 飛速發展的HBM仍面臨著一些挑戰
飛速發展的HBM仍面臨著一些挑戰
飛速發展的HBM仍面臨著一些挑戰。
高帶寬內存 (HBM) 正在成為超大規模廠商的首選內存,但其在主流市場的最終命運仍存在疑問。雖然它在數據中心中已經很成熟,并且由于人工智能/機器學習的需求而使用量不斷增長,但其基本設計固有的缺陷阻礙了更廣泛的采用。一方面,HBM提供緊湊的 2.5D 外形尺寸,可大幅減少延遲。
Rambus產品營銷高級總監Frank Ferro在本周的 Rambus 設計峰會上的演講中表示:“HBM 的優點在于,您可以在很小的占地面積內獲得所有這些帶寬,而且還可以獲得非常好的能效。”
缺點是它依賴昂貴的硅中介層和 TSV 來運行。
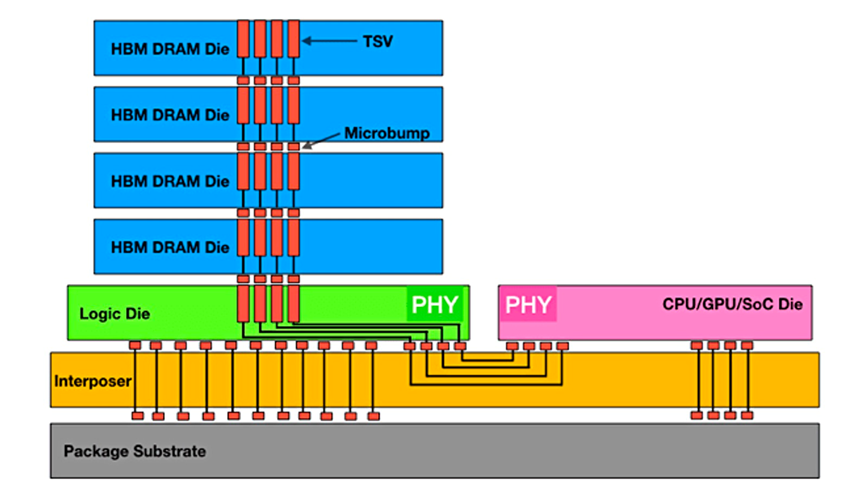
圖 1:實現最大數據吞吐量的 HBM 堆棧。來源:Rambus
CadenceIP 團隊產品營銷總監 Marc Greenberg 表示:“目前困擾高帶寬內存的問題之一是成本。”。“三維堆疊的成本很高。在堆疊芯片的底部有一個邏輯芯片,這是需要額外付出的硅片。然后是硅中介層,它位于 CPU 或 GPU 以及 HBM 存儲器的下方。這些都需要成本。然后,你需要更大的封裝等等。這些系統成本使 HBM 現在已經脫離了消費領域,而更多地應用于服務器機房或數據中心。相比之下,GDDR6等顯存雖然性能不如 HBM,但成本卻低得多。實際上,GDDR6的單位成本性能比 HBM 好得多,但 GDDR6 設備的最大帶寬卻比不上 HBM 的最大帶寬。"
Greenberg表示,這些差異為公司選擇 HBM 提供了理由,即使HBM可能不是他們的第一選擇。“HBM 提供了大量的帶寬,并且點對點傳輸的能量極低。使用 HBM 是因為必須這樣做,沒有其他解決方案可以提供相同的帶寬或相同的功率配置文件。”
HBM 只會變得越來越快。“我們預計 HBM3 Gen3 的帶寬將提高 50%,”美光計算產品事業部副總裁兼總經理 Praveen Vaidyanathan 說道。“從美光的角度來看,我們預計 HBM3 Gen2 產品將在 2024 財年期間實現量產。我們預計, 2024年年初將開始為預期的數億美元收入機會做出貢獻。此外,我們預測美光的 HBM3 將貢獻比 DRAM 更高的利潤。”
盡管如此,經濟因素可能會迫使許多設計團隊考慮價格敏感應用的替代方案。
他指出:"如果可以將問題細分為更小的部分,可能會發現HBM更具成本效益。例如,當必須在一個硬件上執行所有這些操作,而且必須在那里擁有 HBM,也許可以將其分成兩部分,讓兩個進程并行運行,也許連接到 DDR6。如果能將問題細分為更小的部分,就有可能以更低的成本完成相同的計算量。但是,如果你需要巨大的帶寬,如果你能承受成本,那么 HBM 就是你的最佳選擇。”
散熱挑戰
另一個主要缺點是 HBM 的 2.5D 結構會產生熱量,而靠近 CPU 和 GPU 的布局又會加劇這種情況。事實上,當前的布局就不太合理,因為當前的布局是將 HBM 及其堆疊的熱敏 DRAM 放在計算密集型熱源附近。
“最大的挑戰是熱量,”Greenberg說。"一個 CPU會產生大量的數據。每秒要通過這個接口傳輸太比特的數據。即使每筆數據交換只產生少量的微焦耳,每秒也要處理十億次,因此 CPU 的溫度非常高。而且,CPU 的工作不僅僅是轉移數據,它還必須進行計算。除此之外,最不耐熱的半導體元件是 DRAM。它在 85°C 左右開始遺失數據,而在 125°C 左右就會完全無法存儲。”
有一點值得慶幸。“擁有 2.5D 堆棧的優點是,CPU 很熱,而 HBM 位于 CPU 旁邊,因此喜歡冷,之間有一定的物理隔離,”他說。
在延遲和熱量之間的權衡中,延遲是不可變的。“我沒有看到任何人愿意放棄優化延遲,”Synopsys 內存接口 IP 解決方案產品線總監 Brett Murdock說道。“我看到他們推動物理團隊尋找更好的冷卻方式,或者更好的放置方式,以保持較低的延遲。”
