 3D DRAM還能這樣玩?
3D DRAM還能這樣玩?
由于受到半導體材料、制造技術和成本等的限制,如何發展芯片就成為了大家的關注重點。尤其是在存儲方面,緊隨NAND Flash的步伐,DRAM也走上了3D之路。日前,來自東京東京工業大學的科學家發表了一篇論文,并在其中闡述了一種名為BBcube的 3D DRAM 堆棧設計,其頂部配有處理器,可以提供比高帶寬內存 (HBM) 高四倍的帶寬和五分之一的位訪問能量。
根據該研究團隊負責人 Takayuki Ohba 教授所說:“BBCube 3D 有潛力實現每秒 1.6 TB 的帶寬,比 DDR5 高 30 倍,比 HBM2E 高四倍。”而在本文中,我們摘譯了其關于3D DRAM的一些描述,以其給大家一些參考。更多詳細內容,請大家點擊文末的原文查看。
以下為論文摘譯:
隨著特征尺寸的不斷減小,半導體器件和計算機系統也在不斷發展。另一方面,自 20 世紀 80 年代以來,人們主要從單片IC的角度考慮三維技術。從20世紀90年代末開始,3D技術被廣泛研究用于混合結構,包括從芯片級到晶圓級的封裝,例如如何堆疊半導體元件以及如何通過TSV等垂直互連在堆疊的芯片之間進行連接。
按照這一趨勢,計算機系統體積將達到50 mm3,功耗將達到0.5 mW 。即使在如此小型的計算機中,也需要高性能和大存儲容量,同時又不犧牲功率效率和散熱。然而,傳統的二維(2D)縮放和三維(3D)集成方法,例如高帶寬內存(HBM)中使用的方法,由于制造成本和所需的良率而不可避免地面臨經濟危機。
克服這些問題的一種有前途的方法是將 3D 堆疊與高吞吐量相結合,即使用WOW和COW技術將共集成擴展到三維(z 方向) 。具體來說,多晶圓堆疊的 z 高度必須很小,這意味著裸片之間不應有凸塊,并且裸片應該很薄,這是 BBCube 的主要特點,而且,由于 TSV 長度短和高密度信號并行性,它可以實現高帶寬和低功耗。又因為高密度 TSV 能充當熱管,因此,即使在 3D 結構中,也可以實現低溫。
