 Vitis AI工具概述
Vitis AI工具概述
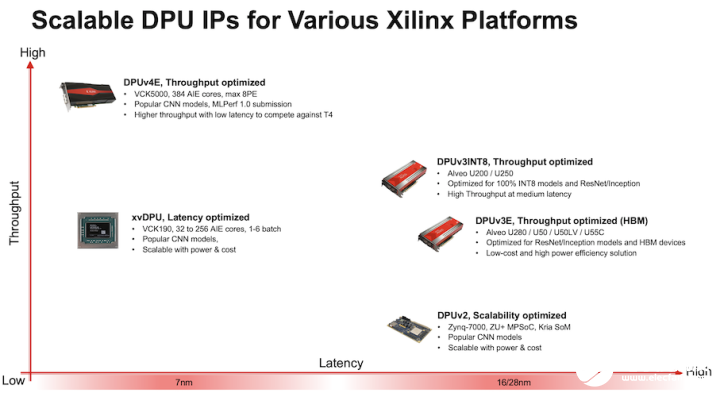
圖 1. DPU 選項
DPU 命名
DPU 名稱的不同字段用于表示不同的特征或作用,命名方案如下圖所示:
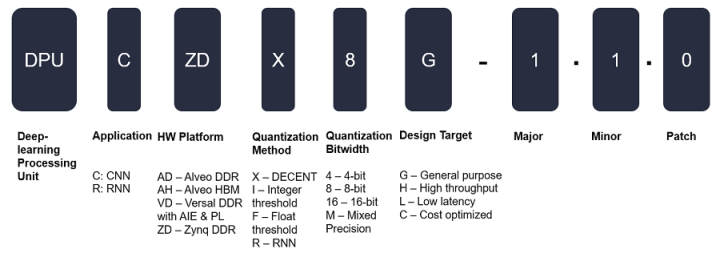
圖 2. DPU 命名方案
Zynq UltraScale+ MPSoC:DPUCZDX8G
DPUCZDX8G IP 針對 Zynq UltraScale+ MPSoC 進行了最優化。您可將此 IP 作為塊集成到選定的 Zynq UltraScale+ MPSoC 的可編程邏輯 (PL) 中,并直接連接到處理器系統 (PS)。DPU 可由用戶配置且包含多個參數,用戶可通過指定這些參數來對 PL 資源進行最優化,或者也可以自定義啟用的功能。如要在自定義的 AI 工程或產品中集成 DPU,請訪問Vitis-AI/dsa/DPU-TRD at master · Xilinx/Vitis-AI · GitHub。
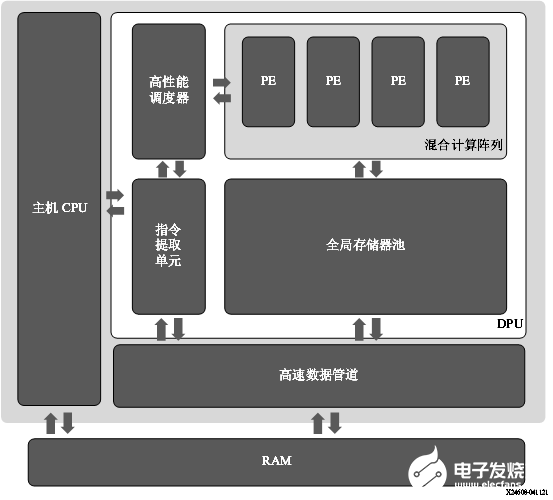
圖 3. DPUCZDX8G 架構
Alveo U50LV/U55C 卡:DPUCAHX8H
賽靈思 DPUCAHX8H DPU 是專為卷積神經網絡最優化的可編程引擎,主要適用于高吞吐量應用。本單元包含高性能調度器模塊、混合計算陣列模塊、指令提取單元模塊和全局存儲器池模塊。DPU 使用專用指令集,從而支持諸多卷積神經網絡的有效實現。其中部署的一些卷積神經網絡示例包括 VGG、ResNet、GoogLeNet、YOLO、SSD、MobileNet 和 FPN。 DPU IP 可實現到選定的 Alveo 開發板的 PL 中。DPU 需要通過指令才能為輸入圖像、臨時數據和輸出數據實現神經網絡和可訪問的存儲器位置。PL 上運行的用戶定義單元也需要執行必要的配置、注入指令、服務中斷和協調數據傳輸。 DPU 的頂層模塊框圖如下圖所示。
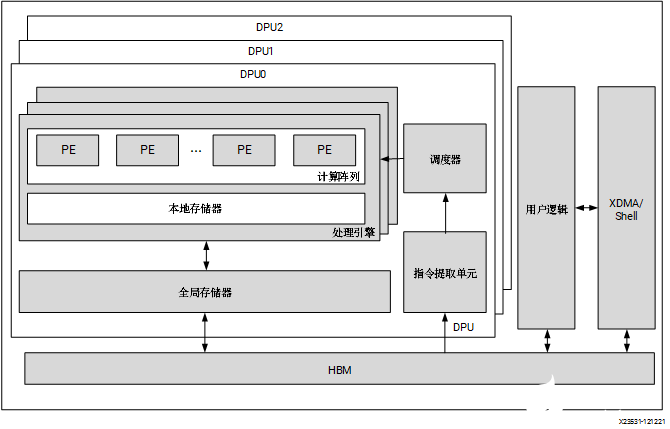
圖 4. DPUCAHX8H 頂層模塊框圖
Alveo U200/U250 卡:DPUCADF8H
DPUCADF8H 是專為 Alveo U200/U250 卡最優化的 DPU,適用于高吞吐量應用。DPUCADF8H 的關鍵特征如下:
