") 算力技術(shù)未來發(fā)展路徑概述(2023)
算力技術(shù)未來發(fā)展路徑概述(2023)
隨著人工智能、隱私計(jì)算、AR/VR以及基因測(cè)試/生物制藥等新型高性能計(jì)算應(yīng)用的不斷普及,對(duì)算力的需求也不斷持續(xù)增加。比如,以ChatGPT為代表的大模型需要巨大算力支撐。大模型對(duì)算力的需求增速遠(yuǎn)大于摩爾定律增速。
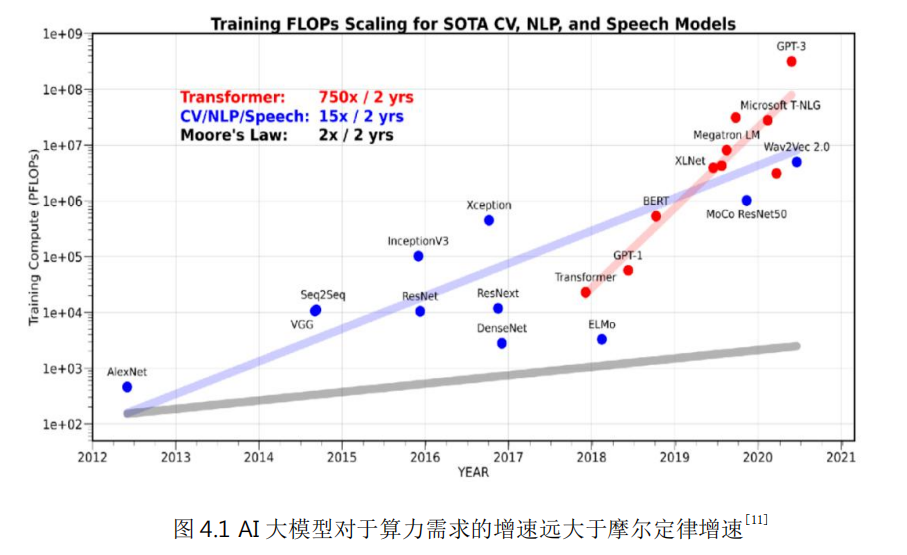
自微處理器誕生以來,算力的增長按摩爾定律發(fā)展,即通過增加單位芯片面積的門電路數(shù)量來增加處理器算力,降低處理器成本和功耗。但近年來這條路已經(jīng)遇到越來越大的困難,通過持續(xù)縮微來提升性能已經(jīng)無法滿足應(yīng)用的需求。
1、More Moore:繼續(xù)追求更高的晶體管單位密度。比如晶體管工藝結(jié)構(gòu)從鰭式結(jié)構(gòu)FinFET到環(huán)形結(jié)構(gòu)GAA,以及納米片、納米線等技術(shù)手段有望將晶體管密度繼續(xù)提升5倍以上。但這條路在成本、功耗方面的挑戰(zhàn)非常大。
2、Beyond CMOS:放棄CMOS工藝,尋求新材料和新工藝。比如使用碳納米管、二硫化鉬等二維材料的新型制備工藝,和利用量子隧穿效應(yīng)的新型機(jī)制晶體管。但這條路徑的不確定性較大,離成熟還需要很長時(shí)間。
芯片架構(gòu):DSA & 3D堆疊& Chiplet
DSA針對(duì)特定領(lǐng)域的應(yīng)用采用高效的架構(gòu),比如使用專用內(nèi)存最小化數(shù)據(jù)搬移、根據(jù)應(yīng)用特點(diǎn)把芯片資源更多側(cè)重于計(jì)算或存儲(chǔ)、簡化數(shù)據(jù)類型、使用特定編程語言和指令等等。與ASIC芯片(Application Specific Integrated Circuit,專用集成電路)相比,DSA芯片在同等晶體管資源下具有相近的性能和能效,并且最大程度的保留了靈活性和領(lǐng)域的通用性。
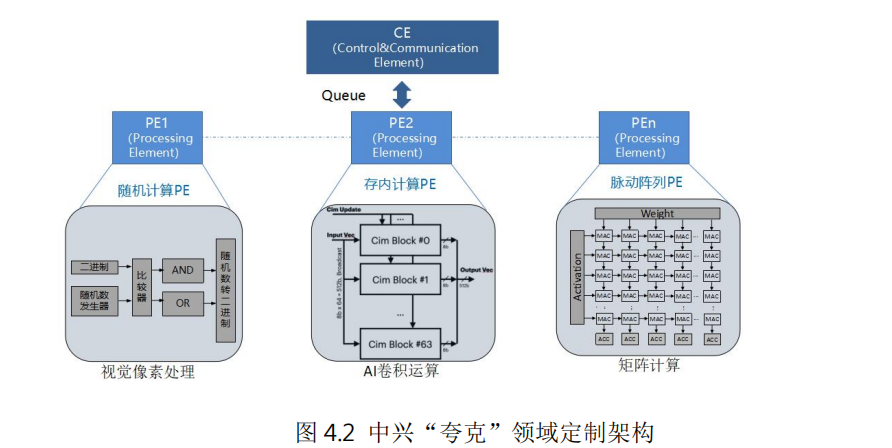
