") Kafka 的簡介
Kafka 的簡介
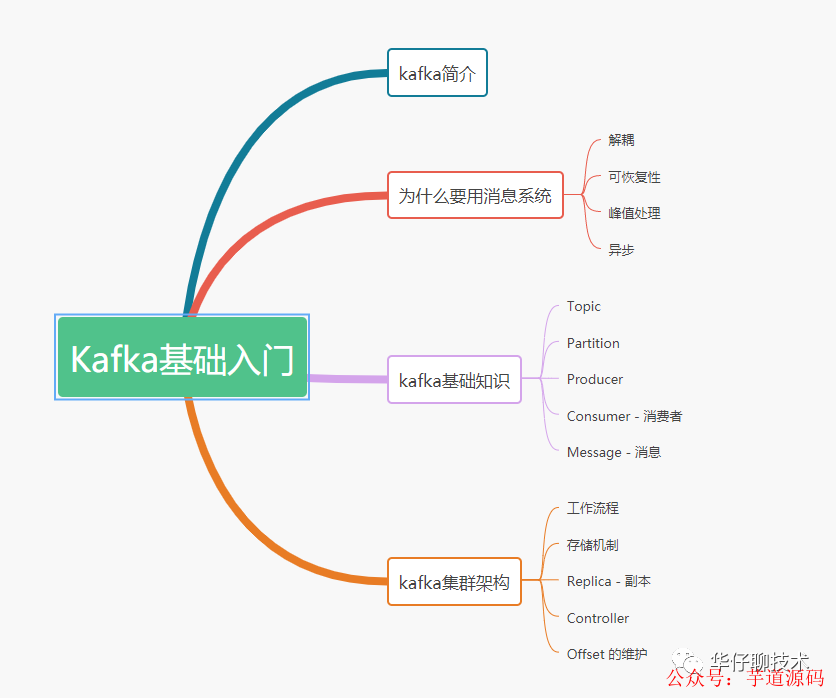
1 kafka簡介
2 為什么要用消息系統(tǒng)
3 kafka基礎(chǔ)知識
4 kafka集群架構(gòu)
5 總結(jié)
1 kafka簡介
其主要設(shè)計目標如下:
以時間復(fù)雜度為O(1)的方式提供消息持久化能力,即使對TB級以上數(shù)據(jù)也能保證常數(shù)時間的訪問性能
高吞吐率。即使在非常廉價的機器上也能做到單機支持每秒100K條消息的傳輸
支持Kafka Server間的消息分區(qū),及分布式消費,同時保證每個partition內(nèi)的消息順序傳輸,同時支持離線數(shù)據(jù)處理和實時數(shù)據(jù)處理
基于 Spring Boot + MyBatis Plus + Vue & Element 實現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
2 為什么要用消息系統(tǒng)
Kafka 本質(zhì)上是一個 MQ(Message Queue),使用消息隊列的好處?
解耦:允許我們獨立修改隊列兩邊的處理過程而互不影響。
冗余:有些情況下,我們在處理數(shù)據(jù)的過程會失敗造成數(shù)據(jù)丟失。消息隊列把數(shù)據(jù)進行持久化直到它們已經(jīng)被完全處理,通過這一方式規(guī)避了數(shù)據(jù)丟失風(fēng)險, 確保你的數(shù)據(jù)被安全的保存直到你使用完畢
峰值處理能力:不會因為突發(fā)的流量請求導(dǎo)致系統(tǒng)崩潰,消息隊列能夠使服務(wù)頂住突發(fā)的訪問壓力, 有助于解決生產(chǎn)消息和消費消息的處理速度不一致的情況
異步通信:消息隊列允許用戶把消息放入隊列但不立即處理它, 等待后續(xù)進行消費處理。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
3 kafka基礎(chǔ)知識
下面給出 Kafka 一些重要概念,讓大家對 Kafka 有個整體的認識和感知
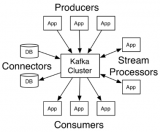
