 “百模大戰”:盤點國內外橫空出世的AI大模型
“百模大戰”:盤點國內外橫空出世的AI大模型
所謂AI大模型就是人工智能預訓練模型,包含三大要素:大算力、強算法、大數據。大模型相當于人工智能的土壤,沒有大模型支持,就不會有AI的成功。
AI大模型戰場上,國外的OpenAI、谷歌、微軟等大廠正打得火熱;國內以百度、阿里、華為、騰訊為代表的科技巨頭,科大訊飛、智譜AI、商湯科技等AI公司,三大運營商,以及智源研究院、中科院等學術/研究機構都紛紛投身AI大模型浪潮。
從全球已經發布的大模型分布來看,中美兩國數量合計占全球總數的超 80%,美國在大模型數量方面居全球之首。有專家披露,據不完全統計,目前中國 10 億參數規模以上的大模型已發布 79 個。

下面一起看看在“百模大戰”下,有哪些橫空出世的AI大模型!
國內戰場
百度:文心大模型
2017年,在百度首屆AI開發者大會上,百度喊出了“All in AI”口號,隨后圍繞著AI進行了技術研發投入。得益于在人工智能領域的長期投入,百度在人工智能四層架構,也就是“芯片層、框架層、模型層、應用層”有著全棧的布局。
在芯片層,百度昆侖芯科技已實現兩代通用 AI芯片“昆侖”的量產及應用,為大模型落地提供強大算力支持。
在框架層,“飛槳”是國內首個自主研發的產業級深度學習平臺,集基礎模型庫、端到端開發套件和工具組件于一體,有效支持文心大模型高效、穩定訓練。
在模型層,“文心大模型”包括基礎大模型、任務大模型、行業大模型三級體系,全面滿足產業應用需求。
在應用層,文心已大規模應用于百度自有業務的各類產品,并通過企業級平臺“文心千帆”進一步推動生態構建。
文心大模型包括 NLP 大模型、CV 大模型、跨模態大模型、生物計算大模型和行業大模型。目前,文心大模型已經迭代至3.5版本,與3.0版本相比,訓練速度提升了2倍,推理速度提升了17倍,模型效果累計提升超過50%。據百度官方表示,文心一言大模型的訓練數據包括了萬億級網頁數據、數十億的搜索數據和圖片數據、百億級的語音日均調用數據,以及5500億事實的知識圖譜等。

騰訊:混元大模型
基于騰訊強大的底層算力和低成本的高速網絡基礎設施,2022 年底騰訊發布了低成本、可落地的NLP萬億大模型——混元(HunYuan)AI 大模型。
混元AI大模型采用騰訊太極機器學習平臺自研的訓練框架AngelPTM,相比業界主流的解決方案,太極AngelPTM單機可容納的模型可達55B,20個節點(A100-40Gx8)可容納萬億規模模型,節省45%訓練資源,并在此基礎上訓練速度提升1倍!
在模型層,混元大模型完整覆蓋 NLP 大模型、 CV 大模型、多模態大模型、文生圖大模型及眾多行業/領域/任務模型。其中,HunYuan-NLP 1T 的模型能力在自然語言理解任務榜單 CLUE 中登頂。
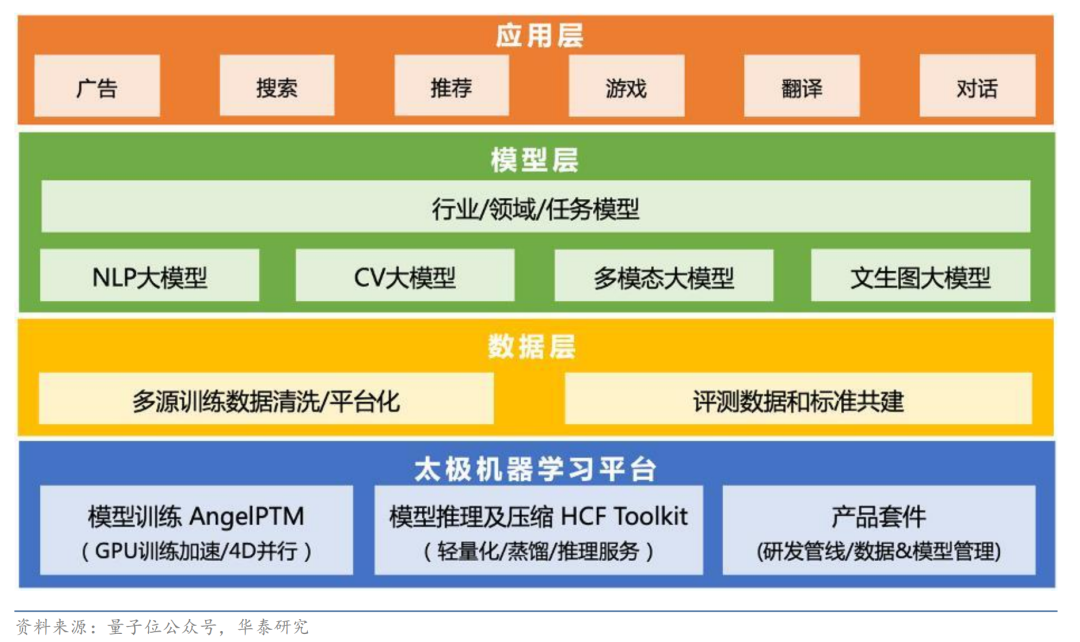
| 混元大模型全景圖
在產業化方面,混元先后支持了包括微信、QQ、游戲、騰訊廣告、騰訊云等眾多產品和業務,通過 NLP、CV、跨模態等 AI 大模型,不僅為業務創造了增量價值而且降低了使用成本。特別是其在廣告內容理解、行業特征挖掘、文案創意生成等方面的應用,在為騰訊廣告帶來大幅 GMV 提升的同時,也初步驗證了大模型的商業化潛力。
阿里:通義大模型
2022年9月,阿里達摩院發布通義大模型系列。該模型打造了AI統一底座,并構建了通用與專業模型協同的層次化人工智能體系,首次實現模態表示、任務表示、模型結構的統一。通義大模型整體架構分為三個層次:
模型底座層:多模態統一底座模型 M6-OFA,實現統一的學習范式和模塊化設計;
通用模型層:多模態模型“通義-M6”、NLP 模型“通義-AliceMind”以及 CV 模型“通義-視覺”;
行業模型層:深入電商、醫療、法律、金融、娛樂等行業。

