") Mobileye和特斯拉差距在哪?
Mobileye和特斯拉差距在哪?
對(duì)比Mobileye和特斯拉,兩者做事風(fēng)格截然不同。Mobileye有著十幾年的積累,可靠性經(jīng)過(guò)了市場(chǎng)和時(shí)間的驗(yàn)證,傳統(tǒng)大廠無(wú)一例外都會(huì)選擇Mobileye,但同時(shí)意味著有資產(chǎn)包袱,不舍得放棄以前的研究成果,難接受新的研究方向與潮流變化,對(duì)學(xué)術(shù)界的東西似乎完全不在意。特斯拉則是博采各家所長(zhǎng),時(shí)刻關(guān)注著學(xué)術(shù)界的最新動(dòng)向,發(fā)現(xiàn)有好的技術(shù)點(diǎn)就努力將其落地,始終走在技術(shù)最前沿。
Mobileye在L2領(lǐng)域占據(jù)絕對(duì)霸主地位,市場(chǎng)占有率超過(guò)70%,特斯拉則是智能駕駛技術(shù)的引領(lǐng)者。對(duì)于感知任務(wù),核心就是建立一個(gè)3D的周邊環(huán)境模型,即3D場(chǎng)景重建,這也是L2與L2+系統(tǒng)的本質(zhì)區(qū)別。L2的目的是避免碰撞,遇到可能發(fā)生的碰撞就剎車或減速,而L2+系統(tǒng)是自主駕駛,遇到可能發(fā)生的碰撞時(shí),通過(guò)對(duì)周邊3D場(chǎng)景重建,找到可行駛空間Freespace繞開(kāi)障礙物,而不是減速或剎車。3D場(chǎng)景重建的最佳表征形式是BEV即鳥(niǎo)瞰,很多時(shí)候BEV幾乎等于3D場(chǎng)景重建。
3D場(chǎng)景重建最佳解決辦法是立體雙目,即基于Depth Map的3D重建。立體雙目可以準(zhǔn)確測(cè)量出深度信息,但除了博世、奔馳、豐田這些大廠外,雙目的標(biāo)定和立體匹配是無(wú)法跨越的難關(guān),包括特斯拉和Mobileye。還有一個(gè)原因是新興造車在單目上累積了豐富的知識(shí)產(chǎn)權(quán),跳到立體雙目領(lǐng)域意味著這些累積都作廢了,這是最核心資產(chǎn)的嚴(yán)重流失。
特斯拉和Mobileye的思路都是用單目做3D重建,常見(jiàn)方法有SfM和Transformer。此外3D場(chǎng)景重建還可以基于點(diǎn)云、VOXEL和MESH。