以吞吐量為導向的高效計算引擎:根據不同工作負載,吞吐量可改善達 1.5~2.0 倍
廣泛的卷積神經網絡支持
對剪枝卷積神經網絡友好
專為高分辨率圖像而最優化
頂層模塊框圖如下圖所示:
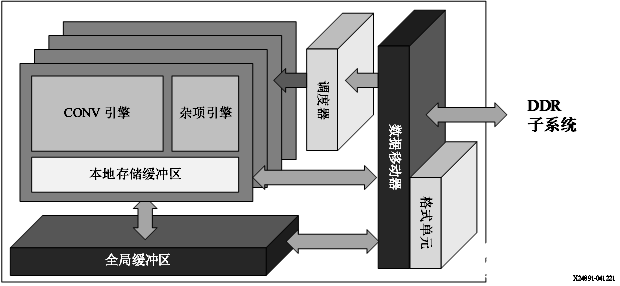
圖 5. DPUCADF8H 架構
Versal AI Core 系列:DPUCVDX8G
DPUCVDX8G 是高性能通用 CNN 處理引擎,針對 Versal AI Core 系列進行了最優化。相比傳統 FPGA、CPU 和 GPU,Versal 器件可提供卓越的性能/功耗比。DPUCVDX8G 由 AI 引擎 和 PL 電路組成。此 IP 可由用戶配置且包含多個參數,用戶可通過指定這些參數來對 AI 引擎和 PL 資源進行最優化,或者自定義功能。 DPUCVDX8G 的頂層模塊框圖如下圖所示。
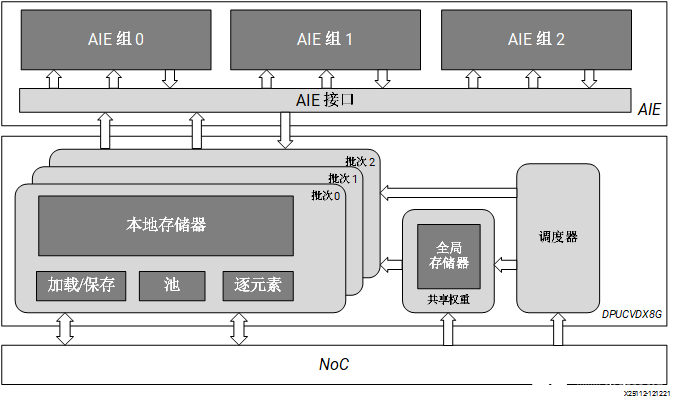
圖 6. DPUCVDX8G 架構
Versal AI Core 系列:DPUCVDX8H
DPUCVDX8H 是高性能、高吞吐量通用 CNN 處理引擎,針對 Versal AI Core 系列進行了最優化。除了傳統程序邏輯之外,Versal 器件還集成了高性能 AI 引擎陣列、高帶寬 NoC、DDR/LPDDR 控制器和其它高速接口,與傳統 FPGA、CPU 和 GPU 相比,可提供出色的性能功耗比。DPUCVDX8H 在 Versal 器件上實現,以便充分利用這些優勢。您可通過配置參數來滿足您的數據中心應用要求。 DPUCVDX8H 的頂層模塊框圖如下圖所示。
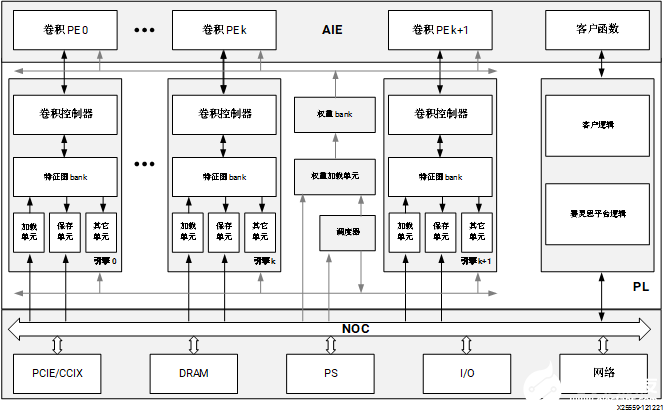
圖 7. DPUCVDX8H 模塊框圖
Vitis AI Model Zoo
Vitis AI Model Zoo 包含經過最優化的深度學習模型,可在賽靈思平臺上加速部署深度學習推斷。這些模型涵蓋了不同的應用,包括 ADAS/AD、視頻監控機器人學和數據中心等。您可從這些經過預訓練的模型開始著手,享受深度學習加速所帶來的諸多利益。 如需了解更多信息,請參閱 GitHub 上的Vitis AI Model Zoo。
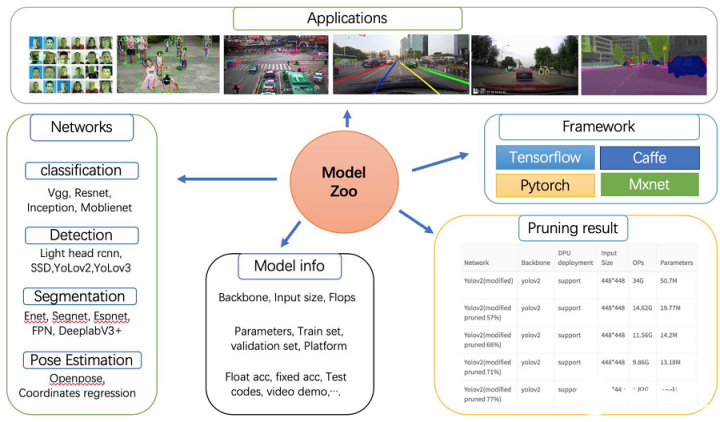
圖 8. Vitis AI Model Zoo
Vitis AI 優化器