例如中興通訊提出的計(jì)算和控制分離的人工智能領(lǐng)域定制芯片架構(gòu)“夸克”,針對(duì)深度神經(jīng)網(wǎng)絡(luò)的計(jì)算特點(diǎn),將算力抽象成張量、向量和標(biāo)量引擎,通過獨(dú)立的控制引擎(CE)對(duì)各種PE引擎進(jìn)行靈活編排和調(diào)度,從而可以高效實(shí)現(xiàn)各種深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)計(jì)算,完成自然語言處理、AI檢測(cè)、識(shí)別和分類等各種人工智能應(yīng)用。由于采用軟硬件協(xié)同設(shè)計(jì)的定制化方案,DSA芯片在相同功耗下可以取得比傳統(tǒng)CPU高數(shù)十倍甚至幾百倍的性能。
摩爾定律本身是在2D空間進(jìn)行評(píng)估的,隨著芯片微縮愈加困難,3D堆疊技術(shù)被認(rèn)為是提升集成度的一個(gè)重要技術(shù)手段。3D堆疊就是不改變?cè)痉庋b面積情況下,在垂直方向進(jìn)行的芯片疊放。這種芯片設(shè)計(jì)架構(gòu)有助于解決密集計(jì)算的內(nèi)存墻問題,具有更好的擴(kuò)展性和能效比。
Chiplet技術(shù)被認(rèn)為是延續(xù)摩爾定律的關(guān)鍵技術(shù)。首先Chiplet技術(shù)將芯片設(shè)計(jì)模塊化,將大型芯片小型化,可以有效提升芯片良率,降低芯片設(shè)計(jì)的復(fù)雜程度。其次,Chiplet技術(shù)可以把不同芯粒根據(jù)需要來選擇合適的工藝制程分開制造(比如核心算力邏輯使用新工藝提升性能,外圍接口仍采用成熟工藝降低成本),再通過先進(jìn)封裝技術(shù)進(jìn)行組裝,可以有效降低制造成本。
與傳統(tǒng)芯片方案相比,Chiplet模式具有設(shè)計(jì)靈活性、成本低、上市周期短三方面優(yōu)勢(shì)。Chiplet技術(shù)面臨的最大挑戰(zhàn)是互聯(lián)技術(shù),2022年3月2日,“UCIe產(chǎn)業(yè)聯(lián)盟”成立,致力于滿足客戶對(duì)可定制封裝互聯(lián)互通要求。Chiplet產(chǎn)業(yè)會(huì)逐漸成熟,并將形成包括互聯(lián)接口、架構(gòu)設(shè)計(jì)、制造和先進(jìn)封裝的完整產(chǎn)業(yè)鏈。
存算一體使得計(jì)算和存儲(chǔ)從分離走向聯(lián)合優(yōu)化
存算一體技術(shù)就是從應(yīng)用需求出發(fā),進(jìn)行計(jì)算和存儲(chǔ)的最優(yōu)化聯(lián)合設(shè)計(jì),減少數(shù)據(jù)的無效搬移、增加數(shù)據(jù)的讀寫帶寬、提升計(jì)算的能效比,從而突破現(xiàn)有內(nèi)存墻和功耗墻的限制。
