 聯合學習使得跨企業管理復雜的人工智能工作流更加容易
聯合學習使得跨企業管理復雜的人工智能工作流更加容易
在工作流程中利用人工智能的企業面臨的主要挑戰之一是管理支持大規模培訓和部署機器學習( ML )模型所需的基礎設施。為此,NVIDIA FLARE平臺提供了一個解決方案:聯合學習,使得跨企業管理復雜的人工智能工作流變得更加容易。
NVIDIA FLARE 2.3.0 是 NVIDIA 聯合學習平臺的最新版本,其中包含了令人興奮的新功能和增強功能,如:
使用基礎設施作為代碼的多云支持( IaC )
自然語言處理( NLP )示例,包括 BERT 和 GPT-2
用于分離數據和標簽的拆分學習
這篇文章詳細介紹了這些功能,并探討了它們如何幫助您的組織提升人工智能工作流程,并通過機器學習獲得更好的結果。
多云部署
有了這個版本,您現在可以使用 IaC 無縫管理您的多云基礎設施,利用不同云提供商的優勢,并分配您的工作負載以提高效率和可靠性。 IaC 使您能夠自動化基礎設施的管理和部署,從而節省時間并降低人為錯誤的風險。 NVIDIA FLARE 2.3.0 支持在 Microsoft Azure 和 AWS 云上進行自動部署。
要在云中部署 NVIDIA FLARE,請使用 NVIDIA FLARE CLI 命令創建基礎結構、部署和啟動 Dashboard UI、FL Server 和 FL Client。要在云中創建和部署 NVIDIA FLARE,請按照NVIDIA FLARE 啟動套件,由 NVIDIA FLARE 資源調配過程生成并分發給服務器和客戶端的簽名軟件包。
/start.sh --cloud azure | aws /start.sh --cloud azure | aws nvflare dashboard --cloud azure | aws
這些命令將創建資源組、網絡、安全、計算運行時實例等(作為代碼的基礎結構),并將 NVIDIA FLARE 客戶端或服務器部署到新創建的虛擬機( VM )。每個啟動工具包都包含可獨立部署的 FLARE 服務器或客戶端的唯一配置。這讓用戶可以靈活地在 prem 或混合云服務提供商(例如 AWS 上的服務器以及 Azure 和/或 AWS 上的客戶端)上進行部署,以實現簡單的混合多云配置。
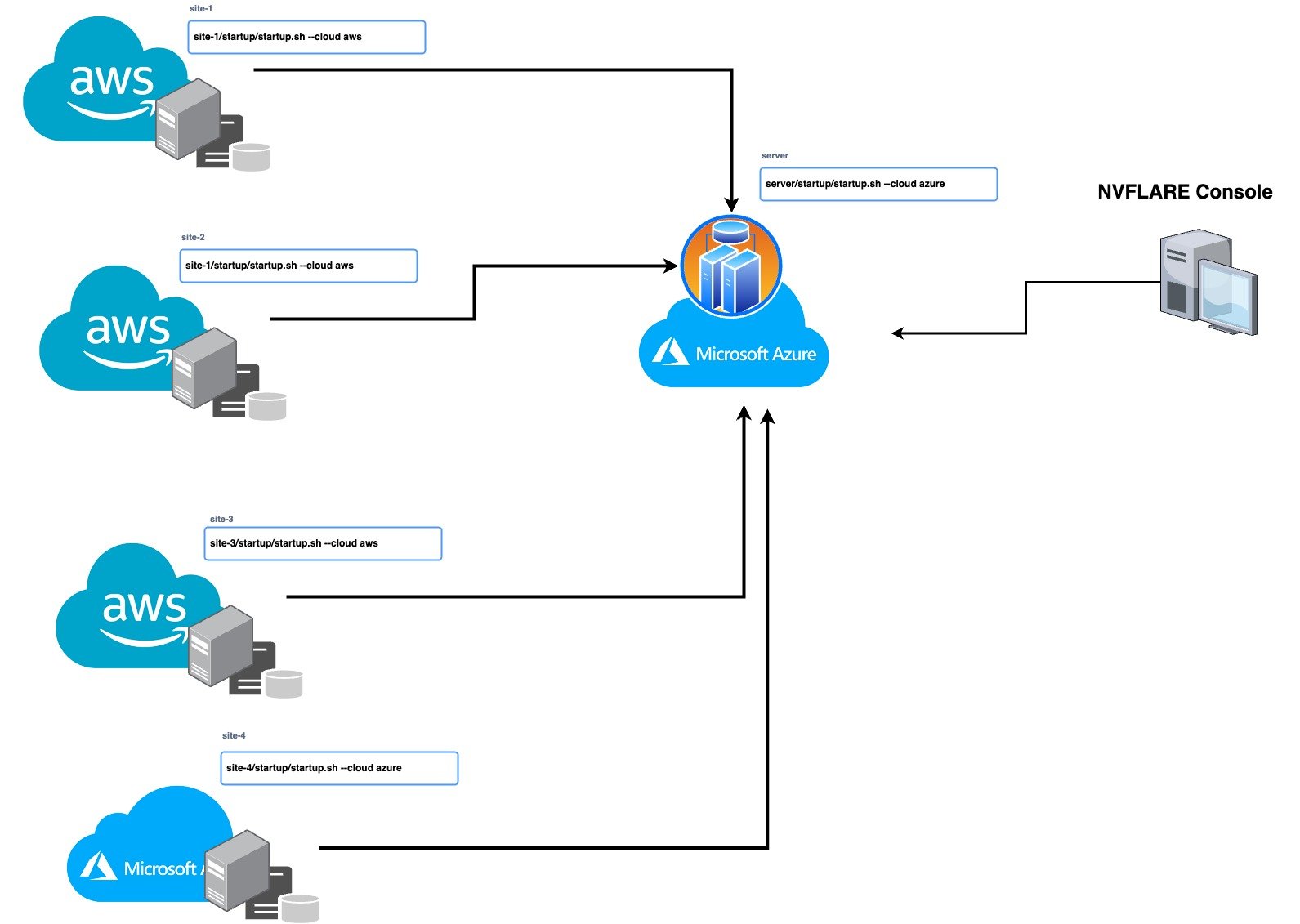 圖 1 。用于設置多云部署的 NVIDIA FLARE 單行 CLI 命令
圖 1 。用于設置多云部署的 NVIDIA FLARE 單行 CLI 命令
LLM 和聯合學習
Large language models(LLM)正在開啟多個行業的新可能性,比如醫療保健中的藥物發現。要了解更多詳情,請參見NVIDIA BioNeMo Service 建立生成式 AI 管道以進行藥物發現。
在 LLM 培訓中利用聯合學習有許多好處,包括:
保護數據隱私:模型可以在數據不離開前提的情況下進行訓練。即使在同一個組織中,數據位于世界不同地區的不同部門,這一點也可能很重要。例如,考慮到不同的國家隱私法,可能不可能將存儲在歐洲和中國的數據復制到一個集中的數據湖中。
避免數據移動:即使不關心隱私,將大量數據從一個位置復制到另一個位置也需要時間和金錢。
利用數據多樣性:當不同的站點具有不同類型的數據時,通過聯合學習訓練模型可以利用這種數據多樣性來改進全局模型。
實現任務多樣性:具有各種任務的培訓模式可以促進?模型性能。這也可以通過聯合學習來實現。
