
Armv9架構通過名為ETE(Embedded Trace Extention)和TRBE(TRace Buffer Extention)的擴展,來捕捉這些數據,做“基于硬件的追蹤”。最終在程序的binary size、追蹤捕獲數據對性能方面都達成了影響最低。
明年手機性能提升的一些數字參考
最后來談談可能更多人關心的性能提升數字,其中的絕大部分應該都是上述參考設計的表現提升,也要考慮進軟件層面的提升。既然是系統層面的,那就是高層級的系統測試了,對于反映未來手機性能變化應該相比IP層面的性能和能效提升數字更有價值。
?首先上述對比是不同游戲,每一幀的DRAM帶寬需求縮減。Arm測試了不少游戲。相比TCS22,最高可達成44%的帶寬縮減,平均縮減幅度30%。換句話說就是片外主內存的依賴更低了,這對提升游戲能效表現是很有價值的。
這也對應地帶來了20%的功耗節省(測試這些游戲在60fps下持續性能發揮)。“決定,這些節約下來的能耗,它們或被用于 SoC 功率的計算中,來實現性能進一步提升,或者又可以把它們存起來,從而實現更長電池續航的時間,讓用戶能夠玩更長時間的游戲。”Kinjal說。
前文也部分提到了圖形計算目標之一的帶寬縮減,主要是DVS延遲頂點著色技術的加入,以及system cache分配策略優化。
?在GFXBench系統性能測試里,兩個比較知名的測試項Manhattan 3.0和Aztec Ruins High中,TCS23分別有21%和20%的性能提升。這是更高的頻率、更多的shader核心,外加系統級優化帶來的。未來的游戲手機又可以期待以下了。
CPU方面,Arm主要給的是Geekbench 6多線程測試,和Speedometer 2.1網頁瀏覽測試。需要注意的是,GB6的這個測試,TCS23這邊的CPU搭配方法是1+5+2,多線程性能提升27%。
Kinjal解釋說之所以這樣搭配,是因為“越來越多的人們開始比較多線程指標,并且它也成為我們合作伙伴進行優化的一個目標。我們看到許多 AAA 級的游戲會產生高性能線程,而且數量正在不斷增加,因此就對CPU集群持續的多線程性能提出了要求。我們通過這個基準測試來展示全新 IP 效率的提升以及制程技術的改進,可以滿足持續多線程性能方面的要求。”
Speedometer這邊是1+3+4,其中還加入了軟件優化——即Arm與谷歌就Chromium的合作,開啟PAC/BTI安全特性。軟件優化達成的更高性能提升。
?還有個CPU的對比,是比較CPU的機器學習性能,具體到對象識別、分類、人體姿勢追蹤等;比的主要就是Int8推理。不同核心的性能提升幅度,相比TCS22如上圖所示。
圖中右邊是GPU的AI超分性能提升達成了4倍。這里面除了CPU、GPU算力加強,也在于Arm NN和Arm Compute Library的進化。
?以上就是從解決方案層面Arm闡釋的TCS23了。不過Kinjal提到,TCS23是個可伸縮的平臺,面向廣闊的客戶端設備,不只是高端手機設備。比如說Immortalis-G720彈性縮放有下設Mali-G720/G620可選配;而在CPU集群方面,Cortex-A720核心有著對應的可伸縮選項。
“我們最新發布的產品也將推動下一代的旗艦智能手機。”Arm產品營銷副總裁Ian Smythe說。實際上他在開篇還展望了未來的TCS設計,如上圖,包括Blackhawk CPU以及Krake GPU等關鍵IP,“我們還著眼于未來。我們對 CPU 和 GPU 產品路線圖的承諾更勝以往,在接下來的幾年里,我們將在包括 Krake GPU 和 Blackhawk CPU 等關鍵 IP 上加大投入,以滿足合作伙伴對于計算和圖形性能的要求。”
審核編輯 黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
ARM
+關注
關注
134文章
9121瀏覽量
368220 -
手機
+關注
關注
35文章
6888瀏覽量
157827 -
cpu
+關注
關注
68文章
10889瀏覽量
212373 -
gpu
+關注
關注
28文章
4760瀏覽量
129129
發布評論請先 登錄
相關推薦
明年用5G手機? 最新數據顯示:沒那么簡單
進程仍在最后的攻堅階段,5G建設暫時不會占用國家過多的資源。此外,按照以往通訊升級的經驗,從4G到5G還會受到地域、資費等限制。但目前,5G通訊的大部分標準還未擬定,明年全國覆蓋5G網絡的可能性不大,更別說使用5G手機了。綜上所
發表于 10-24 15:58
搭載RISC-V芯片的手機,或將于明年正式推出
。最終,RISC-V作為硬件,打鐵還要自身硬,RISC-V芯片必須先得證明自己的能力,比如芯片廠商推出性能更強的產品。在硬件基礎打好了后,或許就如同蘋果從x86轉向ARM一樣,包括Android、甚至未來
發表于 12-17 08:00
如何使用ESP8266和TAOS TCS23的顏色識別板?
我設法使用 ESP8266 和 TAOS TCS230 顏色識別模塊實現了顏色識別板。我必須采取一些技巧才能讓 GPIO 能夠處理方波輸入和頻率,但最終讓它工作并實現了原型板。這是項目的描述
發表于 05-24 08:46
TCS2315 GPRS手機解決方案
TCS2315 GPRS手機解決方案
TI 公司的TCS2315 GPRS手機解決方案是第三代基于GSM的超低成本手機,采用先進的65-n
發表于 12-26 14:53
?1187次閱讀
全新的Arm全面計算解決方案實現基于Arm技術的移動未來
Arm 高級副總裁兼終端事業部總經理 Chris Bergey 表示:“TCS23包含了基于全新第五代 GPU 架構、可實現終極視覺體驗的全新Arm Immortalis GPU,助力 Ar