二維縮放的制造成本危機
在討論大批量制造的3D集成之前,有必要調查一下半導體技術發展的現狀和未來前景。
由于所需的昂貴的光刻工藝和設施,傳統的二維縮放將面臨嚴重的經濟危機。降低成本需要采用先進的光刻技術,加上缺陷監控系統等外圍支持設施,占生產線總成本的三分之一到四分之一。此外,由于不可避免的隱形缺陷減少,位成本在 20 nm 節點附近飽和。同時,除非有足夠的良率,否則即使采用高分辨率光刻,總成本也會增加。這是集成多個小型微處理器裸片(chiplet)的主要原因。
簡而言之,雖然縮小芯片尺寸很有用,但就資本投資而言,這種微縮是極其繁重的。迄今為止,我們已經對新制造設施(Fab)進行了大規模投資,考慮到未來兩到三代的技術將在沒有任何重大技術變化的情況下可用。這是基于半導體領域的經驗規則,即由于涉及產品銷售和設施折舊之間的權衡,投資后幾代才能獲得利潤。
根據這一經驗規則,對最近開發的7納米技術的投資需要考慮其對2-3納米技術的適用性。對于 ArF (λ = 193 nm),需要采用浸沒式光刻、一層的雙重或四重圖案化來滿足這些關鍵圖案尺寸。極紫外(EUV;λ = 13.5 nm)光刻有可能在一步中實現圖案化,因此 EUV 優于 ArF。然而,EUV***的價格超過1.2億美元,是 ArF 浸沒式 (iArF) ***的兩倍以上,但其當前的吞吐量小于 iArF 機器。
換算成當前大型晶圓廠的處理能力(例如每月5萬片來料晶圓),基于此系統性能,EUV技術將需要約20億美元的投資。假設每一代人的終生銷售額約為相應商業投資的10倍,則該投資所需的相應市場規模將超過200億美元。盡管這一估計是基于 2020 年全球半導體銷售額 4400 億美元來做的,但對于一種產品和一家制造商來說,這一市場規模并不現實。