借助世界領先的模型壓縮技術,您可在保證最低限度的精度降級的前提下,將模型復雜性降低 5 到 50 倍。如需了解有關 Vitis AI 優化器的信息,請參閱 Vitis AI 優化器用戶指南(UG1333)。 Vitis AI 優化器需商用許可證方可運行。請與賽靈思銷售代表聯系以獲取更多信息。
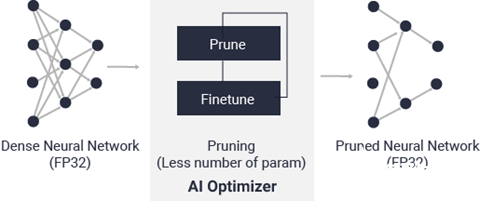
圖 9. Vitis AI 優化器
Vitis AI 量化器
通過將 32 位浮點權重和激活轉換為定點(如 INT8),Vitis AI 量化器可降低計算復雜性,而不會損失預測精度。定點網絡模型所需存儲器帶寬較少,因此相比浮點模型,速度更快且能效更高。

圖 10. Vitis AI 量化器
Vitis AI 編譯器
Vitis AI 編譯器可將 AI 模型映射到高效的指令集和數據流模型。它還可盡可能執行復雜的最優化操作,例如,層融合、指令調度和復用片上存儲器。
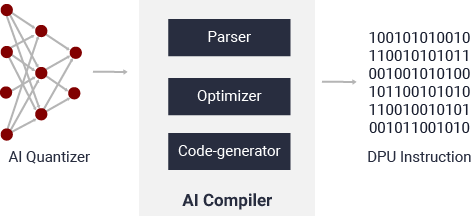
圖 11. Vitis AI 編譯器
Vitis AI Profiler
Vitis AI Profiler 可用于對 AI 應用進行性能剖析和可視化,以在不同器件之間查找瓶頸并分配計算資源。它使用方便且無需更改任何代碼。它可追蹤函數調用和運行時,也可收集硬件信息,包括 CPU、DPU 和存儲器利用率。

圖 12. Vitis AI Profiler
Vitis AI 庫
Vitis AI 庫是一組高層次庫和 API,專為利用 DPU 高效執行 AI 推斷而構建。它是基于 Vitis AI 運行時利用 Vitis 運行時統一 API 來構建的,能夠為 XRT 提供完整支持。 Vitis AI 庫通過封裝諸多高效且高質量的神經網絡,提供易用且統一的接口。由此可簡化深度學習神經網絡的使用,對于不具備深度學習或 FPGA 知識的用戶也是如此。Vitis AI 庫使您能夠專注于開發自己的應用,而不是底層硬件。
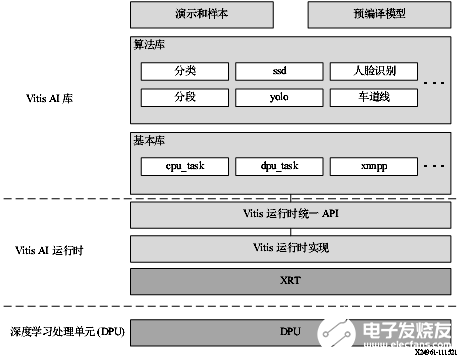
圖 13. Vitis AI 庫
Vitis AI 運行時
Vitis AI 運行時支持應用為云端和邊緣器件使用統一的高層次運行時 API,實現無縫高效的云端到邊緣部署。 AI 運行時 API 的功能如下所述:
向加速器異步提交作業
從加速器異步收集作業
支持多線程和多進程執行
