") Nvidia的H100:有趣的L2緩存和大量帶寬
Nvidia的H100:有趣的L2緩存和大量帶寬
GPU 最初是純粹用于圖形渲染的設(shè)備,但其高度并行的特性也使其對某些計算任務(wù)具有吸引力。隨著過去幾十年 GPU 計算場景的發(fā)展,Nvidia 進(jìn)行了大量投資來占領(lǐng)計算市場。其中一部分涉及認(rèn)識到計算任務(wù)與圖形任務(wù)有不同的需求,并分散其 GPU 系列以更好地瞄準(zhǔn)每個市場。
H100 是 Nvidia 面向計算的 GPU 系列的最新成員。它采用Hopper架構(gòu),并建立在一個巨大的814 mm2芯片上,使用臺積電的4N工藝和800億個晶體管。這個巨大的芯片實(shí)現(xiàn)了 144 個流式多處理器 (SM)、60 MB 的 L2 緩存和 12 個 512 位 HBM 內(nèi)存控制器。我們正在 Lambda Cloud 上測試 H100 的 PCIe 版本,該版本支持 114 個 SM、50 MB 的 L2 緩存和 10 個 HBM2 內(nèi)存控制器。該卡最多可消耗 350 W 的功率。
Nvidia 還提供了 SXM 外形 H100,其功耗高達(dá) 700W,并啟用了 132 個 SM。SXM H100 還使用 HBM3 內(nèi)存,提供額外的帶寬來滿足這些額外的著色器的需要。
關(guān)于時鐘速度的簡要說明
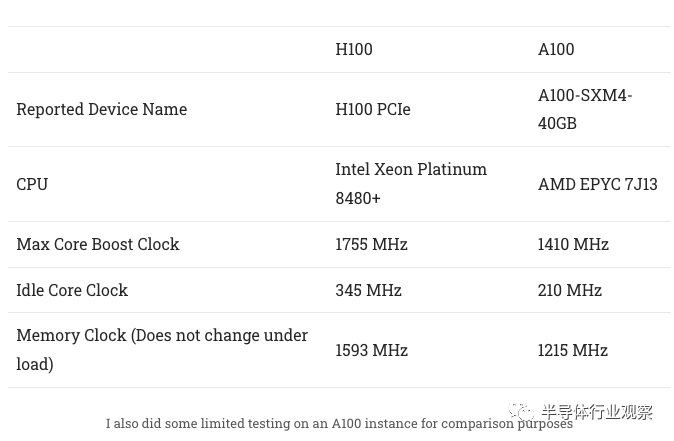
H100 具有比 A100 高得多的升壓時鐘。在進(jìn)行微基準(zhǔn)測試時,H100 有時會降至 1395 MHz,或者略低于其最大升壓時鐘的 80%。nvidia-smi 的其他指標(biāo)表明我們可能會達(dá)到功率限制,特別是在從 L2 提取數(shù)據(jù)時。H100 PCIe 版本的功率限制為 350W,在帶寬測試時正好符合這一要求。
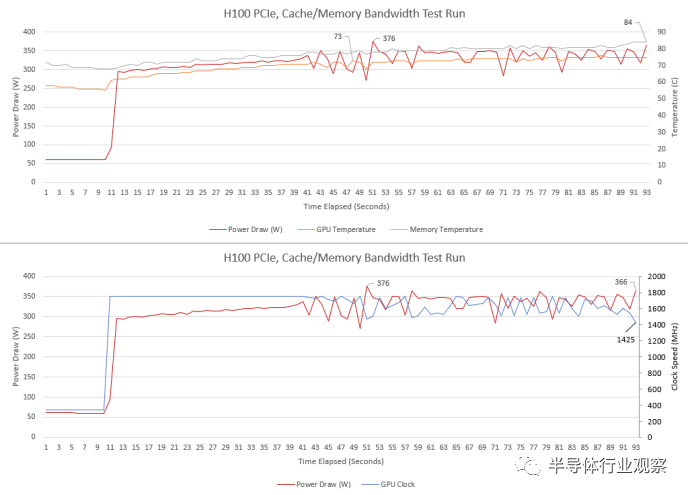
即使 GPU 功耗超過 300W,服務(wù)器冷卻也能夠使 H100 保持在非常低的溫度。內(nèi)存溫度稍高一些,但仍在合理范圍內(nèi)。
A100 看到了不同的行為。核心時鐘在負(fù)載下達(dá)到 1410 MHz 并保持不變。功耗也相當(dāng)高,但 A100 的 SXM4 版本具有更高的 400W 功率限制。可能正因?yàn)槿绱耍词构某^ 350W,我們也沒有看到任何時鐘速度下降。