SfM(Structure From Motion)是最經(jīng)典技術(shù)路線,通過(guò)使用諸如多視圖幾何優(yōu)化之類的數(shù)學(xué)理論從2D圖像序列中確定目標(biāo)的空間幾何關(guān)系,以通過(guò)相機(jī)移動(dòng)恢復(fù)3D結(jié)構(gòu)。SFM方便靈活,但在圖像序列采集中遇到場(chǎng)景和運(yùn)動(dòng)退化問(wèn)題。根據(jù)圖像添加順序的拓?fù)浣Y(jié)構(gòu),可以將其分為增量/順序SFM、全局SFM、混合SFM和分層SFM。此外,還有語(yǔ)義SFM和基于深度學(xué)習(xí)的SFM。步驟包括1.特征提取(SIFT、SURF、FAST等方法);2.配準(zhǔn)(主流是RANSAC和它的改進(jìn)版;3.全局優(yōu)化bundleadjustment用來(lái)估計(jì)相機(jī)參數(shù);4.數(shù)據(jù)融合。

Mobileye的SuperVision
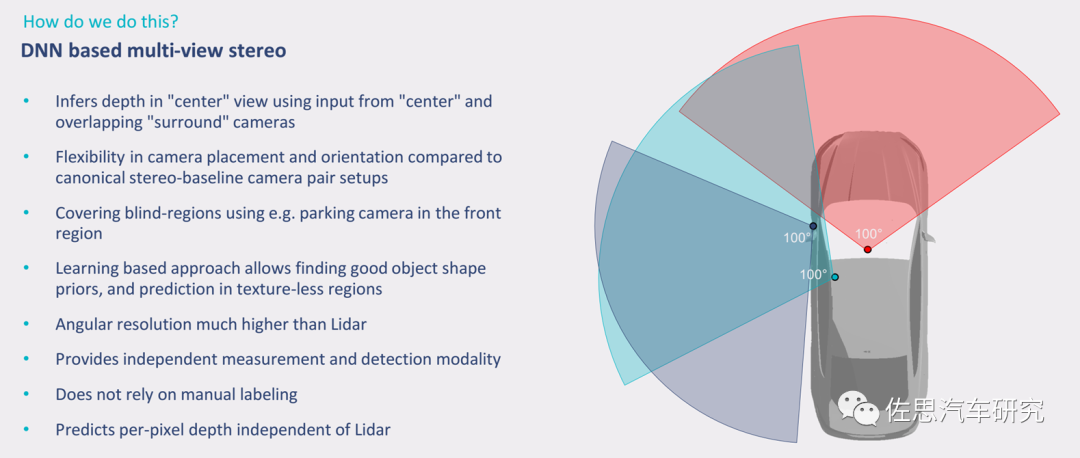
Mobileye的multi-view stereo實(shí)際就是SFM的另一種說(shuō)法,Mobileye還給它取了另一個(gè)名字Vidar或者叫偽激光雷達(dá),這就是SuperVision的核心。

Mobileye的SuperVision,7個(gè)800萬(wàn)像素?cái)z像頭

7個(gè)攝像頭聯(lián)合得到的3D場(chǎng)景重建

偽激光雷達(dá)

VIDAR就是multi-view stereo
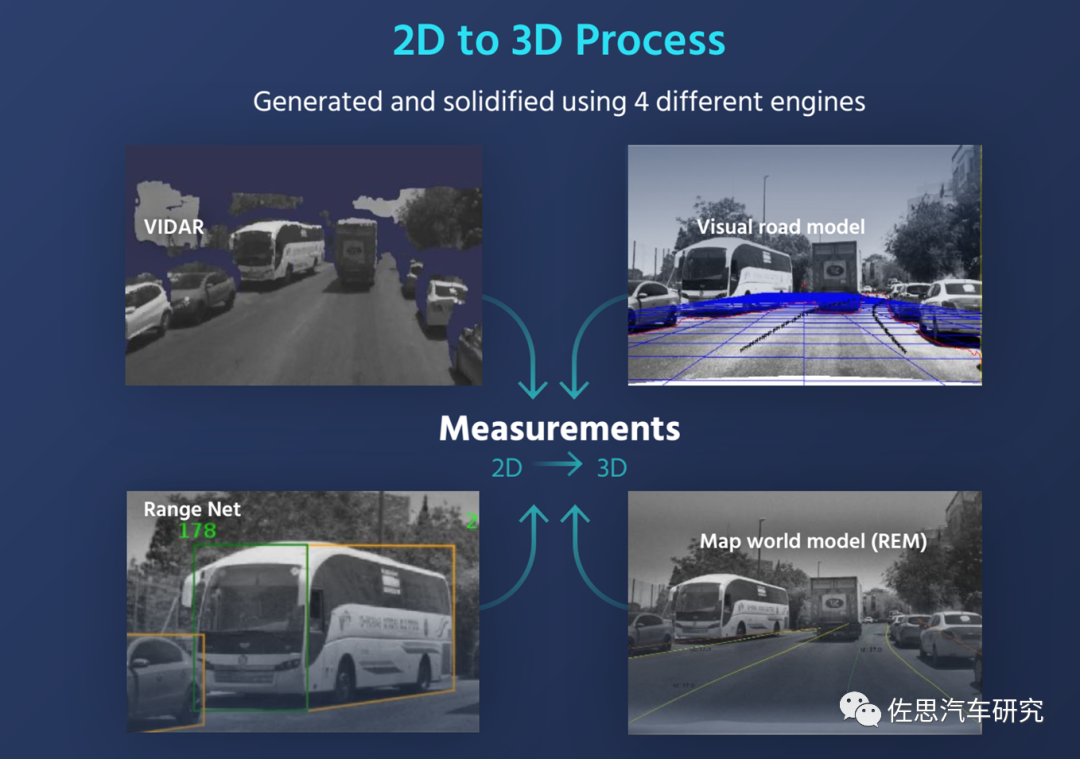
Mobileye的SFM還混合了REM和視覺(jué)道路模型
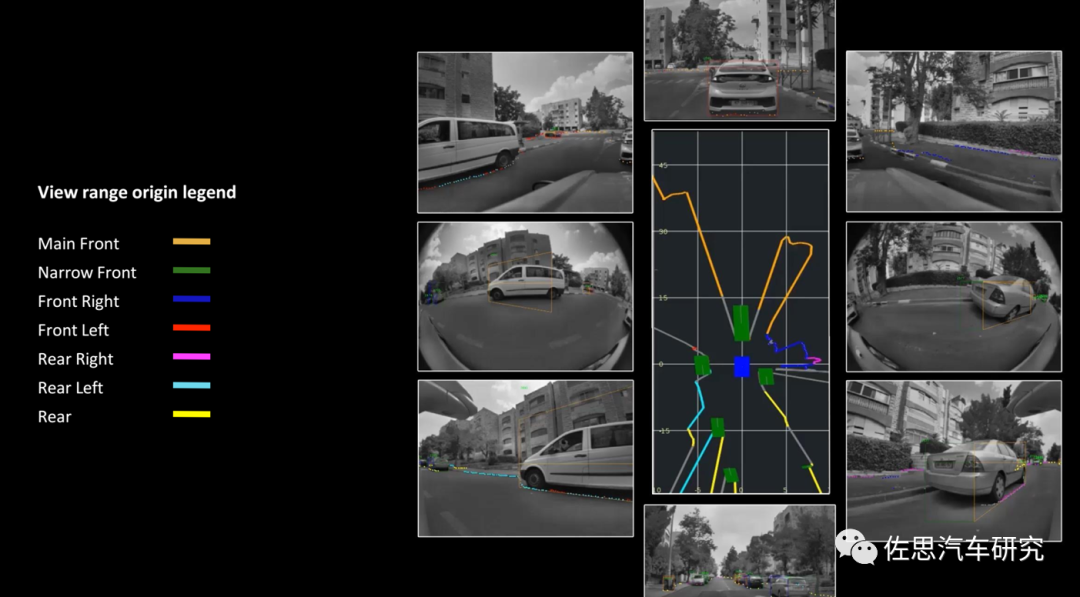
SuperVision也可以得到BEV視角,不過(guò)不像特斯拉那樣高精細(xì)度,特斯拉的所謂OccupancyGrid,Mobileye也有使用。當(dāng)然,大部分情況下還是非BEV視角。
SFM的優(yōu)點(diǎn)是設(shè)計(jì)簡(jiǎn)單,有些類型的SFM可以用非深度學(xué)習(xí)算法,對(duì)算力需求很低,即使深度學(xué)習(xí)算法,因?yàn)檫€是參數(shù)量不到千萬(wàn)的CNN,對(duì)算力需求還是很低。