考慮到這一挑戰,多物理場建模可以提出減少熱問題的方法,但會產生相關成本。“這就是物理學變得非常困難的地方,” Ansys產品經理 Marc Swinnen 說。“功率可能是集成所能實現的最大限制因素。任何人都可以設計一堆芯片并將它們全部連接起來,所有這些都可以完美工作,但無法冷卻它。散發熱量是可實現目標的根本限制。”
潛在的緩解措施可能很快就會變得昂貴,從微流體通道到浸入非導電液體,再到確定散熱器上需要多少個風扇,以及是否使用銅或鋁。
可能永遠不會有完美的答案,但模型和對期望結果的清晰理解可以幫助創建合理的解決方案。“必須定義最佳對你來說意味著什么,”Swinnen說。“你想要最好的熱量嗎?最好的成本?兩者之間的最佳平衡?你將如何衡量它們?答案依賴于模型來了解物理學中實際發生的情況。它依靠人工智能來處理這種復雜性并創建元模型來捕捉這個特定優化問題的本質,并快速探索這個廣闊的空間。”
HBM 和 AI
雖然計算是AI/ML最密集的部分,但如果沒有良好的內存架構,這一切都無法實現。存儲和檢索萬億次計算需要內存。事實上,增加 CPU 并不能提高系統性能,因為內存帶寬不足以支持這些 CPU。這就是臭名昭著的 "內存墻 "瓶頸。
Quadric首席營銷官 SteveRoddy 表示,從最廣泛的定義來看,機器學習只是曲線擬合。“在訓練運行的每次迭代中,你都在努力越來越接近曲線的最佳擬合。這是一個 X,Y 圖,就像高中幾何一樣。大型語言模型基本上是同一件事,但是是 100 億維,而不是 2 維。”
因此,計算相對簡單,但內存架構可能令人難以置信。
Roddy 解釋說:“其中一些模型擁有 1000 億字節的數據,對于每次重新訓練迭代,都必須通過數據中心的背板從磁盤上取出1000 億字節的數據并放入計算箱中。在兩個月的訓練過程中,你必須將這組巨大的內存值來回移動數百萬次。限制因素是數據的移入和移出,這就是為什么人們對 HBM 或光學互連等從內存傳輸到計算結構的東西感興趣。所有這些都是人們投入數十億美元風險投資的地方,因為如果能縮短距離或時間,就可以大大簡化和縮短訓練過程,無論是切斷電源還是加快訓練速度。”
出于所有這些原因,高帶寬內存被認為是 AI/ML 的首選內存。“它提供了某些訓練算法所需的最大帶寬,”Rambus 的 Ferro 說。“從你可以擁有多個內存堆棧的角度來看,它是可配置的,這為你提供了非常高的帶寬。”
這就是人們對 HBM 如此感興趣的原因。“我們的大多數客戶都是人工智能客戶,”Synopsys 的默多克說。“他們正在 LPDDR5X 接口和HBM 接口之間進行一項重大的基本權衡。唯一阻礙他們的是成本。”然而,人工智能的需求如此之高,以至于 HBM 減少延遲的前沿特征突然顯得過時且不足。這反過來又推動了下一代 HBM 的發展。
“延遲正在成為一個真正的問題,”Ferro說。“在 HBM 的前兩代中,我沒有聽到任何人抱怨延遲。現在我們一直收到有關延遲的問題。”Ferro 建議,鑒于當前的限制,了解數據尤為重要。“它可能是連續的數據,例如視頻或語音識別。它可能是事務性的,就像財務數據一樣,可能非常隨機。如果知道數據是隨機的,那么設置內存接口的方式將與流式傳輸視頻不同。這些是基本問題,但也有更深層次的問題。我要在存儲中使用的字長是多少?內存的塊大小是多少?對此了解得越多,設計系統的效率就越高。如果了解它,那么就可以定制處理器以最大限度地提高計算能力和內存帶寬。我們看到越來越多的 ASIC 式 SoC 正在瞄準特定市場細分市場,以實現更高效的處理。”
降低成本
如果經典的 HBM 實現是使用硅中介層,那么就有希望找到成本更低的解決方案。“還有一些方法可以在標準封裝中嵌入一小塊硅,這樣就沒有一個完整的硅中介層延伸到所有東西下面,”格林伯格說。“CPU 和 HBM 之間只有一座橋梁。此外,在標準封裝技術上允許更細的引腳間距也取得了進展,這將顯著降低成本。還有一些專有的解決方案,人們試圖通過高速 SerDes 類型連接來連接存儲器,沿著 UCIE 的路線,并可能通過這些連接來連接存儲器。目前,這些解決方案是專有的,但我希望它們能夠標準化。”
Greenberg表示,可能存在平行的發展軌跡:“硅中介層確實提供了盡可能細的引腳間距或線間距——基本上是用最少的能量實現最大的帶寬——所以硅中介層將永遠存在。但如果一個行業能夠聚集在一起并決定一個適用于標準封裝的內存標準,那么就有可能提供類似的帶寬,但成本卻要低得多。”