通過部署超大模型的輕量化及專業模型版本,通義大模型已在超過 200 個場景中提供服務, 實現 2%~10%的應用效果提升。在搜索場景中,可實現以文搜圖的跨模態搜索。在 AI 輔助審判中,可實現司法卷宗的事件抽取、文書分類等任務效果 3~5%的提升。在人機對話領域,初步具備知識、記憶、情感以及個性的中文開放域對話大模型可實現主動對話、廣泛話題、緊跟熱點等對話體驗。此外,通義大模型在 AI 輔助設計、醫療文本理解等其他領域也有豐富的應用場景。
在近期的2023世界人工智能大會上,阿里宣布推出通義大模型家族新成員“通義萬相”。這是一款AI繪畫模型,支持文生圖等功能,它能夠通過機器學習和自然語言處理技術,從文本描述中生成對應的圖片或畫作。
華為:盤古大模型
2021年4月華為正式發布盤古系列大模型,包括NLP、CV和科學計算大模型,后續還發布了礦山、藥物分子、氣象、海浪等行業大模型。
其中,盤古NLP大模型首次使用Encoder-Decoder架構,兼顧NLP大模型的理解能力和生成能力,保證了模型在不同系統中的嵌入靈活性。在下游應用中,僅需少量樣本和可學習參數即可完成千億規模大模型的快速微調和下游適配。而盤古CV大模型則是首次實現模型按需抽取的業界最大CV大模型,兼顧判別與生成能力,能夠基于模型大小和運行速度需求,自適應抽取不同規模模型,AI應用開發快速落地。
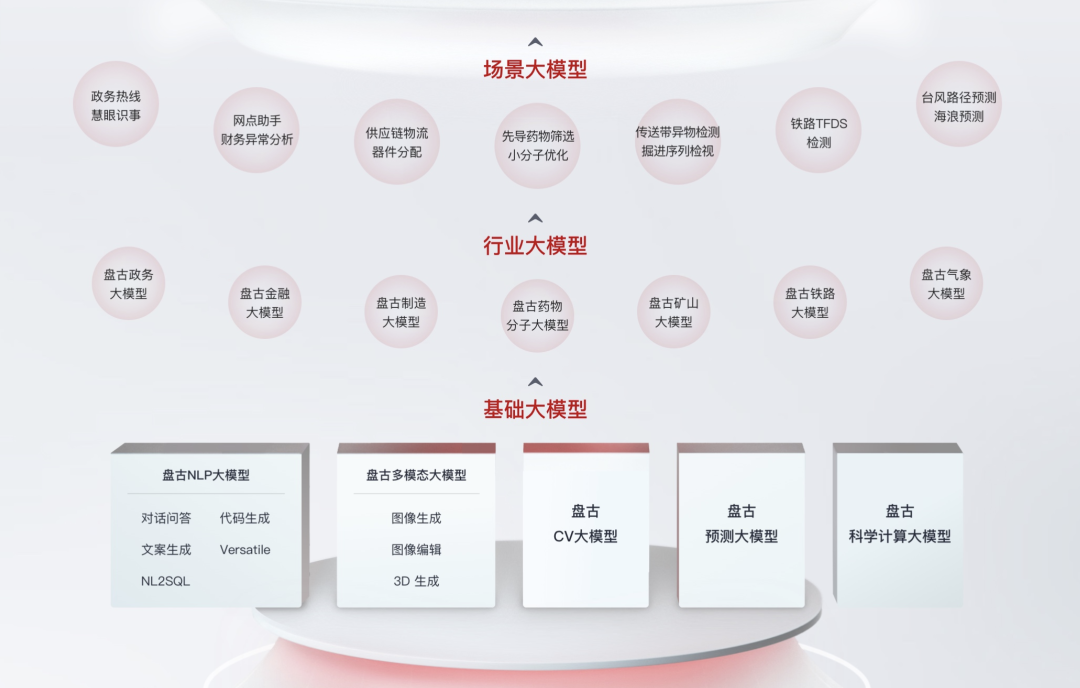
在7月7日的華為開發者大會2023上,盤古大模型3.0正式發布。盤古大模型 3.0 是一個完全面向行業的大模型系列,包括 5+N+X 三層架構:
L0 基礎大模型:包括自然語言大模型、視覺大模型、多模態大模型、預測大模型、科學計算大模型在內的5個基礎大模型。盤古 3.0 為客戶提供 100 億參數、380 億參數、710 參數和 1000 億參數的系列化基礎大模型,匹配客戶不同場景、不同時延、不同響應速度的行業多樣化需求。
L1 行業大模型:涵蓋N 個行業大模型,既可以提供使用行業公開數據訓練的行業通用大模型,包括政務,金融,制造,礦山,氣象等;也可以基于行業客戶的自有數據,在盤古的 L0 和 L1 上,為客戶訓練自己的專有大模型。
L2 場景模型:為客戶提供更多細化場景,它更加專注于某個具體的應用場景或特定業務,為客戶提供開箱即用的模型服務。
網易:玉言、子曰大模型
在2023世界人工智能大會上,網易多款AI大模型落地產品首次亮相,集中展示了在人工智能基礎設施層、引擎層、平臺層、模型層、應用層的領先創新成果。會上,由網易有道自研的首個教育大模型“子曰”最新應用成果——虛擬人口語教練首次亮相。
除了口語訓練外,據悉“子曰”大模型系列應用成果還包括中文作文指導與批改、英語習題精講等多種教育領域細分應用。“子曰”大模型能夠作為基座模型支持很多下游任務,為所有下游場景模型提供語義理解、知識表達等基礎能力,是有道AI產品體系的核心。有道研發團隊在子曰大模型的基礎上,會為不同場景設計定制化模型,以實現模型與場景的高度契合。
此前網易伏羲實驗室推出了中文預訓練大模型“玉言”。公開資料顯示,“玉言”大模型參數達到110億,由浪潮信息提供AI算力支持。“玉言”大模型相關技術已用于網易集團內的文字游戲、智能 NPC、文本輔助創作、音樂輔助創作、美術設計、互聯網搜索推薦等業務場景。
據了解,網易AI大模型正在加速覆蓋百余個產業應用場景,在加速創新應用的同時,網易伏羲有靈眾包平臺今年還將為10萬人提供AI新職業,包含挖掘機遠程駕駛員、AI繪畫師、AI表情綁定師等人機協作的就業崗位。平臺還會根據求職者的用戶畫像,提供針對性的培訓,幫助他們實現能力和收入的提升。
京東:言犀大模型
京東集團技術委員會主席、京東云事業部總裁曹鵬介紹,即將推出的言犀大規模預訓練語言模型將面向多模態,深入零售、物流、工業等產業場景。言犀是“京東版”ChatGPT,其預訓練參數達到千億級、品類覆蓋 3000+、人工審核通過率95%+、生成文字30億+。
據悉,新一代京東大模型定位于產業版本的ChatGPT。該模型的落地應用路線圖“125”計劃也已公布,包括一個平臺、兩個領域和五個應用。其中,一個平臺為ChatJD智能人機對話平臺,兩個領域為零售和金融,五個應用則包括內容生成、人機對話、用戶意圖理解、信息抽取和情感分類。
360:360智腦大模型
6月13日,360集團舉行360智腦大模型應用發布會,認知型通用大模型“360智腦4.0”亮相,360智腦在多模態等關鍵能力上完成迭代,將全面接入“360全家桶”,同時360AI數字人正式發布。
360集團創始人周鴻祎介紹,認知型通用大模型“360智腦4.0”具備生成與創作、多輪對話、代碼能力、邏輯與推理、知識問答、閱讀理解、文本分類、翻譯、文本改寫、多模態(文本生成圖像)十大核心能力。
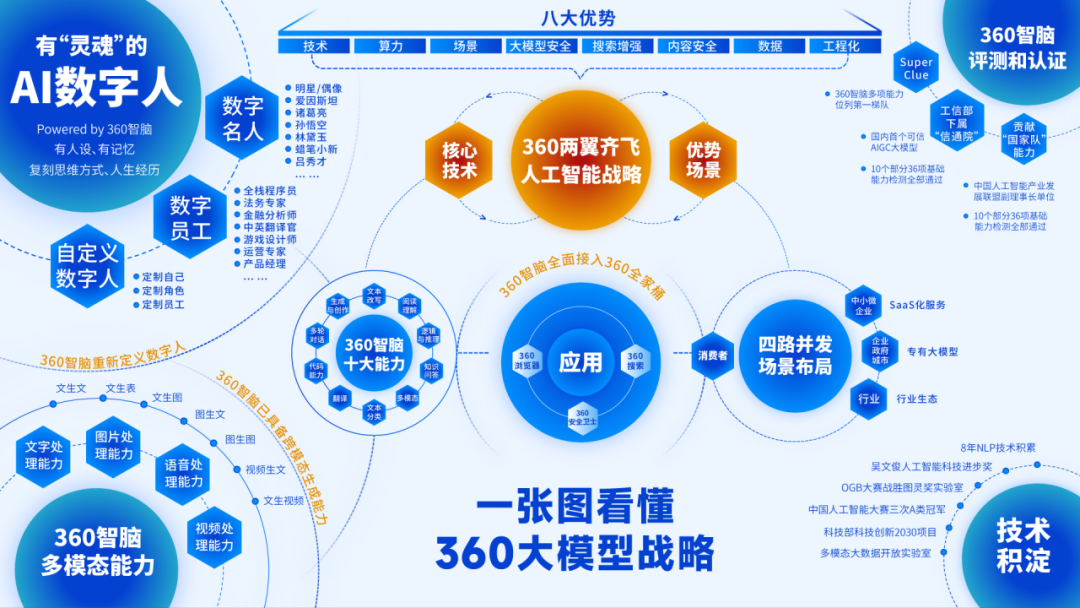
周鴻祎表示,今年3月底,360智腦大模型率先落地搜索場景。在隨后不到3個月時間內,360智腦完成從1.0版本到4.0版本的迭代。下一步,計劃將360智腦升級到5.0版本,并發布插件平臺。
浪潮:源大模型
源1.0是浪潮信息在2021年發布的人工智能巨量模型,單體模型參數量達到2457億。作為通用NLP預訓練模型,源1.0能夠適應多種類的AI任務需求,降低針對不同應用場景的語言模型適配難度,并提升小樣本學習與零樣本學習場景的模型泛化應用能力。

