") 英特爾一系列AI解決方案,為Llama 2大模型提供實(shí)力之選
英特爾一系列AI解決方案,為Llama 2大模型提供實(shí)力之選
英特爾廣泛的AI硬件組合及開放的軟件環(huán)境,為Meta發(fā)布的Llama 2模型提供了極具競爭力的選擇,進(jìn)一步助力大語言模型的普及,推動AI發(fā)展惠及各行各業(yè)。
大語言模型(LLM)在生成文本、總結(jié)和翻譯內(nèi)容、回答問題、參與對話以及執(zhí)行復(fù)雜任務(wù)(如解決數(shù)學(xué)問題或推理)方面表現(xiàn)出的卓越能力,使其成為最有希望規(guī)模化造福社會的AI技術(shù)之一。大語言模型有望解鎖更豐富的創(chuàng)意和洞察,并激發(fā)AI社區(qū)推進(jìn)技術(shù)發(fā)展的熱情。
Llama 2旨在幫助開發(fā)者、研究人員和組織構(gòu)建基于生成式AI的工具和體驗(yàn)。Meta發(fā)布了多個Llama 2的預(yù)訓(xùn)練和微調(diào)版本,擁有70億、130億和700億三種參數(shù)。通過Llama 2,Meta在公司的各個微調(diào)模型中采用了三項(xiàng)以安全為導(dǎo)向的核心技術(shù):安全的有監(jiān)督微調(diào)、安全的目標(biāo)文本提取以及安全的人類反饋強(qiáng)化學(xué)習(xí)(RLHF)。這些技術(shù)相結(jié)合,使Meta得以提高安全性能。隨著越來越廣泛的使用,人們將能夠以透明、公開的方式不斷識別并降低生成有害內(nèi)容的風(fēng)險(xiǎn)。
英特爾致力于通過提供廣泛的硬件選擇和開放的軟件環(huán)境,推動AI的發(fā)展與普及。英特爾提供了一系列AI解決方案,為AI社區(qū)開發(fā)和運(yùn)行Llama 2等模型提供了極具競爭力和極具吸引力的選擇。英特爾豐富的AI硬件產(chǎn)品組合與優(yōu)化開放的軟件相結(jié)合,為應(yīng)對算力挑戰(zhàn)提供了可行的方案。
英特爾提供了滿足模型的開發(fā)和部署的AI優(yōu)化軟件。開放生態(tài)系統(tǒng)是英特爾得天獨(dú)厚的戰(zhàn)略優(yōu)勢,在AI領(lǐng)域亦是如此。我們致力于培育一個充滿活力的開放生態(tài)系統(tǒng)來推動AI創(chuàng)新,其安全、可追溯、負(fù)責(zé)任以及遵循道德,這對整個行業(yè)至關(guān)重要。此次發(fā)布的大模型進(jìn)一步彰顯了我們的核心價值觀——開放,為開發(fā)人員提供了一個值得信賴的選擇。Llama 2模型的發(fā)布是我們行業(yè)向開放式AI發(fā)展轉(zhuǎn)型邁出的重要一步,即以公開透明的方式推動創(chuàng)新并助力其蓬勃發(fā)展。
--李煒
英特爾軟件與先進(jìn)技術(shù)副總裁
兼人工智能和分析部門總經(jīng)理
-- Melissa Evers
英特爾軟件與先進(jìn)技術(shù)副總裁
兼執(zhí)行戰(zhàn)略部總經(jīng)理
