") ChatGPT團(tuán)隊(duì)是如何使用Kubernetes的
ChatGPT團(tuán)隊(duì)是如何使用Kubernetes的
在本文中,OpenAI 的工程師團(tuán)隊(duì)分享了他們?cè)?Kubernetes 集群擴(kuò)展過(guò)程中遇到的各種挑戰(zhàn)和解決方案,以及他們?nèi)〉玫男阅芎托Ч?/p>
我們已經(jīng)將 Kubernetes 集群擴(kuò)展到 7500 個(gè)節(jié)點(diǎn),為大型模型(如 GPT-3、 CLIP 和 DALL·E)創(chuàng)建了可擴(kuò)展的基礎(chǔ)設(shè)施,同時(shí)也為快速小規(guī)模迭代研究(如 神經(jīng)語(yǔ)言模型的縮放定律)創(chuàng)建了可擴(kuò)展的基礎(chǔ)設(shè)施。
將單個(gè) Kubernetes 集群擴(kuò)展到這種規(guī)模很少見(jiàn),但好處是能夠提供一個(gè)簡(jiǎn)單的基礎(chǔ)架構(gòu),使我們的機(jī)器學(xué)習(xí)研究團(tuán)隊(duì)能夠更快地推進(jìn)并擴(kuò)展,而無(wú)需更改代碼。
自上次發(fā)布關(guān)于擴(kuò)展到 2500 個(gè)節(jié)點(diǎn)的帖子以來(lái),我們繼續(xù)擴(kuò)大基礎(chǔ)設(shè)施以滿足研究人員的需求,在此過(guò)程中學(xué)到了許多的經(jīng)驗(yàn)教訓(xùn)。本文總結(jié)了這些經(jīng)驗(yàn)教訓(xùn),以便 Kubernetes 社區(qū)里的其他人也能從中受益,并最后會(huì)介紹下我們?nèi)匀幻媾R的問(wèn)題,我們也將繼續(xù)解決這些問(wèn)題。
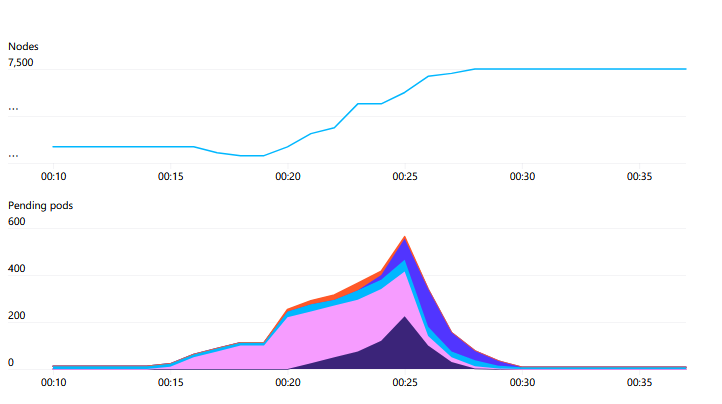
我們的工作負(fù)載
在深入探討之前,我們著重描述一下我們的工作負(fù)載。我們?cè)?Kubernetes 上運(yùn)行的應(yīng)用程序和硬件與大家在普通公司遇到的可能相當(dāng)不同。因此,我們的問(wèn)題及解決方案可能與你自己的設(shè)置匹配,也可能不匹配!