此后,浪潮信息發布了基于“源1.0”大模型生成的4個技能大模型(SkillModel),分別為對話模型“源曉問”、問答模型“源曉搜”、翻譯模型“源曉譯”、古文模型“源曉文”。這些技能大模型在各自細分領域的精度業界領先,可直接應用于人機交互、知識檢索、語言翻譯和文學創作等領域,模型運行速度最高提升9倍。更重要的是,基于大模型快速生成特定領域的技能大模型(Skill Model),也意味著“源”的AI生產力大幅升級,能夠幫助商業組織和研究機構實現對AI技術的高效、快速和低成本應用,加速產業AI化。
浪潮表示,公司在“源”大模型方面的工作在持續推進中。源2.0將會在文生圖、Chat、多模態、工具鏈等方面進行升級提升。
科大訊飛:星火認知大模型
在多年核心技術儲備下,科大訊飛于2022年12月15日啟動“1+N”認知智能大模型專項攻關,2023年5月6日訊飛星火認知大模型正式發布,涵蓋了文本生成、語言理解、知識問答、邏輯推理等七項核心能力,并持續迭代于6月9日再次升級發布星火認知大模型V1.5。

星火認知大模型最先應用于教育、辦公、汽車駕駛、數字員工等場景,升級產品智能化功能,極大程度改善了用戶體驗。
在教育領域,訊飛星火認知大模型+學習機(科大訊飛AI習機T20),可以AI寫作批改、精細批改、給優化參考,儼然成為學生的智能家庭教師。在辦公領域,訊飛星火大模型+辦公(訊飛聽見、訊飛智能辦公本X2),可以自動會議紀要、自動語篇規整、一鍵成稿,是職工的智能辦公助理。
在汽車駕駛領域,訊飛星火認知大模型+智能座艙,可以提供多輪、多人、多區域、多模態智能汽車人機交互范式,強化智能座艙的科技體驗感。在數字員工領域,訊飛星火大模型+數字員工,優化了數字員工語音和文本交互體驗……
近日,科大訊飛高級副總裁、認知智能全國重點實驗室主任胡國平公布了訊飛與華為的合作,表示訊飛星火將與昇騰AI強強聯合,全力打造我國通用智能新底座。“國產大模型只有基于中國自主創新的算力底座才有大未來。”
商湯:日日新大模型
4月,商湯科技董事長兼首席執行官徐立宣布推出“日日新SenseNova”大模型體系。這個體系包含自然語言處理、內容生成、自動化數據標注、自定義模型訓練等多種大模型及能力。