計算成本分布:培訓 LLM 需要大量資源,而且成本可能很高。要找到一個擁有足夠計算資源的機構來完成這項任務是很有挑戰性的。通過聯合學習,可以利用來自多個位置的計算資源來訓練所有參與者共享的模型。
訓練并行性:聯合學習通過橫向數據拆分和將模型的不同層拆分到不同位置,實現了模型訓練的數據和模型并行性。
為了說明這些功能,NVIDIA FLARE 2.3.0 引入了帶有 GPT-2(Generative Pretrained transformer 2)和 BERT(Bidirectional Encoder Representations from transformers)模型的 NLP 命名實體識別(NER)示例。要了解更多詳情,請訪問 GitHub 上的 NVIDIA/NVFlare。參數高效調優和相關工作正在進行中,為未來的版本提供更多 LLM 模型示例。
聯邦 NLP
NVIDIA FLARE 能夠支持具有不同主干模型的各種 NLP 任務,例如 NER 、文本分類和語言生成。
本次發布的重點是使用 NCBI 疾病數據集進行命名實體識別(NER)應用,該數據集包含生物醫學研究論文的摘要,并附有疾病提及,通常用于生物醫學領域的 NER 模型的基準測試。更多詳情,請參閱NCBI 疾病語料庫:疾病名稱識別和概念歸一化的資源。
NER 的任務包括識別文本中的命名實體,并將其分類到預定義的類別中。在 NCBI 疾病數據集的情況下,目標是識別和捕獲疾病提及。
為了解決 NER 任務, NVIDIA FLARE 示例探討了兩種流行型號 BERT 和 GPT-2 的使用。 BERT 是一種基于預訓練 transformer 的模型,廣泛用于各種 NLP 任務,包括 NER 。 GPT-2 是另一個基于 transformer 的模型,主要用于語言生成,但也可以針對 NER 進行微調。
BERT 基本無上限模型和 GPT-2 模型分別有 1 . 1 億個和 1 . 24 億個參數。模型中參數的數量是其大小和復雜性的指示。具有更多參數的較大模型往往會學習數據中更復雜的關系。然而,與較小的模型相比,它們也需要更多的計算資源和更長的訓練時間。
即將發布的版本將包括對更大的十億參數模型和其他任務的支持。
拆分學習
Split learning是一種技術,可以讓多方在各自的數據集上協作訓練機器學習模型,而無需相互共享原始數據。該模型分為兩個或多個部分,每個部分都可以在其中一個參與方上運行。
與傳統的 ML 方法相比,這種方法有幾個優點,尤其是在數據隱私是主要問題的情況下。與聯合學習一樣,分離學習從不在各方之間共享原始數據。這意味著敏感信息可以保密,同時使各方能夠獲得見解并從合作中受益。
NVIDIA FLARE 2.3.0 版本演示了一個分布式學習的示例,其中數據和標簽可以分別存放在兩個不同的站點上。通過將模型的一部分放在一個站點上,并向另一個站點發送激活/嵌入以計算損失,可以實現數據和模型的保護。您可以在 CIFAR10 分割學習示例 中查看這項技術。
開始使用 NVIDIA FLARE 2 . 3 . 0
NVIDIA FLARE 2.3.0 可以幫助您快速部署到多云環境中,探索 LLM 的 NLP 示例,并展示拆分學習功能。通過將這些功能融入工作流程,可以節省時間、提高準確性、降低風險,從而促進人工智能工作流程的實施。
-
NVIDIA
+關注
關注
14文章
4989瀏覽量
103093 -
人工智能
+關注
關注
1791文章
47294瀏覽量
238578
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論