一個(gè)大型的機(jī)器學(xué)習(xí)作業(yè)跨越許多節(jié)點(diǎn),當(dāng)它可以訪問(wèn)每個(gè)節(jié)點(diǎn)上的所有硬件資源時(shí),運(yùn)行效率最高。這允許 GPU 直接使用 NVLink 進(jìn)行交叉通信,或者 GPU 使用 GPUDirect 直接與 NIC 進(jìn)行通信。因此,對(duì)于我們的許多工作負(fù)載,單個(gè) Pod 占用整個(gè)節(jié)點(diǎn)。任何 NUMA、CPU 或 PCIE 資源爭(zhēng)用都不是調(diào)度的因素。裝箱或碎片化不是常見(jiàn)的問(wèn)題。我們目前的集群具有完全的二分帶寬,因此我們也不考慮機(jī)架或網(wǎng)絡(luò)拓?fù)洹K羞@些都意味著,雖然我們有許多節(jié)點(diǎn),但調(diào)度程序的負(fù)載相對(duì)較低。
話雖如此,kube-scheduler 的負(fù)載是有波動(dòng)的。一個(gè)新的作業(yè)可能由許多數(shù)百個(gè) Pod 同時(shí)創(chuàng)建組成,然后返回到相對(duì)較低的流失率。
我們最大的作業(yè)運(yùn)行 MPI,作業(yè)中的所有 Pod 都參與一個(gè)單一的 MPI 通信器。如果任何一個(gè)參與的 Pod 掛掉,整個(gè)作業(yè)就會(huì)停止,需要重新啟動(dòng)。作業(yè)會(huì)定期進(jìn)行檢查點(diǎn),當(dāng)重新啟動(dòng)時(shí),它會(huì)從上一個(gè)檢查點(diǎn)恢復(fù)。因此,我們認(rèn)為 Pod 是半有狀態(tài)的——被刪掉的 Pod 可以被替換并且工作可以繼續(xù),但這樣做會(huì)造成干擾,應(yīng)該盡量減少發(fā)生。
我們并不太依賴 Kubernetes 的負(fù)載均衡。我們的 HTTPS 流量非常少,不需要進(jìn)行 A/B 測(cè)試、藍(lán) / 綠或金絲雀部署。Pod 使用 SSH 直接通過(guò) Pod IP 地址與 MPI 進(jìn)行通信,而不是通過(guò)服務(wù)端點(diǎn)。服務(wù)“發(fā)現(xiàn)”是有限的;我們只在作業(yè)啟動(dòng)時(shí)進(jìn)行一次查找,查找哪些 Pod 參與 MPI。
大多數(shù)作業(yè)與某種形式的 Blob 存儲(chǔ)進(jìn)行交互。它們通常會(huì)直接從 Blob 存儲(chǔ)流式傳輸一些數(shù)據(jù)集的分片或檢查點(diǎn),或?qū)⑵渚彺娴娇焖俚谋镜嘏R時(shí)磁盤(pán)中。我們有一些 PersistentVolumes,用于那些需要 POSIX 語(yǔ)義的情況,但 Blob 存儲(chǔ)更具可擴(kuò)展性,而且不需要緩慢的分離 / 附加操作。
最后,我們的工作性質(zhì)本質(zhì)上是研究,這意味著工作負(fù)載本身是不斷變化的。雖然超級(jí)計(jì)算團(tuán)隊(duì)努力提供我們認(rèn)為達(dá)到“生產(chǎn)”質(zhì)量水平的計(jì)算基礎(chǔ)架構(gòu),但在該集群上運(yùn)行的應(yīng)用程序壽命很短,它們的開(kāi)發(fā)人員會(huì)快速迭代。因此,隨時(shí)可能出現(xiàn)新的使用模式,這些模式會(huì)挑戰(zhàn)我們對(duì)趨勢(shì)和適當(dāng)權(quán)衡的設(shè)定。我們需要一個(gè)可持續(xù)的系統(tǒng),同時(shí)也能讓我們?cè)谑虑榘l(fā)生變化時(shí)快速做出響應(yīng)。
網(wǎng) 絡(luò)
隨著集群內(nèi)節(jié)點(diǎn)和 Pod 數(shù)量的增加,我們發(fā)現(xiàn) Flannel 難以滿足所需的吞吐量。因此,我們轉(zhuǎn)而使用 Azure VMSS 的本地 Pod 網(wǎng)絡(luò)技術(shù)和相關(guān) CNI 插件來(lái)配置 IP。這使我們的 Pod 能夠獲得主機(jī)級(jí)別的網(wǎng)絡(luò)吞吐量。
