 什么是數據庫營銷
什么是數據庫營銷
數據庫一致性(database consistency)由一組值定義,數據庫系統中的所有數據點都必須與這些值保持一致,才能正確讀取和接受數據。如果任何不符合先決條件值的數據進入數據庫,將導致數據集出現一致性錯誤。數據庫一致性通過建立規則來實現。任何寫入數據庫的數據事務都只能按照數據庫開發人員制定的規則,包括特定約束、觸發器、變量、級聯等來更改受影響的數據。
例如,假設您某地區的交通安全研究所工作。您的任務是創建一個新駕照數據庫。在過去的十年中,該地區的人口激增,因此需要為所有首次申領駕照的人提供新的字母和數字格式。在您的數據庫中,該地區駕照的新設定值如下:1個字母+ 7個數字,現在每個條目都必須遵循這一規則。如果輸入"C08846024",則返回錯誤。為什么?因為輸入的值是1個字母+8個數字,這實質上是一種不一致的數據形式。
一致性還意味著,一個表中任何一個特定對象的任何數據更改都需要在該對象所在的所有其他表中進行更改。繼續以駕照為例,如果駕駛員的家庭地址發生變化,則必須在所有存在該地址的表中體現該更新。如果一個表中是舊地址,而其他所有表中卻是新地址,這也是數據不一致的典型例子。
注意:數據庫一致性并不保證在任何給定事務中引入的數據是正確的,它只保證在系統中寫入和讀取的數據符合所有有資格進入數據庫的數據的先決條件。更簡單地說,在上面的示例中,您可以輸入符合1個字母+ 7個數字規則的數據事務,但這并不能保證數據與實際的駕照相對應。數據庫一致性并不考慮數據所代表的內容,只考慮其格式。
為什么數據庫一致性很重要?
一致的數據使數據庫能夠像運轉良好的機器一樣運行。已建立的規則/值可將不一致的數據排除在主數據庫和副本之外,從而保持其操作順利:
準確性
增加數據庫空間
更快、更高效的數據檢索
數據庫一致性對所有輸入數據進行管理。因此,盡管數據庫在接受新數據時會發生變化,但它至少會根據一開始制定的驗證規則一致地發生變化。如今,全球每天都有數十億美元的決策是根據數據庫的一致性做出的。當實時信息成為現代數字業務的基礎時,制定驗證規則以確保數據集沒有錯誤信息就顯得至關重要。因為數據錯誤增加延遲,損害實時體驗。
數據庫一致性示例
現實世界中有哪些數據庫一致性操作的例子?我們已經在上文的駕照數據庫場景中探討了一個例子。現在我們轉向銀行業看看。
假設您正在將資金從一個賬戶轉入另一個賬戶。您剛剛將12000元轉入一個已有3000元的賬戶中。假設正確刷新后,賬戶余額會顯示為15000元。但是,新余額現在顯示為0元,說明最新的操作并沒有反映在您的余額中。這種技術上的疏忽是數據庫弱一致性的一個典型例子。諸如此類的問題可能會損害銀行聲譽并造成巨大損失。對于任何行業的數據庫開發人員和消費者來說,數據庫系統的強一致性正變得越來越不可或缺。
強一致性 vs 弱一致性
強一致性:主節點、副本及其所有相應節點中的所有數據都符合驗證規則,并且在任何給定時間內都是相同的。有了強數據庫一致性,無論從哪個客戶端訪問數據—客戶將始終看到遵循數據庫既定規則的更新版本數據。
弱一致性:無法保證主節點、副本節點或節點中的數據在任何時刻都是相同的。某個客戶可以訪問數據,并看到通過驗證規則的信息,但可能不是最近更新的數據,從而導致一致性錯誤。
Redis Enterprise(Redis企業版數據庫)的Active-Active地理分布允許多個主數據庫,使您能夠靈活地處理越來越大的工作負載。所謂 "Active-Active",是指數據庫的每個實例都可以接受對任何鍵的讀寫操作。每個數據庫實例,無論距離多遠,都是網絡上的一個對等節點。這意味著,當對任何實例進行寫操作時,該節點會自動向網絡上的所有其他實例發送消息,說明緩存中的哪些內容發生了更改,并確保所有實例保留一致的緩存數據集。
