 AI大模型時代需要什么樣的網絡?
AI大模型時代需要什么樣的網絡?
ChatGPT 的爆火掀起了 AI 大模型狂飆熱潮,隨著國內外原來越多的 AI 大模型應用落地,AI 算力需求快速增加。在算力的背后,網絡起到至關重要的作用——網絡性能決定 GPU 集群算力,網絡可用性決定 GPU 集群算力穩定性。因此,高性能與高可用的網絡對 AI 大模型的構建尤為重要。
6 月 26 日,騰訊云舉辦《面向 AI 大模型的高性能網絡》溝通會,首次對外完整披露自研星脈高性能計算網絡,并梳理了騰訊的網絡架構演進歷程。會后,騰訊云副總裁王亞晨、騰訊云數據中心網絡總監李翔接受了 InfoQ 在內的媒體采訪,進一步分享面向 AI 大模型的高性能網絡是如何構建的。
據了解,星脈網絡具備業界最高的 3.2T 通信帶寬,可提升 40% 的 GPU 利用率、節省 30%~60% 的模型訓練成本,進而能為 AI 大模型帶來 10 倍通信性能提升。基于騰訊云新一代算力集群,可支持 10 萬卡的超大計算規模。
王亞晨表示:“星脈網絡是為大模型而生。它所提供的大帶寬、高利用率以及零丟包的高性能網絡服務,將助力算力瓶頸的突破,進一步釋放 AI 潛能,全面提升企業大模型的訓練效率,在云上加速大模型技術的迭代升級和落地應用。”
AI 大模型時代需要什么樣的網絡? 大帶寬、高利用率、無損
AI 大模型訓練需要海量算力的支撐,而這些算力無法由單臺服務器提供,需要由大量的服務器作為節點,通過高速網絡組成集群,服務器之間互聯互通,相互協作完成任務。有數據顯示,GPT-3.5 的訓練使用了微軟專門建設的 AI 計算系統,由 1 萬個 V100 GPU 組成的高性能網絡集群,總算力消耗約 3640 PF-days (假如每秒計算一千萬億次,需要計算 3640 天)。
如此大規模、長時間的 GPU 集群訓練任務,僅僅是單次計算迭代內梯度同步需要的通信量就達到了百 GB 量級,此外還有各種并行模式、加速框架引入的通信需求。如果網絡的帶寬不夠大、延時長,不僅會讓算力邊際遞減,還增加了大模型訓練的時間成本。因此,大帶寬、高利用率、無損的高性能網絡至關重要。
王亞晨表示,大模型運算實際上是一個通信過程,一部分 GPU 進行運算,運算完成后還需要與其他 GPU 之間交互數據。通信帶寬越大,數據傳輸越快,GPU 利用率越高,等待時間就會越少。此外,大模型訓練對時延和丟包要求也比較高。“假設有很多 GPU 運算同一個任務,因為有木桶效應存在,一定要等花費時間最長的 GPU 運算完之后,才能完成一個運算任務。AI 對于時延的敏感度比 CPU 高很多,所以一定要把木桶效應消除,把時延控制在非常短的水平,讓 GPU 的效率更高。此外,和帶寬、時延相比,丟包對 GPU 效率的影響更加明顯,一旦丟包就需要重傳,重新進行 GPU 的訓練。”
王亞晨認為,大集群不等于大算力。集群訓練會引入額外的通信開銷,導致 N 個 GPU 算力達不到單個 GPU 算力的 N 倍。這也意味著,一味地增加 GPU 卡或計算節點,并不能線性地提升算力收益。“GPU 利用率的合理水平大概是在 60% 左右。”王亞晨說道。