Producer:即消息生產(chǎn)者,向 Kafka Broker 發(fā)消息的客戶端。
Consumer:即消息消費者,從 Kafka Broker 讀消息的客戶端。
Consumer Group:即消費者組,消費者組內(nèi)每個消費者負責消費不同分區(qū)的數(shù)據(jù),以提高消費能力。一個分區(qū)只能由組內(nèi)一個消費者消費,不同消費者組之間互不影響。
Broker:一臺 Kafka 機器就是一個 Broker。一個集群是由多個 Broker 組成的且一個 Broker 可以容納多個 Topic。
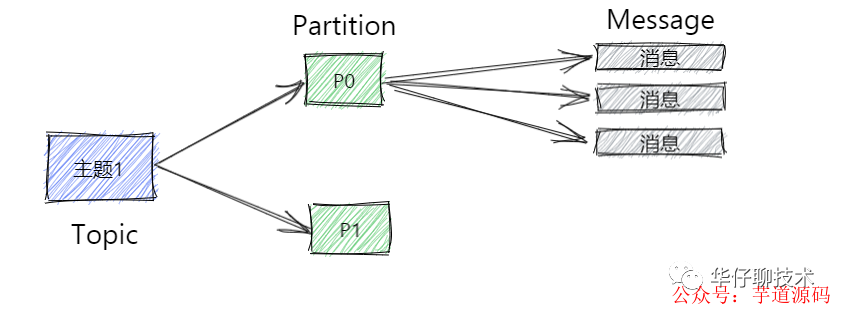
Topic:可以簡單理解為隊列,Topic 將消息分類,生產(chǎn)者和消費者面向的都是同一個 Topic。
Partition:為了實現(xiàn)Topic擴展性,提高并發(fā)能力,一個非常大的 Topic 可以分布到多個 Broker 上,一個 Topic 可以分為多個 Partition 進行存儲,每個 Partition 是一個有序的隊列。
Replica:即副本,為實現(xiàn)數(shù)據(jù)備份的功能,保證集群中的某個節(jié)點發(fā)生故障時,該節(jié)點上的 Partition 數(shù)據(jù)不丟失,且 Kafka 仍然能夠繼續(xù)工作,為此Kafka提供了副本機制,一個 Topic 的每個 Partition 都有若干個副本,一個 Leader 副本和若干個 Follower 副本。
Leader:即每個分區(qū)多個副本的主副本,生產(chǎn)者發(fā)送數(shù)據(jù)的對象,以及消費者消費數(shù)據(jù)的對象,都是 Leader。
Follower:即每個分區(qū)多個副本的從副本,會實時從 Leader 副本中同步數(shù)據(jù),并保持和 Leader 數(shù)據(jù)的同步。Leader 發(fā)生故障時,某個 Follower 還會被選舉并成為新的 Leader , 且不能跟 Leader 在同一個broker上, 防止崩潰數(shù)據(jù)可恢復(fù)。
Offset:消費者消費的位置信息,監(jiān)控數(shù)據(jù)消費到什么位置,當消費者掛掉再重新恢復(fù)的時候,可以從消費位置繼續(xù)消費。