總而言之,從行業經濟角度來看,這是二維縮放的限制之一,市場目前很難找到勝利的場景,尤其是在納米節點之外。
在本文中,我們會介紹由東京工業大學創新研究所推出的一種BBCube解決方案在3D DRAM實現的一種解決方案。
BBCube技術介紹
通過三維堆疊結合傳統的二維集成將結構延伸到垂直空間(z方向)有望克服上述問題。BBCube的概念是下一代 2.5D(side-by-side arrays)和 3D 堆棧系統問題的解決方案,其中器件芯片和中介層無凸塊連接。
下圖顯示了使用 TSV 的凸塊互連和無凸塊互連的比較,假設一個內存核心有 8 個芯片,一個邏輯控制器。由于采用凸塊連接的片上芯片 (COC) 技術形成的芯片級堆疊需要拾取和放置來進行芯片轉移,因此芯片厚度受到機械剛度要求和翹曲的限制,導致芯片間距約為80–100 微米。機械剛度隨著裸片厚度的增加而降低。
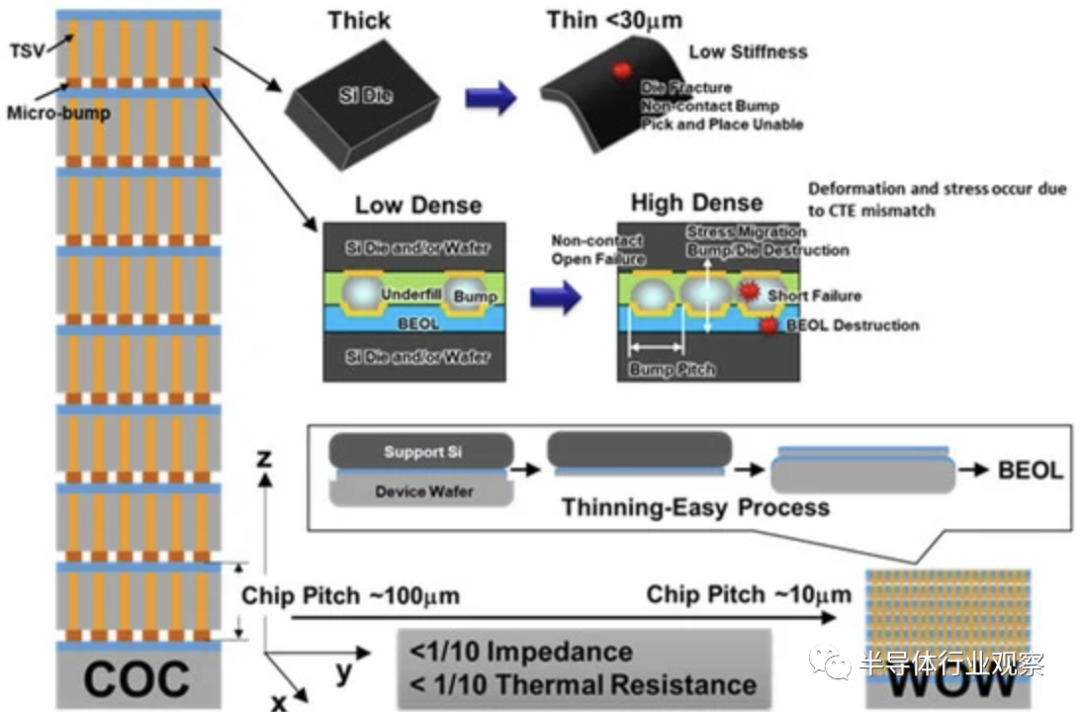
由于使用支撐晶圓減薄后的鍵合工藝可以將硅晶圓減薄至 4 μm,而不會降低器件特性,因此包括器件層和粘合層在內的晶圓總厚度僅為 10 至 20 μm。這是使用 TSV 的傳統凸塊互連厚度的 1/3 至 1/5。因此,即使堆疊的晶圓數量為100,我們假設晶圓厚度為10μm,那么堆疊后的總厚度為1mm。該總高度滿足當前的封裝標準。在這些多級堆疊工藝之后,當四個、八個、十六個等這些器件與由30Gb/cm2 的存儲密度制造的傳統存儲器件堆疊時例如,采用22nm技術,3D存儲器件的總容量可以分別線性增加到120Gb、240Gb、480Gb等,如下圖所示。
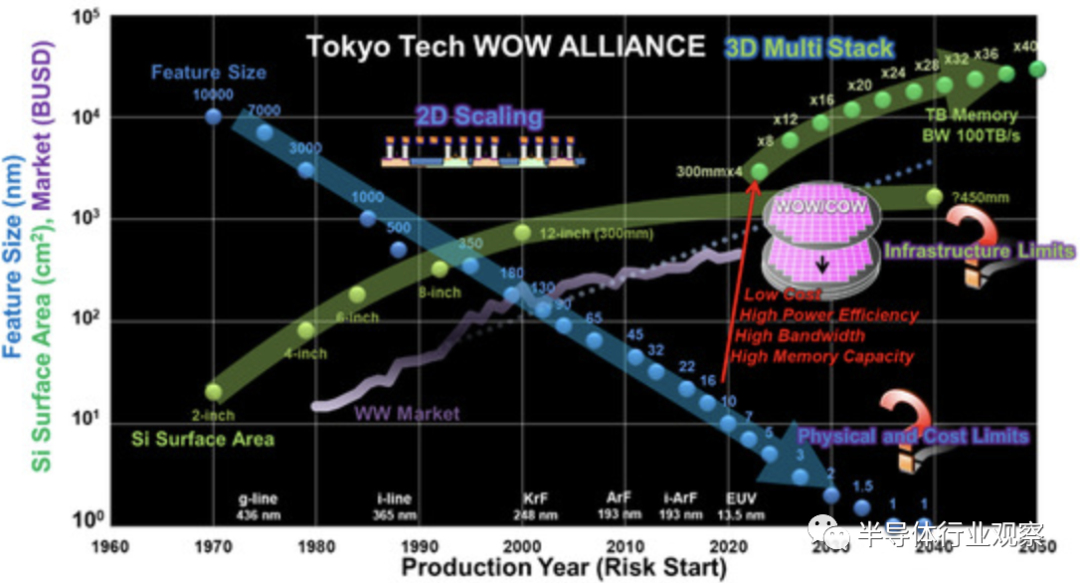
通過堆疊40層可以實現太比特容量的3D存儲器。相比之下,要使用極端縮放的單個晶圓實現等效容量,將需要1 nm節點技術,其等效尺寸約為0.23 nm的Si-Si鍵長dSi-Si的四倍。因此,不僅需要針對 3D 晶體管的創新技術,還需要針對 3D 芯片堆棧的創新技術。
