 ChatGPT深度報告合集:奇點臨近,未來已來
ChatGPT深度報告合集:奇點臨近,未來已來
ChatGPT深度報告合集:奇點臨近,未來已來
一直以來,大家都對 GPT-4 的模型架構、基礎設施、訓練數據集、成本等信息非常好奇。
奈何 OpenAI 嘴太嚴,很長時間以來,大家也都只是猜測這些數據。
不久之前,「天才黑客」喬治?霍茲(George Hotz)在接受一家名為 Latent Space 的 AI技術播客采訪時透露出一個小道消息,稱 GPT-4 是由 8 個混合專家模型組成的集成系統,每個專家模型都有 2200 億個參數(比 GPT-3 的 1750 億參數量略多一些),并且這些模型經過了針對不同數據和任務分布的訓練。
雖然此消息無法驗證,但其流傳度非常高,也被部分業內人士認為非常合理。
最近,更多的消息似乎被泄露了出來。
今日,SemiAnalysis 發布了一篇付費訂閱的內容,「揭秘」了有關 GPT-4 的更多信息。

文章稱,他們從許多來源收集了大量有關 GPT-4 的信息,包括模型架構、訓練基礎設施、推理基礎設施、參數量、訓練數據集組成、token 量、層數、并行策略、多模態視覺適應、不同工程權衡背后的思維過程、獨特的實現技術以及如何減輕與巨型模型推理有關的瓶頸等。
作者表示,GPT-4 最有趣的方面是理解 OpenAI 為什么做出某些架構決策。
此外,文章還介紹了 A100 上 GPT-4 的訓練和推理成本,以及如何拓展到下一代模型架構 H100 。
我們根據 Deep Trading(一家算法交易公司)創始人 Yam Peleg 的推文(目前已刪除),整理了以下關于 GPT-4 的數據信息。感興趣的讀者可以細致研究下。

不過請注意,這并非官方確認的數據,大家自行判斷其準確性。
1、參數量:GPT-4 的大小是 GPT-3 的 10 倍以上。文章認為它 120 層網絡中總共有 1.8 萬億個參數。
2、確實是混合專家模型。OpenAI 能夠通過使用混合專家(MoE)模型來保持合理成本。他們在模型中使用了 16 個專家模型,每個專家模型大約有 111B 個參數。這些專家模型中的 2 個被路由到每個前向傳遞。
3、MoE 路由:盡管文獻中對于選擇將每個 token 路由到哪個專家模型的高級路由算法進行了大量討論,但據稱 OpenAI 在當前的 GPT-4 模型中采用了相當簡單的路由方式。該模型大約使用了 550 億個共享參數來進行注意力計算。
4、推理:每次前向傳遞的推理(生成 1 個 token)僅利用約 2800 億個參數和約 560 TFLOP 的計算量。相比之下,純密集模型每次前向傳遞需要大約 1.8 萬億個參數和約 3700 TFLOP 的計算量。