近日,“商湯日日新SenseNova”大模型體系多方位全面升級。作為千億級參數的自然語言處理模型,商湯商量SenseChat 2.0版本突破了大語言模型輸入長度的限制,并推出不同參數量級的模型版本,可完美適配移動端、云端等不同終端及場景的應用需求,降低部署成本。商湯的自研生成式大模型商湯秒畫SenseMirage 3.0的模型參數從今年4月首次發布以來的10億提升至70億量級,能夠實現專業攝影級的圖片細節刻畫。
商湯如影SenseAvatar 2.0數字人生成平臺相較1.0版本的語音和口型流暢度提升30%以上,實現4K高清視頻效果,并帶來AIGC生成形象及數字人歌唱功能。此外,商湯瓊宇SenseSpace 2.0的空間重建效率提升20%,渲染性能提升50%,每100平方公里場景的建圖時間僅需38小時即可完成(1200 TFLOPS/秒算力支持);而商湯格物SenseThings 2.0對小物體的紋理及材質還原達到毫米級精細度,并突破對高反光和鏡面物體的采集難題。
智譜AI:智譜AI系列大模型
2022年 11月,斯坦福大學大模型中心對全球 30 個主流大模型進行全方位評測,智譜 AI研發的雙語千億級超大規模預訓練模型 GLM-130B 是亞洲唯一入選的大模型,測評結果顯示,其準確性等關鍵指標與 OpenAI、谷歌大腦、微軟和英偉達等公司的大模型接近或持平,全球已有70個國家 1000 余家機構申請使用。
智譜AI語言大模型ChatGLM系列模型,通過注入代碼預訓練,有監督微調等技術對齊人類意圖,具備問答、多輪對話、代碼生成等能力;代碼大模型CodeGeeX模型,130億參數,支持20多種編程語言,具備代碼生成、續寫、翻譯等能力;多模態大模型CogView模型,基于Transformer架構的文本生成圖像模型,支持根據指令生成和編輯圖像。

ChatGLM 在GLM-130B 上通過有監督微調等技術實現人類意圖對齊,支持英偉達和華為異騰、海光及申威等***進行訓練和推理,開源的ChatGLM-6B 模型全球下載超過 160萬,持續兩周位列Huggingface 全球模型趨勢榜榜首。
據360官方消息,360 和智譜 AI 達成戰略合作,打造中國的“微軟+OpenAI”組合引領大模型技術攻關,共同研發的千億級大模型“360GLM”。
昆侖萬維:天工大模型
4月10日,昆侖萬維宣布聯合奇點智源共同研發了號稱“中國第一個真正實現智能涌現”的國產大語言模型——“天工”3.5。
天工作為一款大型語言模型,擁有強大的自然語言處理和智能交互能力,能夠實現智能問答、聊天互動、文本生成等多種應用場景,并且具有豐富的知識儲備,涵蓋科學、技術、文化、藝術、歷史等領域。