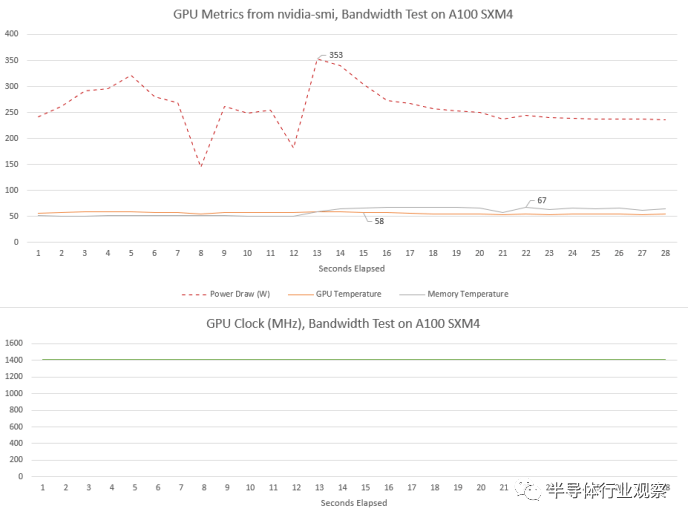
與 H100 一樣,A100 的核心溫度非常低。被動冷卻卡似乎在氣流充足的服務(wù)器機(jī)箱中蓬勃發(fā)展。A100的內(nèi)存溫度也比H100低。
緩存和內(nèi)存設(shè)置
計算機(jī)幾乎一直受到內(nèi)存速度的限制。我們已經(jīng)看到消費(fèi)類 GPU 通過日益復(fù)雜的緩存設(shè)置來應(yīng)對這一問題。AMD 的 RX 6900 XT 使用四級緩存層次結(jié)構(gòu),末級緩存容量為 128 MB,而 Nvidia 的 RTX 4090 將二級容量擴(kuò)展至 72 MB。Nvidia 的計算 GPU 的緩存容量也有所增加,但策略略有不同。
流式多處理器 (SM) 是 Nvidia 的基本 GPU 構(gòu)建塊。Nvidia 在之前面向數(shù)據(jù)中心的 GPU 中一直強(qiáng)調(diào) SM 私有緩存。對于大多數(shù) Nvidia 架構(gòu),SM 具有私有內(nèi)存塊,可以在 L1 緩存和共享內(nèi)存(軟件管理暫存器)使用之間靈活分區(qū)。GK210 Kepler SM 具有 128 KB 的內(nèi)存,而客戶端實(shí)現(xiàn)的內(nèi)存為 64 KB。A100 為 192 KB,而客戶端 Ampere 為 128 KB。現(xiàn)在,H100 將 L1/共享內(nèi)存容量提高到 256 KB。
我們可以使用 Nvidia 的專有 API 對 L1 緩存分配進(jìn)行有限的測試。我們通常使用 OpenCL 或 Vulkan 進(jìn)行測試,因?yàn)樵S多供應(yīng)商支持這些 API,讓測試無需修改即可在各種 GPU 上運(yùn)行。但 CUDA 對 L1 和共享內(nèi)存分割的控制有限。具體來說,我們可以要求 GPU 偏好 L1 緩存容量、偏好均等分割或偏好共享內(nèi)存容量。請求更大的 L1 緩存分配不會帶來任何延遲損失。
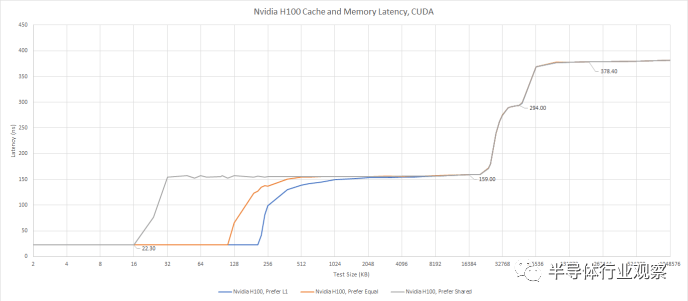
使用 CUDA 測試內(nèi)存訪問延遲,這讓我們可以指定首選的 L1/共享內(nèi)存分割。