不過(guò)SFM精度不高,特別是大范圍場(chǎng)景或者說(shuō)遠(yuǎn)距離使用困難,因?yàn)橐粋€(gè)大場(chǎng)景環(huán)境是很復(fù)雜的,如各種物體、多樣的光照、反光表面,還有不同焦距、畸變和傳感器噪聲的多樣攝像機(jī)。許多先前的方法采用多視角深度估計(jì)(MVS)來(lái)重建場(chǎng)景,預(yù)測(cè)每一幀圖像的稠密深度圖,這種depth-based方法可以估計(jì)準(zhǔn)確的局部幾何形狀,但需要額外的步驟來(lái)融合這些深度圖,例如解決不同視角之間的不一致性,這相當(dāng)困難。Mobileye的解決辦法是使用高像素?cái)z像頭,7個(gè)攝像頭都是8百萬(wàn)像素,像素越高,有效距離越遠(yuǎn)。
再有就是SFM準(zhǔn)確度有限,為了從多個(gè)輸入視圖中學(xué)習(xí)有效的3D表示,大多數(shù)基于CNN的方法遵循分而治之的設(shè)計(jì)原則,其中通常的做法是引入CNN進(jìn)行特征提取和融合模塊來(lái)集成多個(gè)視圖的特征或重建得到。盡管這兩個(gè)模塊之間有很強(qiáng)的關(guān)聯(lián),但它們的方法設(shè)計(jì)是分開(kāi)研究的。另外,在CNN特征提取階段,很少研究不同視圖中的目標(biāo)關(guān)系。雖然最近的一些方法引入了遞歸神經(jīng)網(wǎng)絡(luò)(RNN)來(lái)學(xué)習(xí)不同視圖之間的目標(biāo)關(guān)系,但這種設(shè)計(jì)缺乏計(jì)算效率,而且RNN模型的輸入視圖是對(duì)順序變化敏感的,難以與一組無(wú)序的輸入視圖兼容。
輪到特斯拉的BEVFormer閃亮登場(chǎng)了,BEV一直存在,BEV視角下的物體,不會(huì)出現(xiàn)圖像視角下的尺度(scale)和遮擋(occlusion)問(wèn)題。由于視覺(jué)的透視效應(yīng),物理世界物體在2D圖像中很容易受到其他物體遮擋,2D感知只能感知可見(jiàn)的目標(biāo),而在BEV空間內(nèi),算法可以基于先驗(yàn)知識(shí),對(duì)被遮擋的區(qū)域進(jìn)行預(yù)測(cè)。再有就是BEV視角下,感知和決策規(guī)劃有機(jī)地融為一體,依靠Freespace或者說(shuō)Occupancy Grid提供直接路徑規(guī)劃,無(wú)需中間計(jì)算環(huán)節(jié),速度和準(zhǔn)確度都大幅提升。
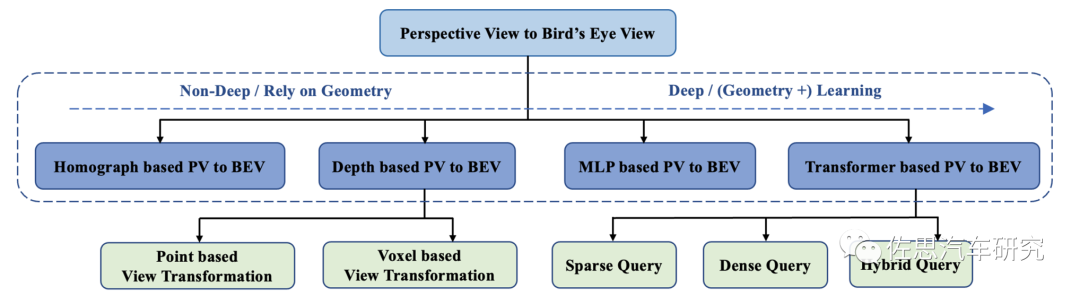