考慮到技術路線圖,縮放技術和制造 3D 結構技術的問題通常會分開討論。人們認為封裝可以負責3D結構。然而,這兩種技術并不總是相互排斥的。通過使用3D高密度集成技術與量產技術相結合,微縮技術將不再受到嚴格的要求。換句話說,可以確保足夠長的學習時間,并且通過集中控制代際差異和縮短流程,可以預期進一步降低成本。
下圖顯示了芯片間連接的芯片級配置示意圖。該配置是從并排到芯片堆棧的演變,以減少信號延遲、IR 壓降和封裝板上的占用空間。BBCube 是滿足這些要求的候選者之一。無凸塊連接和超薄化可實現最短的布線和高密度 TSV,并改善晶圓堆疊中的錯位。高密度 TSV 非常有用,因為并行通信可提供高帶寬。根據上述功能,BBCube架構為長期以來關于高密度LSI中信號傳播、功率分配和散熱的討論提供了解決方案。
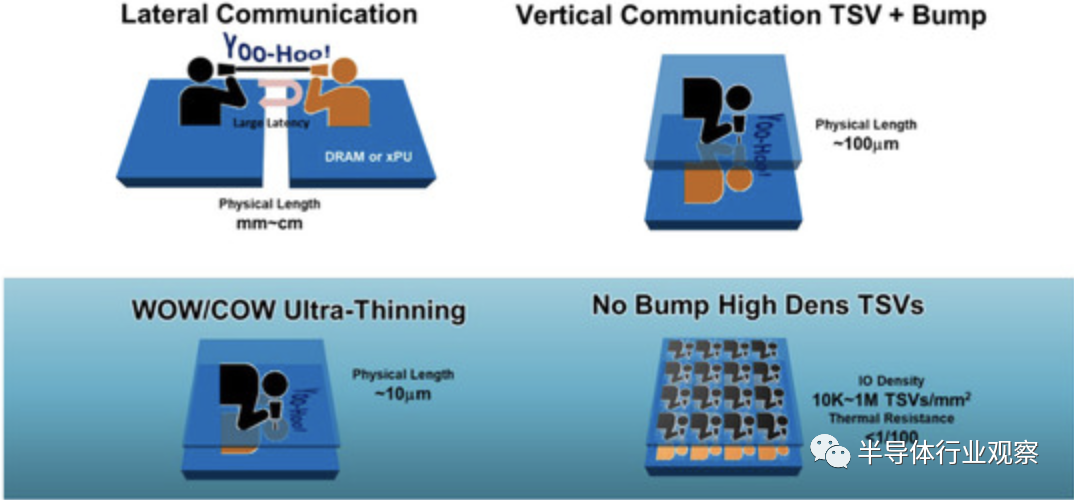
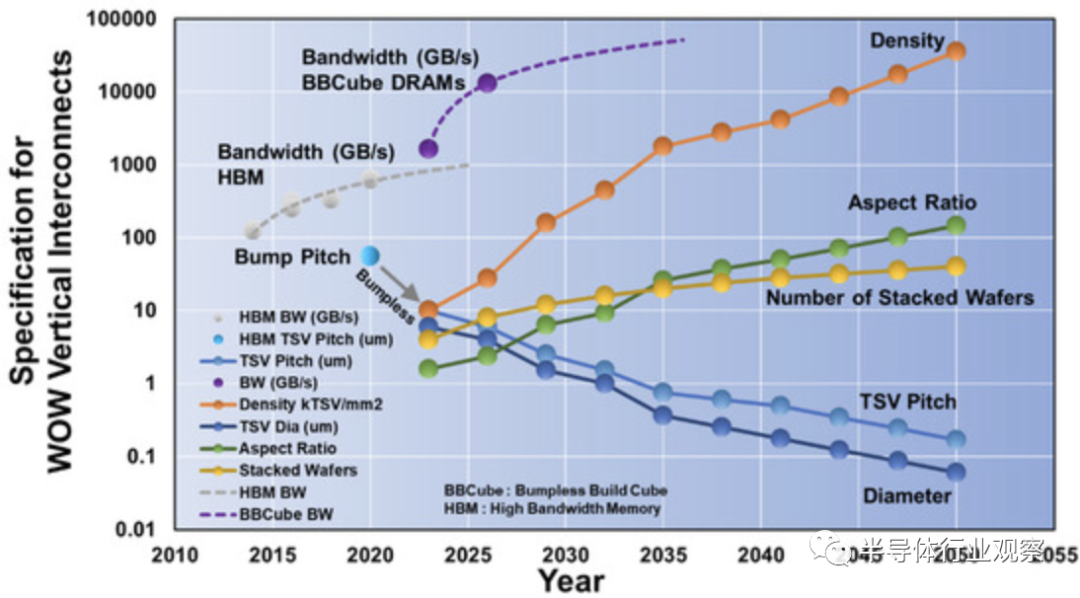
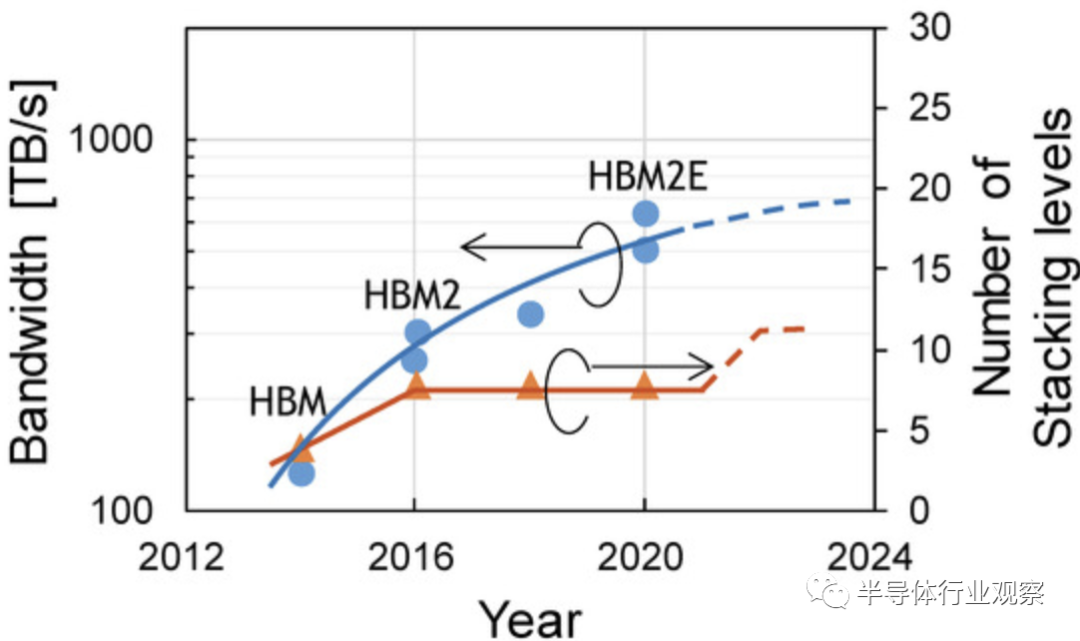
事實上,由于凸點間距的限制,最近的高帶寬存儲器(HBM)的帶寬趨于飽和,如下圖所示。但就 BBCube 而言,由于 BBCube 使用高密度 TSV 和新穎的內存架構,因此可以實現高一個數量級的帶寬。根據WOW聯盟的說法,考慮到鍵合對準的成熟度,TSV間距將每三年縮小一次。
基于BBCube的DRAM
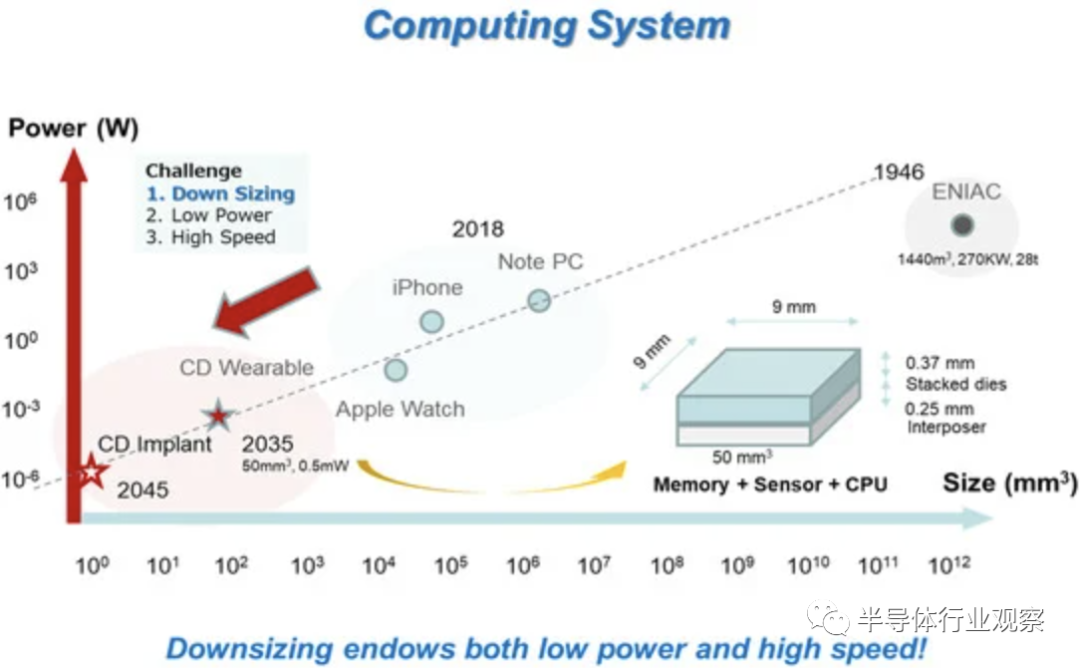