在Llama 2發(fā)布之際,我們很高興地分享70億和130億參數(shù)模型的初始推理性能測試結(jié)果。這些模型在英特爾AI產(chǎn)品組合上運(yùn)行,包括Habana?Gaudi?2 深度學(xué)習(xí)加速器、第四代英特爾?至強(qiáng)?可擴(kuò)展處理器、英特爾?至強(qiáng)?CPU Max系列和英特爾?數(shù)據(jù)中心GPU Max系列。我們在本文中分享的性能指標(biāo)是我們當(dāng)前軟件提供的“開箱即用”的性能,并有望在未來的軟件中進(jìn)一步提升。我們還支持700億參數(shù)模型,并將很快分享最新相關(guān)信息。
Habana?Gaudi?2 深度學(xué)習(xí)加速器
Habana Gaudi2旨在為用戶提供高性能、高能效的訓(xùn)練與推理,尤其適用于諸如Llama和Llama 2的大語言模型。Gaudi2加速器具備96GB HBM2E的內(nèi)存容量,可滿足大語言模型的內(nèi)存需求并提高推理性能。Gaudi2配備Habana?SynapseAI?軟件套件,該套件集成了對PyTorch和DeepSpeed的支持,以用于大語言模型的訓(xùn)練和推理。此外,SynapseAI近期開始支持HPU Graphs和DeepSpeed推理,專門針對時延敏感度高的推理應(yīng)用。Gaudi2還將進(jìn)行進(jìn)一步的軟件優(yōu)化,包括計(jì)劃在2023年第三季度支持FP8數(shù)據(jù)類型。此優(yōu)化預(yù)計(jì)將在執(zhí)行大語言模型時大幅提高性能、吞吐量,并有效降低延遲。
大語言模型的性能需要靈活敏捷的可擴(kuò)展性,來突破服務(wù)器內(nèi)以及跨節(jié)點(diǎn)間的網(wǎng)絡(luò)瓶頸。每張Gaudi2芯片集成了21個100Gbps以太網(wǎng)接口,21個接口專用于連接服務(wù)器內(nèi)的8顆Gaudi2,該網(wǎng)絡(luò)配置有助于提升服務(wù)器內(nèi)外的擴(kuò)展性能。
在近期發(fā)布的MLPerf基準(zhǔn)測試中,Gaudi2在大語言模型上展現(xiàn)了出色的訓(xùn)練性能,包括在384個Gaudi2加速器上訓(xùn)練1750億參數(shù)的GPT-3模型所展現(xiàn)的結(jié)果。Gaudi2經(jīng)過驗(yàn)證的高性能使其成為Llama和Llama 2模型訓(xùn)練和推理的高能效解決方案。
圖1顯示了70億參數(shù)和130億參數(shù)Llama 2模型的推理性能。模型分別在一臺Habana Gaudi2設(shè)備上運(yùn)行,batch size=1,輸出token長度256,輸入token長度不定,使用BF16精度。報(bào)告的性能指標(biāo)為每個token的延遲(不含第一個)。該測試使用optimum-habana文本生成腳本在Llama模型上運(yùn)行推理。optimum-habana庫能夠幫助簡化在Gaudi加速器上部署此類模型的流程,僅需極少的代碼更改即可實(shí)現(xiàn)。如圖1所示,對于128至2000輸入token,在70億參數(shù)模型上Gaudi2的推理延遲范圍為每token 9.0-12.2毫秒,而對于130億參數(shù)模型,范圍為每token 15.5-20.4毫秒1。
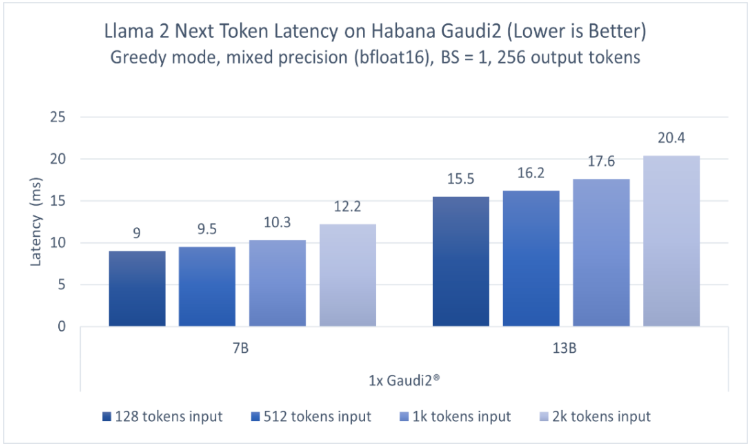
圖1基于Habana Gaudi2,70億和130億參數(shù)Llama 2模型的推理性能