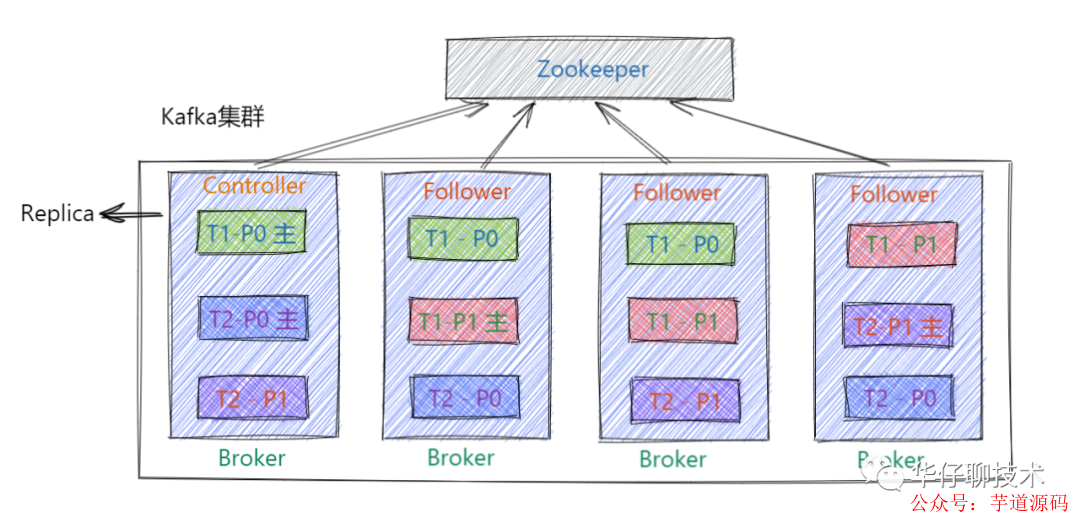
ZooKeeper服務(wù):Kafka 集群能夠正常工作,需要依賴于 ZooKeeper,ZooKeeper 幫助 Kafka 存儲和管理集群元數(shù)據(jù)信息。在最新版本中, 已經(jīng)慢慢要脫離 ZooKeeper。
4 kafka集群架構(gòu)
工作流程
在了解kafka集群之前, 我們先來了解下kafka的工作流程, Kafka集群會將消息流存儲在 Topic 的中,每條記錄會由一個Key、一個Value和一個時間戳組成。
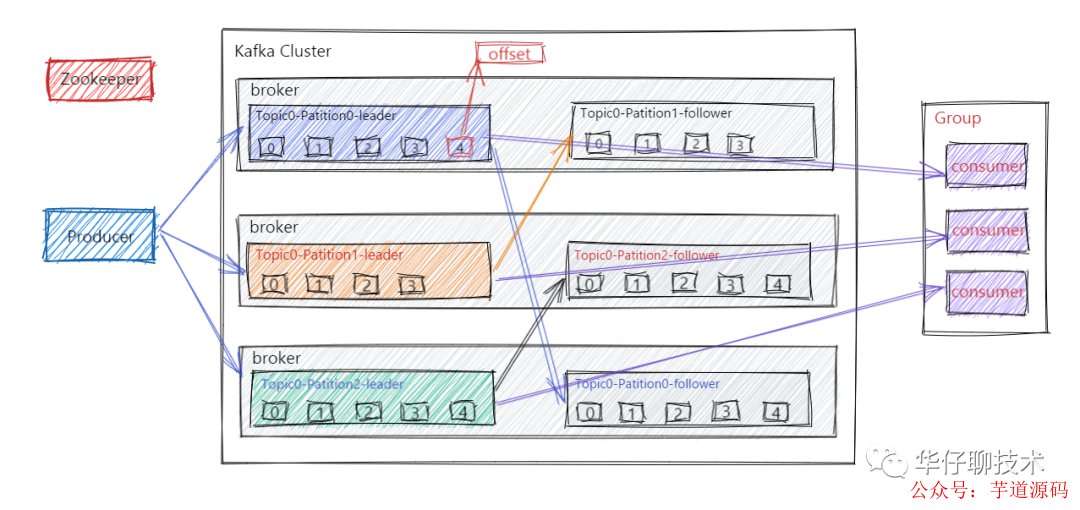
Kafka 中消息是以 Topic 進行分類的,生產(chǎn)者生產(chǎn)消息,消費者消費消息,讀取和消費的都是同一個 Topic。但是Topic 是邏輯上的概念, Partition 是物理上的概念,每個 Partition 對應(yīng)一個 log 文件,該 log 文件中存儲的就是 Producer 生產(chǎn)的數(shù)據(jù)。Producer 端生產(chǎn)的數(shù)據(jù)會不斷順序追加到該 log 文件末尾,并且每條數(shù)據(jù)都會記錄有自己的 Offset 。而消費者組中的每個消費者,也都會實時記錄當前自己消費到了哪個 Offset,方便在崩潰恢復(fù)時,可以繼續(xù)從上次的 Offset 位置消費。
存儲機制
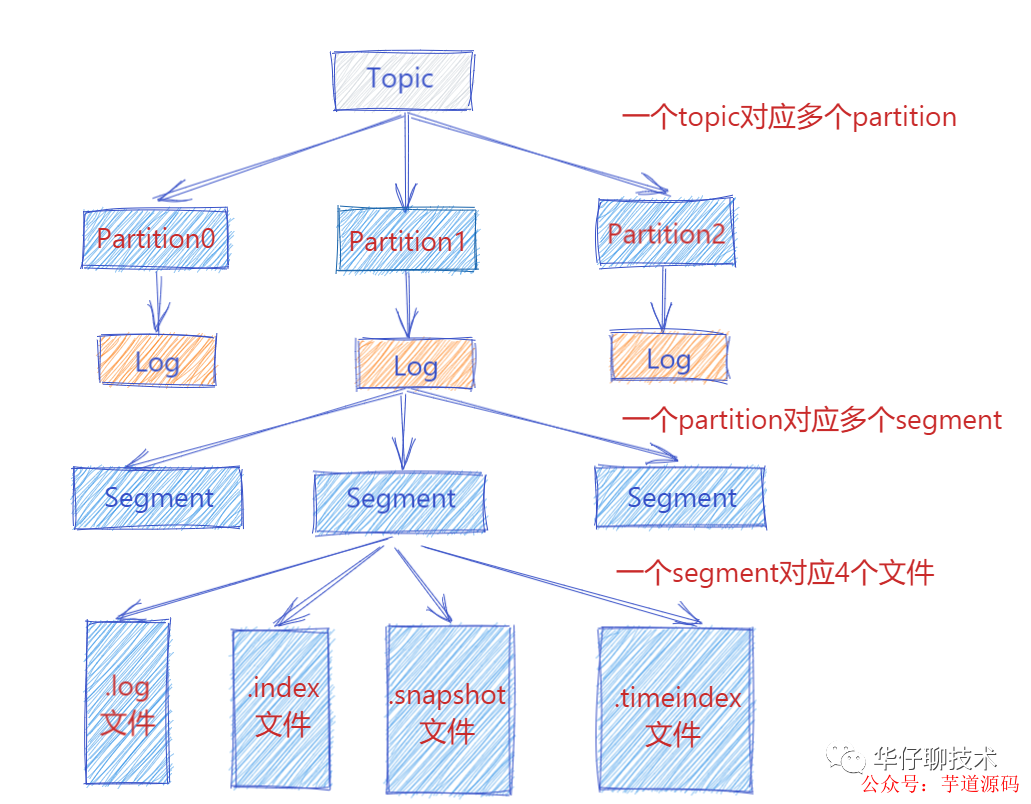
此時 Producer 端生產(chǎn)的消息會不斷追加到 log 文件末尾,這樣文件就會越來越大, 為了防止 log 文件過大導(dǎo)致數(shù)據(jù)定位效率低下,那么Kafka 采取了分片和索引機制。它將每個 Partition 分為多個 Segment,每個 Segment 對應(yīng)4個文件:“.index” 索引文件, “.log” 數(shù)據(jù)文件, “.snapshot” 快照文件, “.timeindex” 時間索引文件。這些文件都位于同一文件夾下面,該文件夾的命名規(guī)則為:topic 名稱-分區(qū)號。例如, heartbeat心跳上報服務(wù) 這個 topic 有三個分區(qū),則其對應(yīng)的文件夾為 heartbeat-0,heartbeat-1,heartbeat-2這樣。