我們轉(zhuǎn)而使用別名 IP 地址的另一個(gè)原因是,在我們最大的集群中,可能會(huì)同時(shí)使用約 20 萬(wàn)個(gè) IP 地址。在測(cè)試了基于路由的 Pod 網(wǎng)絡(luò)后,我們發(fā)現(xiàn)能夠使用的路由數(shù)明顯存在限制。
避免封裝會(huì)增加底層 SDN 或路由引擎的需求,雖然這使我們的網(wǎng)絡(luò)設(shè)置變得簡(jiǎn)單。添加 VPN 或隧道可以在不需要任何其他適配器的情況下完成。我們不需要擔(dān)心由于某部分網(wǎng)絡(luò)具有較低的 MTU 而導(dǎo)致的分組分段。網(wǎng)絡(luò)策略和流量監(jiān)控很簡(jiǎn)單;沒(méi)有關(guān)于數(shù)據(jù)包源和目的地的歧義。
我們使用主機(jī)上的 iptables 標(biāo)記來(lái)跟蹤每個(gè) Namespace 和 Pod 的網(wǎng)絡(luò)資源使用情況,這使研究人員可以可視化他們的網(wǎng)絡(luò)使用模式。特別是,由于我們的許多實(shí)驗(yàn)具有不同的 Internet 和 Pod 內(nèi)通信模式,因此能夠調(diào)查任何瓶頸發(fā)生的位置通常是非常有意義的。
可以使用 iptables mangle 規(guī)則任意標(biāo)記符合特定條件的數(shù)據(jù)包。以下是我們用來(lái)檢測(cè)流量是內(nèi)部流量還是 Internet 流量的規(guī)則。FORWARD 規(guī)則涵蓋了來(lái)自 Pod 的流量,而 INPUT 和 OUTPUT 規(guī)則涵蓋了主機(jī)上的流量:
iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in" iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in" iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out" iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
一旦標(biāo)記,iptables 將開(kāi)始計(jì)數(shù)以跟蹤匹配該規(guī)則的字節(jié)數(shù)和數(shù)據(jù)包數(shù)。你可以使用 iptables 本身來(lái)查看這些計(jì)數(shù)器:
% iptables -t mangle -L -v Chain FORWARD (policy ACCEPT 50M packets, 334G bytes) pkts bytes target prot opt in out source destination .... 1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */ 1161K 7937M all -- any any !10.0.0.0/8 anywhere /* iptables-exporter openai traffic=internet-in */
我們使用名為 iptables-exporter 的開(kāi)源 Prometheus 導(dǎo)出器將這些數(shù)據(jù)追蹤到我們的監(jiān)控系統(tǒng)中。這是一種簡(jiǎn)單的方法,可以跟蹤與各種不同類型的條件匹配的數(shù)據(jù)包。
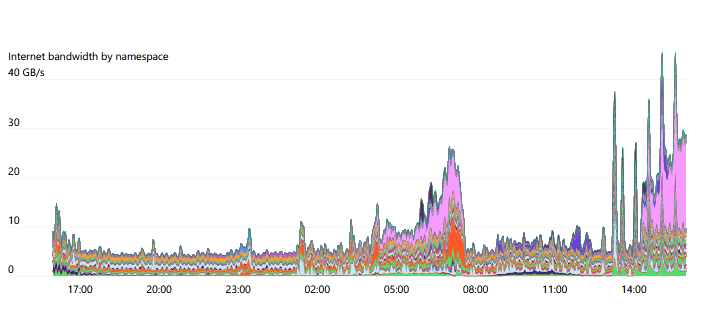
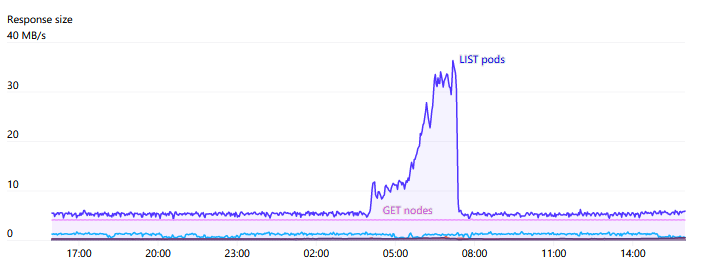
我們網(wǎng)絡(luò)模型中比較獨(dú)特的一點(diǎn)是,我們完全向研究人員公開(kāi)節(jié)點(diǎn)、Pod 和 Service 網(wǎng)絡(luò) CIDR 范圍。我們采用集線器和分支的網(wǎng)絡(luò)模型,并使用本機(jī)節(jié)點(diǎn)和 Pod CIDR 范圍路由該流量。研究人員連接到中心樞紐,然后可以訪問(wèn)任何一個(gè)單獨(dú)的集群(分支)。但是這些集群本身無(wú)法相互通信。這確保了集群保持隔離、沒(méi)有跨集群依賴,可以防止故障隔離中的故障傳播。