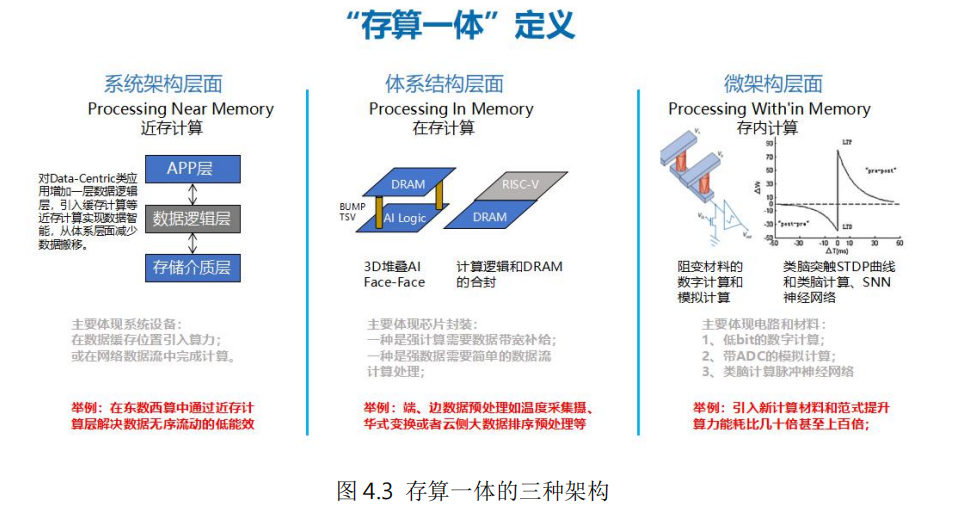
存算一體包含系統(tǒng)架構(gòu)、體系結(jié)構(gòu)和微架構(gòu)多個(gè)層面。系統(tǒng)架構(gòu)層面,在傳統(tǒng)計(jì)算和存儲(chǔ)單元中間增加數(shù)據(jù)邏輯層,實(shí)現(xiàn)近存計(jì)算,減少數(shù)據(jù)中心內(nèi)、外數(shù)據(jù)低效率搬移,從系統(tǒng)層面提升計(jì)算能效比;體系架構(gòu)層面,利用3D堆疊、異構(gòu)集成等先進(jìn)技術(shù),將計(jì)算邏輯和存儲(chǔ)單元合封,實(shí)現(xiàn)在存計(jì)算,從而增加數(shù)據(jù)帶寬、優(yōu)化數(shù)據(jù)搬移路徑、降低系統(tǒng)延時(shí);微架構(gòu)層面,進(jìn)行存儲(chǔ)和計(jì)算的一體化設(shè)計(jì),實(shí)現(xiàn)存內(nèi)計(jì)算,基于傳統(tǒng)存儲(chǔ)材料和新型非易失存儲(chǔ)材料,在存儲(chǔ)功能的電路內(nèi)同時(shí)實(shí)現(xiàn)計(jì)算功能,取得最佳的能效比。
(一)系統(tǒng)架構(gòu)層面的近存計(jì)算(Processing Near Memory)
近存計(jì)算在數(shù)據(jù)緩存位置引入算力,在本地產(chǎn)生處理結(jié)果并直接返回,可以減少數(shù)據(jù)移動(dòng),加快處理速度,并提升安全性。通過對(duì)Data-Centric類應(yīng)用增加一層數(shù)據(jù)邏輯層,整合原系統(tǒng)架構(gòu)中的數(shù)據(jù)邏輯布局功能和應(yīng)用服務(wù)數(shù)據(jù)智能功能,并引入緩存計(jì)算,從而減少數(shù)據(jù)搬移。在“東數(shù)西算”工程中,可以通過設(shè)置近存計(jì)算層,解決數(shù)據(jù)無序流動(dòng)的低能效問題。
(二)體系架構(gòu)層面的在存計(jì)算(Processing In Memory)