眾所周知,計算系統歷史上存在三個關鍵挑戰:(1)尺寸減小,(2)功耗降低,(3)速度提高。在這些關鍵要素中,尺寸減小是最迫切的挑戰,因為低功耗和高速都可以通過尺寸減小本身來實現。下圖顯示了計算系統路線圖。根據推斷趨勢,到2035年,目標器件體積將達到50 mm3,功耗為0.5 mW。這樣的設備可能類似于人工智能機器蜜蜂,具有 CPU/GPU、DRAM、NAND 閃存和傳感器。它將服務于人類用戶,讓AI機器蜂可以觀察用戶周圍的環境,保護用戶,并充當行政秘書。
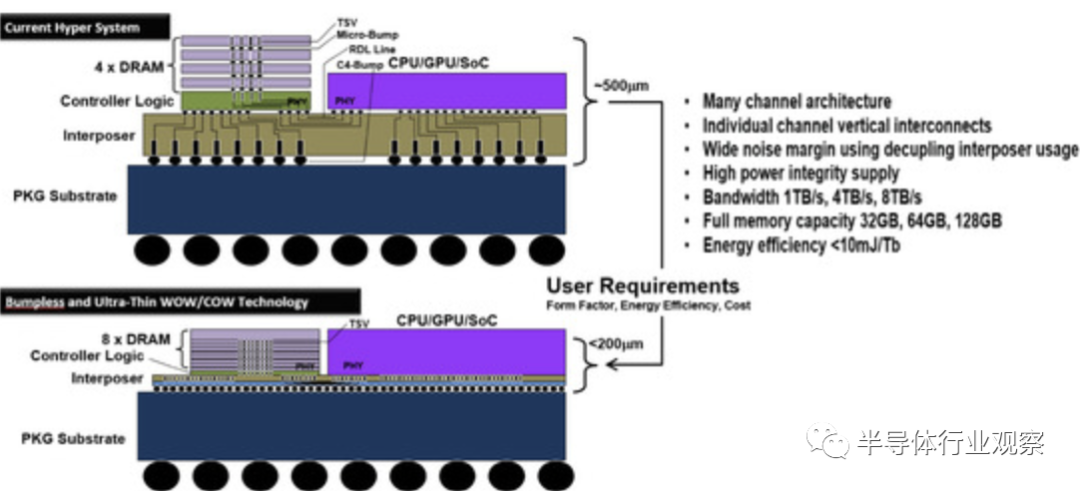
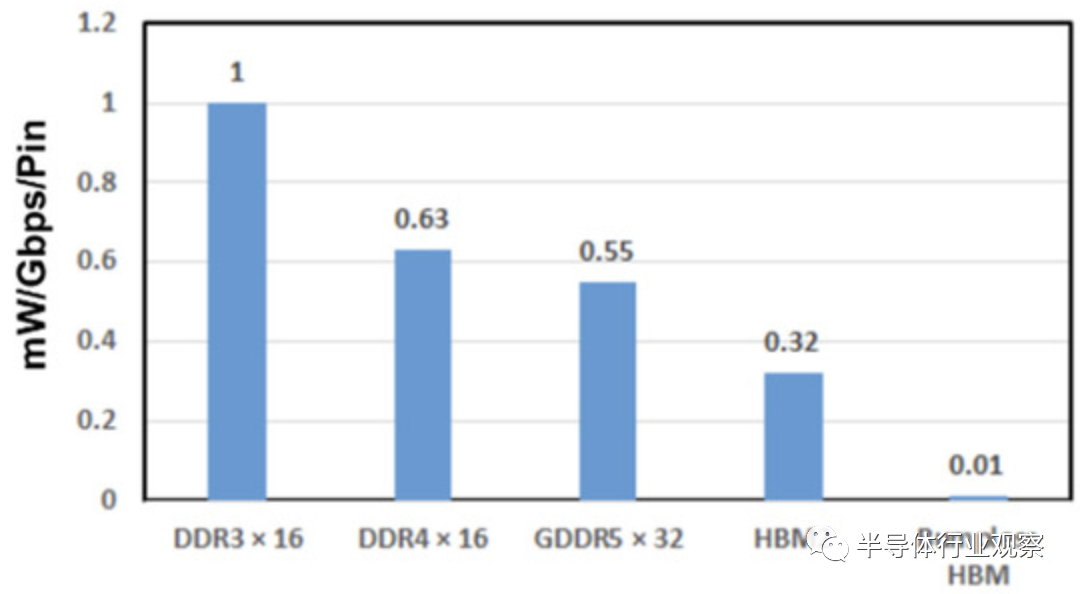
具有微凸塊的TSV通常用于高帶寬存儲器(HBM),如圖29所示。然而,使用微凸塊時存在幾個問題。一個主要問題是,即使是 HBM 也很難跟上 GPU 或 CPU 速度的提高。例如,NVIDIA生產的Pascal的處理速度為1TB/s,因此必須使用四組256GB/s的HBM。GPU/CPU供應商不斷努力提高其產品的速度,例如提高到2TB/s和4TB/s,重點關注AI系統。HBM 必須將 I/O 引腳速度提高 2.5 倍,例如從2.0 Gb/s/pin提升到 5.0 Gb/s/pin ,因此,功率和熱量也將增加。
如圖所示,具有競爭力的 BBCube DRAM 結構是一種能夠通過無凸塊 TSV 實現 8 芯片堆疊的結構。通過增加通道數量并降低 TSV 阻抗,應該可以實現 1、4 和 8 TB/s 的超高帶寬。
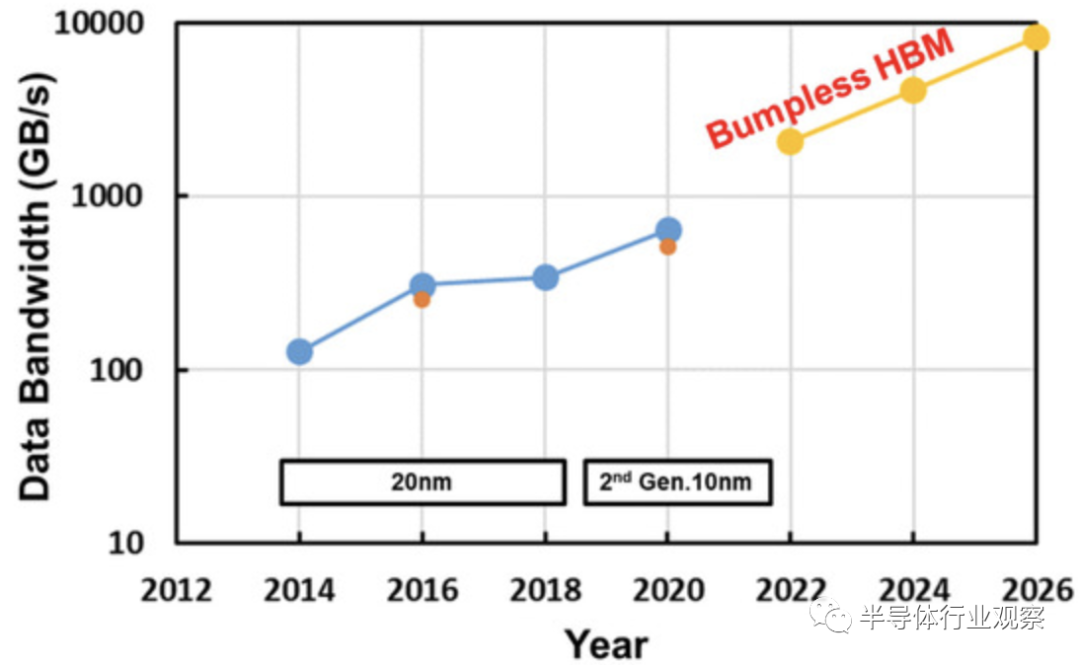
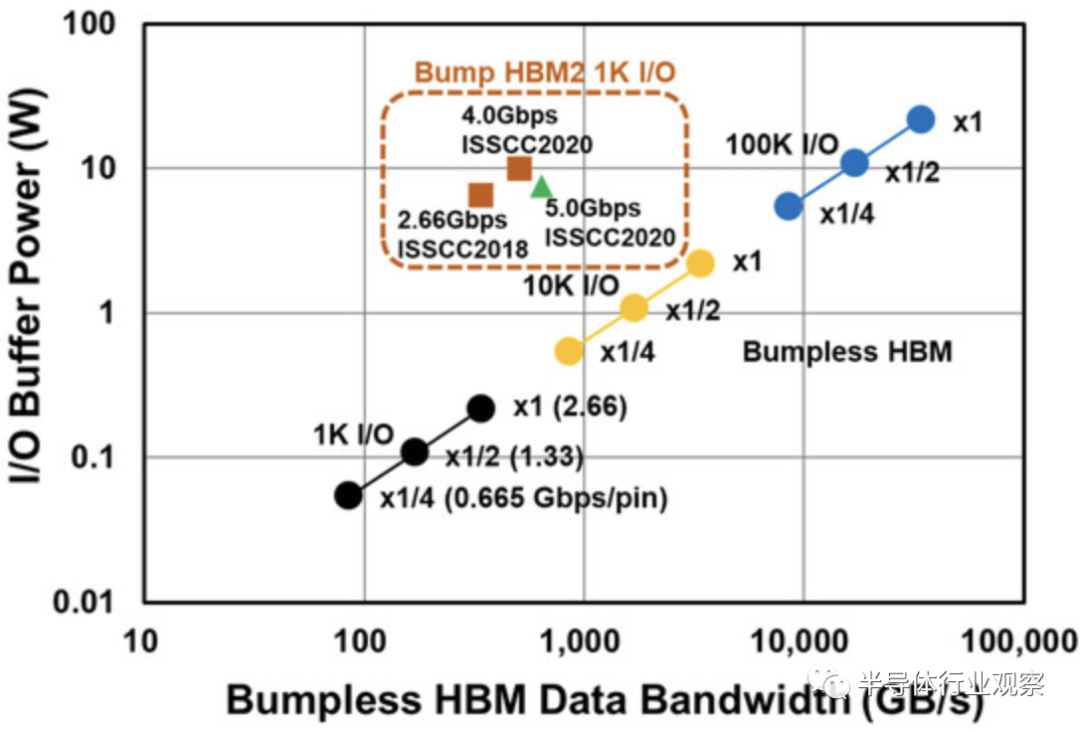
從上圖我們可以看到HBM 數據帶寬路線圖。通過實現因 I/O 數量增加而帶來的并行性增強,預計沒有任何bumps的 HBM 帶寬將不斷增加。至于I/O功耗,bumpless HBM的第一個目標是當前HBM2的三十分之一,如下圖所示。
根據I/O 數量,我們還能從下圖獲得了帶凸塊 HBM2 和無凸塊HBM的數據帶寬和I/ O緩沖功率。