當(dāng)我們要求 CUDA 優(yōu)先選擇 L1 緩存容量時,我們看到 208 KB 的 L1 緩存。通過這種設(shè)置,H100 比任何其他 GPU 擁有更多的一級數(shù)據(jù)緩存能力。即使我們考慮到 AMD 使用單獨(dú)內(nèi)存進(jìn)行緩存和暫存器的策略,H100 仍然領(lǐng)先。將 RDNA 3 的 L0 矢量緩存、標(biāo)量緩存和 LDS(暫存器)容量加起來僅提供 208 KB 的存儲空間,而 Hopper 上的存儲空間為 256 KB。
相對于A100,H100的L1容量更高,延遲更低。這是一個值得歡迎的改進(jìn),并且在緩存層次結(jié)構(gòu)中繼續(xù)保持比 A100 稍好的趨勢。
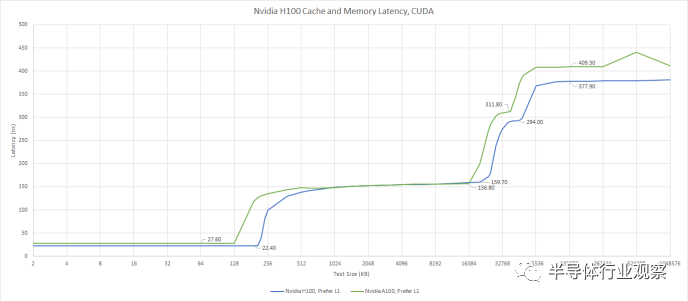
對于 L1 無法容納的數(shù)據(jù),H100 有 50 MB L2。當(dāng) A100 于 2020 年推出時,其 40 MB L2 為其提供了比當(dāng)時任何 Nvidia GPU 更高的末級緩存容量。H100稍微增加了緩存容量,但今天沒什么特別的。Nvidia 的 RTX 4090 具有 72 MB 的二級緩存,而 AMD 的高端 RDNA 2 和 RDNA 3 GPU 分別具有 128 MB 和 96 MB 的末級緩存。

Nvidia 白皮書中的 H100 框圖,顯示了兩個 L2 分區(qū)以及它們之間的鏈接
H100還繼承了A100的分離式L2配置。GPU 上運(yùn)行的任何線程都可以訪問全部 50 MB 緩存,但速度不同。訪問“遠(yuǎn)”分區(qū)所需的時間幾乎是原來的兩倍。它的延遲大約與 RX 6900 XT 上的 VRAM 一樣長,這使得它對帶寬更有用,而不是讓單個扭曲或波前更快完成。
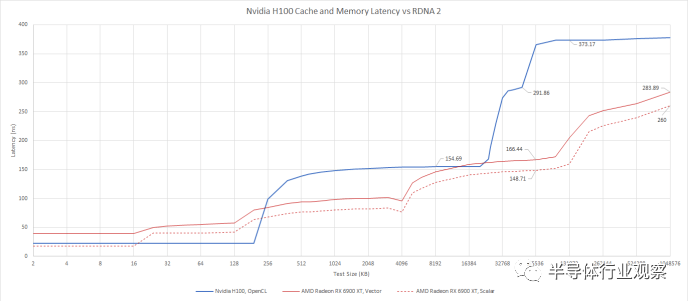
使用 OpenCL 與 AMD 的客戶端 RDNA 2 架構(gòu)進(jìn)行比較
H100 的二級緩存感覺像是兩級設(shè)置,而不是單級緩存。在 H100 上運(yùn)行的線程可以比在 A100 上更快地訪問“遠(yuǎn)”L2 緩存,因此 Nvidia 與上一代相比有所改進(jìn)。在實(shí)現(xiàn)大型緩存方面,A100 是 Nvidia 的先驅(qū),而 H100 的設(shè)置是 A100 的自然演變。但這并不是現(xiàn)代客戶端 GPU 上使用的低延遲、高效的緩存設(shè)置。
在 VRAM 中,H100 的延遲比 A100 略低,與一些較舊的客戶端 GPU 相當(dāng)。例如,GTX 980 Ti 的 VRAM 延遲約為 354 ns。
不再有常量緩存?