在存計(jì)算主要在存儲(chǔ)器內(nèi)部集成計(jì)算引擎,這個(gè)存儲(chǔ)器通常是DRAM。其目標(biāo)是直接在數(shù)據(jù)讀寫的同時(shí)完成簡單處理,而無需將數(shù)據(jù)拷貝到處理器中進(jìn)行計(jì)算。例如攝氏和華氏溫度的轉(zhuǎn)換。在存計(jì)算本質(zhì)上還是計(jì)算、存儲(chǔ)分離架構(gòu),只是將存儲(chǔ)和計(jì)算靠近設(shè)計(jì),從而減少數(shù)據(jù)搬移帶來的開銷。目前主要是存儲(chǔ)器廠商在推動(dòng)其產(chǎn)業(yè)化。
(三)微架構(gòu)層面的存內(nèi)計(jì)算(Processing Within Memory)
存內(nèi)計(jì)算是把計(jì)算單位嵌入到存儲(chǔ)器中,特別適合執(zhí)行高度并行的矩陣向量乘積,在機(jī)器學(xué)習(xí)、密碼學(xué)、微分方程求解等方面有較好的應(yīng)用前景。
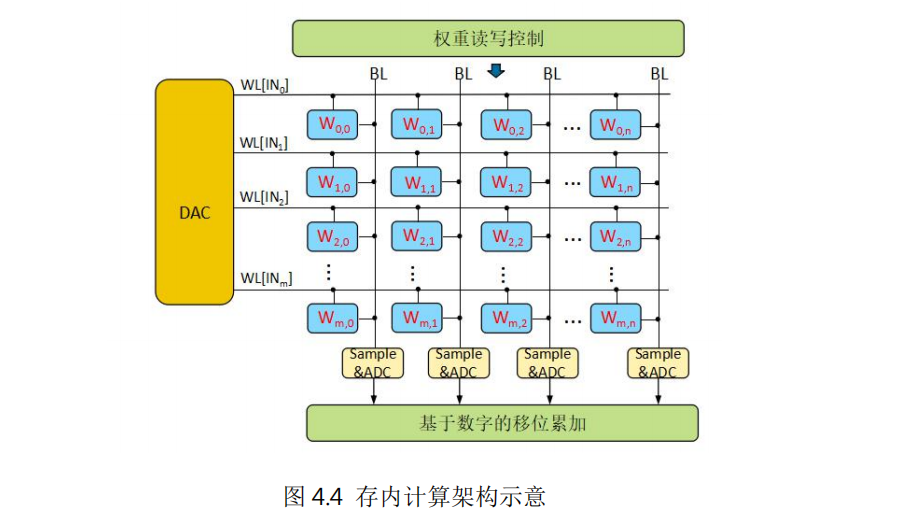
存內(nèi)計(jì)算采用計(jì)算、存儲(chǔ)統(tǒng)一設(shè)計(jì)的架構(gòu)。以深度神經(jīng)網(wǎng)絡(luò)的矩陣向量乘加操作為例,由輸入端的DAC、單元陣列、輸出端的ADC以及其他輔助電路組成。存儲(chǔ)單元中存放權(quán)重?cái)?shù)據(jù),輸入經(jīng)過DAC轉(zhuǎn)換后變成對(duì)存儲(chǔ)數(shù)據(jù)的讀寫操作,利用歐姆定律和基爾霍夫定律,不同的存儲(chǔ)單元輸出電流自動(dòng)累加后輸出到ADC單元進(jìn)行采樣,轉(zhuǎn)換成輸出的數(shù)字信號(hào),這樣就完成了矩陣向量乘加操作。
基于對(duì)等系統(tǒng)的分布式計(jì)算架構(gòu)
傳統(tǒng)的計(jì)算系統(tǒng)以CPU為中心進(jìn)行搭建,業(yè)務(wù)的激增對(duì)于系統(tǒng)處理能力要求越來越高,摩爾定律放緩,CPU的處理能力增長越來越困難,出現(xiàn)了算力墻。通過領(lǐng)域定制(DSA)和異構(gòu)計(jì)算架構(gòu)可以提升系統(tǒng)的性能,但是改變不了以CPU為中心的架構(gòu)體系,加速器之間的數(shù)據(jù)交互通常還是需要通過CPU來進(jìn)行中轉(zhuǎn),CPU容易成為瓶頸,效率不高。
