 大模型將會推動手機內存和AI加速器革新?
大模型將會推動手機內存和AI加速器革新?
人工智能已經成為半導體行業過去幾年最重要的新推動力。而去年以ChatGPT為代表的大模型更是進一步點燃了人工智能以及相關的芯片市場,ChatGPT背后的大模型正在成為下一代人工智能的代表并可望進一步推進新的應用誕生。
說起大模型,一般我們想到的往往是在云端服務器上運行模型。然而,事實上大模型已經在走入終端設備。一方面,目前已經有相當多的工作證明了大模型經過適當處理事實上可以運行在終端設備上(而不局限于運行在云端服務器);另一方面,大模型運行在終端設備上也會給用戶帶來很大的價值。因此,我們認為在未來幾年內,大模型將會越來越多地運行在終端設備上,而這也會推動相關芯片技術和行業的進一步發展。
智能汽車是大模型運行在終端的第一個重要市場。從應用角度來看,大模型運行在智能汽車的首要推動力就是大模型確實能給智能駕駛相關的任務帶來客觀的性能提升。去年,以BEVformer為代表的端到端鳥瞰攝像頭大模型可以說是大模型在智能汽車領域的第一個里程碑,它把多個攝像頭的視頻流直接輸入使用transformer模塊的大模型做計算,最后的性能比之前使用傳統卷積神經網絡(CNN)模型的結果好了接近10個點,這個可謂是革命性的變化。而在上個月召開的CVPR上,商湯科技發布的UniAD大模型更是使用單個視覺大模型在經過統一訓練后去適配多個不同的下游任務,最后在多個任務中都大大超越了現有最好的模型:例如,多目標跟蹤準確率超越了20%,車道線預測準確率提升 30%,預測運動位移和規劃的誤差則分別降低了 38% 和 28%。
目前,汽車企業(尤其是造車新勢力)已經在積極擁抱這些智能汽車的大模型,BEVformer(以及相關的模型)已經被不少車企使用,我們預計下一代大模型也將會在未來幾年逐漸進入智能駕駛。如果從應用角度考慮,智能汽車上的大模型必須要在終端設備上運行,因為智能汽車對于模型運行的可靠性和延遲要求非常高,在云端運行大模型并且使用網絡把結果傳送到終端無法滿足智能汽車的需求。
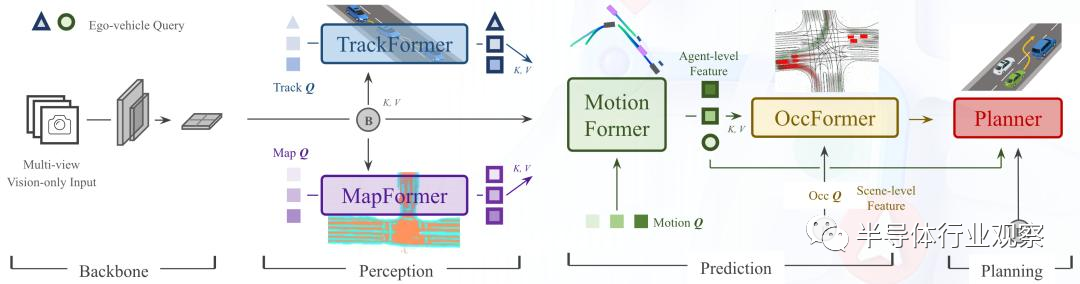
商湯科技提出的UniAD大模型架構,使用統一模型去適配多個任務
除了智能汽車之外,手機也是大模型進入終端的另一個重要市場。以ChatGPT為代表的語言類大模型事實上已經成為了下一代用戶交互的重要組成部分,因此在手機上使用大語言模型將會能把這樣的新用戶交互體驗帶入手機操作系統中。而在手機設備終端直接運行大語言模型的主要好處在于能夠在保護用戶隱私的情況下給用戶帶來個性化的體驗(例如歸納和某個用戶的聊天記錄等等)。目前,開源社區已經可以把Llama大語言模型能夠運行在安卓手機上CPU,回答一個問題大約需要5-10秒的時間,我們認為未來的潛力巨大。
智能汽車芯片加速大模型:算力與功耗成為關鍵
目前,人工智能已經在智能汽車的輔助駕駛應用中得到了廣泛應用,因此大多數智能汽車上使用的芯片也有對于人工智能的支持,例如加入人工智能加速器等。然而,這些人工智能加速器主要考慮的加速對象模型仍然是上一代以卷積神經網絡為代表的模型,這些模型往往參數量比較小,對于算力的需求也比較低。
為了適配下一代大模型,智能汽車芯片會有相應的改動。下一代大模型對于智能汽車芯片的要求主要包括:
| 1 | 大算力:由于智能汽車上的相關感知和規劃任務都必須在實時完成,因此相關芯片必須能夠提供足夠的算力來支持這樣的計算 |
|---|---|
| 2 | 低功耗:智能汽車上的計算功耗仍然有限制,考慮到散熱等因素,芯片不可能做到像GPU一樣有幾百瓦的功耗 |
| 3 | 合理的成本:智能汽車上的芯片不能像GPU一樣成本高達數千美元。因此,智能汽車上的大模型加速芯片主要考慮的就是如何在功耗和成本的限制下,實現盡可能高的算力。 |
我們可以從目前最成功的大模型加速芯片(即GPU)出發去推測支持大模型智能汽車芯片的具體架構,考慮GPU上有哪些設計思路需要進一步發揚光大,另外有哪些應該考慮重新設計。
首先,GPU上有海量的矩陣計算單元,這些計算單元是GPU算力的核心支撐(與之相對的,CPU上缺乏這些海量的矩陣計算單元因此算力無論如何不可能高上去),這些計算單元在智能汽車芯片上同樣也是必須的;但是由于智能汽車芯片上的計算不用考慮GPU上對于數據流和算子通用性的支持,因此智能汽車芯片上無需做GPU上這樣的大量stream core,因此從控制邏輯的角度可以做簡化以減少芯片面積成本。
第二,GPU能成功運行大模型的另一個關鍵在于有超高速的內存接口和海量的內存,因為目前大模型的參數量動輒千億級,這些模型必須有相應的內存支持。這一點在智能車芯片上同樣需要,只是智能汽車芯片未必能使用GPU上的HBM這樣的超高端(同時也是高成本)內存,而是會考慮和架構協同設計來盡可能地利用LPDDR這樣的接口的帶寬。