Redis Enterprise獨特的Active-Active地理分布采用了復雜的算法,旨在處理可能導致緩存不一致的潛在寫入沖突。這些算法基于無沖突復制數據類型(CRDT),確保來自多個副本的寫入數據能夠以有效保持一致性的方式進行合并。
虹科是Redis企業版數據庫中國區戰略合作伙伴,可為您提供技術支持和解決方案服務。Redis企業版軟件(Redis Enterprise)是企業級的數據庫軟件,也是一款實時數據平臺,為全球超過8500家知名企業提供實時數據服務。具有線性可擴展性、高可用性、持久性、備份和恢復、地理分布、分層內存訪問、多租戶、安全性等8大核心功能、擁有RediSearch、RedisJSON等7大【Redis企業版特有模塊】,可以任何規模在云、本地和混合部署中運行現代應用程序,提供無服務器、多模型的數據庫解決方案。
一致性級別
一致性級別是另一組先決條件值,它決定了有多少個副本或節點必須響應新的允許數據,然后才被確認為有效事務。這種操作可以根據每筆事務進行更改。例如,程序員可以規定,在確認數據一致性之前,只有兩個節點需要讀取新輸入的數據。一旦數據跨過了這個界限,它就會被認為是一致的數據。
隔離級別
隔離級別是數據庫ACID(原子性、一致性、隔離性、持久性)屬性的一部分。ACID是SQL數據庫一致性的基本概念,也是某些數據庫為優化數據庫一致性而遵循的基本概念。隔離(Isolation)是ACID屬性之一,它將某些數據塊與特定數據庫網絡中的所有信息隔離開來,使其不會被其他用戶事務修改。隔離被用來減少并發事務中產生的無關數據的讀寫。
有四種類型的隔離級別:
(1)未提交讀取:最低級別。如果前一個事務對該行進行了未提交更新,則停止該行的更新。
(2)已提交讀取:不允許"臟讀"。如果事務已經更新,但尚未提交,則會阻止任何讀取或寫入。
(3)可重復讀取:該級別使正在讀取的數據行不會被訪問和更新。
(4)可序列化:最高隔離級別,可序列化通常鎖定整個表,而不是特定的數據行。
復制過程中的一致性
Redis企業版數據庫軟件能夠將數據復制到另一個數據庫實例,以獲得高可用性,并將內存中的數據永久持久化到磁盤上,以獲得持久性。使用WAIT命令,可以控制復制和持久化數據庫的一致性和持久性保證。
向數據庫發布的任何更新通常按以下流程執行:
(1)應用程序發出寫操作
(2)代理與系統中包含給定鍵的正確主(也稱為“master”)"分片"通信
(3)分片寫入數據并向代理發送回執
(4)代理將回執發送給應用程序
(5)主分片向副本發送寫入信息
(6)副本將寫入確認發回給主服務器
(7)寫入副本的內容被持久化到磁盤上
(8)副本內部確認寫入
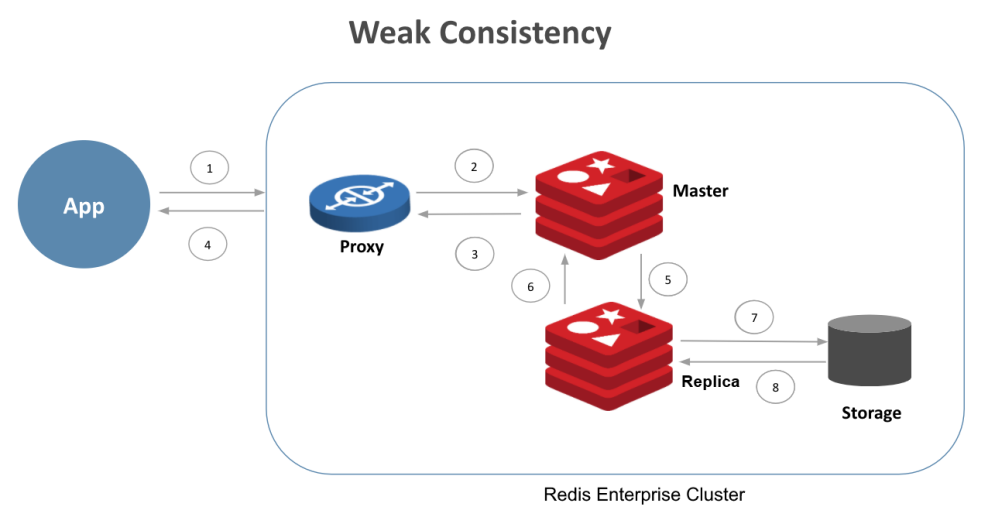
使用WAIT命令,應用程序可以要求僅在復制或持久性在副本上確認后等待確認。
命令的寫操作流程如下所示:
(1)應用程序發出寫操作
(2)代理與系統中包含給定key的正確主 "分片"通信
(3)復制將更新傳遞給副本分片
(4)復制將更新持久化到磁盤(假設選擇了每次寫入都自動更新)
(5-8)通過步驟5至8,確認從副本一直發回代理。
通過此流程,應用程序只有在復制到副本和持久化存儲實現耐久性后,才能從寫入中獲得確認。
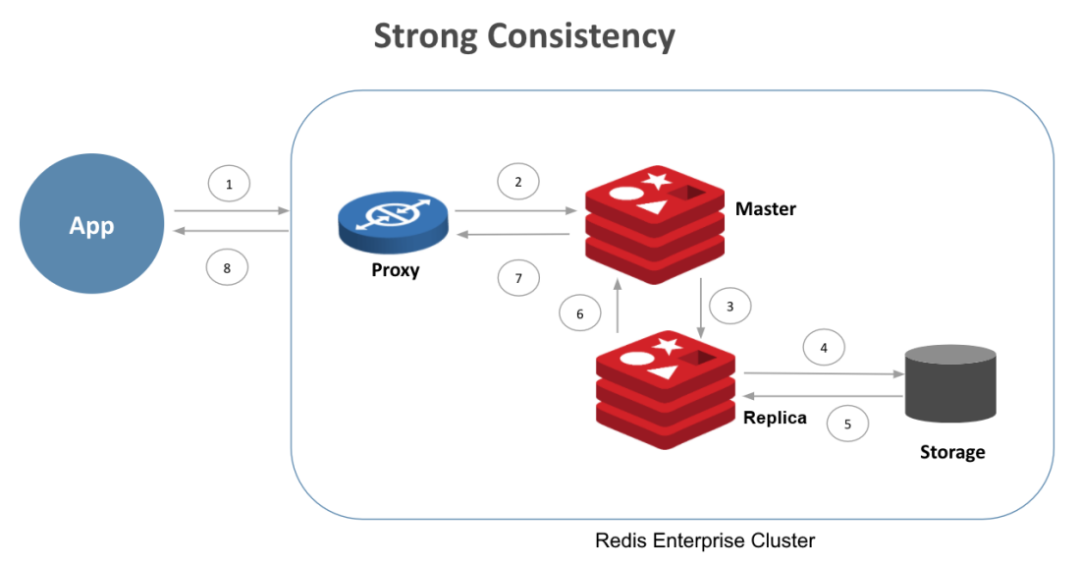
使用WAIT命令,應用程序可以保證,在節點故障或節點重新啟動的情況下也會記錄已確認的寫入。