基于xPU(以數(shù)據(jù)為中心的處理單元)為中心的對(duì)等系統(tǒng)可以構(gòu)建一個(gè)新型的分布式計(jì)算架構(gòu)。如圖4.5所示,對(duì)等系統(tǒng)由多個(gè)結(jié)構(gòu)相似的節(jié)點(diǎn)互聯(lián)而成,每個(gè)節(jié)點(diǎn)以xPU為核心,包含多種異構(gòu)的算力資源,如CPU、GPU及其它算力芯片。xPU主要功能是完成節(jié)點(diǎn)內(nèi)異構(gòu)算力的接入、互聯(lián)以及節(jié)點(diǎn)間的互聯(lián),xPU內(nèi)部的通用處理器核可以對(duì)節(jié)點(diǎn)內(nèi)的算力資源進(jìn)行管理和二級(jí)調(diào)度。節(jié)點(diǎn)內(nèi)不再以CPU為中心,CPU、GPU及其它算力芯片作為節(jié)點(diǎn)內(nèi)的算力資源處于完全對(duì)等的地位,xPU根據(jù)各算力芯片的特點(diǎn)及能力進(jìn)行任務(wù)分配。
對(duì)等系統(tǒng)的節(jié)點(diǎn)內(nèi)部和節(jié)點(diǎn)之間采用基于內(nèi)存語義的新型傳輸協(xié)議,即,采用read/write等對(duì)內(nèi)存操作的語義,實(shí)現(xiàn)對(duì)等、無連接、授權(quán)空間訪問的通信模式,通過多路徑傳輸、選擇性重傳、集合通信等技術(shù)提高通信效率。與TCP、RoCE等現(xiàn)有傳輸協(xié)議相比,基于內(nèi)存語義的傳輸協(xié)議基于低延時(shí)、高擴(kuò)展性的優(yōu)勢(shì)。節(jié)點(diǎn)內(nèi)xPU、CPU、GPU及其他算力芯片之間通過基于內(nèi)存語義的低延時(shí)總線直接進(jìn)行數(shù)據(jù)交互。節(jié)點(diǎn)間通過xPU內(nèi)部的高性能轉(zhuǎn)發(fā)面實(shí)現(xiàn)基于內(nèi)存語義的低延時(shí)Fabric,從而構(gòu)建以節(jié)點(diǎn)為單位的分布式算力系統(tǒng)。同時(shí)xPU內(nèi)置安全、網(wǎng)絡(luò)、存儲(chǔ)加速模塊,降低了算力資源的消耗,提高了節(jié)點(diǎn)的性能。
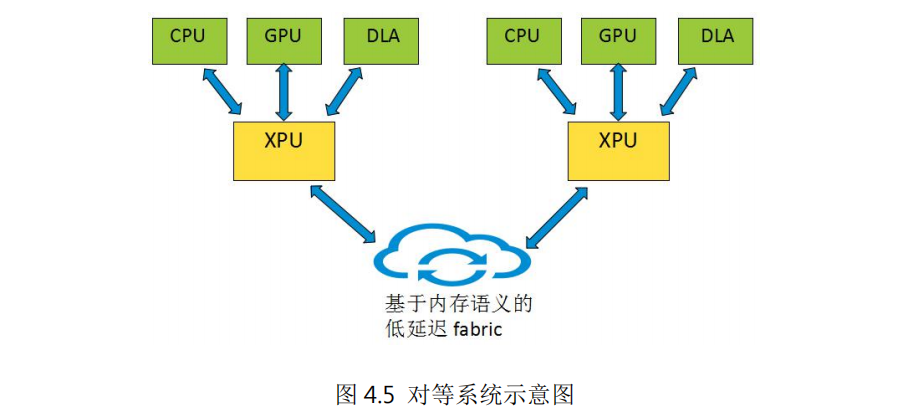
基于對(duì)等系統(tǒng)架構(gòu)的服務(wù)器可以看成一個(gè)“分布式計(jì)算系統(tǒng)”,有利于產(chǎn)業(yè)鏈上各節(jié)點(diǎn)獨(dú)立規(guī)劃開發(fā),發(fā)揮各自優(yōu)勢(shì)。比如xPU卸載+庫/外OS演進(jìn)+ APP direct模式解決公共能力(存儲(chǔ)、網(wǎng)絡(luò)),整體性能的提升不再依賴于先進(jìn)工藝;基于對(duì)等內(nèi)存語義互聯(lián)實(shí)現(xiàn)系統(tǒng)平滑擴(kuò)展,將龐大分布式算力視為一臺(tái)單一的“計(jì)算機(jī)”。