5、數據集:GPT-4 的訓練數據集包含約 13 萬億個 token。這些 token 是重復計算之后的結果,多個 epoch 中的 token 都計算在內。
Epoch 數量:針對基于文本的數據進行了 2 個 epoch 的訓練,而針對基于代碼的數據進行了 4 個 epoch 的訓練。此外,還有來自 ScaleAI 和內部的數百萬行的指令微調數據。
6、GPT-4 32K:在預訓練階段,GPT-4 使用了 8k 的上下文長度(seqlen)。而 32k 序列長度版本的 GPT-4 是在預訓練后對 8k 版本進行微調而得到的。
7、Batch Size:在計算集群上,幾天時間里,batch size 逐漸增加,最后,OpenAI 使用 batch size 達到了 6000 萬!當然,由于不是每個專家模型都能看到所有 token,因此這僅僅是每個專家模型處理 750 萬個 token 的 batch size。
真實的 batch size:將這個數字除以序列長度(seq len)即可得到真實的 batch size。請不要再使用這種誤導性的數字了。
8、并行策略:為了在所有 A100 GPU 上進行并行計算,他們采用了 8 路張量并行,因為這是 NVLink 的極限。除此之外,他們還采用了 15 路流水線并行。(很可能使用了 ZeRo Stage 1,也可能使用了塊級的 FSDP)。
9、訓練成本:OpenAI 在 GPT-4 的訓練中使用了大約 2.15e25 的 FLOPS,使用了約 25,000 個 A100 GPU,訓練了 90 到 100 天,利用率(MFU)約為 32% 至 36%。這種極低的利用率部分是由于大量的故障導致需要重新啟動檢查點。
如果他們在云端的每個 A100 GPU 的成本大約為每小時 1 美元,那么僅此次訓練的成本將達到約 6300 萬美元。(而如今,如果使用約 8192 個 H100 GPU 進行預訓練,用時將降到 55 天左右,成本為 2150 萬美元,每個 H100 GPU 的計費標準為每小時 2 美元。)
10、使用專家混合模型時的 tradeoff:在使用專家混合模型時存在多方面 tradeoff。
例如,在推理過程中處理 MoE 非常困難,因為并非模型的每個部分都在每個 token 生成時被利用。這意味著在某些部分被使用時,其他部分可能處于閑置狀態。在為用戶提供服務時,這會嚴重影響資源利用率。研究人員已經證明使用 64 到 128 個專家比使用 16 個專家能夠實現更好的損失(loss),但這僅僅是研究的結果。