人們正在不斷嘗試降低下一代的成本。“臺積電已宣布他們擁有三種不同類型的中介層,”Ferro 說。“他們有一個 RDL 中介層,他們有硅中介層,他們有一些看起來有點像兩者的混合體。還有其他技術,例如如何完全擺脫中介層。可能會在接下來的 12 或 18 個月內看到一些如何在頂部堆疊 3D 內存的原型,理論上可以擺脫中介層。”
解決該問題的另一種方法是使用較便宜的材料。“正在研究非常細間距的有機材料,以及它們是否足夠小以處理所有這些痕跡,”Ferro說。“此外,UCIe是通過更標準的材料連接芯片的另一種方式,以節省成本。但同樣,仍然必須解決通過這些基材的數千條痕跡的問題。”
Murdock希望通過規模經濟來削減成本。“隨著 HBM 越來越受歡迎,成本方面將有所緩解。HBM 與任何 DRAM 一樣,歸根結底都是一個商品市場。在中介層方面,我認為下降速度不會那么快。這仍然是一個需要克服的挑戰。”
但原材料成本并不是唯一的考慮因素。“這還取決于 SoC 需要多少帶寬,以及電路板空間等其他成本,”Murdock 說。“對于那些想要高速接口并需要大量帶寬的人來說,LPDDR5X 是一種非常受歡迎的替代方案,但與 HBM 堆棧的通道數量相匹配所需的 LPDDR5X 通道數量相當大。雖然有大量的設備成本和電路板空間成本,這些成本可能令人望而卻步。僅就美元而言,也可能是一些物理限制促使人們轉向 HBM,盡管從美元角度來看它更昂貴。”
其他人對未來成本削減則不太確定。Objective Analysis 首席分析師 Jim Handy 表示:“降低HBM 成本將是一項挑戰。由于將 TSV 放置在晶圓上的成本很高,因此加工成本已經明顯高于標準 DRAM。這使得它無法擁有像標準 DRAM 一樣大的市場。由于市場較小,規模經濟導致成本在一個自給自足的過程中更高。體積越小,成本越高,但成本越高,使用的體積就越少。沒有簡單的方法可以解決這個問題。”
盡管如此,Handy 對 HBM 的未來持樂觀態度,并指出與 SRAM 相比,它仍然表現出色。“HBM 已經是一個成熟的 JEDEC 標準產品,”他說。“這是一種獨特的 DRAM 技術形式,能夠以比 SRAM 低得多的成本提供極高的帶寬。它還可以通過封裝提供比 SRAM 更高的密度。它會隨著時間的推移而改進,就像 DRAM 一樣。隨著接口的成熟,預計會看到更多巧妙的技巧來提高其速度。”
事實上,盡管面臨所有挑戰,HBM 還是有理由保持樂觀。“標準正在迅速發展,” Ferro補充道。“如果你看看 HBM 如今的發展,會發現它大約以兩年為間隔,這確實是一個驚人的速度。”
審核編輯:劉清
-
DRAM芯片
+關注
關注
1文章
84瀏覽量
18016 -
人工智能
+關注
關注
1791文章
47279瀏覽量
238513 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646 -
TSV技術
+關注
關注
0文章
17瀏覽量
5680 -
HBM
+關注
關注
0文章
380瀏覽量
14761
原文標題:HBM 的未來:必要但昂貴
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Chiplet技術革命:解鎖半導體行業的未來之門

機器視覺要面臨的挑戰及其解決方法
2024存儲市場冰火交織,時創意電子如何應對挑戰與機遇
用國產化硬件守護信息安全,飛騰D2000網絡安全主板應用優勢
節能回饋式負載技術創新與發展
偉創力談制造業面臨的挑戰和發展趨勢
三星芯片復興之路:半導體業務飆升與HBM挑戰并存
液態金屬鎵的罐裝與包裝過程正面臨著從傳統向智能化轉型

NFC風險如何?安全便捷,風險無憂
蘋果AI服務在華面臨挑戰,尋求本土合作新機遇
vivo印度子公司面臨本土化挑戰,與Tata洽談多數股份收購
高速串行信號測試時注意事項有哪些
自動駕駛發展問題及解決方案淺析
國產光耦2024:發展機遇與挑戰全面解析






 工商網監
工商網監
評論