第三,GPU有很好的規模化和分布式計算能力,當模型無法在一個GPU上裝下時,GPU可以方便地把模型分割成多個子模型在多個GPU上做計算。智能車芯片也可以考慮這樣的架構,從而確保汽車可以在使用周期內滿足日新月異的模型的需求。
綜合上述考慮,我們推測針對大模型的智能車芯片架構中,可能會有多個人工智能加速器同時運行,每個加速器都有簡單的設計(例如一個簡單的控制核配合大量計算單元),搭配大內存和高速內存接口,并且加速器之間通過高速互聯互相通信從而可以以本地分布計算的方法來加速大模型。從這個角度,我們認為智能駕駛芯片中的內存和內存接口將會扮演決定性的角色,而另一方面,這樣的架構也非常適合使用chiplet的方式來實現每個加速器并且使用高級封裝技術(包括2.5D和3D封裝)來完成多個加速器的整合,換句話說大模型在智能汽車的應用將會進一步推動下一代內存接口和高級封裝技術的普及和演進。
大模型將會推動手機內存和AI加速器革新
如前所述,大模型進入手機將會把下一代用戶交互范式帶入手機。我們認為,大模型進入手機將會是一個漸進的過程:例如,目前的大語言模型,即使是小版本的Llama 70億參數的模型,也沒法完全裝入手機的內存中,而必須部分放在手機的閃存中運行,這就導致了運行速度比較慢。在未來的幾年中,我們認為手機上面的大語言模型會首先從更小的版本(例如10億參數以下的模型)開始進入應用,然后再逐漸增大參數量。
從這個角度來看,手機上運行大模型仍然會加速推動手機芯片在相關領域的發展,尤其是內存和AI加速器領域——畢竟目前主流運行在手機上的模型參數量都小于10M,大語言模型的參數量大了兩個數量級,而且未來模型參數量會快速增大。這一方面將會推動手機內存以及接口技術以更快的速度進化——為了滿足大模型的需求,未來我們可望會看到手機內存芯片容量增長更快,而且手機內存接口帶寬也會加快發展速度,因為目前來看內存實際上是大模型的瓶頸。
除了內存之外,手機芯片上的人工智能加速器也會為了大模型而做出相關的改變。目前手機芯片上的人工智能加速器(例如各種NPU IP)幾乎已經是標配,但是這些加速器的設計基本上是針對上一代卷積神經網絡設計,因此在設計上并不完全針對大模型。為了適配大模型,人工智能加速器首先必須能有更大的內存訪問帶寬并減少內存訪問延遲,這一方面需要人工智能加速器的接口上做出一些改變(例如分配更多的pin給內存接口),另一方面需要片上數據互聯做出相應的改變來滿足人工智能加速器訪存的需求。
除此之外,在加速器內部邏輯設計上,我們認為可能會更加激進地推進低精度量化計算(例如4bit甚至2bit)和稀疏計算,目前的學術界研究表明大語言模型有較大的機會可以做這樣的低精度量化/稀疏化,而如果能量化到例如4bit的話,就會大大減小相關計算單元需要的芯片面積,同時也能減小模型在內存中需要的空間(例如4bit量化精度相對于之前的標準8bit精度就會內存需求減半),這預計也會是未來針對手機端人工智能加速器的設計方向。
根據上述分析,我們預計從市場角度手機內存芯片將會借著手機大模型的東風變得更重要,預計會在未來看到相比之前更快的發展,包括大容量內存以及高速內存接口。另一方面,手機端人工智能加速器IP也會迎來新的需求和發展,我們預計相關市場會變得更加熱鬧一些。
審核編輯:劉清
-
半導體
+關注
關注
334文章
27515瀏覽量
219791 -
人工智能
+關注
關注
1792文章
47425瀏覽量
238957 -
智能汽車
+關注
關注
30文章
2870瀏覽量
107363 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11882 -
ChatGPT
+關注
關注
29文章
1564瀏覽量
7814
原文標題:大模型走向終端,芯片怎么辦?
文章出處:【微信號:光刻人的世界,微信公眾號:光刻人的世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
拋棄8GB內存,端側AI大模型加速內存升級

英偉達AI加速器新藍圖:集成硅光子I/O,3D垂直堆疊 DRAM 內存

IBM與AMD攜手部署MI300X加速器,強化AI與HPC能力
IBM將在云平臺部署AMD加速器
AMD Alveo V80計算加速器網絡研討會
SiFive發布MX系列高性能AI加速器IP
KAIST開發出高性能人工智能加速器技術
美國限制向中東AI加速器出口,審查國家安全
Arm推動生成式AI落地邊緣!全新Ethos-U85 AI加速器支持Transformer 架構,性能提升四倍






 工商網監
工商網監
評論