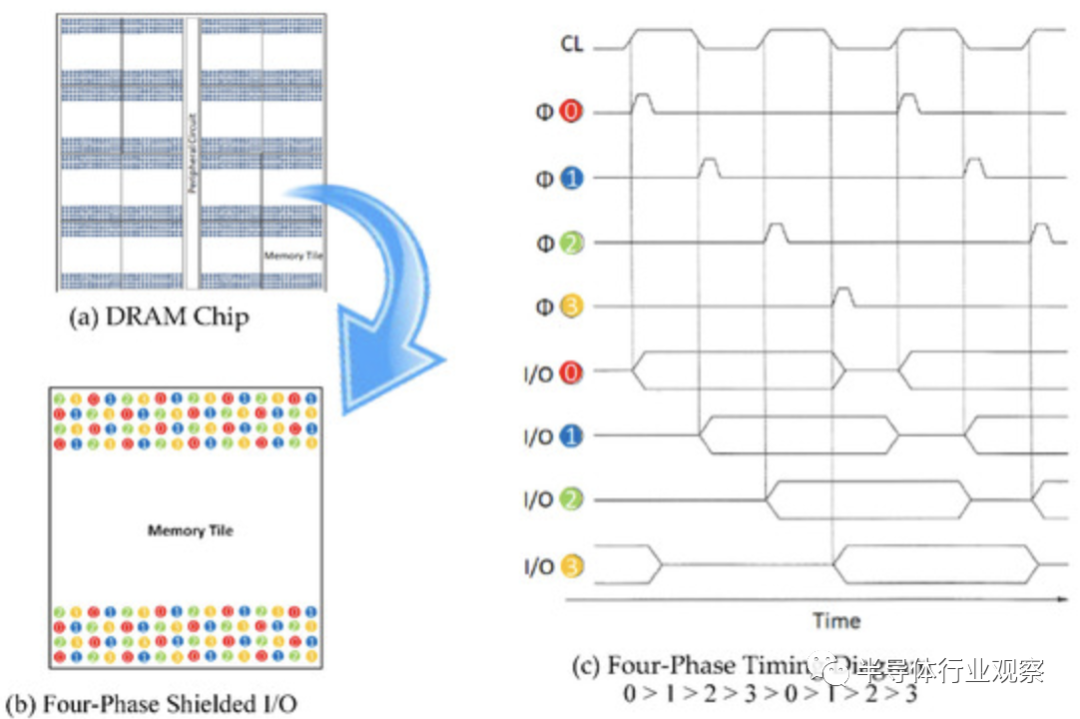
據統計,無凸塊HBM 可通過將 I/O 數量增加到 1 K、10 K 和 100 K 來實現超高數據帶寬,并可通過采用四相屏蔽 I/O 方案減少 I/O 引腳頻率,以將 I/O buffer功率降低至 1/2 或 1/4。
在實際測試中,從下圖a我們可以看到該方案的 TSV 電容的頻率特性。由于慢波(slow-wave)模式,它增加到 3 GHz 以下。下圖b則指出,襯墊厚度(liner thickness)決定了 3 GHz 以下的 TSV 電容。TSV 直徑和 Si 厚度也決定了 TSV 電容,可以通過采用 BBCube 來減小 TSV 電容。
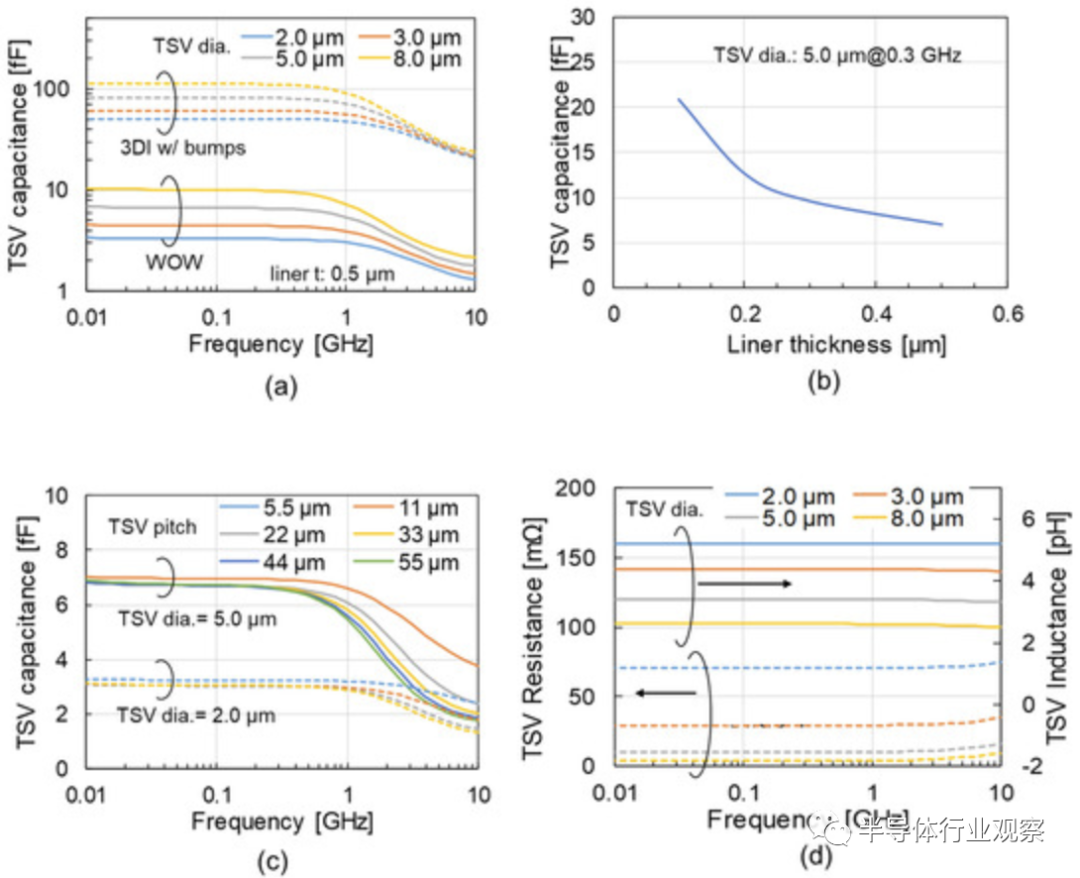
如圖上圖c、TSV間距不影響TSV電容。因此,當TSV直徑為5μm時,BBCube能夠在不增加電容的情況下將TSV間距縮短至11μm。此外,當TSV直徑為2μm時,BBCube能夠將TSV間距縮短至5.5μm。與傳統3DI相比,BBCube的TSV電容變為1/20。如上圖d所示,TSV 電阻的頻率依賴性由于集膚效應(skin effect)而在 5 GHz 以上增加,但這高于 BBCube 的工作頻率,因此沒有任何影響。
此外,由于DRAM cell的溫度會影響其保留時間并限制堆棧數量。因此,研究人員還對堆疊式 DRAM 進行了熱分析。
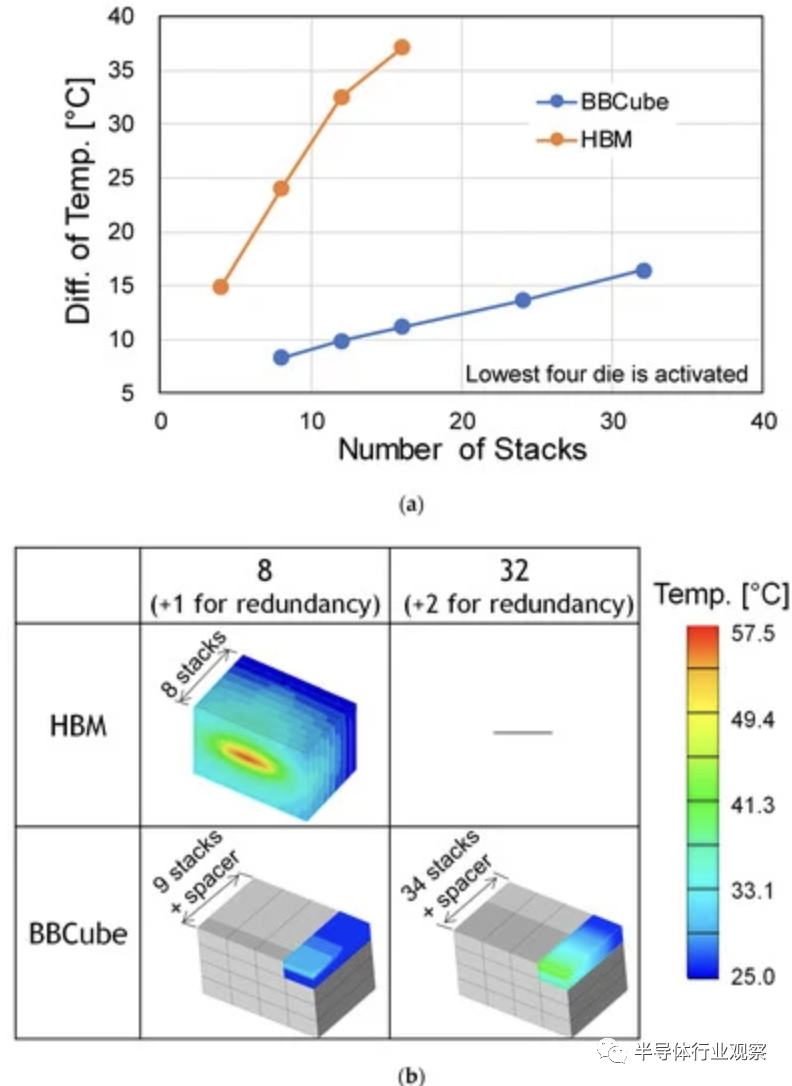
從技術上看,BBCube 中的 TSV 直接連接到底部裸片,而對于傳統 3DI,需要在 TSV 之間放置焊料和 BEOL 層,這會增加熱阻。BBCube 情況下的熱阻是傳統 3DI 的 1/4。下圖則顯示了室溫下堆疊 DRAM 頂部與DRAM Cell最高溫度的溫度差。