全新的Arm全面計算解決方案實現基于Arm技術的移動未來
Arm? 今日宣布推出 2023 全面計算解決方案(TCS23),該解決方案將成為最重要的移動計算平臺,為智能手機帶來絕佳的解決方案。TCS23 提供一整套針對特定工作負載而設計與優化

Arm TCS23現迄今最快處理器IP組合,前瞻定義旗艦手機SoC性能,為生成式AI而來
最近Arm推出2023 全面計算解決方案(TCS23),發布最新CPU和GPU IP等產品。沒有意外,高通和聯發科的下一代旗艦手機SoC將采用Arm最新的CPU架構Cortex-X4,
從Arm TCS23看Arm對移動設備未來的洞察
5月29日Arm正式推出 Arm 2023 全面計算解決方案(TCS23), 包含基于全新第五代 GPU 架構、可實現終極視覺體驗的全新Arm Immortalis GPU,助力
移動設備部署機器學習,Arm談如何賦能移動AI
計算解決方案 (TCS23)?持續引領這樣的應用趨勢。在最近,Arm高級副總裁兼終端事業部總經理Chris Bergey接受媒體采訪,分享了Arm對移動AI發展的看法以及Arm如何賦能
Arm攜手MediaTek和vivo將TCS23運用于新一代旗艦智能手機
2023 年五月,Arm 宣布推出移動計算平臺——2023 全面計算解決方案 (Arm TCS23)。
TCS23的軟件棧和FVP加速移動生態的產品開發方案一覽
今年五月,Arm 發布了 2023 全面計算解決方案 (TCS23)。TCS23 是面向移動計算的完整 IP 組合,也是我們有史以來最佳的面向智能手機的高端解決方案。
ARM發布旗艦手機芯片:性能提升、AI性能增強、節能減耗
ARM為Cortex-X系列CPU重新命名,以強調其性能的顯著提升。據稱,X925的單核性能較X4提升了36%(依據Geekbench測試結





 工商網監
工商網監
評論