Nvidia 長期以來一直使用單獨(dú)的常量緩存層次結(jié)構(gòu),通常具有 2 KB 常量緩存,并由 32 至 64 KB 中級常量緩存支持。常量緩存提供非常低的延遲訪問,但它是只讀的并且由有限的內(nèi)存空間支持。H100 以不同的方式處理常量內(nèi)存。Nvidia 可以分配最多 64 KB 的恒定內(nèi)存(這一限制可以追溯到 Tesla 架構(gòu)),并且延遲在整個范圍內(nèi)是恒定的。
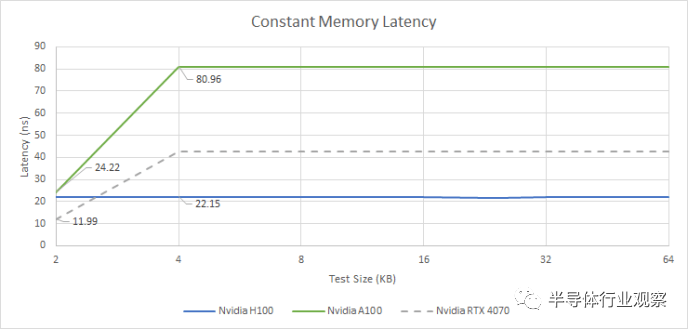
此外,延遲看起來與 L1 緩存延遲幾乎相同。H100 可能使用 L1 數(shù)據(jù)緩存來保存常量數(shù)據(jù)。驗(yàn)證這個假設(shè)需要額外的測試,由于現(xiàn)實(shí)生活和日常工作的需求,我目前無法投入時間。但無論 Nvidia 做了什么,它都比 A100 的持續(xù)緩存有了明顯的改進(jìn),并且全面降低了延遲。如果 Ada Lovelace 可以處理來自小型且快速的 2 KB 常量緩存的請求,那么它可以享受較低的延遲,但如果有大量常量數(shù)據(jù),它也會落后。
本地內(nèi)存延遲
如前所述,H100 的 SM 具有大塊私有存儲,可以在 L1 緩存和共享內(nèi)存使用之間分配。共享內(nèi)存是 Nvidia 的術(shù)語,指的是軟件管理的暫存器,可提供始終如一的高性能。AMD 的等效項(xiàng)稱為本地數(shù)據(jù)共享 (LDS)。在 Intel GPU 上,它稱為共享本地內(nèi)存 (SLM)。OpenCL 將此內(nèi)存類型稱為本地內(nèi)存。
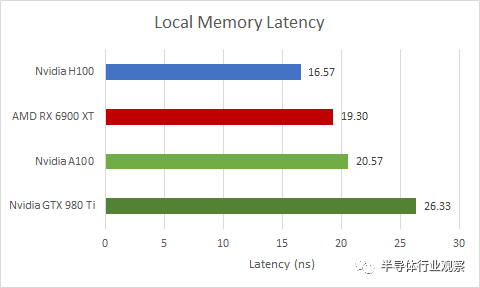
盡管 H100 從同一存儲塊中分配共享內(nèi)存,但共享內(nèi)存比 L1 緩存訪問更快,因?yàn)樗恍枰獦?biāo)記比較和狀態(tài)檢查來確保命中。與各種 GPU 相比,H100 表現(xiàn)出色,盡管它可以比任何其他當(dāng)前 GPU 分配更多的共享內(nèi)存容量。
Atomics
共享內(nèi)存(或本地內(nèi)存)對于同步同一工作組內(nèi)的線程也很有用。在這里,我們正在測試 OpenCL 的atomic_cmpxchg 函數(shù),該函數(shù)會進(jìn)行比較和交換操作,并保證在這些操作之間沒有其他東西會觸及其所使用的內(nèi)存。
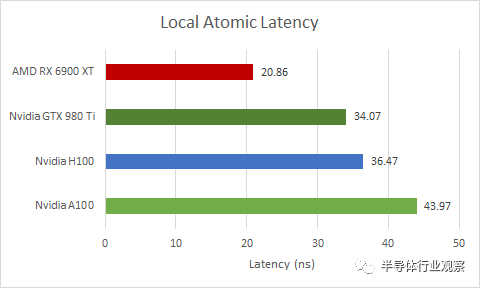
H100 在這種原子(Atomics)操作方面做得相當(dāng)好,盡管它有點(diǎn)落后于消費(fèi)級 GPU 的能力。令人驚訝的是,這也適用于以較低時鐘運(yùn)行的舊 GPU,例如 GTX 980 Ti。不過,H100 確實(shí)比 A100 做得更好。
如果我們在全局內(nèi)存(即由 VRAM 支持的內(nèi)存)上執(zhí)行相同的操作,延遲會嚴(yán)重得多。它略高于 L2 延遲,因此 H100 可能正在 L2 緩存處處理跨 SM 同步。
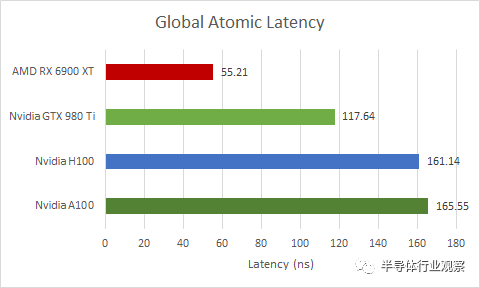
