 詳細介紹?注意力機制中的掩碼
詳細介紹?注意力機制中的掩碼
注意力機制的掩碼允許我們發送不同長度的批次數據一次性的發送到transformer中。在代碼中是通過將所有序列填充到相同的長度,然后使用“attention_mask”張量來識別哪些令牌是填充的來做到這一點,本文將詳細介紹這個掩碼的原理和機制。
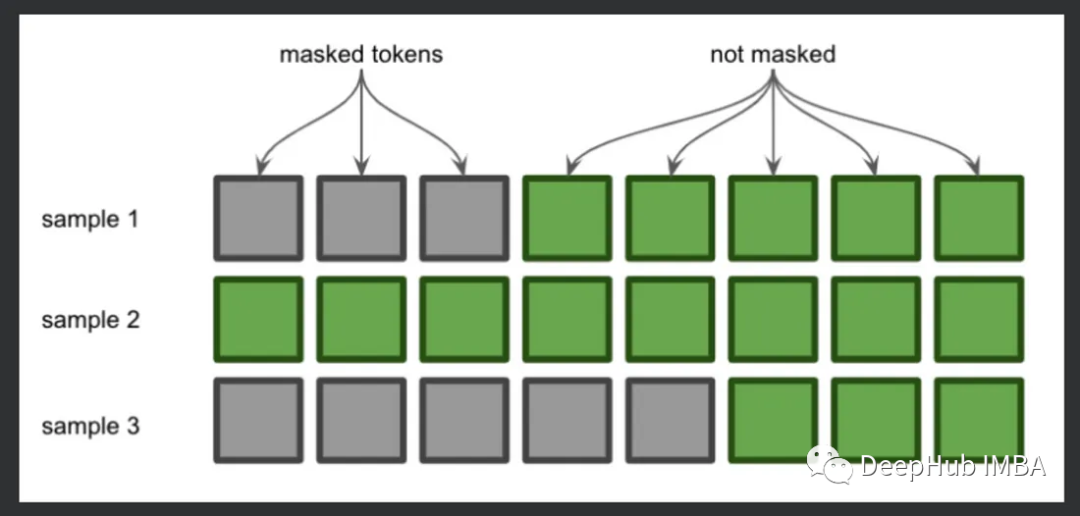
我們先介紹下如果不使用掩碼,是如何運行的。這里用GPT-2每次使用一個序列來執行推理,因為每次只有一個序列,所以速度很慢:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
gpt2 = GPT2LMHeadModel.from_pretrained('gpt2')
context = tokenizer('It will rain in the', return_tensors='pt')
prediction = gpt2.generate(**context, max_length=10)
tokenizer.decode(prediction[0])
# prints 'It will rain in the morning, and the rain'
在顯存允許的情況下,使用批處理輸入的速度更快,因為我們在一次推理的過程可以同時處理多個序列。對許多樣本執行推理要快得多,但也稍微復雜一些,下面是使用transformer庫進行推理的代碼:
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.eos_token
sentences = ["It will rain in the",
"I want to eat a big bowl of",
"My dog is"]
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
output_sequences = gpt2.generate(**inputs)
for seq in output_sequences:
print(tokenizer.decode(seq))
transformer庫幫我們處理了很多細節,我們現在詳細的介紹它里面到底做了什么。
我們將令牌輸入到語言模型中,如GPT-2和BERT,作為張量進行推理。張量就像一個python列表,但有一些額外的特征和限制。比如說,對于一個2+維的張量,該維中的所有向量必須是相同的長度。例如,
from torch import tensor
tensor([[1,2], [3,4]]) # ok
tensor([[1,2], [3]]) # error!
當我們對輸入進行標記時,它將被轉換為序列的張量,每個整數對應于模型詞表中的一個項。以下是GPT-2中的標記化示例:

如果我們想在輸入中包含第二個序列:

因為這兩個序列有不同的長度,所以不能把它們組合成一個張量。這時就需要用虛擬標記填充較短的序列,以便每個序列具有相同的長度。因為我們想讓模型繼續向序列的右側添加,我們將填充較短序列的左側。

這就是注意力掩碼的一個應用。注意力掩碼告訴模型哪些令牌是填充的,在填充令牌的位置放置0,在實際令牌的位置放置1。現在我們理解了這一點,讓我們逐行查看代碼。
tokenizer.padding_side = "left"
這一行告訴標記器從左邊開始填充(默認是右邊),因為最右邊標記的logits將用于預測未來的標記。
tokenizer.pad_token = tokenizer.eos_token
這一行指定將使用哪個令牌進行填充。選擇哪一個并不重要,這里我們選擇的是“序列結束”標記。
sentences = ["It will rain in the",
"I want to eat a big bowl of",
"My dog is"]
上面這三個序列在標記時都有不同的長度,我們使用下面的方法填充:
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
在進行表計劃和添加填充后,得到了以下的結果:
{'input_ids': tensor([
[50256, 50256, 50256, 1026, 481, 6290, 287, 262],
[ 40, 765, 284, 4483, 257, 1263, 9396, 286],
[50256, 50256, 50256, 50256, 50256, 3666, 3290, 318]
]),
'attention_mask': tensor([
[0, 0, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1]
])}
可以看到,第一個和第三個序列在開始時進行了填充,并且attention_mask參數標記了這個填充的位置。
現在讓我們將這個輸入傳遞給模型來生成新的文本:
output_sequences = gpt2.generate(**inputs)
如果你不熟悉函數調用的**kwargs語法,它是將輸入字典作為命名參數傳入,使用鍵作為參數名,并使用值作為相應的實參值。
我們只需要循環遍歷每個生成的序列并以人類可讀的形式打印出結果,使用decode()函數將令牌id轉換為字符串。
for seq in output_sequences:
print(tokenizer.decode(seq))
在注意力掩碼中,我們的輸入是0和1,但是在最終的計算時,會將在將無效位置的注意力權重設置為一個很小的值,通常為負無窮(-inf),以便在計算注意力分數時將其抑制為接近零的概率。
這時因為,在計算注意力權重時,需要進行Softmax的計算:
Softmax函數的性質:注意力機制通常使用Softmax函數將注意力分數轉化為注意力權重,Softmax函數對輸入值進行指數運算,然后進行歸一化。當輸入值非常小或負無窮時,經過指數運算后會接近零。因此,將掩碼設置為負無窮可以確保在Softmax函數計算時,對應位置的注意力權重趨近于零。
排除無效位置的影響:通過將無效位置的注意力權重設置為負無窮,可以有效地將這些位置的權重壓低。在計算注意力權重時,負無窮的權重會使對應位置的注意力權重接近于零,從而模型會忽略無效位置的影響。這樣可以確保模型更好地關注有效的信息,提高模型的準確性和泛化能力。
但是負無窮并不是唯一的選擇。有時也可以選擇使用一個很大的負數,以達到相似的效果。具體的選擇可以根據具體的任務和模型的需求來確定。
-
處理器
+關注
關注
68文章
19313瀏覽量
230054 -
虛擬機
+關注
關注
1文章
918瀏覽量
28232 -
python
+關注
關注
56文章
4797瀏覽量
84757
發布評論請先 登錄
相關推薦
注意力機制的誕生、方法及幾種常見模型
注意力機制或將是未來機器學習的核心要素
基于注意力機制的深度學習模型AT-DPCNN

基于多層CNN和注意力機制的文本摘要模型







 工商網監
工商網監
評論