 英偉達Quantum-2 Infiniband平臺技術
英偉達Quantum-2 Infiniband平臺技術
隨著大數據和人工智能等技術的快速發展,高性能計算需求日益增長。英偉達Quantum-2 Infiniband平臺應運而生,為用戶提供高速、低延遲的數據傳輸和處理能力,實現卓越的分布式計算性能。
Quantum-2采用最新一代NVIDIA Mellanox HDR 200Gb/s Infiniband網絡適配器,支持高速數據傳輸和低延遲計算。結合NVIDIA GPU,實現加速計算和分布式存儲,提高計算效率和資源利用率。

此外,Quantum-2還支持多種先進技術,如NVIDIA RDMA、NVLink和Multi-host等,實現數據中心范圍內的高效數據傳輸和資源共享。用戶可根據實際需求,搭建高性能計算集群或分布式存儲系統,為大數據分析、人工智能、科學計算等領域提供強大支持。
Q:CX7 NDR 200 QSFP112能否兼容HDR/EDR線纜?
A:可以
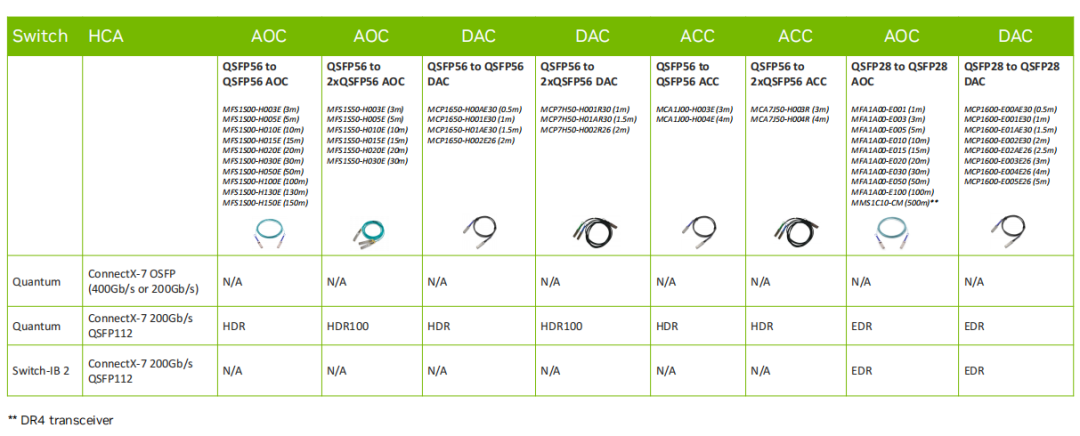
Q:CX7 NDR能否支持CR8模塊?
A:CX7 NDR用Nvidia SR4多模或者DR4單模規格的模塊,IB交換機側使用SR8或者DR8模塊。Q:CX7 Dual-port 400G能否bonding后達到800G,為啥200G bonding后能疊加達到400G?
A:目前CX7并沒有雙口400G配置,網絡總性能由PCle帶寬/網卡處理能力/網口物理帶寬的瓶頸決定,PCle帶寬上限為512G,網卡處理能力》400G,故雙口200G bond可達到400G帶寬。
Q:一分二線纜怎么連接
A:Al訓練場景需配合NCCLSHARP通信環連接SU內不同節點的網卡。
Q:哪些卡是IB/ETH雙模的,IB/ETH雙模怎么切換
A:mlxconfig -d mlx5_x s LINK_TYPE_P1=1(Or 2)
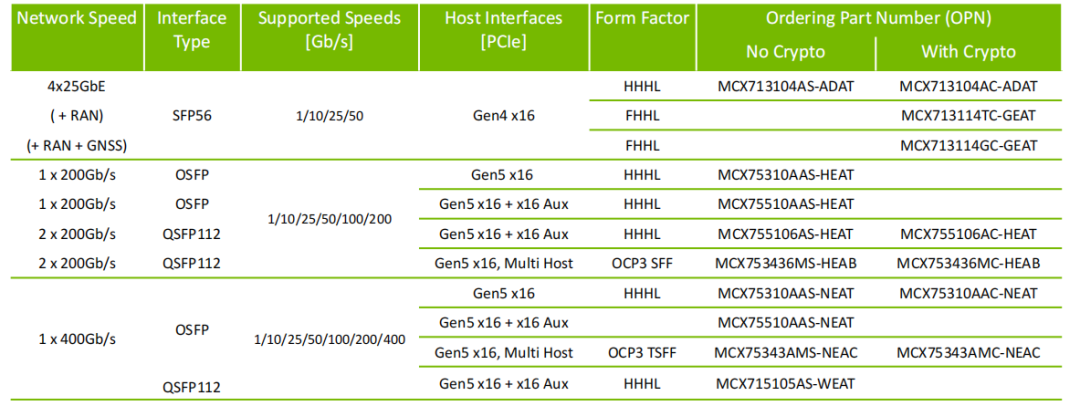
Q: Superpod組網里,假如我每臺服務器上配置4個NDR200的卡,那我能直接用一個一分四的線纜直接連接到同一個交換機上嗎?還是說得用2根一分二的分別連不同的交換機?
A:不推薦,這種連接方式不符合SuperPoD組網規則,考慮到NCCL/SHARP性能,需要Leaf層交換機分別使用一分四線纜連接SU內不同服務器的NDR200端口,形成不同的通信環。
Q:Super Pod組網中,如果最后一個SU中,節點的數量不足32臺,比如只有16臺,那最后一個SU的Leaf交換機可以只用4臺嗎?這樣會出現同一個節點的兩個網卡接入到一個leaf交換機上,SHARP樹會不會有問題?
A:可以但不推薦,NDR交換機可以支持64 SAT(SHARP Aggregation Tree)。
Q.NDR交換機上的同一個模塊,一個口插NDR線纜,另一個口插NDR 200的一分二線纜嗎?
A:可以,需要交換機側做NDR口的端口分拆配置。