要想通過集群發揮出更強的算力,計算節點需協同工作并共享計算結果,需要優化服務器之間的通信、拓撲、模型并行、流水并行等底層問題。高速、低延遲的網絡連接可以縮短兩個節點之間同步梯度信息的時間,使得整個訓練過程變得更快。同時,降低不必要的計算資源消耗,使計算節點能夠專注于運行訓練任務。
AI 大模型驅動 DCN 網絡代際演進
據介紹,騰訊網絡主要提供的功能是“連接”,一是連接用戶到機器的流量,二是連接機器到機器的流量。目前,騰訊的網絡架構主要分三大部分:
ECN 架構,表示不同類型的客戶通過多種網絡方式接入云上虛擬網絡,這一塊主要是外聯架構,主要包括終端用戶、企業用戶、物聯網用戶分別通過運營商專線、企業專線、邊緣網關接入騰訊數據中心。
DCI 網絡,主要是數據中心之間的互聯,實現一個城市多數據中心或者多個城市的數據中心進行互聯,底層會用到光纖傳輸。
DCN,主要是數據中心的網絡,這部分的任務是實現數據中心里面超過 10 萬或者幾十萬服務器進行無阻塞的連接。
騰訊通過 ECN、DCI、DCN 等網絡,把用戶和業務服務器連接起來,并且把數百萬臺服務器連接起來。
王亞晨表示,AI 大模型的發展驅動了 DCN 網絡代際演進。
在移動互聯網時代,騰訊的業務以 to C 為主,數據中心網絡服務器規模并不大,當時主要解決的是數據中心、服務器之間的互聯,以及運營商之間的互聯。所以那時數據中心流量特征很明顯,基本都是外部訪問的流量,對網絡的時延和丟包要求也不高。
隨著移動互聯網以及云的快速發展,數據中心網絡流量模型發生了變化,除了有從運營商訪問過來的南北向流量,也有數據中心之間互訪的東西向流量,對網絡的時延要求也是從前的 10 倍。為了降低設備故障對網絡的影響,騰訊采用多平面設計,并引入了控制器的概念,把轉發面和控制面進行分離。用定制的設備、多平面以及 SDN 的路由器控制,將故障的解決時間控制在一分鐘之內。
在 AI 大模型時代,數據中心網絡流量模型進一步發生變化。“到了 AI 大模型時代,我們發現東西向流量比以前大了很多,尤其是 AI 在訓練的時候,幾乎沒有什么南北向流量。我們預計如果大模型逐漸成熟,明年大模型數據中心流量南北向流量可能會有所增長,因為推理需求會上來。但就現在而言,東西向流量需求非常大,我們 DCN 網絡設計會把南北向流量和東西向流量分開,以前是耦合在一張網絡里,基礎網絡都是一套交換機,只是分不同層。但到了 GPU 時代,我們需要專門為 GPU 構建一層高性能網絡。”王亞晨說道。
基于此,騰訊打造出了高性能網絡星脈:具備業界最高的 3.2T 通信帶寬,能提升 40% 的 GPU 利用率,節省 30%~60% 的模型訓練成本,為 AI 大模型帶來 10 倍通信性能提升。基于騰訊云新一代算力集群 HCC,可支持 10 萬卡的超大計算規模。
高性能網絡星脈是如何設計的?
據李翔介紹,騰訊網絡大概由大大小小幾十個組件組成,數據中心網絡是其中最大、歷史最悠久的一個。在 PC 和移動互聯網時代,數據中心網絡主要解決的是規模問題。而進入算力時代,業務對算力網絡有了更高的要求。
“舉個例子,如果說過去兩個階段數據中心網絡是‘村村通’,解決大規模部署和廣覆蓋的問題,那么在算力時代,數據中心網絡就是全自動化、無擁塞的高速公路。”李翔表示,AI 大模型對互聯有比較高的要求,幾千張 GPU 協同計算,如果出現任何一個丟包阻塞,那么全部都要降速,這種降速 1 分鐘就有幾十萬的損失。