選擇較少的專家模型有多個原因。OpenAI 選擇 16 個專家模型的一大原因是:在許多任務中,更多的專家模型很難泛化,也可能更難收斂。
由于進行了如此大規模的訓練,OpenAI 選擇在專家模型數量上更加保守。
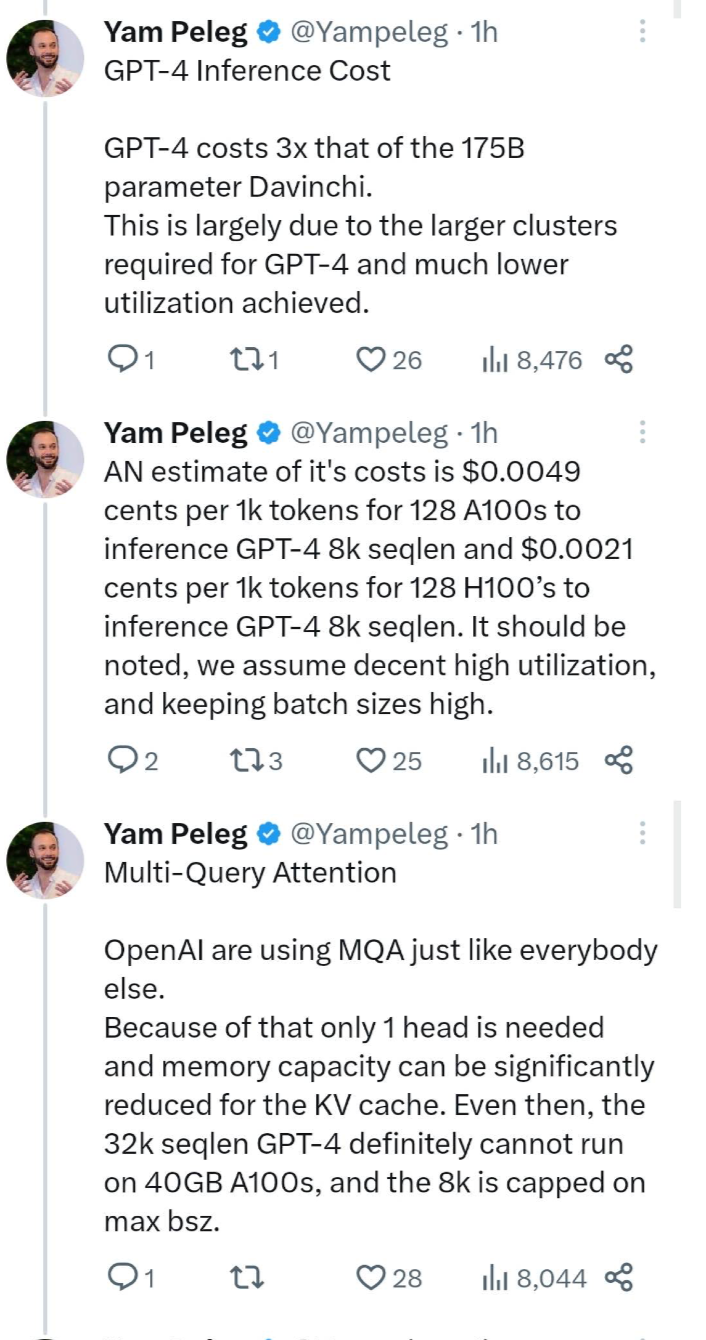
11、推理成本:GPT-4 的推理成本是 1750 億參數的 Davinci 模型的 3 倍。這主要是因為 GPT-4 需要更大規模的集群,并且達到的利用率要低得多。
據估計,在用 128 個 A100 GPU 進行推理的情況下,8k 版本 GPT-4 推理的成本為每 1,000 個 token 0.0049 美分。如果使用 128 個 H100 GPU 進行推理,同樣的 8k 版本 GPT-4 推理成本為每 1,000 個 token 0.0021 美分。值得注意的是,這些估計假設了高利用率和保持較高的 batch size。
12、Multi-Query Attention:OpenAI 和其他機構一樣,也在使用 Multi-Query Attention(MQA)。由于使用 MQA 只需要一個注意力頭(head),并且可以顯著減少用于 KV 緩存的內存容量。即便如此,32k 序列長度的 GPT-4 也絕對無法在 40GB 的 A100 GPU 上運行,而 8k 序列長度的模型則受到了最大 batch size 的限制。
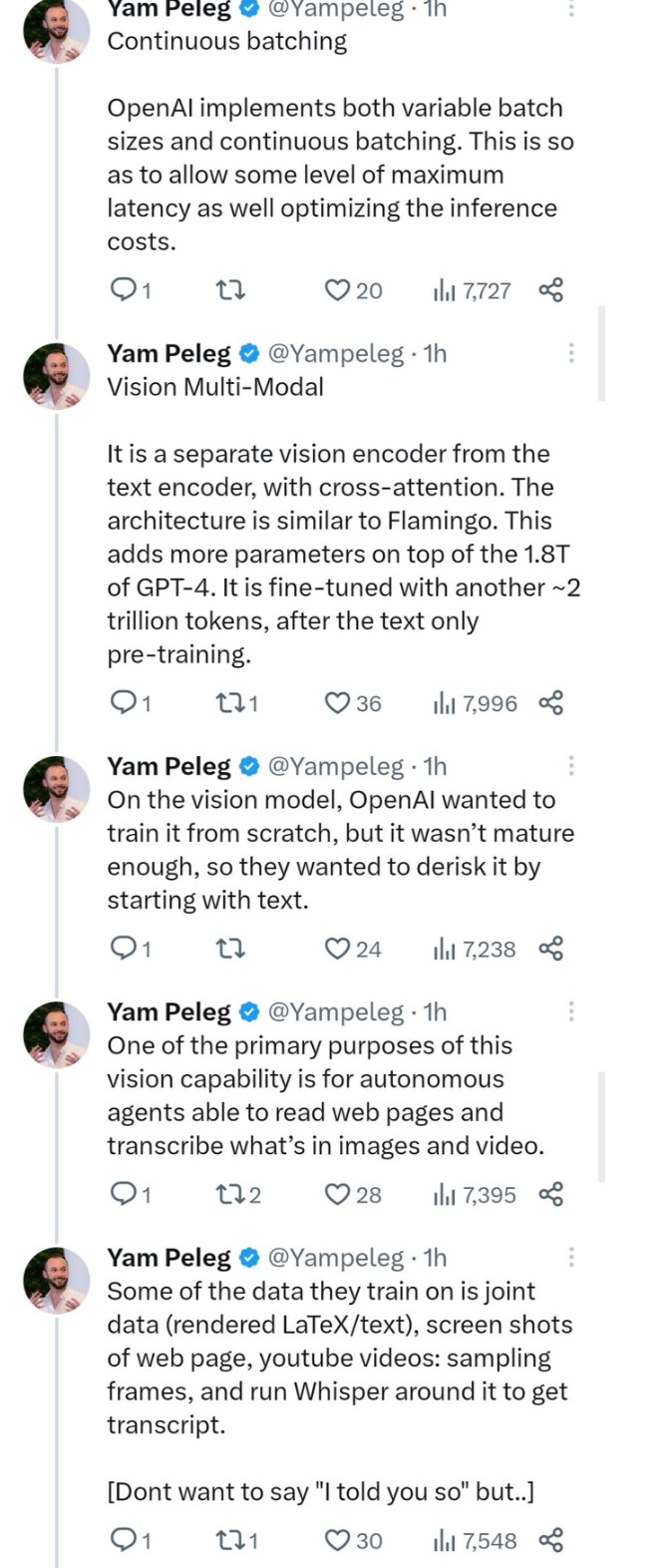
13、連續 batching:OpenAI 實現了可變 batch size 和連續 batching。這樣做是為了允許一定程度的最大延遲,并優化推理成本。
14、視覺多模態:它是一個獨立于文本編碼器的視覺編碼器,二者之間存在交叉注意力。該架構類似于 Flamingo。這在 GPT-4 的 1.8 萬億個參數之上增加了更多參數。在純文本的預訓練之后,它又經過了另外約 2 萬億個 token 的微調。
對于視覺模型,OpenAI 本來希望從零開始訓練,但由于其尚未成熟,所以他們決定先從文本開始訓練來降低風險。
這種視覺能力的主要目的之一是使自主智能體能夠閱讀網頁并轉錄圖像和視頻中的內容。
他們訓練的一部分數據是聯合數據(包括渲染的 LaTeX / 文本)、網頁的截屏、YouTube 視頻(采樣幀),并使用 Whisper 對其進行運行以獲取轉錄文本。

15、推測式解碼(Speculative Decoding):OpenAI 可能在 GPT-4 的推理過程中使用了推測式解碼技術(不確定是否 100%)。這種方法是使用一個更小更快的模型提前解碼多個 token,并將它們作為單個 batch 輸入到一個大型的預測模型(oracle model)中。