我們使用一個(gè)“NAT”主機(jī)來(lái)翻譯從集群外部傳入的服務(wù)網(wǎng)絡(luò) CIDR 范圍的流量。這種設(shè)置為我們的研究人員提供了很大的靈活性,他們可以選擇各種不同類型的網(wǎng)絡(luò)配置進(jìn)行實(shí)驗(yàn)。
API 服務(wù)器
Kubernetes 的 API Server 和 etcd 是保持集群健康運(yùn)行的關(guān)鍵組件,因此我們特別關(guān)注這些系統(tǒng)的壓力。我們使用 kube-prometheus 提供的 Grafana 儀表板以及額外的內(nèi)部?jī)x表板。我們發(fā)現(xiàn),將 HTTP 狀態(tài)碼 429(請(qǐng)求太多)和 5xx(服務(wù)器錯(cuò)誤)的速率作為高級(jí)信號(hào)警報(bào)是有用的。
雖然有些人在 kube 內(nèi)部運(yùn)行 API 服務(wù)器,但我們一直在集群外運(yùn)行它們。etcd 和 API 服務(wù)器都在它們自己的專用節(jié)點(diǎn)上運(yùn)行。我們的最大集群運(yùn)行 5 個(gè) API 服務(wù)器和 5 個(gè) etcd 節(jié)點(diǎn),以分散負(fù)載并盡可能減少發(fā)生故障后帶來(lái)的影響。自從我們?cè)?上一篇博文 中提到的將 Kubernetes 事件拆分到它們自己的 etcd 集群中以來(lái),我們沒(méi)有遇到 etcd 的任何值得注意的問(wèn)題。API 服務(wù)器是無(wú)狀態(tài)的,通常很容易在自我修復(fù)的實(shí)例組或擴(kuò)展集中運(yùn)行。我們尚未嘗試構(gòu)建任何自我修復(fù) etcd 集群的自動(dòng)化,因?yàn)榘l(fā)生事故非常罕見(jiàn)。
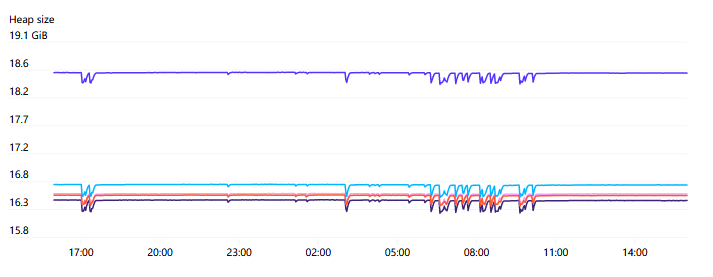
API 服務(wù)器可能會(huì)占用相當(dāng)多的內(nèi)存,并且往往會(huì)與集群中的節(jié)點(diǎn)數(shù)量成線性比例。對(duì)于我們有 7500 個(gè)節(jié)點(diǎn)的集群,我們觀察到每個(gè) API 服務(wù)器使用高達(dá) 70GB 的堆內(nèi)存,因此幸運(yùn)地是,未來(lái)這應(yīng)該仍然在硬件能力范圍之內(nèi)。
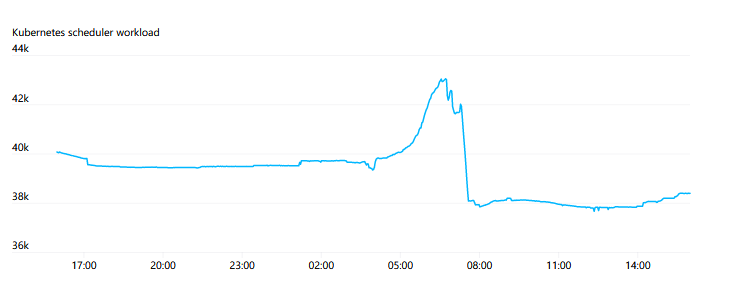
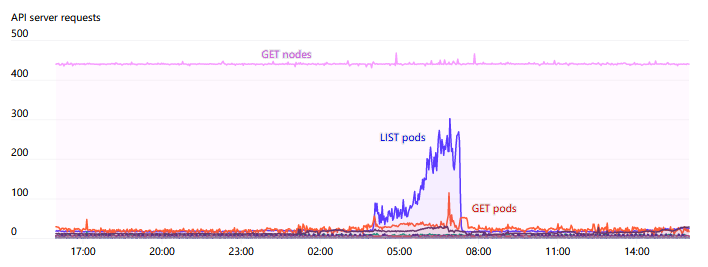
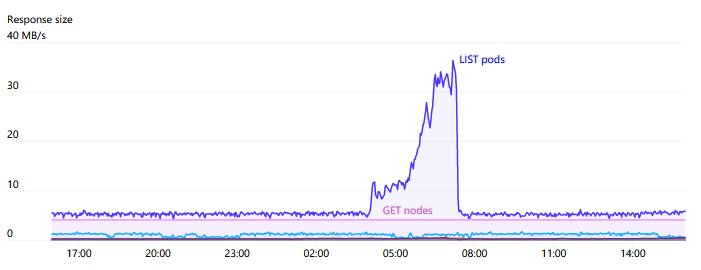
API Servers 受到壓力的主要來(lái)源之一就是對(duì) Endpoints 的 WATCH。在整個(gè)集群中有一些服務(wù),如“kubelet”和“node-exporter”,其中每個(gè)節(jié)點(diǎn)都是成員。當(dāng)一個(gè)節(jié)點(diǎn)被添加或從集群中刪除時(shí),這個(gè) WATCH 將被觸發(fā)。通常,由于每個(gè)節(jié)點(diǎn)本身都通過(guò) kube-proxy 監(jiān)視 kubelet 服務(wù),因此這些響應(yīng)中所需的數(shù)量和帶寬將是N2非常大,有時(shí)會(huì)達(dá)到 1GB/s 或更高。Kubernetes 1.17 中推出的 EndpointSlices 大大降低了這種負(fù)載,減少達(dá) 1000 倍。
總的來(lái)說(shuō),我們會(huì)非常注意隨著集群規(guī)模增大而增加的 API Server 請(qǐng)求。我們盡量避免任何 DaemonSets 與 API Server 交互。在需要每個(gè)節(jié)點(diǎn)監(jiān)視更改的情況下,引入緩存服務(wù)(例如 Datadog Cluster Agent)作為中介,似乎是避免集群范圍瓶頸的良好模式。
隨著集群的增長(zhǎng),我們對(duì)集群的實(shí)際自動(dòng)伸縮越來(lái)越少。但當(dāng)一次性自動(dòng)擴(kuò)展太多時(shí),我們偶爾會(huì)遇到問(wèn)題。當(dāng)新節(jié)點(diǎn)加入集群時(shí)會(huì)生成大量請(qǐng)求,一次性添加數(shù)百個(gè)節(jié)點(diǎn)可能會(huì)超過(guò) API 服務(wù)器容量的負(fù)荷。稍微平滑一下這個(gè)過(guò)程,即使只有幾秒鐘也有助于避免宕機(jī)。