同樣,H100 比 A100 略有改進(jìn),但與消費(fèi)級 GPU 相比有所不足。但這一次,差距要大得多。RX 6900 XT 將 H100 和 A100 遠(yuǎn)遠(yuǎn)拋在了后面。舊版 GTX 980 Ti 的性能也好很多。我認(rèn)為在巨大的 814 mm2或 826 mm2芯片上同步事物是相當(dāng)具有挑戰(zhàn)性的。
分布式共享內(nèi)存
為了降低跨巨大芯片傳輸數(shù)據(jù)的成本,H100 具有一項(xiàng)稱為分布式共享內(nèi)存 (DSMEM) 的功能。使用此功能,應(yīng)用程序可以將數(shù)據(jù)保存在 GPC 或 SM 集群中。與上述全局原子相比,這應(yīng)該允許更低的延遲數(shù)據(jù)共享,同時能夠在比工作組中容納的更多線程之間共享數(shù)據(jù)。
測試此功能需要每小時支付 2 美元購買 H100 實(shí)例,同時學(xué)習(xí)新的 API,然后在沒有其他 GPU 的情況下進(jìn)行測試,以對結(jié)果進(jìn)行健全性檢查。即使在有利的條件下,編寫、調(diào)試和驗(yàn)證測試通常也需要許多小時。Nvidia 聲稱 DSMEM通常比通過全局內(nèi)存交換數(shù)據(jù)快 7 倍。
帶寬
延遲只是問題的一部分。H100 等 GPU 專為極其并行的計算工作負(fù)載而設(shè)計,并且可能不必處理可用并行性較低的情況。這與消費(fèi)類 GPU 形成鮮明對比,消費(fèi)類 GPU 偶爾會面臨較少的并行任務(wù),例如幾何處理或小型繪制調(diào)用。所以,H100強(qiáng)調(diào)的是海量帶寬。從 L2 緩存開始,我們看到超過 5.5 TB/s 的讀取帶寬。我們測量了 RX 7900 XTX L2 的讀取帶寬約為 5.7 TB/s,因此 H100 獲得了幾乎相同的帶寬量和更高的緩存容量。
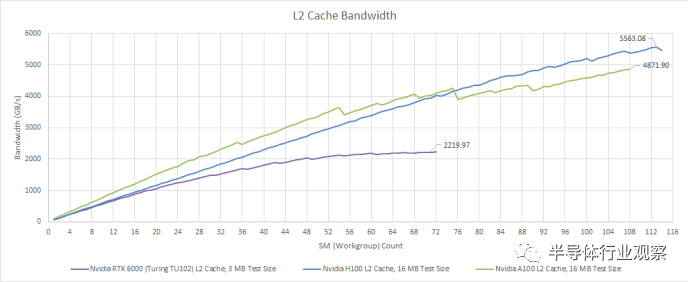
使用 OpenCL 進(jìn)行測試
與 A100 相比,H100 的帶寬提升雖小但很明顯。但這僅適用于“近”L2 分區(qū)。如前所述,A100 和 H100 的 L2 并不是真正的單級緩存。如果我們超過“接近”L2 容量,帶寬會明顯變差。在訪問整個 50 MB L2 時,H100 與 A100 相比也有所退步,為 3.8 TB/s,而 A100 為 4.5 TB/s。Nvidia 可能已經(jīng)確定很少有工作負(fù)載在 A100 上受 L2 帶寬限制,因此放棄一點(diǎn)跨分區(qū) L2 帶寬并不是什么大問題。
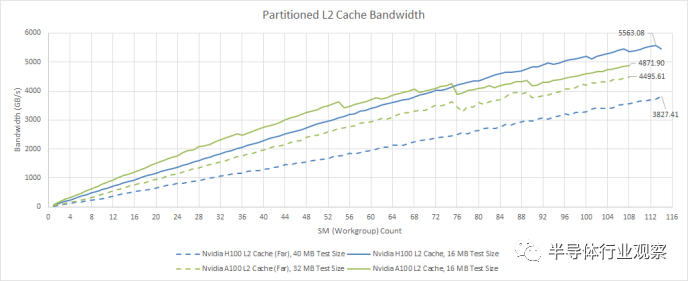
從絕對意義上講,即使請求必須穿過緩存分區(qū),H100 的 50 MB L2 仍然可以提供大量帶寬。相比之下,RDNA 2 的無限緩存可提供約 2 TB/s 的帶寬,而 RDNA 3 的無限緩存僅略低于 3 TB/s。因此,H100 提供的緩存容量比 AMD 高端客戶端 GPU 上的無限緩存要少一些,但通過更高的帶寬來彌補(bǔ)。