如果小型模型對其預測是正確的,大型模型將會同意,我們可以在單個 batch 中解碼多個 token。
但是,如果大型模型拒絕了草稿模型預測的 token,那么 batch 中剩余的部分將被丟棄,然后我們將繼續使用大型模型進行解碼。
有些陰謀論指出,新的 GPT-4 質量已經下降,這可能只是因為他們讓推測式解碼模型(speculative decoding model)將概率較低的序列傳遞給預測模型,從而導致了這種誤解。
16、推理架構:推理運行在由 128 個 GPU 組成的集群上。在不同地點的多個數據中心存在多個這樣的集群。推理過程采用 8 路張量并行(tensor parallelism)和 16 路流水線并行(pipeline parallelism)。每個由 8 個 GPU 組成的節點僅具有約 1300 億個參數。
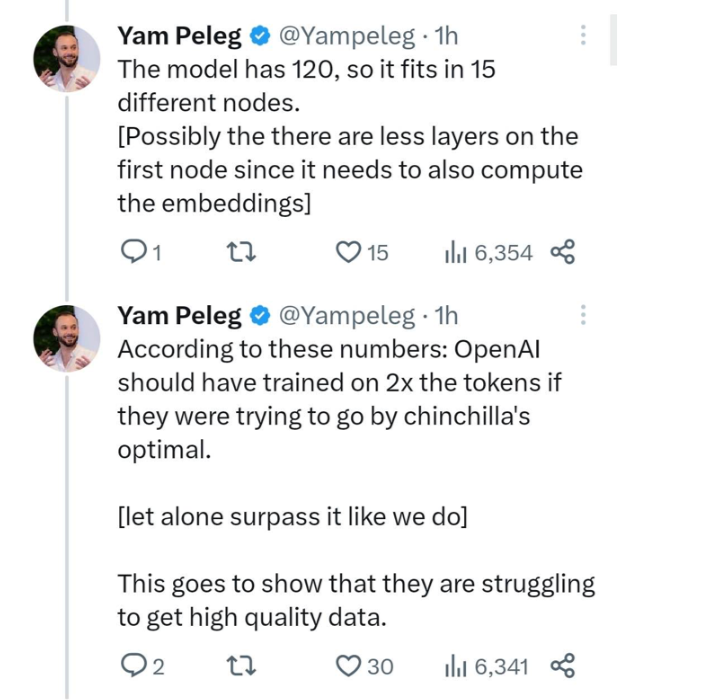
該模型有 120 層,因此適合于 15 個不同的節點。可能第一個節點的層數較少,因為它還需要計算嵌入。
根據這些數字,如果 OpenAI 試圖按照 chinchilla 的最佳指標進行訓練,他們應該使用的 token 數量是現在的兩倍。這表明他們在獲取高質量數據方面遇到了困難。
最后想說的是,這應該是迄今為止關于 GPT-4 最為詳細的數據揭秘。目前還不能求證是否真實,但也值得大家研究下。正如原文作者所說,「有趣的方面是理解 OpenAI 為什么做出某些架構決策。」
關于 GPT-4 的這些架構信息,你怎么看?
-
數據集
+關注
關注
4文章
1208瀏覽量
24747 -
ai技術
+關注
關注
1文章
1284瀏覽量
24368 -
ChatGPT
+關注
關注
29文章
1564瀏覽量
7858
原文標題:終極「揭秘」:GPT-4模型架構、訓練成本、數據集信息都被扒出來了
文章出處:【微信號:WUKOOAI,微信公眾號:悟空智能科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT深度融入蘋果Mac軟件生態
ChatGPT新增實時搜索與高級語音功能
蘋果iOS 18.2公測版發布,Siri與ChatGPT深度融合
ChatGPT 與人工智能的未來發展
如何使用 ChatGPT 進行內容創作
華納云:ChatGPT 登陸 Windows
llm模型和chatGPT的區別
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了






 工商網監
工商網監
評論