據悉,天工算力基于國內最大的GPU集群之一,其規模優勢使得天工可通過海量數據進行更充分的訓練,從而積累更強的理解能力和記憶力。其次,天工采用了雙千億模型——千億預訓練基座模型和千億RLHF模型,這使其具備了更高級的自主學習和智能涌現能力。此外,蒙特卡洛搜索樹算法使天工可以提供更加人性化的交互體驗。這些技術突破,使得天工在復雜任務和場景中能夠快速且準確地響應指令,輸出高質量回答。
中國移動:“九天”1+N大模型
2023 年7 月 8 日,中國移動正式發布 “ 九天 ” 人工智能大模型:九天?海算政務大模型和九天?客服大模型。目前,九天人工智能平臺的技術團隊擁有超過600名研發人員。
據了解,九天?海算政務大模型具備政務事項理解能力、多維度信息關聯能力、面向復雜事項和復雜流程的多元交互能力,首創 “ 政務大模型 — 信息場 — 應用 ” 端到端政務服務體系,可以滿足工作人員動態管理、公文寫作等需求。
九天?客服大模型可根據用戶提供的自然語言描述,解析問題并提供答案;還可與人工客服協作,分析歷史溝通內容的語義和上下文,總結和歸納對話的重點和關鍵信息,為人工客服提供回復建議。
中國電信:TeleChat大模型
7月6日,中國電信數字智能科技分公司正式對外發布中國電信大語言模型TeleChat,并展示了大模型賦能數據中臺、智能客服和智慧政務三個方向的產品。
中國電信依托云網融合的優勢,打造了中國電信的大語言模型TeleChat。TeleChat使用了大量高質量中英文語料進行預訓練,并采用了千萬級問答數據進行微調。同時,設計了漸進膨脹注意力機制,用于增加模型的間隔采樣,擴大實際感受野;研發了自校準微調技術,將迭代后相關性偏差作為強化學習的監督信號,提升強化學習效果;并且利用知識圖譜協同增強策略,通過知識圖譜增強大模型的預訓練和推理能力,減少大模型幻覺現象。
此外,以TeleChat為底座的教育版大模型TeleChat-E在全球大模型綜合性考試評測榜單C-Eval上排名第七,前幾名包括ChatGPT等知名大模型。TeleChat-E使用人工收集、標注、整理的高質量領域數據對TeleChat進行持續效果強化。同時,TeleChat-E對Transformer Decoder的損失函數進行改進,使之更加關注題目答案的生成,提高準確率。
當下,電信TeleChat大模型正在與千行百業的信息化解決方案進行融合,在諸多行業實現商業化落地。
中國聯通:鴻湖圖文大模型1.0
近日,在上海世界移動通信大會期間,中國聯通發布了一項重要的技術創新成果——鴻湖圖文大模型1.0。中國聯通稱,鴻湖圖文大模型是首個面向運營商增值業務的大模型。
據了解,鴻湖圖文大模型目前有兩個版本,分別是擁有8億訓練參數和20億訓練參數的版本。這意味著該大模型具備了強大的計算和學習能力,能夠實現多種復雜的圖文處理功能。
以文生圖是鴻湖圖文大模型的一項重要功能。通過該功能,用戶可以輸入文字描述,大模型能夠自動生成相應的圖像。這對于一些需要圖像輔助的場景,如廣告設計、創意表達等,具有重要的應用價值。
另外,鴻湖圖文大模型還具備視頻剪輯和以圖生圖的功能。視頻剪輯功能可以根據用戶提供的視頻素材,自動進行剪輯和編輯,生成符合用戶需求的視頻作品。而以圖生圖功能則可以根據用戶提供的圖像,生成新的圖像,為用戶提供更多的創作靈感。
中國科學院自動化研究所:紫東太初大模型
紫東太初是中國科學院自動化研究所研發的跨模態通用人工智能平臺 ,首次發布于 2021 年 7 月。紫東太初是圖文音(視覺-文本-語音)三模態預訓練模型(OPT-Omni-Perception pre-Trainer),同時具備跨模態理解與跨模態生成能力。
2023年6月16日,中國科學院自動化研究所發布紫東太初2.0。相比1.0版本,在語音、圖像和文本三模態的基礎上,加入視頻、傳感信號、3D點云等模態數據,研究突破了認知增強的多模態關聯等關鍵技術,具備全模態理解能力、生成能力和關聯能力,面向數字經濟時代加速通用人工智能的實現。
紫東太初 2.0以自動化所自研算法為核心,以昇騰AI硬件及昇思MindSpore AI框架為基礎,依托武漢人工智能計算中心算力支持,著力打造全棧國產化通用人工智能底座。長期以來,強大的算力支撐是約束我國人工智能發展的瓶頸之一,此舉將有力推動國產基礎軟硬件與大模型技術的適配,協同構建我國通用人工智能自主可控發展生態。
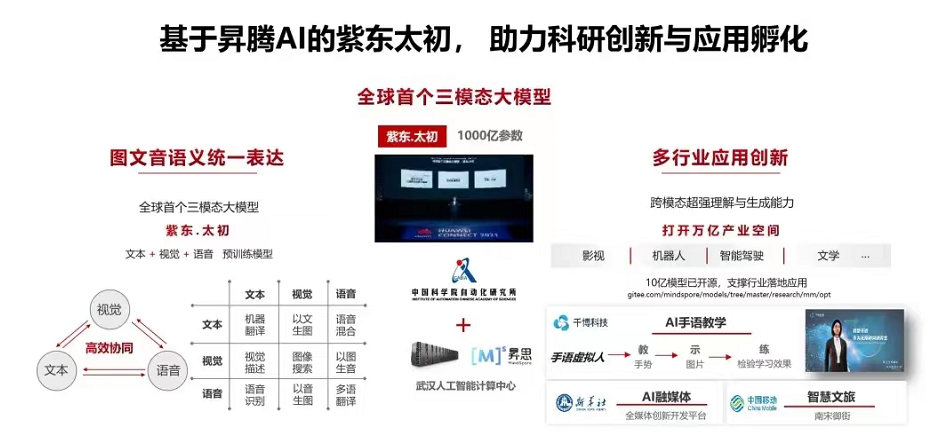
目前,“紫東太初”大模型已在神經外科手術導航、短視頻內容審核、法律咨詢、醫療多模態鑒別診斷、交通違規圖像研讀等領域開始了一系列應用。
智源研究院:悟道智能模型
智源研究院自 2020 年 10 月正式啟動超大規模智能模型悟道項目,2021 年3月2號就發布了超大規模的智能模型悟道1.0,取得了多項領域的領先突破。2021年6月1日,基于智能模型“悟道2.0”誕生的原創虛擬學生“華智冰”在北京正式亮相。
悟道2.0智能模型參數規模達到1.75萬億個,可以同時處理中英文和圖片數據。該模型還引入大規模的知識圖譜,構建了數據與知識雙輪驅動的人工智能框架,并通過這種框架分析、理解富含前沿技術信息的知識。
2023年 6 月的智源大會上,智源發布并全面開源“悟道3.0”系列模型。值得注意的是,智源的關注點不僅是模型本身,更包括模型背后的算力平臺建設、數據梳理、模型能力評測、算法測試、開源開放組織等體系化工作。
“悟道3.0 ”包括“悟道·天鷹”(Aquila)語言大模型系列、“悟道 · 視界”視覺大模型系列,以及一系列多模態模型成果。
國外戰場
OpenAI:GPT 系列大模型
2022 年11月,OpenAI發布了名為ChatGPT的人工智能模型并迅速引爆人工智能市場,推動國內公司進入生成式人工智能領域,導致市場競爭激烈。OpenAI GPT 系列大模型基于 Transformer 基礎模型,GPT(Generative Pre-trained Transformer)即生成式預訓練 Transformer模型,模型被設計為對輸入的單詞進行理解和響應并生成新單詞,預訓練代表著 GPT 通過填空方法來對文本進行訓練。
GPT-4 是 OpenAI 在深度學習擴展方面的最新里程碑。根據微軟發布的GPT-4 論文,GPT-4 已經可被視為一個通用人工智能的早期版本。GPT-4 是一個大型多模態模型(接受圖像和文本輸入 、輸出),雖然在許多現實場景中的能力不如人類,但在各種專業和學術基準測試中表現出人類水平的性能。GPT-4 不僅在文學、醫學、法律、數學、物理科學和程序設計等不同領域表現出高度熟練程度,而且它還能夠將多個領域的技能和概念統一起來,并能理解其復雜概念。

