 HaluEval數據集的構建過程分析
HaluEval數據集的構建過程分析
一、背景
最近,大語言模型(Large Language Models, LLMs)的快速發展帶來了自然語言處理領域的范式轉變,在各類任務上的優秀表現引發了眾多關注。然而,在自然語言社區迎接和擁抱大語言模型時代的同時,也迎來了一些屬于大模型時代的新問題,其中大模型的幻象問題(Hallucination in LLMs)是最具代表性的問題之一。大語言模型的幻象問題是指其生成的內容要么與現有的內容有沖突,要么無法通過已有的事實或知識進行驗證。圖1是一個大模型生成的文本中包含幻象的例子,當用戶詢問大模型兩磅羽毛和一磅磚頭哪個更重時,模型給出的答案自相矛盾,首先回答二者一樣重,然后又說兩磅比一磅重。這也就是眾多用戶在與大模型交互過程中遇到的,大模型會“一本正經的胡說八道”的現象。對用戶來說,大模型生成文本的可信度是一項非常重要的指標。如果生成的文本無法信任,則會嚴重影響大模型在現實世界中的應用。
為了進一步研究大模型幻象的內容類型和大模型生成幻象的原因,本文提出了用于大語言模型幻象評估的基準——HaluEval。我們基于現有的數據集,通過自動生成和手動標注的方式構建了大量的幻象數據組成HaluEval的數據集,其中包含特定于問答、對話、文本摘要任務的30000條樣本以及普通用戶查詢的5000條樣本。在本文中,我們詳細介紹了HaluEval數據集的構建過程,對構建的數據集進行了內容分析,并初步探索了大模型識別和減少幻象的策略。
二、HaluEval Benchmark
數據構建
HaluEval包含35000條帶幻象的樣本和對應的正確樣本用于大模型幻象的評估。為了生成幻象數據集,我們設計了自動生成和人工標注兩種構建方式。對于特定于問答、基于知識的對話和文本摘要三類任務的樣本,我們采用自動生成的構建方式;對于一般的用戶查詢數據,我們采用人工標注的構建方式。
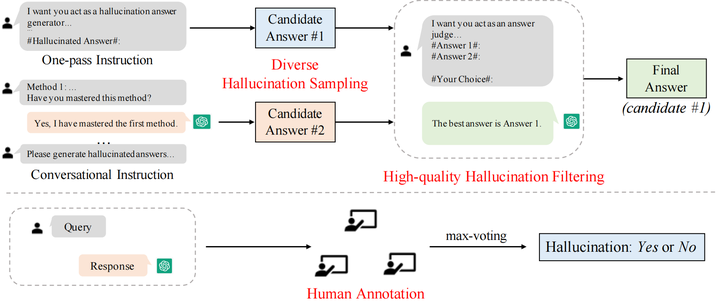
圖2 HaluEval的構建方法
自動生成
HaluEval中基于任務的樣本共有30000條,其中問答、基于知識的對話和文本摘要各有10000條,分別基于現有的數據集HotpotQA,OpenDialKG, CNN/Daily Mail作為種子數據進行采樣生成。
對于自動生成,我們設計了先采樣后過濾的兩步生成框架,包括多樣化的幻象采樣和高質量的幻象過濾兩個步驟。
多樣化的幻象采樣 為了在采樣指令中給出條理的幻象生成方法,針對三類任務,我們參考現有的工作將幻象分為不同類型,并向模型輸入各個類別幻象介紹作為生成幻象樣本的方法。對于問答任務,將幻象分為comprehension、factualness、specificity和inference四種類型;對于基于知識的問答任務,將幻象分為extrinsic-soft,、extrinsic-hard和 extrinsic-grouped三類;對于文本摘要任務,將幻象分為factual、non-factual和intrinsic三類。考慮到生成的幻象樣本可以有不同的類型,我們提出了兩種采樣方法來生成幻象。如圖2所示,第一種方法采用單指令模式(one-pass instruction),我們直接將包含所有生成幻象方法的完整的指令輸入ChatGPT,然后得到生成的幻象答案;第二種方法采用對話式的指令(conversational instruction),每輪對話輸入一種生成幻象的方法,確保ChatGPT掌握了每一類方法,最后根據學到的指令生成給定問題的幻象答案。使用兩種策略進行采樣,每個問題可以得到兩個候選的幻象答案。
高質量的幻象過濾 為了得到更加合理和具有挑戰性的幻象樣本,我們對采樣得到的兩個候選答案進行過濾。為了提高過濾質量,我們在幻象過濾指令中加入樣本過濾的示例。與對兩個幻象答案進行過濾不同,過濾指令中的示例包含正確答案和幻象答案,我們選擇正確答案作為過濾結果;然后輸入測試樣本的兩個候選幻象答案讓模型進行選擇,期望ChatGPT選擇更加接近真實答案的幻象答案來增強過濾效果。通過進一步的過濾,得到的幻象答案更加難以識別。我們收集過濾得到的更具挑戰性的候選樣本作為最終的幻象樣本。
在先采樣后過濾的自動生成框架中,關鍵在于設計有效的指令來生成和過濾幻象答案。在我們的設計中,幻象的采樣指令包括意圖描述、幻象模式和幻象示例三部分,圖3為問答任務的采樣指令,其中藍色部分表示意圖描述,紅色部分為幻象模式,綠色部分為幻象示例;幻象的過濾指令包括意圖描述和過濾示例兩部分,圖4為問答任務的幻象過濾指令,其中藍色部分表示意圖描述,綠色部分為過濾示例。