若想訪問Gaudi2,可按照此處(https://developer.habana.ai/intel-developer-cloud/)在英特爾開發(fā)者云平臺上注冊一個實(shí)例,或聯(lián)系超微(Supermicro)了解Gaudi2服務(wù)器基礎(chǔ)設(shè)施。
英特爾?至強(qiáng)?可擴(kuò)展處理器
第四代英特爾至強(qiáng)可擴(kuò)展處理器是一款通用計(jì)算處理器,具有英特爾?高級矩陣擴(kuò)展(英特爾?AMX)的AI加速功能。具體而言,該處理器的每個核心內(nèi)置了BF16和INT8通用矩陣乘(GEMM)加速器,以加速深度學(xué)習(xí)訓(xùn)練和推理工作負(fù)載。此外,英特爾?至強(qiáng)?CPU Max系列,每顆CPU提供64GB的高帶寬內(nèi)存(HBM2E),兩顆共128GB,由于大語言模型的工作負(fù)載通常受到內(nèi)存帶寬的限制,因此,該性能對于大模型來說極為重要。
目前,針對英特爾至強(qiáng)處理器的軟件優(yōu)化已升級到深度學(xué)習(xí)框架中,并可用于PyTorch*、TensorFlow*、DeepSpeed*和其它AI庫的默認(rèn)發(fā)行版。英特爾主導(dǎo)了torch.compile CPU后端的開發(fā)和優(yōu)化,這是PyTorch 2.0的旗艦功能。與此同時,英特爾還提供英特爾?PyTorch擴(kuò)展包*(Intel?Extension for PyTorch*),旨在PyTorch官方發(fā)行版之前,盡早、及時地為客戶提供英特爾CPU的優(yōu)化。
第四代英特爾至強(qiáng)可擴(kuò)展處理器擁有更高的內(nèi)存容量,支持在單個插槽內(nèi)實(shí)現(xiàn)適用于對話式AI和文本摘要應(yīng)用的、低延遲的大語言模型執(zhí)行。對于BF16和INT8,該結(jié)果展示了單個插槽內(nèi)執(zhí)行1個模型時的延遲。英特爾?PyTorch擴(kuò)展包*支持SmoothQuant,以確保INT8精度模型具有良好的準(zhǔn)確度。
考慮到大語言模型應(yīng)用需要以足夠快的速度生成token,以滿足讀者較快的閱讀速度,我們選擇token延遲,即生成每個token所需的時間作為主要的性能指標(biāo),并以快速人類讀者的閱讀速度(約為每個token 100毫秒)作為參考。如圖2、3所示,對于70億參數(shù)的Llama2 BF16模型和130億參數(shù)的Llama 2 INT8模型,第四代英特爾至強(qiáng)單插槽的延遲均低于100毫秒2。
得益于更高的HBM2E帶寬,英特爾至強(qiáng)CPU Max系列為以上兩個模型提供了更低的延遲。而憑借英特爾AMX加速器,用戶可以通過更高的批量尺寸(batch size)來提高吞吐量。
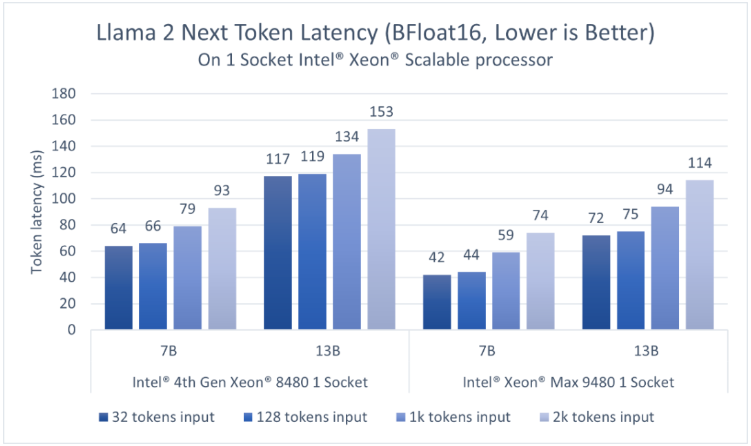
圖2 基于英特爾至強(qiáng)可擴(kuò)展處理器,70億參數(shù)和130億參數(shù)Llama 2模型(BFloat16)的推理性能
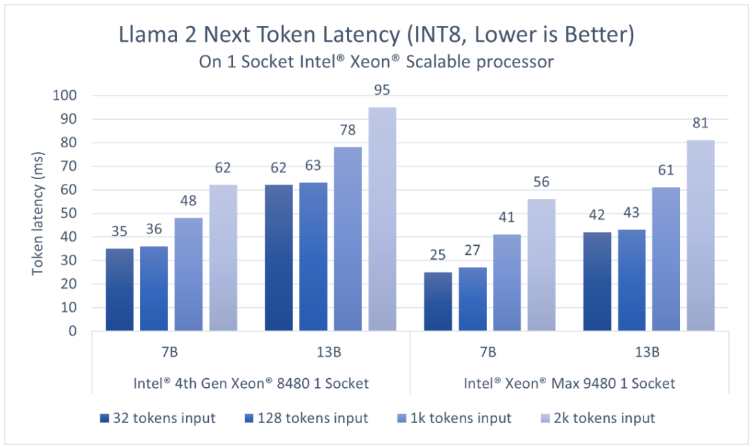
圖3 基于英特爾至強(qiáng)可擴(kuò)展處理器,70億參數(shù)和130億參數(shù)Llama 2模型(INT8)的推理性能