BEV可以分為基于深度/幾何信息的和基于深度學(xué)習(xí)的兩大類。
基于深度/幾何信息的 BEV 是正向思維,采用自底向上、從2D 到3D 的方式,先在2D視角預(yù)測(cè)每個(gè)像素的深度再通過(guò)內(nèi)外參投影到 BEV空間通過(guò)多視角的融合生成BEV特征,但對(duì)深度的估計(jì)一直都是難點(diǎn)。不過(guò)激光雷達(dá)和雙目都可以提供準(zhǔn)確的深度信息完全不是難點(diǎn)。純單目的方式典型代表就是SFM,用SFM 推測(cè)深度信息。Mobileye 可以用SFM 做出BEV,但目前來(lái)看還似乎是沒(méi)有使用,還是2D 平視。
基于深度學(xué)習(xí)的 BEV是逆向思維,采用自頂向下、從3D到2D 的方式,先在 BEV 空間初始化特征,再通過(guò)多層transformer 與每個(gè)圖像特征進(jìn)行交互融合,最終再得到 BEV特征。這就是特斯拉的BEVFormer。
早期自動(dòng)駕駛研究階段都是頭頂64線或128線360度Velodyne機(jī)械激光雷達(dá),就是為了制造BEV視角,但是要到落地階段,Velodyne的64線或128線激光雷達(dá)顯然無(wú)法商業(yè)化。
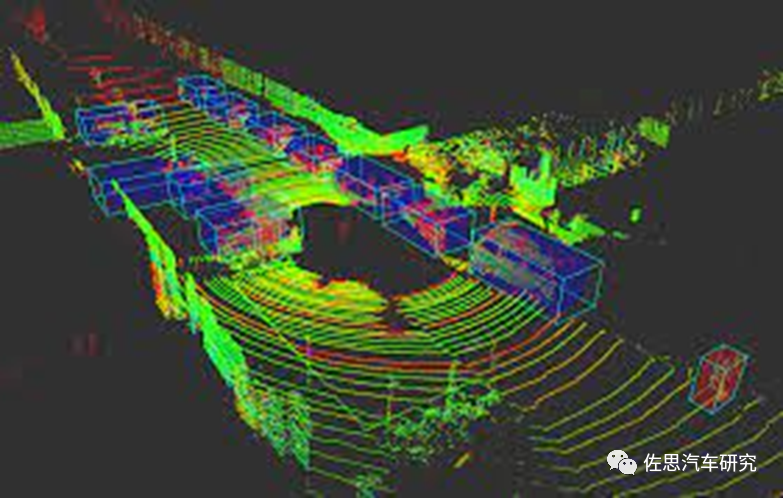
激光雷達(dá)制造的BEV
于是才有了純攝像頭的BEV。BEV是連接時(shí)空的理想橋梁。對(duì)于人類視覺(jué)感知系統(tǒng)來(lái)說(shuō),時(shí)間信息在推斷目標(biāo)的運(yùn)動(dòng)狀態(tài)和識(shí)別遮擋目標(biāo)方面起著至關(guān)重要的作用,視覺(jué)領(lǐng)域的許多工作已經(jīng)證明了視頻數(shù)據(jù)的有效性。然而,現(xiàn)有最先進(jìn)的多攝像頭3D檢測(cè)方法很少利用時(shí)間信息。應(yīng)用Transformer(空域)結(jié)構(gòu)和Temporal結(jié)構(gòu)(時(shí)域)從多攝像頭輸入生成鳥(niǎo)瞰圖(BEV)特征。BEVFormer利用查詢查找空域和時(shí)域,并相應(yīng)地聚合時(shí)-空信息,有利于實(shí)現(xiàn)感知任務(wù)的更強(qiáng)表征。