在堆疊DRAM的底部,HBM 和 BBCube 中均放置了具有相同功耗的基礎裸片。對于具有 9 個堆棧的 BBCube,由于熱阻較低,DRAM 單元溫度差異為 8.3 °C。即使堆疊 34 個芯片,BBCube 中的溫差仍為 16 °C,大約是堆疊 8 個芯片的 HBM 的三分之二。BBCube 允許堆疊的芯片數量是 HBM 的 4 倍。這使得使用 16 Gb DRAM 芯片的內存容量達到 64 GB。
總結
由于器件結構后微縮時代的需求,三維集成技術預計將得到越來越多的采用。通過這樣做,當堆疊微米厚度的晶圓時,總厚度減小,晶體管容量與晶圓數量成比例增加。增加 TSV 互連密度可在不犧牲能源效率的情況下實現 TB 級帶寬。功耗和散熱對于高密度模塊(例如 2.5D 和 3D 系統)尤其重要。
2.5D不是一個物理術語,是指將HBM、GPU(圖形處理單元)、MPU等三維存儲器整合并集成在一個中介層上的高速、高帶寬系統,是一種后端進程的總稱。最近幾年,它已成為一種將具有不同功能的多個芯片和無源元件組合到一個系統模塊中的產品差異化技術。本文作者的研究組織“WOW Alliance”提出了使用 WOW 和 COW 流程的 BBCube 架構,適用于包括無源器件的 2.5D 和 3D 系統。
隨著堆疊晶圓數量的增加,制造中使用晶圓的數量也成比例增加。最近已采用每月8萬片晶圓的量產。為了保持 8 片 DRAM 晶圓堆疊的相同吞吐量,每月使用的晶圓數量將為 640,000 片。在不考慮設備成本和運行成本的情況下,增加制造工廠的規模是可能的。然而,占地八倍的生產線可能無法平衡生產成本。因此,在未來,在這種情況下,可能會重新考慮擴大晶圓尺寸或替代方法,例如減少總工藝步驟與非常高產量的組合。