對于70億和130億參數(shù)的模型,每個第四代至強(qiáng)插槽可提供低于100毫秒的延遲。用戶可以分別在兩個插槽上同時運(yùn)行兩個并行實(shí)例,從而獲得更高的吞吐量,并獨(dú)立地服務(wù)客戶端。亦或者,用戶可以通過英特爾?PyTorch擴(kuò)展包*和DeepSpeed* CPU,使用張量并行的方式在兩個第四代至強(qiáng)插槽上運(yùn)行推理,從而進(jìn)一步降低延遲或支持更大的模型。
關(guān)于在至強(qiáng)平臺上運(yùn)行大語言模型和Llama 2,開發(fā)者可以點(diǎn)擊此處(https://intel.github.io/intel-extension-for-pytorch/llm/cpu/)了解更多詳細(xì)信息。第四代英特爾至強(qiáng)可擴(kuò)展處理器的云實(shí)例可在AWS和Microsoft Azure上預(yù)覽,目前已在谷歌云平臺和阿里云全面上線。英特爾將持續(xù)在PyTorch*和DeepSpeed*進(jìn)行軟件優(yōu)化,以進(jìn)一步加速Llama 2和其它大語言模型。
英特爾?數(shù)據(jù)中心GPU Max系列
英特爾數(shù)據(jù)中心GPU Max系列提供并行計(jì)算、科學(xué)計(jì)算和適用于科學(xué)計(jì)算的AI加速。作為英特爾性能最為出色、密度最高的獨(dú)立顯卡,英特爾數(shù)據(jù)中心GPU Max系列產(chǎn)品中封裝超過1000億個晶體管,并包含多達(dá)128個Xe內(nèi)核,Xe是英特爾GPU的計(jì)算構(gòu)建模塊。
英特爾數(shù)據(jù)中心GPU Max系列旨在為AI和科學(xué)計(jì)算中使用的數(shù)據(jù)密集型計(jì)算模型提供突破性的性能,包括:
●408 MB基于獨(dú)立SRAM技術(shù)的L2緩存、64MB L1緩存以及高達(dá)128GB的高帶寬內(nèi)存(HBM2E)。
●AI增強(qiáng)型的Xe英特爾?矩陣擴(kuò)展(英特爾?XMX)搭載脈動陣列,在單臺設(shè)備中可實(shí)現(xiàn)矢量和矩陣功能。
英特爾Max系列產(chǎn)品統(tǒng)一支持oneAPI,并基于此實(shí)現(xiàn)通用、開放、基于標(biāo)準(zhǔn)的編程模型,釋放生產(chǎn)力和性能。英特爾oneAPI工具包括高級編譯器、庫、分析工具和代碼遷移工具,可使用SYCL輕松將CUDA代碼遷移到開放的C++。
英特爾數(shù)據(jù)中心Max系列GPU通過當(dāng)今框架的開源擴(kuò)展來實(shí)現(xiàn)軟件支持和優(yōu)化,例如面向PyTorch*的英特爾擴(kuò)展、面向TensorFlow*的英特爾?擴(kuò)展和面向DeepSpeed*的英特爾?擴(kuò)展。通過將這些擴(kuò)展與上游框架版本一起使用,用戶將能夠在機(jī)器學(xué)習(xí)工作流中實(shí)現(xiàn)快速整合。