圖3 問答任務的幻象采樣指令
 圖4 問答任務的幻象過濾指令
圖4 問答任務的幻象過濾指令
人工標注
對于一般的用戶查詢,我們采用人工標注的方法構建數據。我們邀請三位專家對來自Alpaca數據集的普通用戶查詢和ChatGPT回復進行人工標注,判斷ChatGPT的回復中是否包含幻象并標注包含幻象的片段。在進行人工標注之前,為了篩選出更有可能產生幻覺的用戶查詢,我們首先設計了一個預選程序。具體來說,我們使用 ChatGPT 對每個用戶查詢生成三個響應,然后使用 BERTScore 計算它們的平均語義相似度,最終保留了 5000 個相似度最低的用戶查詢。如圖2所示,篩選出來的每個樣本由三個專家進行標記,標注者從三個方面判斷回復中是否包含幻象并標注幻象所在位置:unverifiable,、non-factual和irrelevant,我們最終采用最大投票策略來確定回復中是否包含幻象。
基準使用
為了幫助大家更好地使用HaluEval,我們提出了使用HaluEval來進行大模型幻象研究的三個可能的方向。
基于HaluEval中生成和注釋的幻象樣本,研究人員可以分析大模型產生幻象的查詢屬于什么主題;
HaluEval可以用于評估大模型識別幻象的能力,例如給定一個問題及答案,要求大模型判斷答案中是否包含幻象;
HaluEval包含正確樣本和幻象樣本,因此也可用于評估大模型的輸出是否包含幻象。
三、實驗
在實驗部分,為了測試大模型在HaluEval上的幻象識別表現,我們使用所構造的HaluEval,在davinci、text-davinci-002、text-davinci-003和gpt-3.5-turbo四個模型上進行了幻象識別實驗,并針對實驗結果進行了詳細分析,最后提出了一些可能對提高識別效果有用的策略。
幻象識別實驗
在幻象識別實驗中,對于每一個測試樣本我們以50%的概率從幻象答案和正確答案中選擇一個作為測試答案,將問題與測試答案一起輸入模型,讓模型判斷測試答案中是否包含幻象。如圖5所示,類似于幻象生成和過濾的步驟,我們設計了用于幻象識別的指令,包括意圖描述、幻象模式和幻象識別示例,并在上述四個模型上進行測試。表1中展示了四個模型在幻象識別任務上的準確率。