Vitis AI 運行時 (VART) 是下一代運行時,適合基于 DPUCZDX8G、DPUCADF8H、DPUCAHX8H、DPUCVDX8G 和 DPUCVDX8H 的器件。
DPUCZDX8G 用于邊緣器件,如 ZCU102 和 ZCU104 評估板以及 KV260 入門套件。
DPUCADX8G 和 DPUCADF8H 用于云端器件,例如 Alveo U200 和 U250 卡。
DPUCAHX8H 用于云端器件,例如 Alveo U50LV 和 U55C 卡。
DPUCVDX8G 用于 Versal 評估板,例如 VCK190 開發板。
DPUCVDX8H 用于 Versal ACAP VCK5000 開發板。
VART 框架如下圖所示。對于此 Vitis AI 版本,VART 基于 XRT。XIR 對應賽靈思中間表示形式 (Xilinx Intermediate Representation)。
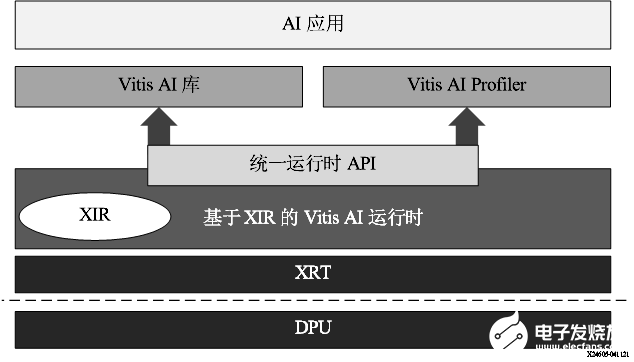
圖 14. VART 棧
文章來源:芯選
審核編輯:湯梓紅
-
處理器
+關注
關注
68文章
19349瀏覽量
230296 -
AI
+關注
關注
87文章
31155瀏覽量
269494 -
DPU
+關注
關注
0文章
365瀏覽量
24215 -
Vitis
+關注
關注
0文章
147瀏覽量
7461
發布評論請先 登錄
相關推薦
Vitis AI Model Zone軟件平臺具備哪些功能?
【KV260視覺入門套件試用體驗】部署vitis-ai環境以及測試demo
【KV260視覺入門套件試用體驗】Vitis AI 初次體驗
【KV260視覺入門套件試用體驗】部署DPU鏡像并運行Vitis AI圖像分類示例程序
【KV260視覺入門套件試用體驗】五、VITis AI (人臉檢測和人體檢測)
【KV260視覺入門套件試用體驗】六、VITis AI車牌檢測&車牌識別
【KV260視覺入門套件試用體驗】基于Vitis AI的ADAS目標識別
【KV260視覺入門套件試用體驗】Vitis-AI加速的YOLOX視頻目標檢測示例體驗和原理解析
【KV260視覺入門套件試用體驗】Vitis AI 構建開發環境,并使用inspector檢查模型
【KV260視覺入門套件試用體驗】Vitis AI Library體驗之OCR識別
基于軟件的Vitis AI 2.0加速解決方案
Vitis HLS工具簡介及設計流程
Vitis AI RNN用戶指南






 工商網監
工商網監
評論