然而,我覺得 Nvidia 可以將一些客戶端工程引入到面向計算的 GPU 中。他們的 RTX 4090 提供約 5 TB/s 的 L2 帶寬,并具有更多的 L2 緩存容量。從好的方面來說,H100 的 L2 提供比 VRAM 高得多的帶寬,即使請求必須跨分區(qū)也是如此。這是一種恭維,因?yàn)?H100 擁有大量的 VRAM 帶寬。
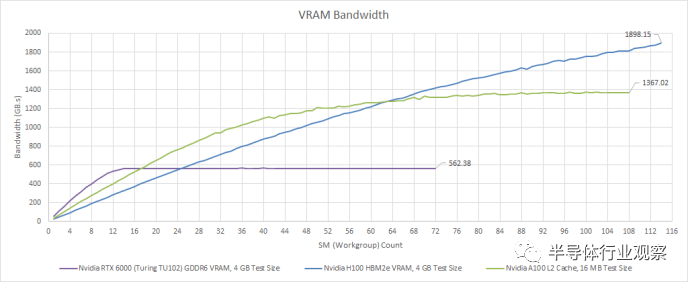
憑借五個 HBM2e 堆棧,H100 可以從 VRAM 中提取略低于 2 TB/s 的速度。因此,H100 的 VRAM 帶寬實(shí)際上非常接近 RDNA 2 的 Infinity Cache 帶寬。它還代表了相對于 A100 的顯著改進(jìn)。A100 使用 HBM2,并且仍然比任何消費(fèi)類 GPU 擁有更多的 VRAM 帶寬,但其較低的內(nèi)存時鐘讓 H100 領(lǐng)先。
H100 的 VRAM 帶寬對于沒有緩存友好訪問模式的大量工作集非常有用。消費(fèi)級 GPU 已趨向于良好的緩存,而不是大量的 VRAM 設(shè)置。與具有適度 GDDR 設(shè)置但具有出色緩存的 GPU 相比,少數(shù)使用 HBM 的消費(fèi)級 GPU 的性能表現(xiàn)平平。這是因?yàn)榫彺嫜舆t較低,即使工作負(fù)載較小,也可以更輕松地保持執(zhí)行單元的運(yùn)行。從 Nvidia 和 AMD 構(gòu)建計算 GPU 的方式來看,計算工作負(fù)載似乎恰恰相反。A100 已經(jīng)針對大型工作負(fù)載進(jìn)行了調(diào)整。H100 更進(jìn)一步,如果您可以填充一半以上的 GPU,則 H100 領(lǐng)先于 A100,但如果您不能填充一半以上,則 H100 會落后一些。
計算吞吐量
A100 的 SM 提供比客戶端 Ampere 更高的理論占用率和 FP64 性能,但只有 FP32 吞吐量的一半。H100 通過為每個 SM 子分區(qū) (SMSP) 提供 32 個 FP32 單元來解決這個問題,讓它每個時鐘執(zhí)行一個扭曲指令。
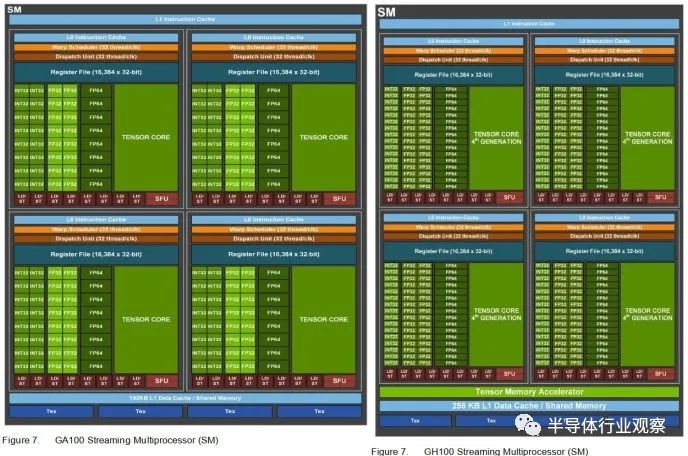
數(shù)據(jù)來自A100和H100各自的白皮書
除了 FP32 性能之外,F(xiàn)P64 性能也翻倍。每個 H100 SMSP 可以每兩個周期執(zhí)行一條 FP64 warp 指令,而 A100 每四個周期執(zhí)行一次。這使得 H100 在需要提高精度的科學(xué)應(yīng)用中比 A100 表現(xiàn)更好。
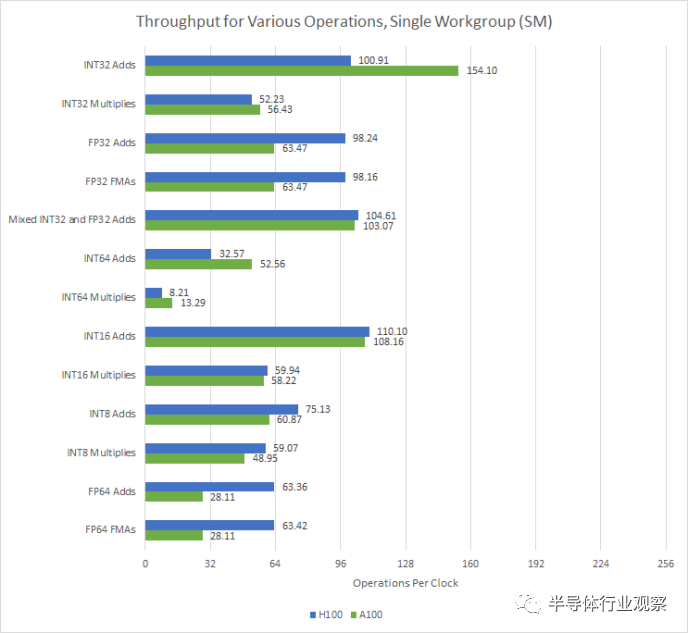
A100 上的 INT32 加法吞吐量絕對是一個測量誤差。遺憾的是,Nvidia 不支持 OpenCL 的 FP16 擴(kuò)展,因此無法測試 FP16 吞吐量
同時,H100繼承了Nvidia在整數(shù)乘法方面的優(yōu)勢。具體來說,與 AMD GPU 上的四分之一速率相比,INT32 乘法以一半速率執(zhí)行。另一方面,AMD GPU 可以以雙倍速率執(zhí)行 16 位整數(shù)運(yùn)算,而 Nvidia GPU 則不能。