Transformer是一種基于注意力機(jī)制(Attention)的神經(jīng)網(wǎng)絡(luò)模型,由Google在2017年提出。與傳統(tǒng)神經(jīng)網(wǎng)絡(luò)RNN和CNN不同,Transformer不會(huì)按照串行順序來(lái)處理數(shù)據(jù),而是通過(guò)注意力機(jī)制,去挖掘序列中不同元素的聯(lián)系及相關(guān)性,這種機(jī)制背后,使得Transformer可以適應(yīng)不同長(zhǎng)度和不同結(jié)構(gòu)的輸入。利用多個(gè)無(wú)序輸入之間的自注意力來(lái)探索視圖到視圖的關(guān)系。將多視圖3D重建問(wèn)題重新表述為一個(gè)序列到序列的預(yù)測(cè)問(wèn)題,并將特征提取和視圖融合統(tǒng)一在單個(gè)transformer網(wǎng)絡(luò)中。
另一方面,在Transformer模型中,自注意力機(jī)制在任意數(shù)量的輸入標(biāo)記內(nèi)顯示出其學(xué)習(xí)復(fù)雜語(yǔ)義抽象的強(qiáng)大能力,并且自然地適合于探索3D目標(biāo)不同語(yǔ)義部分的視圖到視圖關(guān)系。鑒于此,transformer的結(jié)構(gòu)成為多視圖3D重建最吸引人的解決方案,transformer配合語(yǔ)義分割有更好的效果,傳統(tǒng)的CNN也有不錯(cuò)的3D重建。
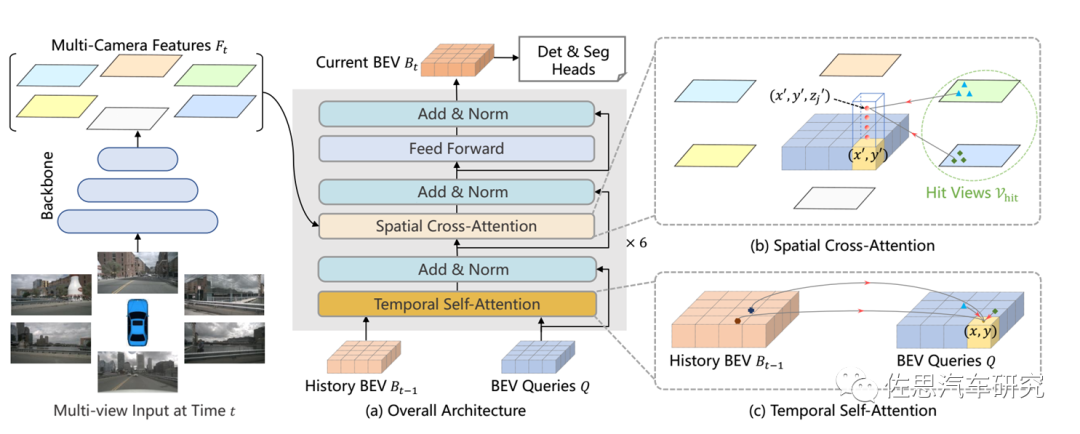
BEVFormer整體架構(gòu)
需要指出BEVFormer有兩個(gè)概念,一個(gè)是南京大學(xué)、上海AI實(shí)驗(yàn)室和香港大學(xué)提出的,見(jiàn)論文《BEVFormer: Learning Bird’s-Eye-View Representation from Multi-CameraImages via Spatiotemporal Transformers》,另一個(gè)是人們根據(jù)特斯拉AI日中的介紹,認(rèn)為特斯拉的感知結(jié)合了BEV和Transformer,因此稱其為BEVFormer。特斯拉不會(huì)公布自己的源代碼,而《BEVFormer: Learning Bird’s-Eye-ViewRepresentation from Multi-Camera Images via Spatiotemporal Transformers》內(nèi)附源代碼。