如果提高晶圓堆疊的對準精度,每平方厘米大約可以形成1至1000萬個TSV。如此大規模的 I/O 對于 DRAM 堆疊來說太高了,但如果 TSV 的縮小和布局靈活性的發展,將有可能單獨堆疊 MPU 邏輯和 SRAM 緩存。如果電源分配和接地可以位于SRAM單元的正下方,則可以實現穩定的電流和<0.7V的低施加電壓和低噪聲,因為它們可以通過微米級短互連以等效長度和高并行性連接。這種高密度 TSV 互連與 BBCube(低功耗)相結合將有助于減少 3D 系統的多余熱量。
總之,正如所討論的,通過采用三維集成技術可以實現半導體路線圖的下一步。雖然需要開發高生產率的3DI技術,例如前端晶圓技術,但許多成熟的工藝都可以應用。因此,3DI的新技術只是薄化和堆疊工藝。這些技術也可以得到改進,因為有來自前端的眾所周知的技術和新穎的候選材料,這些技術有望通過應用在半導體行業多年獲得的專業知識而變得成熟。
審核編輯:劉清
-
半導體
+關注
關注
334文章
27592瀏覽量
220751 -
DRAM
+關注
關注
40文章
2320瀏覽量
183709 -
Nand flash
+關注
關注
6文章
241瀏覽量
39900 -
TSV技術
+關注
關注
0文章
17瀏覽量
5704 -
HBM
+關注
關注
0文章
386瀏覽量
14790
原文標題:3D DRAM,還能這樣玩!
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

3D DRAM內嵌AI芯片,AI計算性能暴增
裸眼3D筆記本電腦——先進的光場裸眼3D技術
SK海力士5層堆疊3D DRAM制造良率已達56.1%
SK海力士五層堆疊的3D DRAM生產良率達到56.1%
三星已成功開發16層3D DRAM芯片
三星電子研發16層3D DRAM芯片及垂直堆疊單元晶體管
3D DRAM進入量產倒計時,3D DRAM開發路線圖


三星電子:2025年步入3D DRAM時代
三星2025年后將首家進入3D DRAM內存時代






 工商網監
工商網監
評論