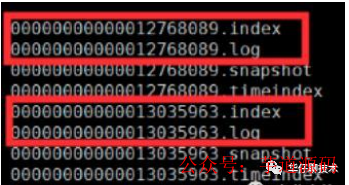
index, log, snapshot, timeindex 文件以當前 Segment 的第一條消息的 Offset 命名。其中 “.index” 文件存儲大量的索引信息,“.log” 文件存儲大量的數(shù)據(jù),索引文件中的元數(shù)據(jù)指向?qū)?yīng)數(shù)據(jù)文件中 Message 的物理偏移量。
下圖為index 文件和 log 文件的結(jié)構(gòu)示意圖:

Replica - 副本
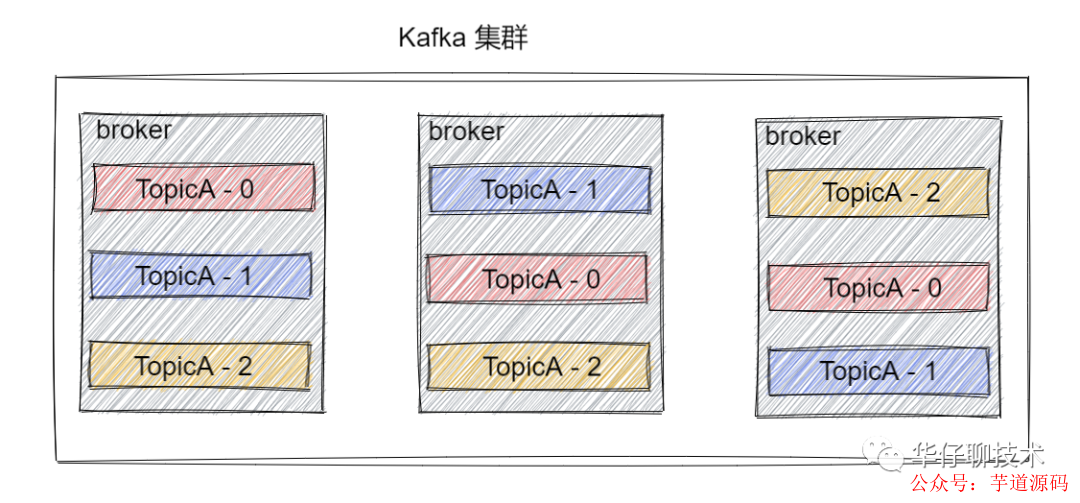
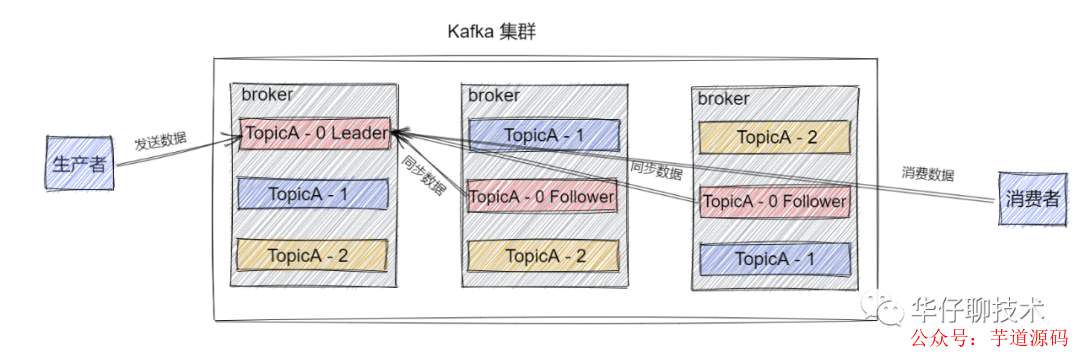
kafka中的 Partition 為了保證數(shù)據(jù)安全,每個 Partition 可以設(shè)置多個副本。此時我們對分區(qū)0,1,2分別設(shè)置3個副本(注:設(shè)置兩個副本是比較合適的)。而且每個副本都是有"角色"之分的,它們會選取一個副本作為 Leader 副本,而其他的作為 Follower 副本,我們的 Producer 端在發(fā)送數(shù)據(jù)的時候,只能發(fā)送到Leader Partition里面 ,然后Follower Partition會去Leader那自行同步數(shù)據(jù), Consumer 消費數(shù)據(jù)的時候,也只能從 Leader 副本那去消費數(shù)據(jù)的。
Controller
Kafka Controller,其實就是一個 Kafka 集群中一臺 Broker,它除了具有普通Broker 的消息發(fā)送、消費、同步功能之外,還需承擔一些額外的工作。Kafka 使用公平競選的方式來確定 Controller ,最先在 ZooKeeper 成功創(chuàng)建臨時節(jié)點 /controller 的Broker會成為 Controller ,一般而言,Kafka集群中第一臺啟動的 Broker 會成為Controller,并將自身 Broker 編號等信息寫入ZooKeeper臨時節(jié)點/controller。