特斯拉自己對(duì)BEV + Transformer的叫法應(yīng)該是Multi-CamVector Space Predictions。
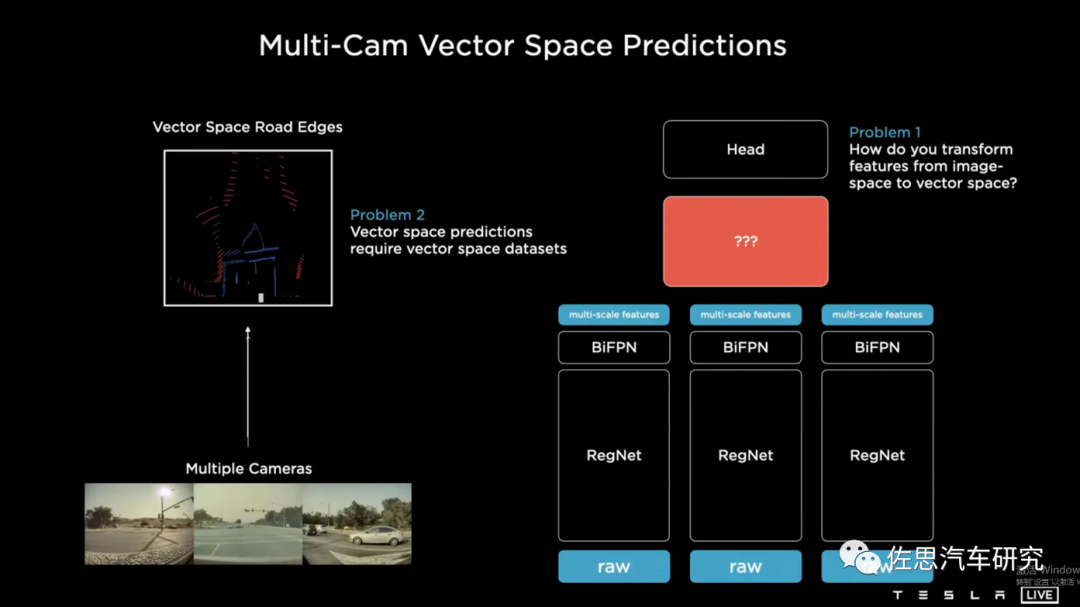
其內(nèi)部構(gòu)造可以參考FACEBOOK的論文《End-to-End Object Detection with Transformers》
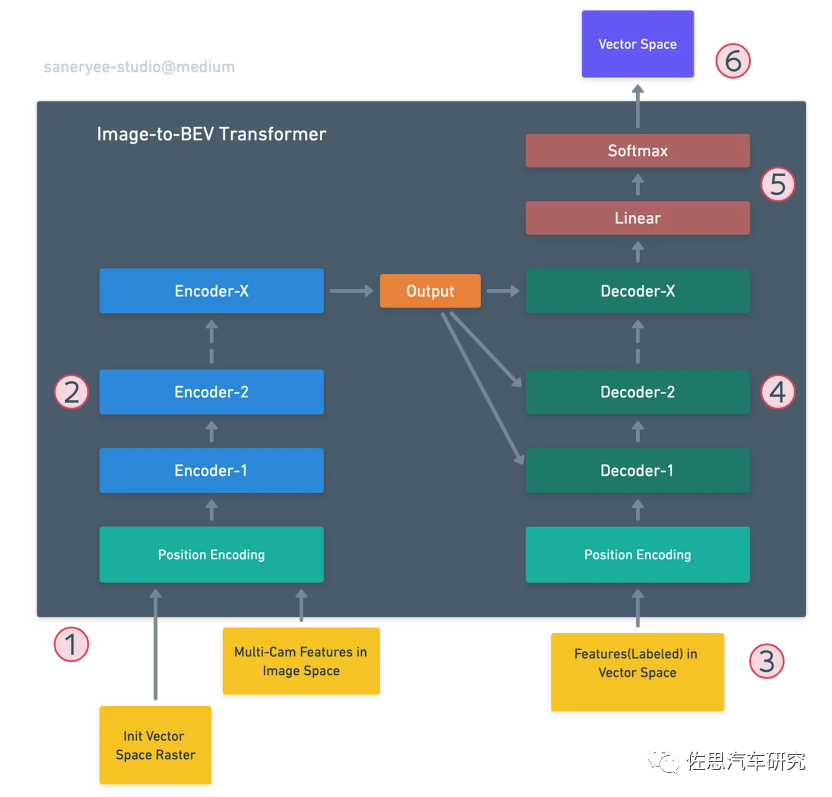
特斯拉圖像到BEV的Transformer
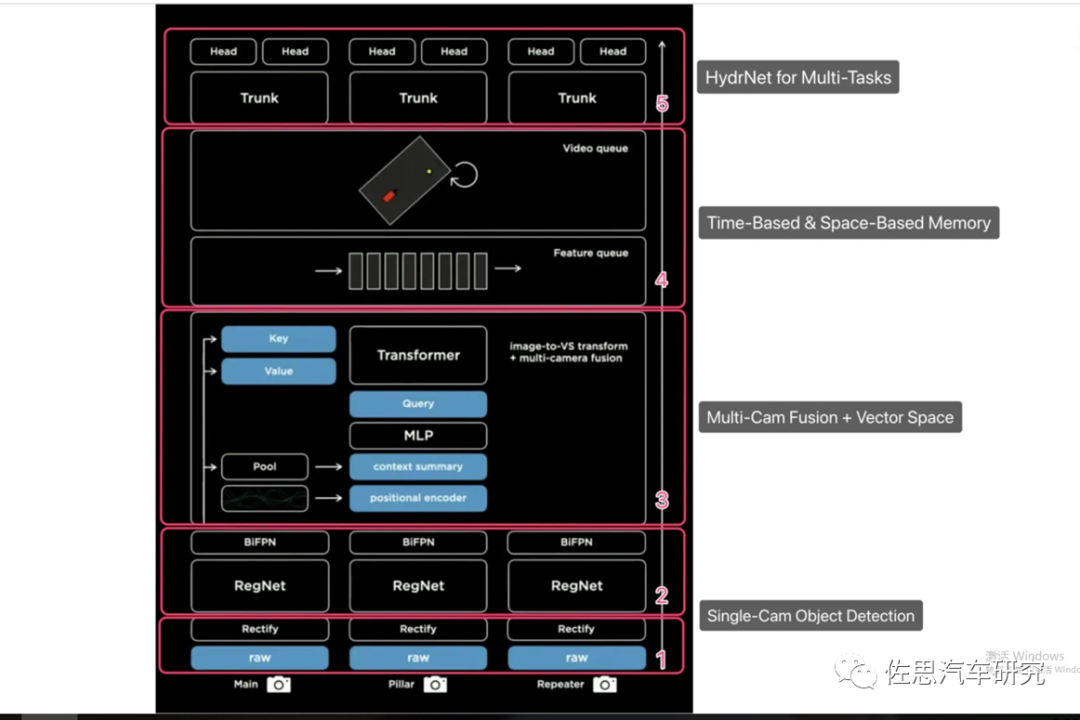
特斯拉視覺(jué)系統(tǒng)整體架構(gòu),BEV+Transformer也就是第二層的Multi-camFusion+矢量空間。
特斯拉的第一層的BiFPN也值得一提。BiFPN當(dāng)然也不是特斯拉創(chuàng)造的,它的詳細(xì)理論參見(jiàn)論文《EfficientDet: Scalable and Efficient Object Detection》,作者是谷歌大腦研究小組。
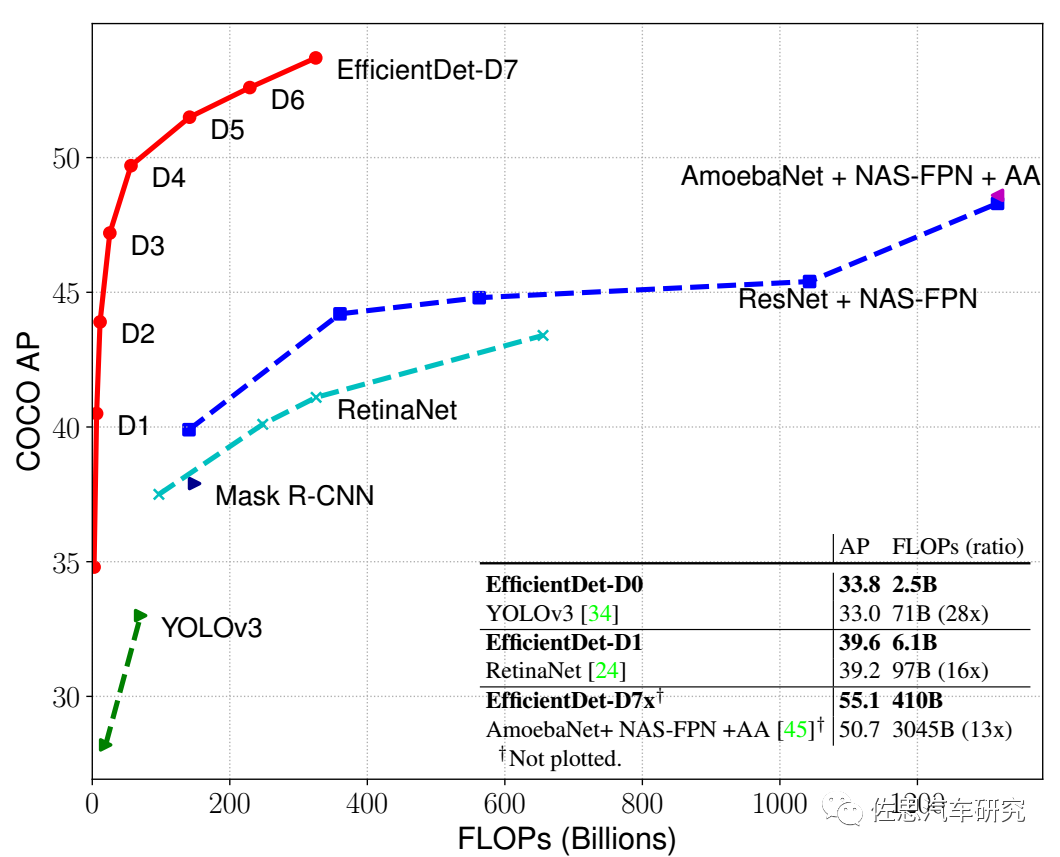
BiFPN準(zhǔn)確率很高,消耗算力比傳統(tǒng)的ResNet要低很多。
Mobileye的算力不高,不是AI算力不高,CPU算力也不高,GPU幾乎為零,因此Mobileye將環(huán)境模型分成4部分,降低計(jì)算密度。

針對(duì)4個(gè)子目錄有不同的處理技術(shù)

這其中的語(yǔ)義分割和特斯拉的Occupancy Grid基本一致,只是特斯拉是基于BEV視角的。

Mobileye的語(yǔ)義分割,Mobileye早在2018年就提出此項(xiàng)技術(shù)并于2019年商業(yè)化落地,技術(shù)實(shí)力還是很不錯(cuò)的。
表面上看,特斯拉和Mobileye的SuperVision的思路一致,但Transformer的使用讓特斯拉明顯遠(yuǎn)比Mobileye要強(qiáng)大,不過(guò)一代FSD或者說(shuō)HW3.0能跑BEVFormer嗎?典型的NLP用Transformer參數(shù)是10億個(gè),針對(duì)視頻的可能會(huì)有20億個(gè),按照汽車行業(yè)慣用的INT8格式,意味著Transformer模型大小是2GB。特斯拉初代 FSD 使用的 LPDDR4,型號(hào)是MT53D512M32D2DS-046 AAT,容量為16Gb,總共 8 片,I/O 頻率 2133MHz,其帶寬為 2.133*64/8,即 17.064GB/s,由于DDR是雙通道,所以帶寬是34.12GB/s,這里非常抱歉,以前的算法有錯(cuò)誤(錯(cuò)誤照搬了英偉達(dá)的張量并行模式),嚴(yán)重高估了內(nèi)存帶寬。