2023 年 6 月,OpenAI對外公布了一種新的AI模型訓練方法,旨在解決“AI幻覺”的問題。所謂“AI幻覺”,指的是聊天機器人用編造的信息進行回應,這是AI自信反應的一種表現。ChatGPT、谷歌 Bard都存在 AI 幻覺問題。OpenAI研究人員在報道中寫道:“即使是最先進的模型也很容易生成虛假信息——在不確定情況時,它們往往表現出捏造事實的傾向。這種幻覺在需要多步推理的領域尤其嚴重,其中一個環節上的邏輯錯誤就足以破壞整個解答過程。”
微軟:Orca大模型等
2019 年微軟首次注資 OpenAI后,雙方開始在微軟的 Azure 云計算服務上合作開發人工智能超級計算技術,同時 OpenAI 逐漸將云計算服務從谷歌云遷移到 Azure。2023 年 3月起,微軟開始全面集成GPT- 4,包括Office 全家桶、Windows、Bing 等等。
2022 年 8 月,微軟亞洲研究院聯合微軟圖靈團隊推出了最新升級的 BEiT-3 預訓練模型,在廣泛的視覺及視覺-語言任務上,包括目標檢測(COCO)、實例分割(COCO)、語義分割(ADE20K)、圖像分類(ImageNet)、視覺推理(NLVR2)、視覺問答(VQAv2)、圖片描述生成(COCO)和跨模態檢索(Flickr30K,COCO)等,實現了 SOTA 的遷移性能。
2023 年6 月,微軟 AI 推出 Orca,這是一個擁有 130 億個參數的AI模型,可以從 GPT-4 中學習復雜的解釋軌跡和逐步的思維過程。這種創新方法顯著提高了現有最先進的指令調整模型的性能,解決了與任務多樣性、查詢復雜性和數據擴展相關的挑戰。Orca 語言模型可以針對特定任務進行優化,并使用 GPT-4 等大型語言模型進行訓練。由于其尺寸較小,Orca 運行和操作所需的計算資源較少。研究人員可以根據自己的需求優化模型并獨立運行,無需依賴大型數據中心。
微軟正在利用大規模和多樣化的模仿數據來促進 Orca 的漸進式學習,Orca 在 Big-Bench Hard (BBH) 等復雜的零樣本推理基準測試中已經 100% 超過了 Vicuna。
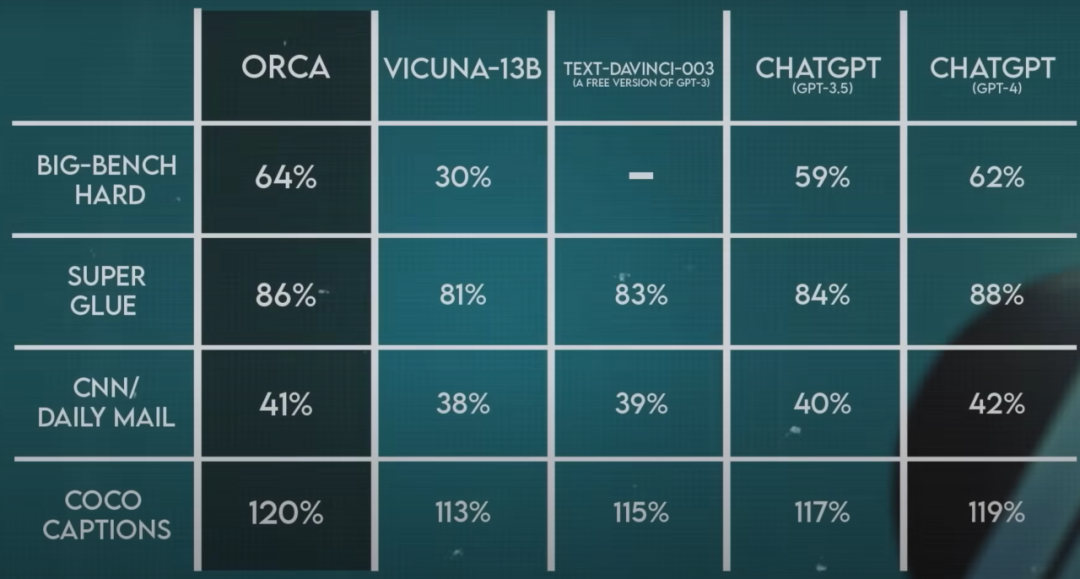
谷歌:PaLM 2 大模型、Gemini大模型等
谷歌最早在 2017 年提出 Transformer 網絡結構,成為了過去數年該領域大多數行業進展的基礎。隨后在 2018 年,谷歌提出的 BERT 模型,在 11 個 NLP 領域的任務上都刷新了以往的記錄。基于 Transformer 結構,谷歌于 2019 年推出大模型——T5(Text-toText Transfer Transformer)
在ChatGPT 取得突破性成功之后,谷歌宣布了自己的聊天機器人谷歌 Bard, 而 Bard 這個技術形象背后是 LaMDA 在提供后端支撐。LaMDA 是繼 BERT之后,谷歌于 2021 年推出的一款自然對話應用的語言模型。同年谷歌研發出 GLaM 模型架構,GLaM 也是混合專家模型(MoE),其在多個小樣本學習任務上取得有競爭力的性能。