時(shí)間序列度量與 Prometheus 和 Grafana
我們使用 Prometheus 收集時(shí)間序列度量數(shù)據(jù),并使用 Grafana 進(jìn)行圖形、儀表板和警報(bào)。我們從 kube-prometheus 部署開(kāi)始收集了各種各樣的度量數(shù)據(jù),并使用了一些良好的儀表板進(jìn)行可視化。隨著節(jié)點(diǎn)數(shù)量的不斷增加,我們開(kāi)始遇到 Prometheus 收集的度量數(shù)據(jù)數(shù)量過(guò)多的問(wèn)題。盡管 kube-prometheus 公開(kāi)了許多有用的數(shù)據(jù),但我們實(shí)際上并沒(méi)有查看所有的度量數(shù)據(jù),一些數(shù)據(jù)也過(guò)于細(xì)化,無(wú)法有效地進(jìn)行收集、存儲(chǔ)和查詢。因此,我們使用 Prometheus 規(guī)則從被攝入的度量數(shù)據(jù)中“刪掉”一些數(shù)據(jù)。
有一段時(shí)間,我們遇到了 Prometheus 消耗越來(lái)越多的內(nèi)存問(wèn)題,最終導(dǎo)致容器崩潰并出現(xiàn) Out-Of-Memory 錯(cuò)誤(OOM)。即使為應(yīng)用程序分配了大量的內(nèi)存容量,這種情況似乎仍然會(huì)發(fā)生。更糟糕的是,它在崩潰時(shí)會(huì)花費(fèi)很多時(shí)間在啟動(dòng)時(shí)回放預(yù)寫(xiě)日志文件,直到它再次可用。最終,我們發(fā)現(xiàn)了這些 OOM 的來(lái)源是 Grafana 和 Prometheus 之間的交互,其中 Grafana 使用 /api/v1/series API 查詢 {le!=""}(基本上是“給我所有的直方圖度量”)。/api/v1/series 的實(shí)現(xiàn)在時(shí)間和空間上沒(méi)有限制,對(duì)于具有大量結(jié)果的查詢,這將不斷消耗更多的內(nèi)存和時(shí)間。即使請(qǐng)求者已經(jīng)放棄并關(guān)閉了連接,它也會(huì)繼續(xù)增長(zhǎng)。對(duì)于我們來(lái)說(shuō),內(nèi)存永遠(yuǎn)不夠,而 Prometheus 最終會(huì)崩潰。因此,我們修補(bǔ)了 Prometheus,將此 API 包含在上下文中以強(qiáng)制執(zhí)行超時(shí),從而完全解決了問(wèn)題。
雖然 Prometheus 崩潰的次數(shù)大大減少,但在我們需要重新啟動(dòng)它的時(shí)候,WAL 回放仍然是一個(gè)問(wèn)題。通常需要多個(gè)小時(shí)來(lái)回放所有 WAL 日志,直到 Prometheus 開(kāi)始收集新的度量數(shù)據(jù)并提供服務(wù)。在 Robust Perception 的幫助下,我們發(fā)現(xiàn)將 GOMAXPROCS=24 應(yīng)用于服務(wù)器可以顯著提高性能。在 WAL 回放期間,Prometheus 嘗試使用所有核心,并且對(duì)于具有大量核心的服務(wù)器,爭(zhēng)用會(huì)降低所有性能。
我們正在探索新的選項(xiàng)來(lái)增加我們的監(jiān)控能力,下面“未解決的問(wèn)題”部分將對(duì)此進(jìn)行描述。
健康檢查
對(duì)于如此龐大的集群,我們當(dāng)然依賴自動(dòng)化來(lái)檢測(cè)并從集群中移除行為不當(dāng)?shù)墓?jié)點(diǎn)。隨著時(shí)間的推移,我們建立了許多健康檢查系統(tǒng)。
被動(dòng)健康檢查