順便指出像ChatGPT這種大模型,英偉達(dá)是采用張量并行的方式計(jì)算,因此如果是8張H100顯卡,英偉達(dá)是將權(quán)重模型一分為8,等同于內(nèi)存帶寬增加了8倍,但是張量并行是針對(duì)多張顯卡服務(wù)器設(shè)計(jì)的,對(duì)于車載領(lǐng)域,Transformer還未聽(tīng)說(shuō)用張量并行的,張量并行也是英偉達(dá)獨(dú)創(chuàng)的。內(nèi)存帶寬僅有34.12GB/s是無(wú)法流暢運(yùn)行Transformer的,因?yàn)槊糠昼妴螁巫x入權(quán)重模型的次數(shù)最高也不過(guò)17次,還未包括處理數(shù)據(jù)的時(shí)間和路徑規(guī)劃所需要的時(shí)間,而智能駕駛需要幀率至少是每秒30幀,也就是每秒30次以上計(jì)算,那么內(nèi)存帶寬至少要能支持每秒60次讀入,也就是帶寬要增加3倍以上。
不僅是內(nèi)存帶寬,Transformer不僅對(duì)AI算力需求大,對(duì)CPU的標(biāo)量算力需求也大,初代FSD僅有12個(gè)ARM Cortex-A72,這是不夠的。二代FSD或者說(shuō)HW4.0用了昂貴的GDDR6,帶寬大幅增加,CPU核心也從12個(gè)增加到20個(gè),勉強(qiáng)可以跑Transformer。不過(guò)GDDR6雖然帶寬高,但速度低,用在CPU領(lǐng)域并不合適。
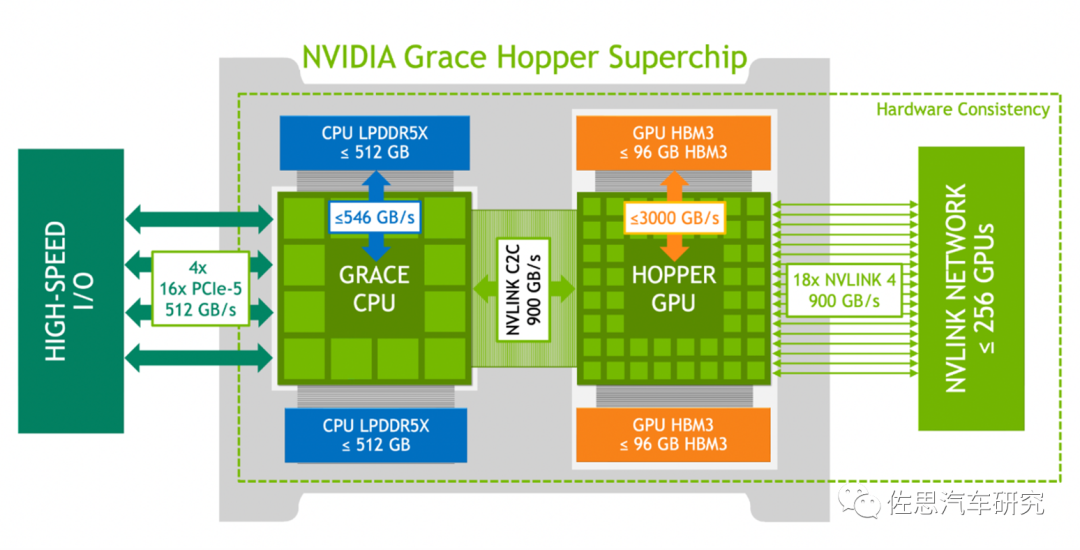
服務(wù)器領(lǐng)域內(nèi)存是分開(kāi)的,CPU用強(qiáng)調(diào)速度的DDR5,GPU用強(qiáng)調(diào)帶寬的HBM3。但汽車領(lǐng)域是CPU+GPU(AI),一般廠家都選擇LPDDR5(LP是低功耗的意思),照顧C(jī)PU更多,特斯拉為了強(qiáng)調(diào)AI算力,用了GDDR6。