2022 年,Google 發布了 Pathways AI 架構的大模型(Pathways Language Model),簡稱為 PaLM),2023 年5 月,谷歌在Google I/O 開發者大會上發布了升級款 PaLM 2 ,PaLM 2 同時提供了四種模型大小的版本分別是:壁虎(Gecko)、水獺(Otter)、野牛(Bison)和獨角獸(Unicorn)。據谷歌介紹,PaLM 2 具有改進的多語言能力,在訓練模型時加入了 100 多種語言的語料來,促使 PaLM 2 在理解、生成和翻譯細微差別的文本(如成語、詩歌和謎語)的能力上相比前代有著顯著提高。同時在推理方面,PaLM 2 的數據集在理解科學論文以及數學表達式等問題時也有著巨大提升。
6月28日消息,谷歌正準備推出全新的AI大模型Gemini。谷歌旗下DeepMind CEO戴密斯·哈薩比斯最近在采訪中進一步透露了Gemini的細節,Gemini會將AlphaGo與GPT-4等大模型的語言功能合并,目標是讓系統具有新的能力,如規劃或解決問題,比OpenAI的GPT-4能力更強。不過Gemini還在開發中, 這個過程預計需要幾個月的時間。
Meta:LLaMA語言模型、ImageBind 大模型等
繼微軟、谷歌之后,Facebook母公司Meta也加入AI軍備競賽。2023 年2月24日,Meta官網公布了一款新的人工智能大型語言模型LLaMA,從參數規模來看,Meta提供有70億、130億、330億和650億四種參數規模的LLaMA模型,并用20種語言進行訓練。
2023 年 5 月,Meta 發布 650億參數語言模型 LIMA,僅在 1000 個精心挑選的樣本上微調 LLaMa-65B 且無需 RLHF,就實現了與 GPT-4 和 Bard 相媲美的性能。此外,Meta還推出了大規模多語言語音項目 MMS(Massively Multilingual Speech)、可“任意圖像分割”的基礎模型SAM(Segment Anything Model)、DINOv2 視覺大模型。
同樣在 5 月,Meta開源 ImageBind 新模型,ImageBind大模型以視覺為核心,結合文本、聲音、深度、熱量(紅外輻射)、運動(慣性傳感器),最終可以做到6個模態之間任意的理解和轉換。ImageBind 可以使用文本、音頻和圖像的組合來搜索照片、視頻、音頻文件或文本消息。ImageBind 用于豐富的多媒體搜索、虛擬現實甚至機器人技術,可以和 Meta 內部的虛擬現實、混合現實和元宇宙等技術相結合。