某些健康檢查是被動(dòng)的,總是在所有節(jié)點(diǎn)上運(yùn)行。這些檢查監(jiān)視基本的系統(tǒng)資源,例如網(wǎng)絡(luò)可達(dá)性、壞盤(pán)或滿盤(pán),或者 GPU 錯(cuò)誤。GPU 以許多不同的方式出現(xiàn)問(wèn)題,但一個(gè)容易出現(xiàn)的常見(jiàn)問(wèn)題是“不可糾正的 ECC 錯(cuò)誤”。Nvidia 的數(shù)據(jù)中心 GPU 管理器(DCGM)工具使查詢這個(gè)問(wèn)題和許多其他“Xid”錯(cuò)誤變得容易。我們跟蹤這些錯(cuò)誤的一種方式是通過(guò) dcgm-exporter 將指標(biāo)收集到我們的監(jiān)控系統(tǒng) Prometheus 中。這將出現(xiàn)為 DCGM_FI_DEV_XID_ERRORS 指標(biāo),并設(shè)置為最近發(fā)生的錯(cuò)誤代碼。此外,NVML 設(shè)備查詢 API 公開(kāi)了有關(guān) GPU 的健康和操作的更詳細(xì)信息。
一旦檢測(cè)到錯(cuò)誤,它們通常可以通過(guò)重置 GPU 或系統(tǒng)來(lái)修復(fù),但在某些情況下確實(shí)需要更換基礎(chǔ) GPU。
另一種健康檢查是跟蹤來(lái)自上游云提供商的維護(hù)事件。每個(gè)主要的云提供商都公開(kāi)了一種方式來(lái)了解當(dāng)前 VM 是否需要進(jìn)行會(huì)最終導(dǎo)致中斷的、即將發(fā)生的維護(hù)事件。VM 可能需要重新啟動(dòng)以應(yīng)用底層的超級(jí)管理程序補(bǔ)丁,或者將物理節(jié)點(diǎn)替換為其他硬件。
這些被動(dòng)健康檢查在所有節(jié)點(diǎn)上不斷運(yùn)行。如果健康檢查開(kāi)始失敗,節(jié)點(diǎn)將自動(dòng)劃分,因此不會(huì)在節(jié)點(diǎn)上安排新的 Pod。對(duì)于更嚴(yán)重的健康檢查失敗,我們還將嘗試 Pod 驅(qū)逐,以要求當(dāng)前運(yùn)行的所有 Pod 立即退出。這仍然取決于 Pod 本身,可通過(guò) Pod 故障預(yù)算進(jìn)行配置來(lái)決定是否允許此驅(qū)逐發(fā)生。最終,無(wú)論是在所有 Pod 終止之后,還是在 7 天過(guò)去之后(我們的服務(wù)級(jí)別協(xié)議的一部分),我們都將強(qiáng)制終止 VM。
活動(dòng) GPU 測(cè)試
不幸的是,并非所有 GPU 問(wèn)題都會(huì)通過(guò) DCGM 可見(jiàn)的錯(cuò)誤代碼表現(xiàn)出來(lái)。我們建立了自己的測(cè)試庫(kù),通過(guò)對(duì) GPU 進(jìn)行測(cè)試來(lái)捕捉其他問(wèn)題,并確保硬件和驅(qū)動(dòng)程序的行為符合預(yù)期。這些測(cè)試無(wú)法在后臺(tái)運(yùn)行 - 它們需要獨(dú)占 GPU 運(yùn)行數(shù)秒鐘或數(shù)分鐘。
我們首先在節(jié)點(diǎn)啟動(dòng)時(shí)運(yùn)行這些測(cè)試,使用我們稱之為“預(yù)檢(preflight)”的系統(tǒng)。所有節(jié)點(diǎn)都會(huì)附帶一個(gè)“預(yù)檢”污點(diǎn)和標(biāo)簽加入集群。這個(gè)污點(diǎn)會(huì)阻止普通 Pod 被調(diào)度到節(jié)點(diǎn)上。我們配置了一個(gè) DaemonSet,在所有帶有此標(biāo)簽的節(jié)點(diǎn)上運(yùn)行預(yù)檢測(cè)試 Pod。測(cè)試成功完成后,測(cè)試本身將刪除污點(diǎn)和標(biāo)簽,然后該節(jié)點(diǎn)就可供一般使用。
我們還定期在節(jié)點(diǎn)的生命周期中運(yùn)行這些測(cè)試。我們將其作為 CronJob 運(yùn)行,允許它著陸在集群中的任何可用節(jié)點(diǎn)上。哪些節(jié)點(diǎn)會(huì)被測(cè)試到可能有些隨機(jī)和不受控制,但我們發(fā)現(xiàn)隨著時(shí)間的推移,它提供了足夠的覆蓋率,并且最小化了協(xié)調(diào)或干擾。
配額和資源使用