在GPU層面,H100的特點(diǎn)是SM數(shù)量小幅增加,時鐘速度大幅提高。其結(jié)果是計算吞吐量全面顯著增加。由于 SM 級別的變化,H100 的 FP32 和 FP64 吞吐量將 A100 擊敗。
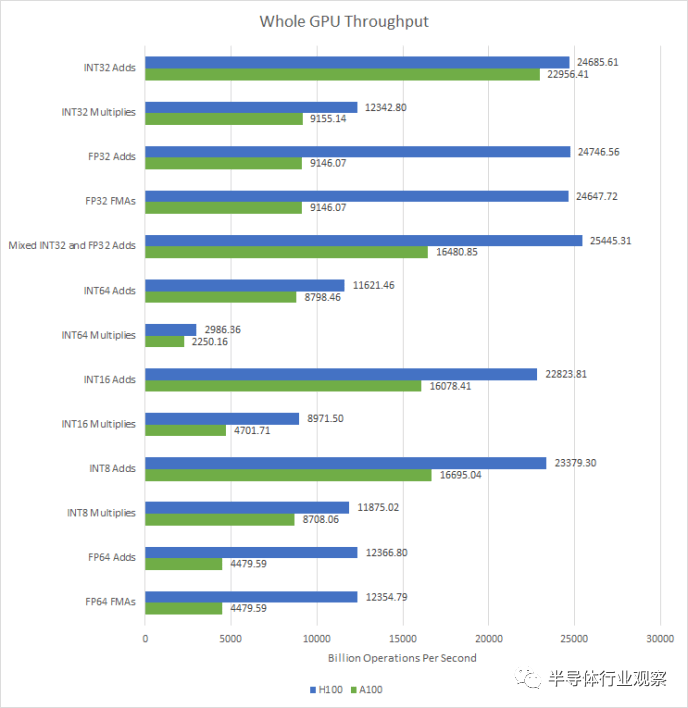
H100 的改進(jìn)將為各種應(yīng)用程序帶來性能優(yōu)勢,因?yàn)楹茈y想象有任何 GPGPU 程序不使用 FP32 或 FP64。將這些操作的吞吐量加倍以及 SM 數(shù)量和時鐘速度的增加將使工作負(fù)載更快地完成。
除了矢量計算性能之外,H100 還使張量核心吞吐量翻倍。張量核心專門通過打破 SIMT 模型來進(jìn)行矩陣乘法,并在 warp 的寄存器中存儲矩陣。我沒有為張量核心編寫測試,并且在不久的將來編寫一個測試超出了我空閑時間愛好項(xiàng)目的時間范圍。但是,我相信 Nvidia 關(guān)于這個主題的白皮書。
最后的話
近年來,消費(fèi)類 GPU 已朝著在面對較小工作負(fù)載時保持良好性能的方向發(fā)展。當(dāng)然,它們?nèi)匀缓軐挘?AMD 和 Nvidia 在吞吐量和延遲之間取得了平衡。RDNA 2/3 和 Ada Lovelace 的運(yùn)行頻率均超過 2 GHz,這意味著它們的時鐘速度接近服務(wù)器 CPU 的時鐘速度。除了高時鐘速度之外,復(fù)雜的緩存層次結(jié)構(gòu)還提供延遲優(yōu)勢和高帶寬,前提是訪問模式對緩存友好。與此同時,昂貴的內(nèi)存解決方案已經(jīng)失寵。少數(shù)配備 HBM 的客戶端 GPU 從未在配備 GDDR 的競爭對手中表現(xiàn)出色,盡管擁有更多的內(nèi)存帶寬和更多的計算吞吐量來支持這一點(diǎn)。
但這顯然不適用于計算 GPU,因?yàn)樗鼈円呀?jīng)朝著相反的方向發(fā)展。H100 是一款以相對較低的時鐘運(yùn)行的超寬 GPU,它強(qiáng)調(diào)每瓦性能而不是絕對性能。1755 MHz 是 Pascal 的典型頻率,該架構(gòu)是七年前推出的。與最新的客戶端 GPU 相比,緩存容量和延遲表現(xiàn)一般。與此同時,英偉達(dá)并沒有犧牲帶寬。在帶寬方面,H100 的 L2 并不落后于客戶端 GPU。L2 之后,由于巨大的 HBM 配置,VRAM 帶寬變得巨大。H100 與 A100 和 AMD 的 CDNA GPU 一樣,旨在運(yùn)行大型、長時間運(yùn)行的作業(yè)。基于對 VRAM 帶寬而非緩存容量的重視,這些作業(yè)可能屬于這樣的類別:如果您無法使用幾十兆字節(jié)的緩存捕獲訪問模式,
H100 在 SM 級別上也有別于客戶端設(shè)計。用于 L1 或共享內(nèi)存的更多內(nèi)存意味著精心設(shè)計的程序可以將大量數(shù)據(jù)保留在非常靠近執(zhí)行單元的位置。在 H100 的 144 個物理 SM 中,有 36.8 MB 的 L1 和共享內(nèi)存容量,這使得芯片面積投資顯著。Nvidia 還使用 SM 區(qū)域來跟蹤飛行中的更多扭曲,以應(yīng)對更高的 L1 未命中延遲。H100 可以跟蹤每個 SM 64 個扭曲,而客戶端 Ampere 和 Ada Lovelace 則為 48 個。額外的 SM 區(qū)域用于使 FP32、FP64 和張量吞吐量加倍。