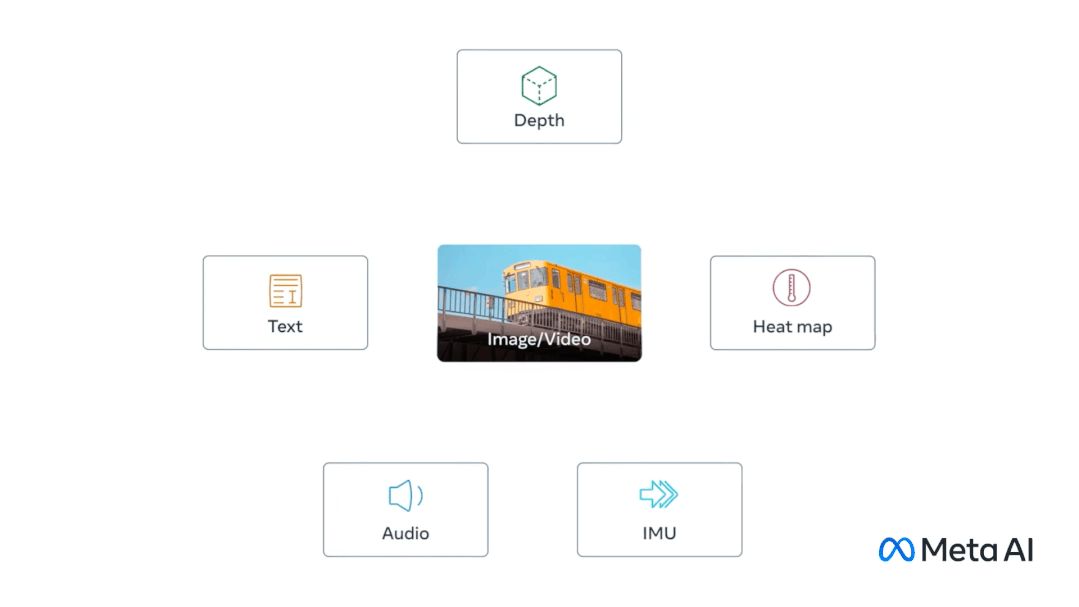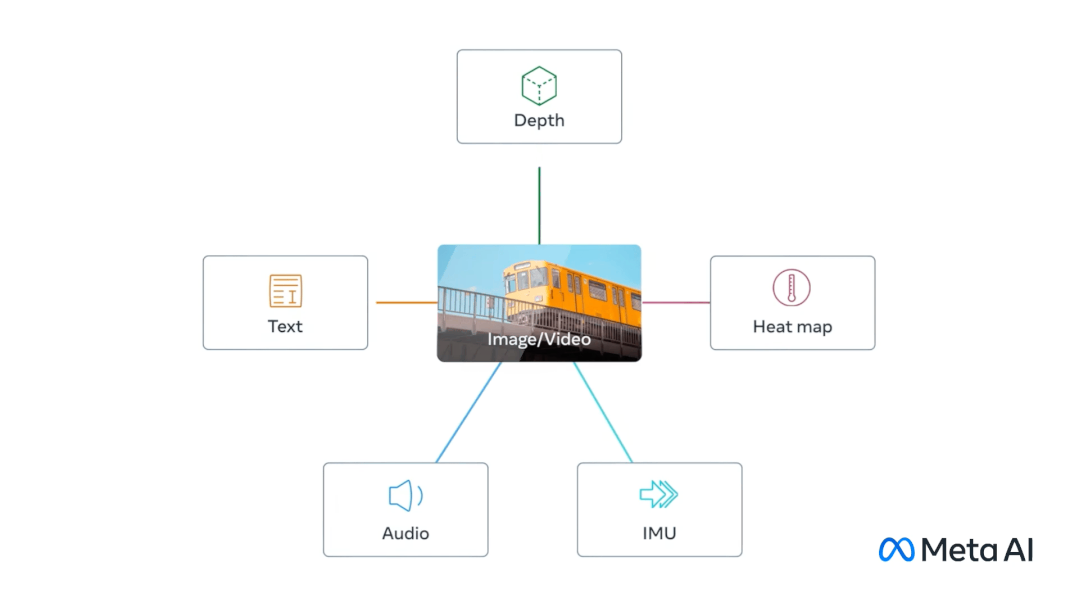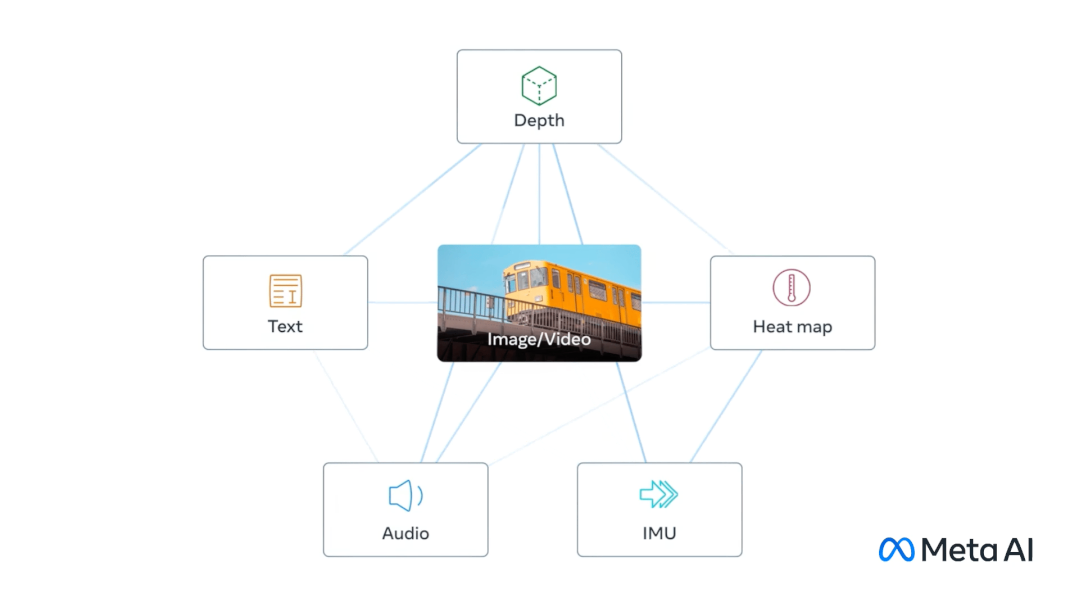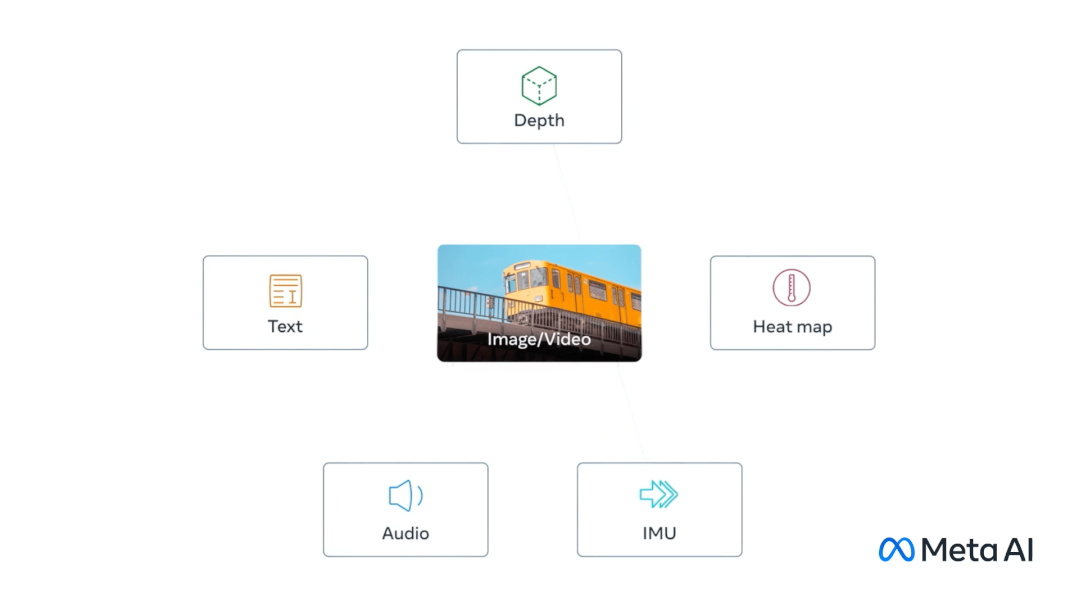
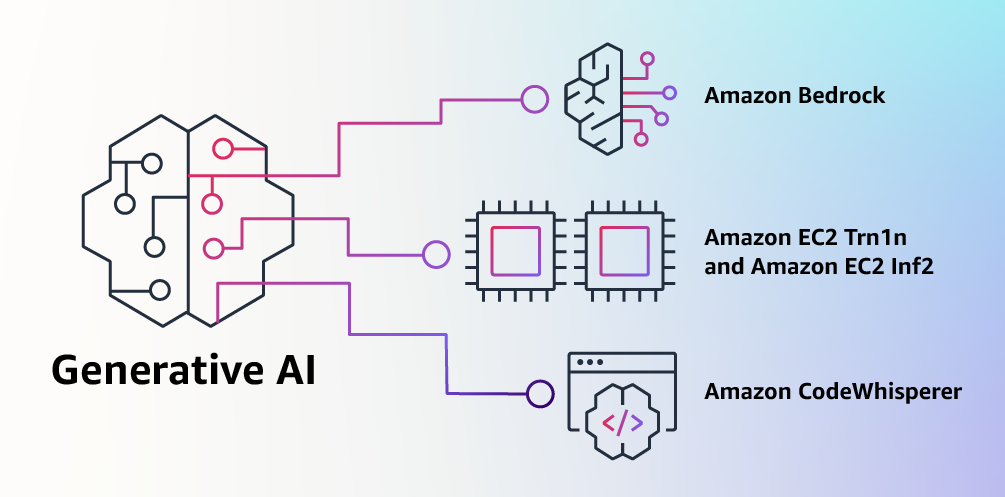
AWS:Titan語言大模型
2023 年 4 月,AWS 正式入局 AIGC,推出自有基礎模型 Titan 和 AIGC 服務 Bedrock,以及 AI 編程助手 Amazon CodeWhisperer,并宣布基于自研推理和訓練 AI 芯片的最新實例 Amazon EC2 Trn1n 和 Amazon EC2 Inf2 正式可用。
AWS 推出的自研語言大模型 Titan分為兩種,一種是針對總結、文本生成(如原創博客)、分類、開放式問答和信息提取等任務的生成式大語言模型。另一種是文本嵌入(embeddings)大語言模型,能夠將文本輸入(字詞、短語甚至是大篇幅文章)翻譯成包含語義的數字表達(即embeddings 嵌入編碼)。AWS表示,除了這兩個以外,未來還會有一系列模型都隸屬于Amazon Titan家族。
除了大模型,同時發的還有新的訓練和推理實例,一個面向開發者的AI編程工具Amazon CodeWhisperer,還有用于托管和開發生成式AI應用的Amazon Bedrock。四箭齊發,亞馬遜云科技搶占大模型市場機遇。
在大模型快速演進的關鍵時期,為方便技術交流,共促產業發展。
-
AI
+關注
關注
87文章
30896瀏覽量
269087 -
大數據
+關注
關注
64文章
8889瀏覽量
137442 -
大模型
+關注
關注
2文章
2450瀏覽量
2707 -
AI大模型
+關注
關注
0文章
316瀏覽量
310
原文標題:“百模大戰”:盤點國內外橫空出世的AI大模型
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
國產大模型發展的經驗與教訓

意法半導體ST Edge AI Suite人工智能開發套件上線
反制無人機的技術進展:國內外先進系統與技術概覽

百度文心大模型日處理Tokens文本已達2490億
當家居營銷遇上AI,2024家居行業AI營銷第一課(成都站)火熱報名中

“百模大戰”競爭格局報告發布,云天天書大模型入選典型案例

火了這么久的大模型,到底能為模組產業帶來什么?

針對高速光模塊應用,小華半導體推出HC32F472系列模擬豐富MCU新品

新火種AI|秒殺GPT-4,狙殺GPT-5,橫空出世的Claude 3振奮人心!

Sora出世 服務器產業鏈受益極大!
除了刷屏的Sora,國內外還有哪些AI視頻生成工具

賈揚清質疑Groq CEO“其芯片價格接近免費” 前員工:不切實際!
成都匯陽投資關于Sora 橫空出世,AI 產業鏈風云再起!






 工商網監
工商網監
評論