數據庫一致性常見問題解答(QA)
Q:數據一致性意味著什么?
A:如果數據在同一時間出現在所有相應的節點中,無論用戶在哪里訪問數據,數據都是一致的。
Q:數據一致性與數據庫一致性是一回事嗎?
A:數據一致性是指數據在整個網絡中以及在使用該數據的眾多應用程序之間盡可能保持一致的過程。數據庫一致性要求對進入網絡的數據制定驗證規則,以使其在公式上與表中的所有其他數據保持一致。
Q:什么是最終一致性?
A:通過最終一致性,經過更新的數據最終將反映在存儲該數據的所有節點中。最終,通過最終一致性,無論任何客戶端在網絡中訪問數據,所有節點都將生成相同的數據。
Q:關系數據庫中的單個表包括?
A:關系數據庫中的所有數據都存儲在表中,表由行和列組成。數據點被組織在這些行和列中。行通常被稱為 "記錄",代表數據類別,而列或 "字段 "則代表 "實例"。在數據庫中可以找到表格,其基于主題的設計有助于防止數據冗余。
Q:關系數據庫由哪些部分組成?
A:關系數據庫由表組成
Q:ACID模型與BASE模型相比有何不同?
A:ACID和BASE(基本可用、軟狀態、最終一致)模型之間的主要區別在于,ACID致力于優化數據庫一致性,而BASE則加強高可用性。ACID可保持事務一致性,因此如果您采用BASE模型,請確保一致性仍是重中之重,并得到徹底解決。
Q:Redis數據庫是否一致?
A:當Redis用作緩存時,一致性問題可能發生在Redis實例(主/副本)之間,以及Redis緩存和作為主數據庫的Redis之間。在這種情況下,如果兩者之間的數據不匹配,數據就會不一致。對于開源Redis來說,一致性較弱,但Redis Enterprise的Active-Active Geo-Distribution提供了較強的最終一致性。
審核編輯:劉清
-
觸發器
+關注
關注
14文章
2000瀏覽量
61158 -
隔離器
+關注
關注
4文章
773瀏覽量
38332 -
WAIT
+關注
關注
0文章
4瀏覽量
2520
原文標題:虹科干貨 | 什么是數據庫一致性?
文章出處:【微信號:Hongketeam,微信公眾號:廣州虹科電子科技有限公司】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫加密辦法
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫事件觸發的設置和應用
數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

Oracle數據恢復—異常斷電后Oracle數據庫啟庫報錯的數據恢復案例
數據庫數據恢復—Oracle數據庫文件system01.dbf損壞的數據恢復案例
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

數據庫數據恢復—SqlServer數據庫底層File Record被截斷為0的數據恢復案例
恒訊科技分析:sql數據庫怎么用?
數據庫數據恢復—SQL Server數據庫所在分區空間不足報錯的數據恢復案例
數據庫數據恢復—數據庫所在分區空間不足導致sqlserver故障的數據恢復案例
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例

選擇 KV 數據庫最重要的是什么?
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例





 工商網監
工商網監
評論