Offset 的維護
Consumer 在消費過程中可能會出現(xiàn)斷電宕機等故障,在 Consumer 恢復(fù)后,需要從故障前的 Offset 位置繼續(xù)消費。所以 Consumer 需要實時記錄自己消費到了哪個 Offset,以便故障恢復(fù)后繼續(xù)消費。在 Kafka 0.9 版本之前,Consumer 默認將 Offset 保存在 ZooKeeper 中,但是從 0.9 版本開始,Consumer 默認將 Offset 保存在 Kafka 一個內(nèi)置的 Topic 中,該 Topic 為 __consumer_offsets, 以支持高并發(fā)的讀寫。
5 總結(jié)
上面和大家一起深入探討了 Kafka 的簡介, 基礎(chǔ)知識和集群架構(gòu),后續(xù)會從Kafka 三高(高性能, 高可用, 高并發(fā))方面來詳細闡述其巧妙的設(shè)計思想。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7026瀏覽量
89025 -
管理系統(tǒng)
+關(guān)注
關(guān)注
1文章
2498瀏覽量
35919 -
kafka
+關(guān)注
關(guān)注
0文章
51瀏覽量
5221
原文標題:Kafka基礎(chǔ)入門篇
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
kafka設(shè)計原理的深度探討

[6.3.1]--6.3數(shù)據(jù)分發(fā)中間件Kafka簡介-視頻

Kafka集群環(huán)境的搭建
Kafka的概念及Kafka的宕機
物通博聯(lián)5G-kafka工業(yè)網(wǎng)關(guān)實現(xiàn)kafka協(xié)議對接到云平臺
Kafka架構(gòu)技術(shù):Kafka的架構(gòu)和客戶端API設(shè)計
kafka基本原理詳解
超詳細“零”基礎(chǔ)kafka入門篇





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論