Q.有一個關于最新superpod組網的問題想咨詢您一下,我看到最新的superpod組網白皮書是計算網絡中單獨配置2臺IB交換機組UFM軟件的網絡,但是這樣就導致了我集群會減少一臺GPU節點。如果我不單獨配置UFM交換機,只在管理節點部署UFM軟件,在不占用計算網絡的情況下通過另一套存儲網絡管理集群是否可以呢?
A:建議配置UFM設備(含軟件),計算網內的管理節點部署UFM軟件是可選方案,但該節點不應該承擔GPU計算業務負載。 存儲網絡是單獨組網的,是不同的網絡平面,無法管理計算集群。
Q: UFM Enterprise,SDN, Telemetry, Cyber-Al有什么區別?是不是必須買UFM?
A:可使用OFED自帶的opensm和命令腳本工具進行簡單的管理和監控,但是不具備UFM友好的可視化界面,功能也少了很多。
Q:交換機的子網管理器,OFED的子網管理器,UFM,三個管理節點的數目是否有差異?客戶部署時選擇哪個比較合適?
A:管理交換機適合2K節點內的管理,UFM和OFED的openSM節點管理能力無限制,需要配合管理節點的CPU以及硬件處理能力。
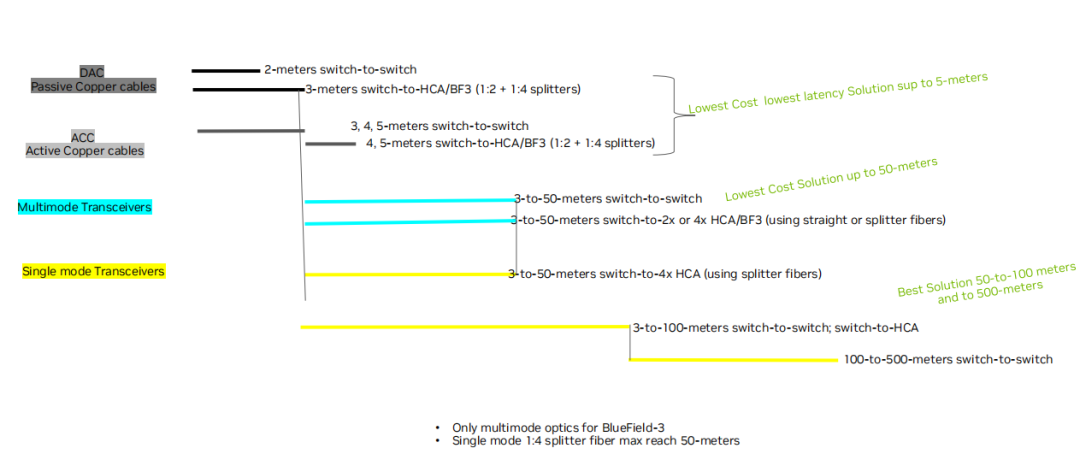
Q: DAC ACC AOC Transceiver的區別,每種的限制。
A:連接距離,布線的難易程度如下圖。
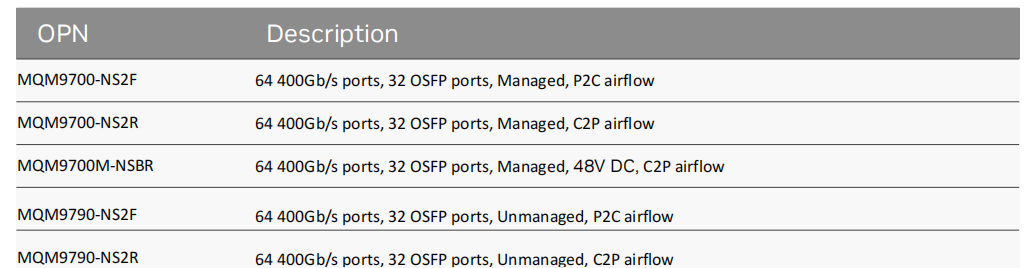
Q: 交換機 64 個 400Gb port, 為什么是 32 個 QSFP56 端口
A: 尺寸和功耗,2U 面板只能 32 cage;這是 OSPF 接口,支持兩個 400G ports,NDR 交換機要把 cage 和 port 的概念區分清楚。
Q: 請問兩端的模塊不同,可以通過線纜鏈接起來打通數據嗎?比如服務器這邊是 OSFP,交換機是 QSFP112
A: IB 必須用我們的 module 和 cable,現在主要介紹 IB,IB 交換機只有是 OSFP;兩側的模塊都要使用 NVIDIA 的推薦模塊,可以支持
Q: UFM 可以用來監控 RoCE 網絡嗎
A: 不可以,只支持 IB
Q: UFM 跟有管理性 Switch 和非管性 switch, 功能性是否一樣
A: 一樣
Q: IB 線纜在不影響傳輸帶寬時延的前提下,最大支持多遠的傳輸距離
A: 模塊+cable,最遠 500m,多模;DAC 銅纜 3m 以下,ACC 5m
Q: CX7 網卡開以太模式可以與其他家的 400G 支持 RDMA 的以太網交換機互聯嗎
A: 400G ethernet 互聯可以,RDMA 是 RoCE,可以在這種情況下跑,性能沒有保證;400G 以太網建議使用 BF3+Spectrum-4 組成的 Spectrum-X 平臺
Q: NDR 兼容 HDR、EDR 的話,這種線纜和模塊只有一體的嗎?
A: 是的,沒有分體的方案
Q: OSFP 網卡側的模塊應該是用的 flat 的吧?
A: 是的,網卡用 flat
Q: IB 卡開以太模式是不支持 RDMA 的嗎?
A: 可以跑 RoCE,就是 RDMA over Ethernet,推薦用 Nvidia Spectrum-X solution