我們在一個600瓦OAM形態(tài)的GPU上評估了Llama 2的70億參數(shù)模型和Llama 2的130億參數(shù)模型推理性能,這個GPU上封裝了兩個tile,而我們只使用其中一個tile來運(yùn)行推理。圖4顯示,對于輸入長度為32到2000的token,英特爾數(shù)據(jù)中心GPU Max系列的一個tile可以為70億參數(shù)模型的推理提供低于20毫秒的單token延遲,130億參數(shù)模型的單token延遲為29.2-33.8毫秒3。因?yàn)樵揋PU上封裝了兩個tile,用戶可以同時并行運(yùn)行兩個獨(dú)立的實(shí)例,每個tile上運(yùn)行一個,以獲得更高的吞吐量并獨(dú)立地服務(wù)客戶端。
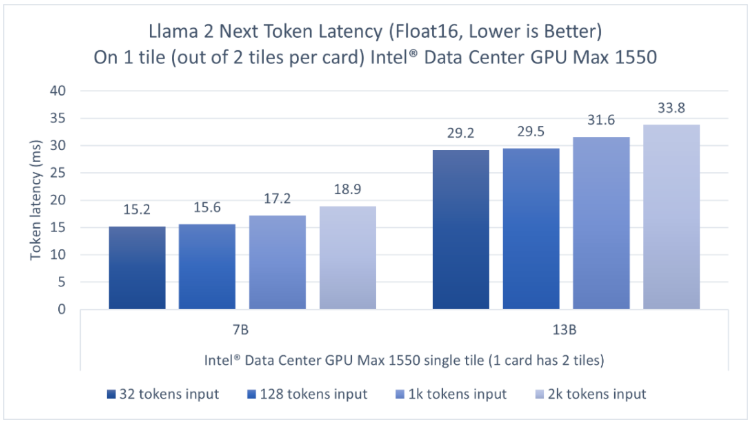
圖4英特爾數(shù)據(jù)中心GPUMax1550上的Llama2的70億和130億參數(shù)模型的推理性能
關(guān)于在英特爾GPU平臺上運(yùn)行大語言模型和Llama 2,可以點(diǎn)擊此處(https://intel.github.io/intel-extension-for-pytorch/llm/xpu/)獲取詳細(xì)信息。目前英特爾開發(fā)者云平臺上已發(fā)布英特爾GPU Max云實(shí)例測試版。
英特爾平臺上的大語言模型微調(diào)
除了推理之外,英特爾一直在積極地推進(jìn)微調(diào)加速,通過向Hugging Face Transformers、PEFT、Accelerate和Optimum庫提供優(yōu)化,并在面向Transformers的英特爾?擴(kuò)展中提供參考工作流。這些工作流支持在相關(guān)英特爾平臺上高效地部署典型的大語言模型任務(wù),如文本生成、代碼生成、完成和摘要。
總結(jié)
上述內(nèi)容介紹了在英特爾AI硬件產(chǎn)品組合上運(yùn)行Llama 2的70億和130億參數(shù)模型推理性能的初始評估,包括Habana Gaudi2深度學(xué)習(xí)加速器、第四代英特爾至強(qiáng)可擴(kuò)展處理器、英特爾?至強(qiáng)?CPU Max系列和英特爾數(shù)據(jù)中心GPU Max系列。我們將繼續(xù)通過軟件發(fā)布提供優(yōu)化,后續(xù)會再分享更多關(guān)于大語言模型和更大的Llama 2模型的評估。
審核編輯 黃宇
-
英特爾
+關(guān)注
關(guān)注
61文章
9995瀏覽量
172023 -
AI
+關(guān)注
關(guān)注
87文章
31259瀏覽量
269615 -
大模型
+關(guān)注
關(guān)注
2文章
2503瀏覽量
2915
發(fā)布評論請先 登錄
相關(guān)推薦
使用英特爾AI PC為YOLO模型訓(xùn)練加速

英特爾推出全新英特爾銳炫B系列顯卡

英特爾發(fā)布全新企業(yè)AI一體化方案
英特爾發(fā)布全新企業(yè)AI一體化解決方案
英特爾AI PC無所不能的實(shí)力
英特爾攜手百度智能云加速AI落地
Inflection AI攜手英特爾推出企業(yè)級AI系統(tǒng)
四大核心展區(qū),英特爾在工博會展現(xiàn)AI與制造深度融合

英特爾亮相2024云棲大會,共話AI時代發(fā)展新機(jī)

如何將Llama3.1模型部署在英特爾酷睿Ultra處理器

英特爾以生成式AI RAG解決方案,為巴黎奧運(yùn)健兒提供便捷體驗(yàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論