客戶端 GPU 繼續(xù)提供合理的計算能力,如果您足夠討厭自己,數(shù)據(jù)中心 GPU可能會被迫渲染圖形。但在可預(yù)見的未來,面向計算和圖形的架構(gòu)可能會繼續(xù)分化。Ada Lovelace 和 H100 有很多差異,即使它們基于相似的基礎(chǔ)。在 AMD 方面,RDNA 和 CDNA 也繼續(xù)存在分歧,盡管兩者的 ISA 根源都可以追溯到古老的 GCN 架構(gòu)。這種分歧是很自然的,因?yàn)楣に嚬?jié)點(diǎn)進(jìn)展減慢,每個人都試圖專業(yè)化以充分利用每個晶體管。
審核編輯:湯梓紅
-
控制器
+關(guān)注
關(guān)注
112文章
16416瀏覽量
178761 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5049瀏覽量
103357 -
gpu
+關(guān)注
關(guān)注
28文章
4760瀏覽量
129131 -
帶寬
+關(guān)注
關(guān)注
3文章
941瀏覽量
40991 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3040瀏覽量
74175
原文標(biāo)題:Nvidia 的 H100:有趣的 L2 和大量帶寬
文章出處:【微信號:IC大家談,微信公眾號:IC大家談】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
英偉達(dá)a100和h100哪個強(qiáng)?英偉達(dá)A100和H100的區(qū)別
請教關(guān)于c6424 L2緩存設(shè)置問題
NVIDIA發(fā)布新一代產(chǎn)品—NVIDIA H100

GTC2022大會黃仁勛:NVIDIA H100的5項(xiàng)突破性創(chuàng)新

GTC2022大會亮點(diǎn):NVIDIA發(fā)布全新AI計算系統(tǒng)—DGX H100

NVIDIA發(fā)布最新Hopper架構(gòu)的H100系列GPU和Grace CPU超級芯片
藍(lán)海大腦服務(wù)器全力支持NVIDIA H100 GPU
利用NVIDIA HGX H100加速計算數(shù)據(jù)中心平臺應(yīng)用
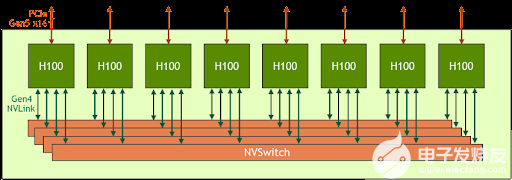
關(guān)于NVIDIA H100 GPU的問題解答
詳解NVIDIA H100 TransformerEngine
英偉達(dá)a100和h100哪個強(qiáng)?
英偉達(dá)h800和h100的區(qū)別
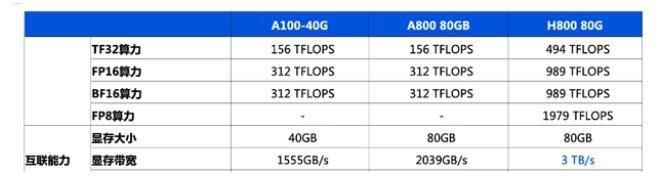
傳英偉達(dá)新AI芯片H20綜合算力比H100降80%
揭秘:英偉達(dá)H100最強(qiáng)替代者





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論