Q: BF3 現在量產了嗎
A: 根據 OPN 不同,量產時間不同,具體跟負責 SA 聯系,提供你需要的 OPN
Q: 為什么 NDR 的光纜是分開的,沒有像 HDR 一樣的那種 AOC 線纜呢
A: 混雜了單多模,風水冷,不同長度這些因素,AOC 一體的方案會非常復雜,部署也不靈活
Q: 請問 400G 的 IB 和 400G 的以太,除了光模塊不一樣,線纜是一樣的嗎
A: 光纜是相同的,注意是 APC 帶 8 度斜角的類型
Q: CX7 網卡延時性能有具體要求么?在滿內存,已綁核等最優調試環境下對于網絡延時要求是?小于多少 us 算合適?
A: 這個跟測試機器的主頻,配置都有關系,還跟測試用 perftest, mpi 工具都有關系,建議你聯系負責 SA,給你提供具體支持
Q: OSFP 網卡側的模塊應該是用的 OSFP-flat 的吧?為啥會說用的是 OSFP-Riding Heatsink 的呢?
A: riding heatsink 指的是在 cage 上有個散熱器
Q: 這個集群方案里 ufm 的部分在哪里呢?想了解下這部分的作用
A: UFM 單獨跑在 server 上,可以當做一個 node,可以 HA 接兩臺。 但不建議跑 UFM 的node 同時跑計算業務
Q: 集群規模多大的時候,建議推薦 UFM 呢?
A: IB 網絡都建議配置,UFM 不只是 opensm,還有其他非常強大的管理和接口功能
A: 只要客戶有網管需求,建議都配置 UFM
Q: PCIe 5 是否只有 512G 嗎?PCIe4 是多少
A: Gen5 32G*16=512G, Gen 4 16G*16=256G
Q: IB 卡有單工或者雙工說法么
A: 都是雙工;單工或者雙工對于當前的設備來講,只是概念而已 因為收和發物理通道已經分離了。
-
人工智能
+關注
關注
1791文章
47279瀏覽量
238513 -
網絡適配器
+關注
關注
0文章
41瀏覽量
11571 -
英偉達
+關注
關注
22文章
3776瀏覽量
91111 -
大數據
+關注
關注
64文章
8889瀏覽量
137446
原文標題:英偉達Quantum-2 Infiniband平臺技術A&Q
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

英偉達加速Rubin平臺AI芯片推出,SK海力士提前交付HBM4存儲器
丹麥推出首臺AI超級計算機Gefion
英偉達Blackwell可支持10萬億參數模型AI訓練,實時大語言模型推理
英偉達高管解讀Q2財報 但是英偉達市值暴跌1.4萬億元


進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
新思科技攜手英偉達:基于加速計算、生成式AI和Omniverse釋放下一代EDA潛能

NVIDIA推出X800網絡交換機平臺,實現800Gb/s端到端吞吐量
英偉達公布了其新的6G研究云平臺
英偉達市值逼近2萬億美元,漲瘋了






 工商網監
工商網監
評論