支撐算網(wǎng)融合的IP網(wǎng)絡(luò)技術(shù)實(shí)現(xiàn)算力資源高效調(diào)度
算網(wǎng)深度融合有兩大驅(qū)動(dòng)力,一是需求側(cè),實(shí)現(xiàn)算力和網(wǎng)絡(luò)的協(xié)同調(diào)度,滿足業(yè)務(wù)對(duì)算力資源和網(wǎng)絡(luò)連接的一體化需求。比如,高分辨率的VR云游戲,既需要專用圖形處理器(GPU)計(jì)算資源完成渲染,又需要確定性的網(wǎng)絡(luò)連接來滿足10 ms以內(nèi)的端到端時(shí)延要求。二是供給側(cè),借助于網(wǎng)絡(luò)設(shè)施天生的無處不在的分布式特點(diǎn),算網(wǎng)深度融合可以助力算力資源也實(shí)現(xiàn)分布化部署,滿足各類應(yīng)用對(duì)于時(shí)延、能耗、安全的多樣化需求。
算網(wǎng)融合給IP網(wǎng)絡(luò)技術(shù)提出了挑戰(zhàn)。在互聯(lián)網(wǎng)整個(gè)技術(shù)架構(gòu)中,通常來說算對(duì)應(yīng)著上層的應(yīng)用,網(wǎng)對(duì)應(yīng)著底層的連接,IP技術(shù)作為中間層,起到承上啟下的樞紐作用。傳統(tǒng)的IP網(wǎng)絡(luò)遵循的端到端和分層解耦的架構(gòu)設(shè)計(jì),使得業(yè)務(wù)可以脫離網(wǎng)絡(luò)而獨(dú)立發(fā)展,極大降低了互聯(lián)網(wǎng)業(yè)務(wù)的創(chuàng)新門檻,增加了業(yè)務(wù)部署的便利。但是在這樣的設(shè)計(jì)架構(gòu)之下,業(yè)務(wù)和網(wǎng)絡(luò)處于“去耦合“的狀態(tài),最終絕大多數(shù)業(yè)務(wù)只能按照“盡力而為”的模式運(yùn)行。
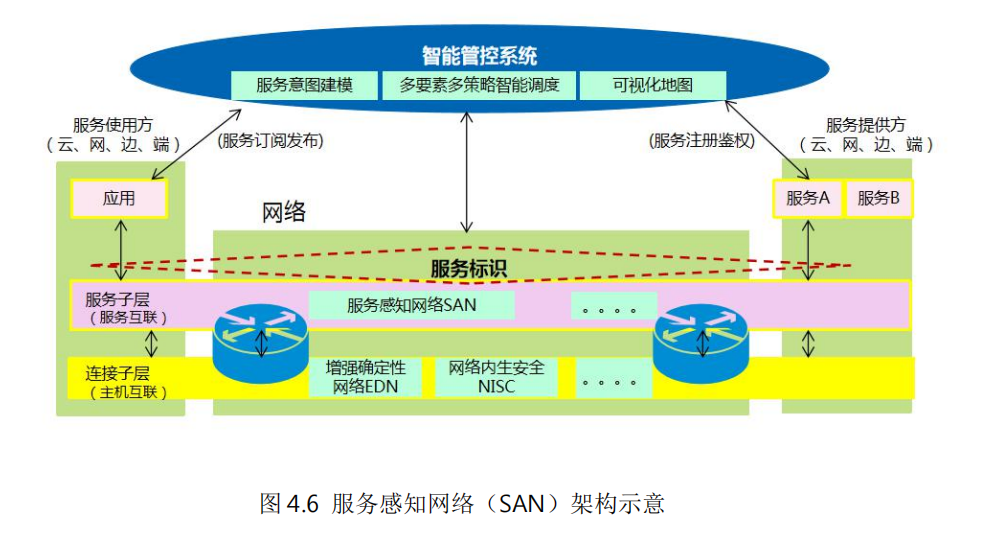