隨著集群規(guī)模的擴(kuò)大,研究人員開(kāi)始發(fā)現(xiàn)他們難以獲取分配給他們的全部容量。傳統(tǒng)的作業(yè)調(diào)度系統(tǒng)有許多不同的功能,可以公平地在競(jìng)爭(zhēng)團(tuán)隊(duì)之間運(yùn)行工作,而 Kubernetes 沒(méi)有這些功能。隨著時(shí)間的推移,我們從這些作業(yè)調(diào)度系統(tǒng)中汲取靈感,并以 Kubernetes 原生的方式構(gòu)建了幾個(gè)功能。
團(tuán)隊(duì)污點(diǎn)
我們?cè)诿總€(gè)集群中都有一個(gè)服務(wù),稱為“team-resource-manager”,具有多個(gè)功能。它的數(shù)據(jù)源是一個(gè) ConfigMap,為在給定集群中具有容量的所有研究團(tuán)隊(duì)指定了 (節(jié)點(diǎn)選擇器、應(yīng)用的團(tuán)隊(duì)標(biāo)簽、分配數(shù)量) 元組。它會(huì)將當(dāng)前節(jié)點(diǎn)與這些元組進(jìn)行對(duì)比,并使用 openai.com/team=teamname:NoSchedule 的污點(diǎn)對(duì)適當(dāng)數(shù)量的節(jié)點(diǎn)進(jìn)行標(biāo)記。
“team-resource-manager”還有一個(gè)入站的 webhook 服務(wù),因此在提交每個(gè)作業(yè)時(shí)會(huì)根據(jù)提交者的團(tuán)隊(duì)成員身份應(yīng)用相應(yīng)的容忍度。使用污點(diǎn)使我們能夠靈活地限制 Kubernetes Pod 調(diào)度程序,例如允許較低優(yōu)先級(jí)的 Pod 具有 "any" 容忍度,這樣團(tuán)隊(duì)可以借用彼此的容量,而無(wú)需進(jìn)行大量協(xié)調(diào)。
CPU 和 GPU balloons
除了使用集群自動(dòng)縮放器動(dòng)態(tài)擴(kuò)展我們基于虛擬機(jī)的集群之外,我們還使用它來(lái)糾正(刪除和重新添加)集群中的不健康成員。我們通過(guò)將集群的 "最小值" 設(shè)置為零、"最大值" 設(shè)置為可用容量來(lái)實(shí)現(xiàn)這一點(diǎn)。然而,如果 cluster-autoscaler 發(fā)現(xiàn)有空閑節(jié)點(diǎn),它將嘗試縮小到只需要的容量。由于多種原因(VM 啟動(dòng)延遲、預(yù)分配成本、上面提到的 API 服務(wù)器影響),這種空閑縮放并不理想。
因此,我們?yōu)?CPU 和 GPU 主機(jī)都引入了“球形”部署。這個(gè)部署包含一個(gè)具有 "最大值" 數(shù)量的低優(yōu)先級(jí) Pod 副本集。這些 Pod 占用節(jié)點(diǎn)內(nèi)的資源,因此自動(dòng)縮放器不會(huì)將它們視為空閑。但由于它們是低優(yōu)先級(jí)的,調(diào)度程序可以立即將它們驅(qū)逐出去,以騰出空間進(jìn)行實(shí)際工作。(我們選擇使用 Deployment 而不是 DaemonSet,以避免將 DaemonSet 視為節(jié)點(diǎn)上的空閑工作負(fù)載。)
需要注意的是,我們使用 pod 反親和性(anti-affinity)來(lái)確保 pod 在節(jié)點(diǎn)之間均勻分布。Kubernetes 調(diào)度器的早期版本存在一個(gè) O(N^2) 的性能問(wèn)題,與 pod 反親和性有關(guān)。自 Kubernetes 1.18 版本以后,這個(gè)問(wèn)題已經(jīng)得到了糾正。
Gang 調(diào)度
我們的實(shí)驗(yàn)通常涉及一個(gè)或多個(gè) StatefulSets,每個(gè) StatefulSet 操作不同部分的訓(xùn)練任務(wù)。對(duì)于優(yōu)化器,研究人員需要在進(jìn)行任何訓(xùn)練之前調(diào)度 StatefulSet 的所有成員(因?yàn)槲覀兺ǔJ褂?MPI 在優(yōu)化器成員之間協(xié)調(diào),而 MPI 對(duì)組成員變化很敏感)。