基于此,騰訊云開始搭建算力集群。4 月 14 日,騰訊云正式發布面向大模型訓練的新一代 HCC(High-Performance Computing Cluster)高性能計算集群。網絡層面,計算節點間存在海量的數據交互需求,隨著集群規模擴大,通信性能會直接影響訓練效率。騰訊自研的星脈網絡,為新一代集群帶來了業界最高的 3.2T 的超高通信帶寬。
據介紹,騰訊對大模型集群網絡做了以下幾大優化:
(1)采用高性能 RDMA 網絡
RDMA(GPU 之間直接通信),是一種高性能、低延遲的網絡通信技術,主要用于數據中心高性能計算,允許計算節點之間直接通過 GPU 進行數據傳輸,無需操作系統內核和 CPU 的參與。這種數據傳輸方法可以顯著提高吞吐量并降低延遲,從而使計算節點之間的通信更加高效。
過往的數據中心 VPC 網絡,在源服務器與目標服務器之間傳輸時,需要經過多層協議棧的處理,過往數據每一層都會產生延遲,而騰訊自研的星脈 RDMA 網絡,可以讓 GPU 之間直接進行數據通信。
打個比方,就像之前貨物在運輸途中需要多次分揀和打包,現在通過高速傳送帶、不經過中間環節,貨物直接送到目的地
同時,由于星脈 RDMA 直接在 GPU 中傳輸數據,CPU 資源得以節省,從而提高計算節點的整體性能和效率。
(2)自研網絡協議(TiTa)
在網絡協議上,騰訊云通過自研 TiTa 協議,讓數據交換不擁塞、時延低,使星脈網絡可以實現 90% 負載 0 丟包。
網絡協議是在計算節點之間傳輸數據的規則和標準,主要關注數據傳輸的控制方式,能改善網絡連接性能、通信效率和延遲問題。
為了滿足大型模型訓練中的超低時延、無損和超大帶寬要求,傳統的網絡協議由于其固有的設計與性能限制,無法滿足這些需求,還需要對“交通規則”進行優化。
星脈網絡采用的自研端網協同協議 TiTa,可提供更高的網絡通信性能,特別是在滿足大規模參數模型訓練的需求方面。TiTa 協議內嵌擁塞控制算法,以實時監控網絡狀態并進行通信優化,使得數據傳輸更加流暢且延遲降低。
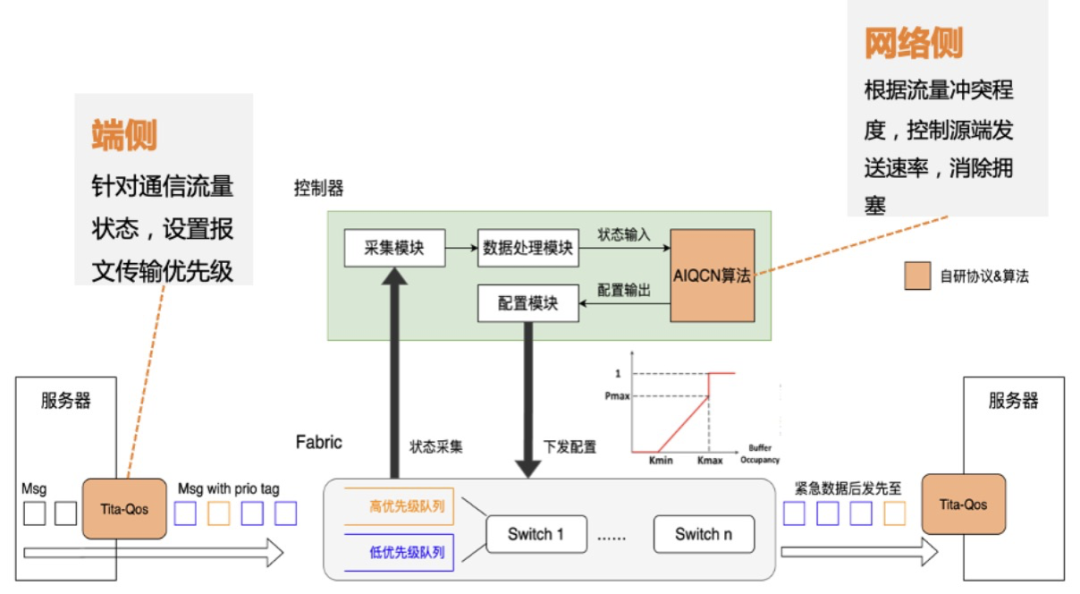
(3)定制化高性能集合通信庫 TCCL
通信庫在訓練過程中負責管理計算節點間的數據通信。面對定制設計的高性能組網架構,業界開源的 GPU 集合通信庫(比如 NCCL)并不能將網絡的通信性能發揮到極致,從而影響大模型訓練的集群效率。
為解決星脈網絡的適配問題,騰訊云還為星脈定制了高性能集合通信庫 TCCL(Tencent Collective Communication Library),相對業界開源集合通信庫,可以提升 40% 左右的通信性能。
并在網卡設備管理、全局網絡路由、拓撲感知親和性調度、網絡故障自動告警等方面融入了定制設計的解決方案。
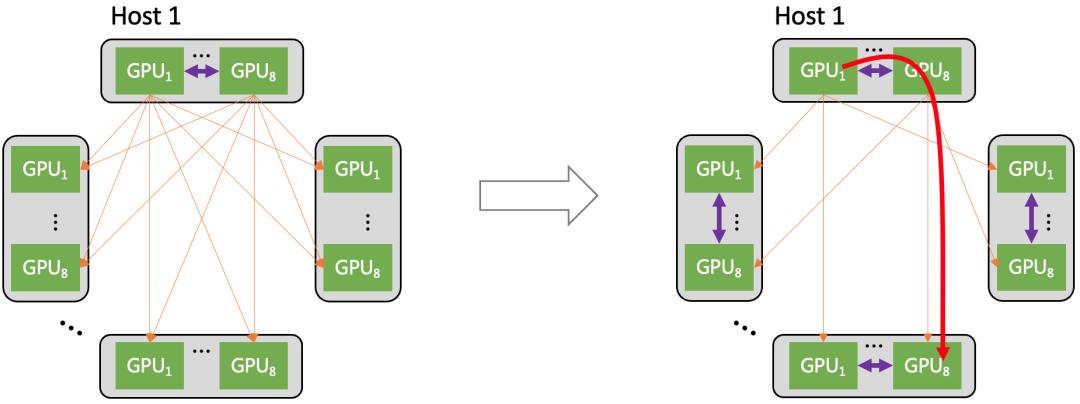
(4)多軌道網絡架構
星脈網絡對通信流量做了基于多軌道的流量親和性規劃,使得集群通信效率達 80% 以上。