如何建立業(yè)務(wù)和網(wǎng)絡(luò)之間的橋梁,實(shí)現(xiàn)算力資源、網(wǎng)絡(luò)資源的協(xié)同和精細(xì)化管理,是未來IP網(wǎng)絡(luò)面臨的一大挑戰(zhàn)。中興通訊提出的“服務(wù)感知網(wǎng)絡(luò)(SAN,Service AwarenessNetwork)”是在這個(gè)方面的創(chuàng)新嘗試
服務(wù)感知網(wǎng)絡(luò)實(shí)現(xiàn)了算力服務(wù)和網(wǎng)絡(luò)服務(wù)的一體化供給,實(shí)現(xiàn)算網(wǎng)資源的高效調(diào)度,既保障了服務(wù)質(zhì)量,又能將節(jié)能減排的要求落到實(shí)處。
-
晶體管
+關(guān)注
關(guān)注
77文章
9693瀏覽量
138189 -
算力
+關(guān)注
關(guān)注
1文章
977瀏覽量
14822 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1561瀏覽量
7671
原文標(biāo)題:算力技術(shù)未來發(fā)展路徑概述(2023)
文章出處:【微信號(hào):架構(gòu)師技術(shù)聯(lián)盟,微信公眾號(hào):架構(gòu)師技術(shù)聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦

英碼科技精彩亮相火爆的IOTE 2023,多面賦能AIoT產(chǎn)業(yè)發(fā)展!
算力網(wǎng)絡(luò)發(fā)展的三大挑戰(zhàn)
高算力芯片未來技術(shù)發(fā)展途徑
ChatGPT技術(shù):AIGC對(duì)算力有哪些需求?
《大規(guī)模光電集成賦能智能算力網(wǎng)絡(luò)白皮書》概述

AI算力研究框架(2023)

從算力網(wǎng)絡(luò)發(fā)展,看未來十年的宏觀算力體系

MWCSH 2023 | 華為譚峰:算力網(wǎng)絡(luò)延伸至家庭終端的市場(chǎng)思考
算力大會(huì)2023 | 華為星河AI網(wǎng)絡(luò),高運(yùn)力釋放AI時(shí)代高算力
數(shù)智新生長 澎湃興算力 中興通訊全棧算力布局亮相2023中國算力大會(huì)
曙光在全國范圍內(nèi)參與建立多個(gè)算力中心
是德科技智能算力‘芯’技術(shù)研討會(huì)回顧
算力中心:數(shù)字經(jīng)濟(jì)發(fā)展的新引擎





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論