圖5 問答任務的幻象識別指令
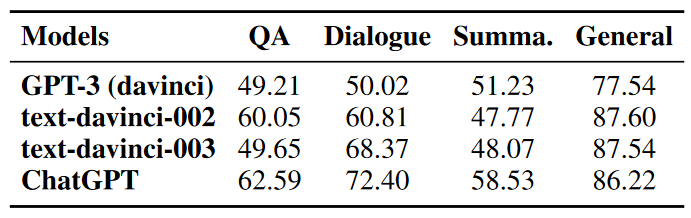
表1 幻象識別實驗結果
實驗結果表明,LLM在識別文本中的幻象這一任務上表現不佳,ChatGPT在文本摘要任務上僅達到58.53%的準確率,與50%的隨機概率相差不大;而其他模型例如GPT-3在問答、對話和摘要任務上的準確率幾乎都在50%左右。
為了進一步分析ChatGPT沒有檢測出的幻象樣本,我們使用LDA對所有的測試樣本和檢測失敗樣本進行聚類,并對聚類得到的主題進行可視化。我們將各個數據集的測試數據聚類為10個主題,并將其中檢測失敗的主題標記為紅色,如圖6所示。從聚類結果來看,我們發現LLM無法識別的幻象集中在幾個特定的主題。例如QA中的電影、公司、樂隊;對話中的書籍、電影、科學;摘要中的學校、政府、家庭;普通用戶查詢中的技術、氣候和語言等話題。
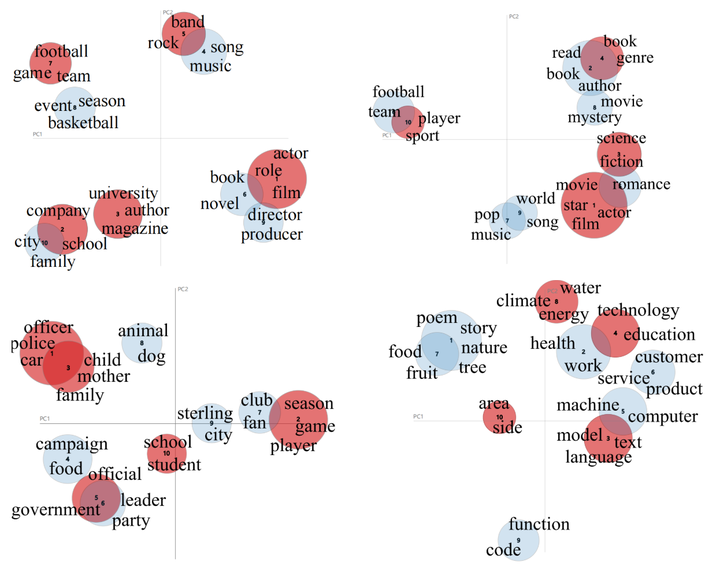
圖6 主題聚類
提升策略
鑒于現有的LLM在幻象識別方面表現欠佳,我們嘗試提出幾種策略來提升大模型識別幻象的能力,包括知識檢索、思維鏈推理和樣本對比。我們使用提出的三種策略在ChatGPT上重新進行幻象識別實驗,下表為使用各個策略后ChatGPT的幻象識別準確率。
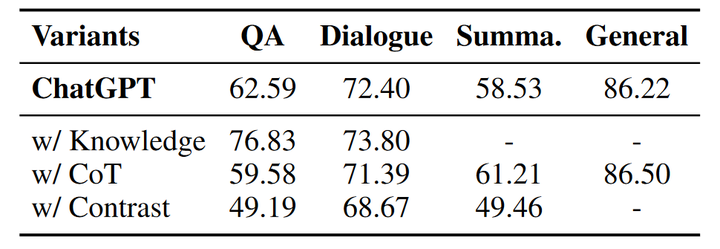
表2 幻象識別能力提升策略實驗結果
知識檢索
知識檢索是一個廣泛使用的用于減少幻象的手段。在幻象檢測實驗中,我們向ChatGPT提供在Wikipedia檢索到的相關事實知識(除了摘要任務),并在指令中要求ChatGPT根據給定知識和問題判斷答案中是否包含幻象。通過向模型提供相關的事實知識,幻象的識別準確率有較為明顯的提升,尤其是在問答任務中,準確率從62.59%提升到了76.83%;對話任務也有小幅度的提升。因此,為LLM提供外部知識可以很大程度上增強其識別幻象的能力。
CoT推理
思維鏈(chain-of-thought)推理是一種通過使LLM加入中間步驟進行推理來獲得最終結果的手段,之前的工作在一些數學問題和邏輯問題中引入思維鏈,能夠明顯提升模型解決問題的能力。在幻象識別實驗中,我們同樣引入思維鏈推理進行嘗試,在識別指令中要求模型逐步生成推理步驟最終得到識別結果。然而和知識檢索相比,在輸出中添加思維鏈并沒有提高模型識別幻象的能力,反而在部分任務上準確率有所下降。與知識檢索相比,思維鏈推理并不能為模型提供顯式的外部知識,反而有可能會干擾最終的判斷。
樣本對比
我們進一步為模型同時提供正確答案和幻象答案來測試模型是否具備區分正確樣本和幻象樣本的能力。表中的實驗結果顯示提供正確樣本使得幻象識別的準確率有較大的下降,這可能是由于生成的幻象答案與真實答案有很高的相似性,也進一步說明了HaluEval的幻象識別對LLM來說具有很大的挑戰性。
四、總結
本文引入了大型語言模型幻象評估基準——HaluEval,這是一個大規模的自動生成的和人工注釋的幻象樣本集合,用于評估大語言模型在識別幻象方面的表現。首先我們介紹了HaluEval的構建過程,包含自動生成和人工標注。為了自動生成幻象樣本,我們提出先采樣后過濾的兩步生成框架;人工標注部分我們請專家針對用戶查詢的回復進行標注。基于HaluEval,我們評估了四個大模型在識別幻象方面的表現,分析了幻象識別實驗的結果,并且提出了三個提升幻想識別能力的策略。基于在HaluEval上的測評實驗,我們得出以下結論:
ChatGPT很可能會編造無法核實的信息,從而在一些特定主題中產生幻覺內容。
現有的大語言模型在識別文本中的幻覺方面面臨著巨大的挑戰。
可以通過提供外部知識或增加推理步驟來提高幻覺識別的準確率。
總之,我們提出的HaluEval基準能夠幫助分析大模型生成幻象的內容,也可用于大模型幻象識別和減輕的研究,為未來建立更加安全可靠的LLM鋪平了道路。
審核編輯:劉清
-
過濾器
+關注
關注
1文章
429瀏覽量
19614 -
LDA
+關注
關注
0文章
29瀏覽量
10608 -
ChatGPT
+關注
關注
29文章
1561瀏覽量
7671
原文標題:幻象 or 事實 | HaluEval:大語言模型的幻象評估基準
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問NanoEdge AI數據集該如何構建?
怎么刪除分析中的“Ghost”數據集
高階API構建模型和數據集使用

WSN中能量有效的連通支配集構建算法
如何利用Dataloder來處理加載數據集

如何構建高質量的大語言模型數據集
大模型數據集:構建、挑戰與未來趨勢
宏集INSYS工業路由器構建可靠的水廠過程控制系統

宏集ASPION數據記錄器:分析運輸過程中的碰撞、沖擊和振動





 工商網監
工商網監
評論