多軌道流量聚合架構將不同服務器上位于相同位置的網卡,都歸屬于同一 ToR switch;不同位置的網卡,歸屬于不同的 ToR switch。由于每個服務器有 8 張計算平面網卡,這樣整個計算網絡平面從物理上劃分為 8 個獨立并行的軌道平面。
在多軌道網絡架構中,AI 訓練產生的通信需求(AllReduce、All-to-All 等)可以用多個軌道并行傳輸加速,并且大部分流量都聚合在軌道內傳輸(只經過一級 ToR switch),小部分流量才會跨軌道傳輸(需要經過二級 switch),大幅減輕了大規模下的網絡通信壓力。
(5)異構網絡自適應通信
大規模 AI 訓練集群架構中,GPU 之間的通信實際上由多種形式的網絡來承載的:機間網絡(網卡 + 交換機)與機內網絡(NVLink/NVSwitch 網絡、PCIe 總線網絡)。
星脈網絡將機間、機內兩種網絡同時利用起來,達成異構網絡之間的聯合通信優化,使大規模 All-to-All 通信在業務典型 message size 下的傳輸性能提升達 30%。
(6)自研全棧網絡運營系統
為確保星脈網絡的高可用性,騰訊云還自研了端到端全棧網絡運營系統,先是實現了端網部署一體化以及一鍵故障定位,提升高性能網絡的易用性,進而通過精細化監控與自愈手段,提升可用性,為極致性能的星脈網絡提供全方位運營保障。
具體應用成效方面,大模型訓練系統的整體部署時間可以從 19 天縮減至 4.5 天,保證基礎配置 100% 準確,并讓系統故障的排查時間由天級降低至每分鐘級,故障的自愈時間縮短到秒級。
寫在最后
AI 大模型時代給網絡帶來了新的機遇與挑戰。隨著 GPU 算力的持續提升,GPU 集群網絡架構也需要不斷迭代升級。
王亞晨表示,未來,星脈網絡將圍繞算力網卡、高效轉發、在網計算、高速互聯四大方向持續迭代。“這四個迭代方向也與我們面臨的痛點相關,目前我們重點發力算力網卡和高效轉發這兩大方向。其中,算力網卡需要與交換機做配合,實現更優的、類似主動預測控制的機制,讓網絡更不容易擁塞;高效轉發方面,之后可能會變成定長包的轉發機制,這樣也能保證整體效率。”
-
gpu
+關注
關注
28文章
4768瀏覽量
129214 -
服務器
+關注
關注
12文章
9295瀏覽量
85856 -
大模型
+關注
關注
2文章
2538瀏覽量
3010 -
AI大模型
+關注
關注
0文章
320瀏覽量
337
原文標題:AI 大模型狂飆的背后:高性能計算網絡是如何“織”成的?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
訓練AI大模型需要什么樣的gpu
智算中心網絡交換機需要什么樣的緩存架構

名單公布!【書籍評測活動NO.49】大模型啟示錄:一本AI應用百科全書
AI大模型與深度學習的關系
ai模型訓練需要什么配置
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
AI智能眼鏡都需要什么芯片

ai開發需要什么配置

生成式 AI 進入模型驅動時代

解鎖AI時代的利器——訊飛AI鼠標AM30助你在AI時代脫穎







 工商網監
工商網監
評論