初代FSD可能還上不了BEVFormer,與Mobileye的SuperVision效果相比,Mobileye的像素遠(yuǎn)高于初代FSD,有效距離更遠(yuǎn),安全系數(shù)更高。但二代FSD就目前來(lái)看,是可以全面勝過(guò)SuperVision的,不過(guò)即使是美國(guó)市場(chǎng),二代FSD估計(jì)也要等到2024年才會(huì)上市,中國(guó)市場(chǎng)估計(jì)要到2025年甚至2026年,屆時(shí)Mobileye或許也有技術(shù)升級(jí)。
-
3D
+關(guān)注
關(guān)注
9文章
2880瀏覽量
107566 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9176瀏覽量
85461 -
Mobileye
+關(guān)注
關(guān)注
2文章
130瀏覽量
33795
原文標(biāo)題:Mobileye和特斯拉差距在哪?
文章出處:【微信號(hào):zuosiqiche,微信公眾號(hào):佐思汽車研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Mobileye牽手Innoviz合作激光雷達(dá)用于其Mobile Drive平臺(tái)
采用LP875761—Q1的Mobileye EyeQ4高電源設(shè)計(jì)

Mobileye關(guān)閉激光雷達(dá)研發(fā)部門
極氪與Mobileye攜手加速自動(dòng)駕駛技術(shù)中國(guó)本地化
特斯拉線圈的疑惑
特斯拉Q1銷量下滑,比亞迪銷量持續(xù)攀升
大眾汽車和Mobileye加強(qiáng)自動(dòng)駕駛合作
Mobileye將為大眾旗下豪華品牌提供駕駛輔助軟件
經(jīng)緯恒潤(rùn)國(guó)內(nèi)首個(gè)基于Mobileye EyeQ?6的高級(jí)駕駛輔助系統(tǒng)即將量產(chǎn)

英特爾子公司Mobileye與馬興達(dá)合作打造下一代智能駕駛技術(shù)
Mobileye和馬恒達(dá)合作開(kāi)發(fā)完全自動(dòng)駕駛系統(tǒng)
Mobileye披露與國(guó)際汽車制造商巨頭的最新合作
Mobileye披露與國(guó)際汽車制造商巨頭基于核心技術(shù)平臺(tái)的最新合作
Mobileye暴跌25%:客戶芯片庫(kù)存過(guò)高導(dǎo)致
特斯拉超預(yù)期交付,比亞迪登頂全球銷量之冠





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論