然而再默認(rèn)情況下,Kubernetes 不一定會(huì)優(yōu)先滿足某個(gè) StatefulSet 的所有請(qǐng)求。例如,如果兩個(gè)實(shí)驗(yàn)都請(qǐng)求 100%的集群容量,那么 Kubernetes 可能只會(huì)調(diào)度給每個(gè)實(shí)驗(yàn)需要的一半 Pod,這會(huì)導(dǎo)致死鎖,使兩個(gè)實(shí)驗(yàn)都無(wú)法進(jìn)行。
我們嘗試了一些需要自定義調(diào)度程序的方法,但遇到了一些與正常 Pod 調(diào)度方式?jīng)_突的邊緣情況。Kubernetes 1.18 引入了核心 Kubernetes 調(diào)度程序的插件體系結(jié)構(gòu),使本地添加此類功能變得更加容易。我們最近選擇了 Coscheduling 插件作為解決此問(wèn)題的方法。
未解決的問(wèn)題
隨著 Kubernetes 集群規(guī)模的擴(kuò)大,我們?nèi)杂性S多問(wèn)題需要解決。其中一些問(wèn)題包括:
指標(biāo)
在如今的規(guī)模下,Prometheus 內(nèi)置的 TSDB 存儲(chǔ)引擎很難壓縮,并且每次重新啟動(dòng)時(shí)需要長(zhǎng)時(shí)間回放 WAL(預(yù)寫(xiě)式日志)。查詢還往往會(huì)導(dǎo)致“查詢處理會(huì)加載過(guò)多樣本”的錯(cuò)誤。我們正在遷移到不同的、與 Prometheus 兼容的存儲(chǔ)和查詢引擎。大家可以期待下我們未來(lái)的博客文章,看看它的表現(xiàn)如何!
Pod 網(wǎng)絡(luò)流量整形
隨著集群規(guī)模的擴(kuò)大,每個(gè) Pod 的互聯(lián)網(wǎng)帶寬量被計(jì)算了出來(lái)。每個(gè)人的聚合互聯(lián)網(wǎng)帶寬需求變得非常大,我們的研究人員現(xiàn)在有能力會(huì)意外地對(duì)互聯(lián)網(wǎng)上的其他位置施加重大資源壓力,例如要下載的數(shù)據(jù)集和要安裝的軟件包。
結(jié) 論
Kubernetes 是一個(gè)非常靈活的平臺(tái),可以滿足我們的研究需求。它具有滿足我們所面臨的最苛刻工作負(fù)載的能力。盡管它仍有許多需要改進(jìn)的地方,但 OpenAI 的超級(jí)計(jì)算團(tuán)隊(duì)將繼續(xù)探索 Kubernetes 的可擴(kuò)展性。
審核編輯:湯梓紅
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9160瀏覽量
85421 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8418瀏覽量
132635 -
kubernetes
+關(guān)注
關(guān)注
0文章
224瀏覽量
8716 -
OpenAI
+關(guān)注
關(guān)注
9文章
1089瀏覽量
6514 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1561瀏覽量
7671
原文標(biāo)題:ChatGPT 團(tuán)隊(duì)是如何使用Kubernetes的
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
在FPGA設(shè)計(jì)中是否可以應(yīng)用ChatGPT生成想要的程序呢
Kubernetes的Device Plugin設(shè)計(jì)解讀
Kubernetes Dashboard實(shí)踐學(xué)習(xí)
科技大廠競(jìng)逐AIGC,中國(guó)的ChatGPT在哪?
Kubernetes API詳解
服務(wù)器被擠爆 復(fù)旦MOSS團(tuán)隊(duì)致歉 中國(guó)版chatGPT來(lái)了嗎?

ChatGPT團(tuán)隊(duì)背景研究報(bào)告
Commvault:護(hù)航Kubernetes,不止Kubernetes
Jenkins pipeline是如何連接Kubernetes的呢?
使用Velero備份Kubernetes集群





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論